Orpheus-TTS:AI文本转语音,免费好用的TTS系统
名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)目录
- 一、Orpheus-TTS:重新定义语音合成的标准
- 1. 什么是Orpheus-TTS?
- 2. 项目的核心理念
- 二、核心技术特性:四大突破性优势
- 1. 超低延迟:实时对话的技术保障
- 2. 类人语音表达:自然情感的完美呈现
- 3. 零样本语音克隆:无需训练的声音复制
- 4. 多语言支持:全球化的语音解决方案
- 三、技术架构深度解析
- 1. 基于Llama-3B的混合架构
- 2. 训练数据规模
- 3. 实时流式处理机制
- 4. Orpheus-TTS工作流程架构
- 四、模型选择指南:找到最适合你的版本
- 1. 预训练模型 vs 微调模型
- 2. 声音角色选择
- 五、快速上手:从安装到第一个语音
- 1. 环境准备与安装
- 2. 基础使用示例
- 3. 高级功能:零样本语音克隆
- 六、应用场景:开启语音交互新时代
- 七、性能优化与部署策略
- 1. 硬件需求与性能优化
- 2. 延迟优化技巧
- 3. 云端部署方案
- 八、社区生态与扩展工具
- 1. 社区贡献的工具集
- 2. 开发者资源
- 九、与主流TTS系统对比分析
- 1. 开源TTS模型横向对比
- 2. 商业化TTS服务对比
- 十、总结
很高兴你打开了这篇博客,更多好用的软件工具,请关注我、订阅专栏《实用软件与高效工具》,内容持续更新中…
在人工智能快速发展的今天,文本转语音(TTS)技术正成为连接人与机器的重要桥梁。
2025年3月19日,由Canopy Labs团队发布的Orpheus-TTS开源文本转语音模型正式亮相,这款基于Llama-3B架构的系统,以其接近人类的情感表达、超低延迟和零样本语音克隆能力,迅速在开源社区引起轰动。

一、Orpheus-TTS:重新定义语音合成的标准
1. 什么是Orpheus-TTS?
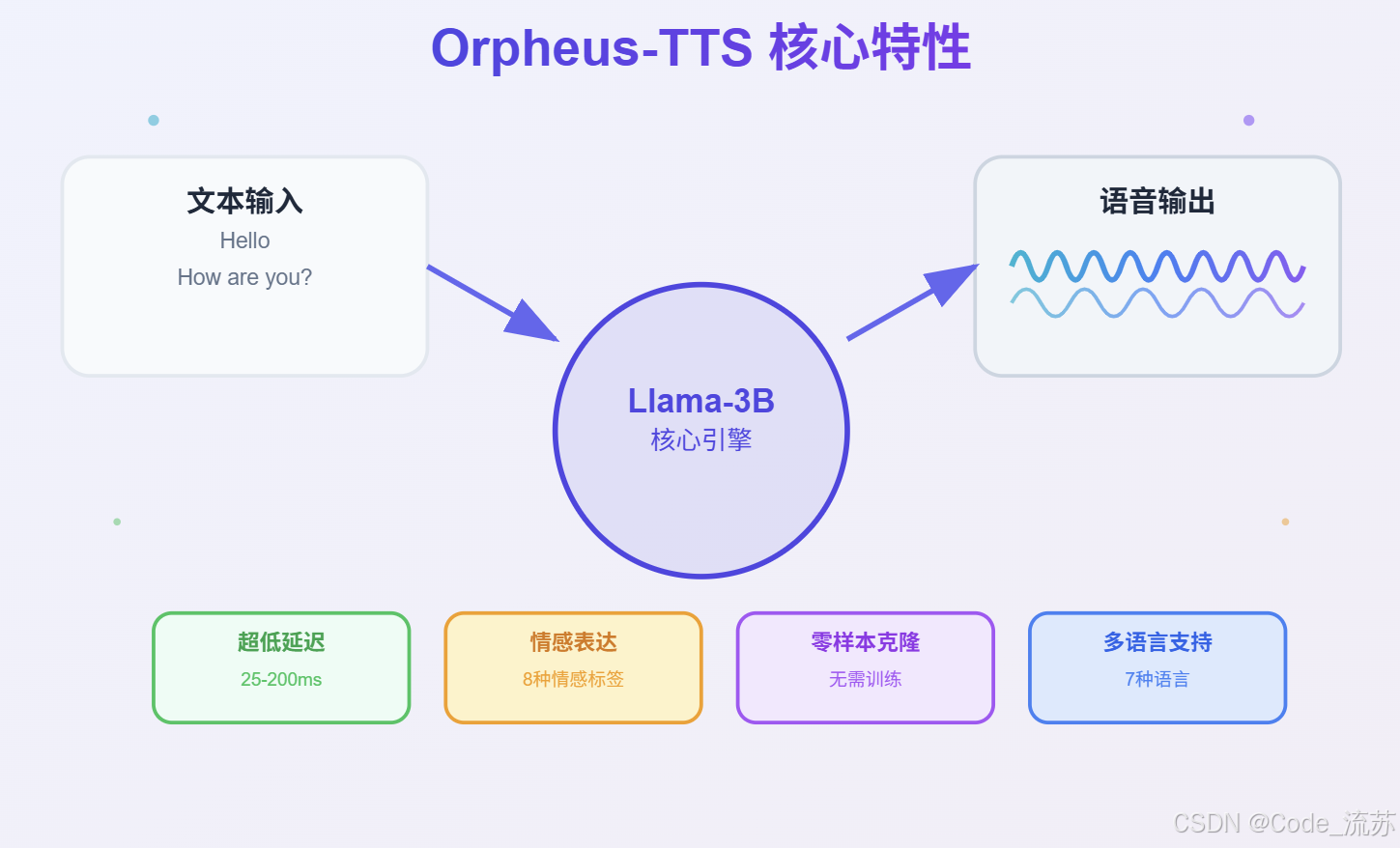
Orpheus-TTS是一个基于Llama-3B骨干网络构建的先进开源文本转语音系统,展示了使用大语言模型进行语音合成的新兴能力。就像希腊神话中能用音乐魅惑众生的俄耳甫斯一样,这个系统旨在产生如此自然和富有表现力的语音,以至于能够吸引听众。
1️⃣github仓库:https://github.com/canopyai/Orpheus-TTS

2️⃣官网:https://canopylabs.ai/

2. 项目的核心理念
Orpheus-TTS的设计理念简单而深刻:让机器说话像人一样自然。它不仅仅是将文字转换为声音,更是要赋予声音情感、语调和节奏,创造出真正接近人类水平的语音体验。
二、核心技术特性:四大突破性优势
1. 超低延迟:实时对话的技术保障
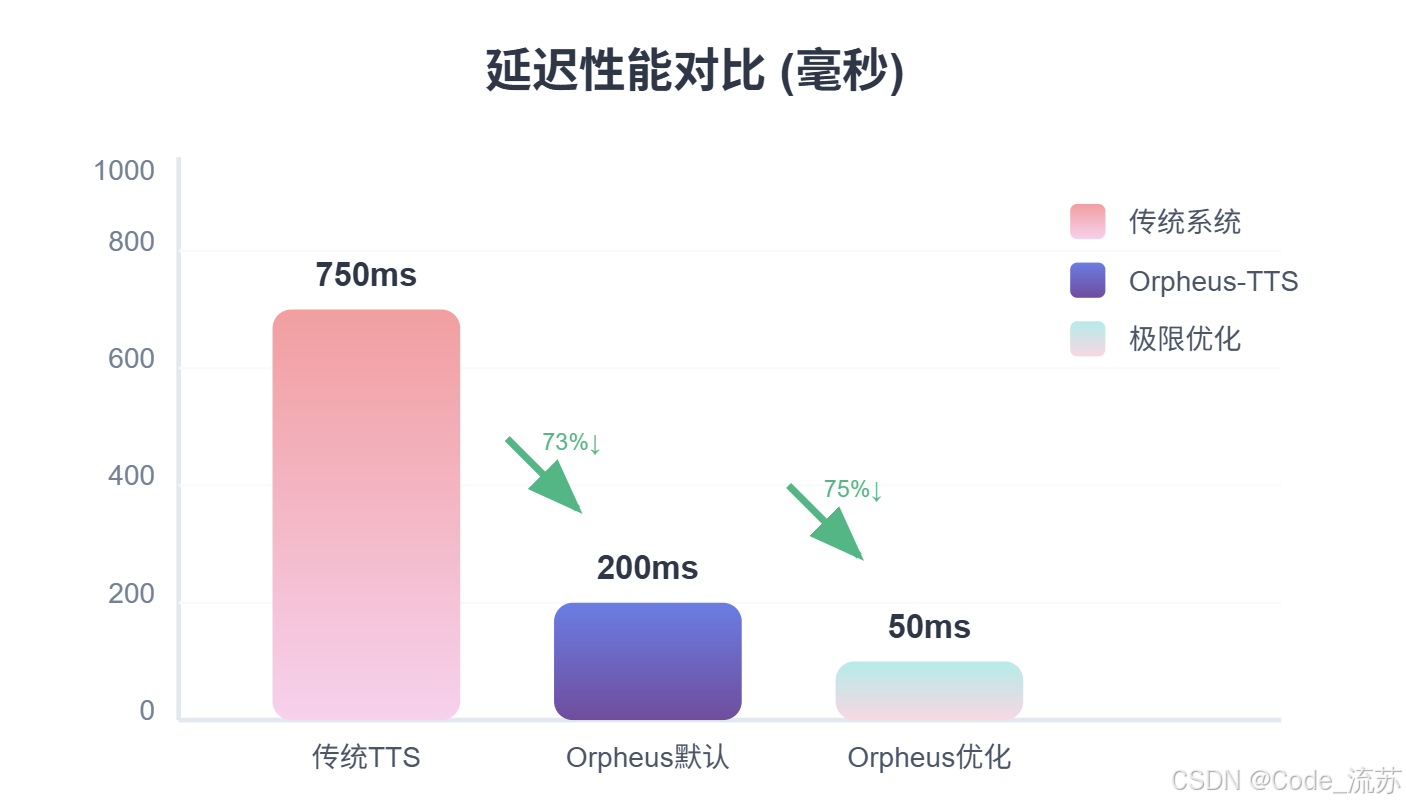
延迟性能对比表
| 应用场景 | 传统TTS系统 | Orpheus-TTS默认 | Orpheus-TTS优化后 |
|---|---|---|---|
| 实时对话 | 500-1000ms | 200ms | 25-50ms |
| 语音助手 | 300-800ms | 200ms | 100ms |
| 流媒体应用 | 400-600ms | 200ms | 100ms |
通过优化输入流和模型的KV缓存,Orpheus-TTS可将延迟从默认的200毫秒大幅降低至25-50毫秒,这种超低延迟使得实时对话成为可能,为虚拟助手、客服系统等即时响应场景提供了技术基础。
2. 类人语音表达:自然情感的完美呈现
Orpheus-TTS能够生成自然的语调、情感和节奏,其性能超越了当前最先进的闭源模型。系统支持多种情感标签,让语音表达更加丰富:
<laugh>- 笑声<chuckle>- 轻笑<sigh>- 叹息<cough>- 咳嗽<groan>- 抱怨<sniffle>- 抽鼻子<yawn>- 打哈欠<gasp>- 喘息

3. 零样本语音克隆:无需训练的声音复制
Orpheus-TTS支持零样本语音克隆,可以在无需预先微调的情况下克隆声音。这意味着你只需要提供一小段音频样本,系统就能学会模仿特定的声音特征,为个性化语音应用开辟了新的可能性。
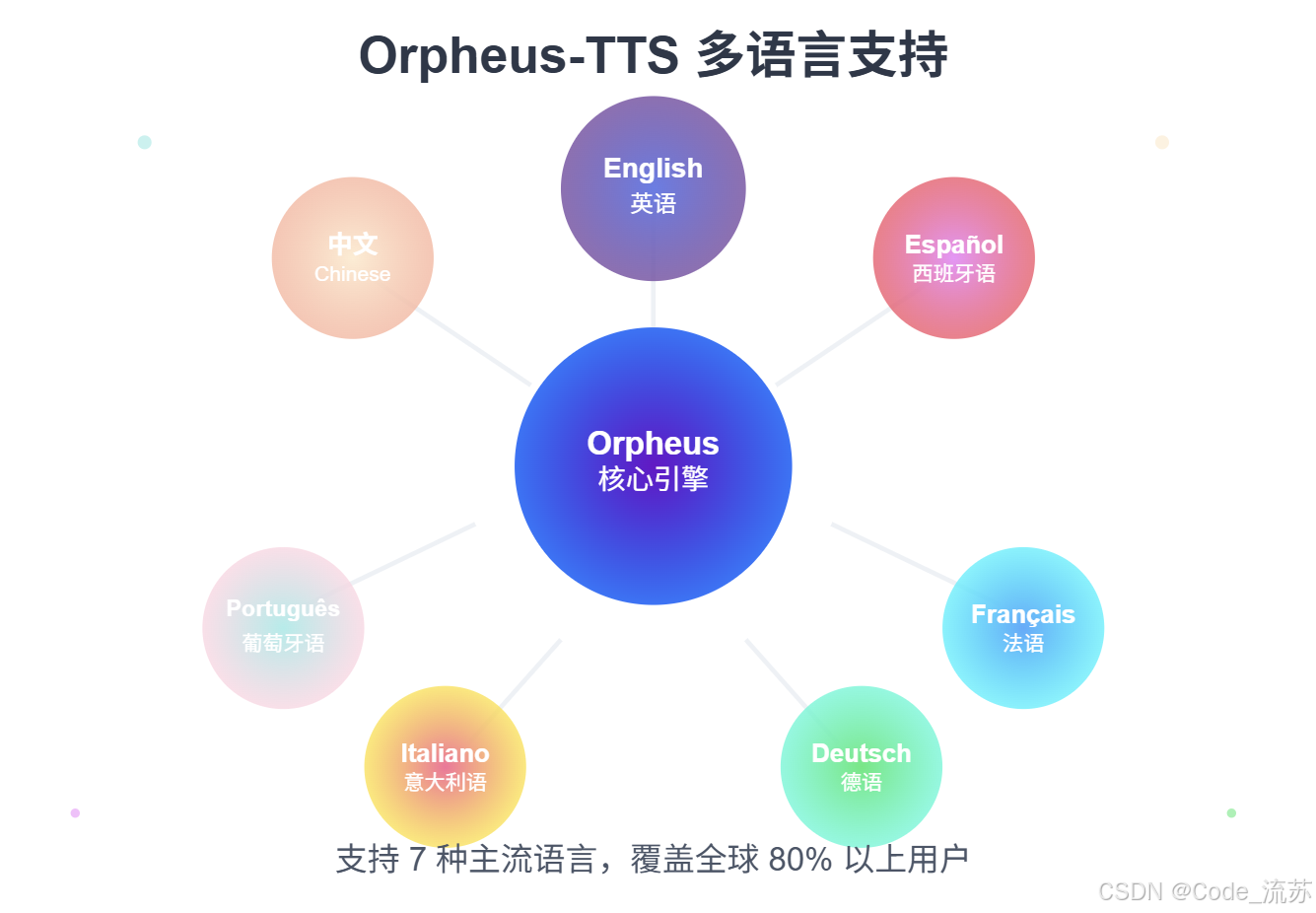
4. 多语言支持:全球化的语音解决方案
Orpheus-TTS支持英语、西班牙语、法语、德语、意大利语、葡萄牙语和中文等多种主流语言,实现了全球化的语音合成能力。
三、技术架构深度解析
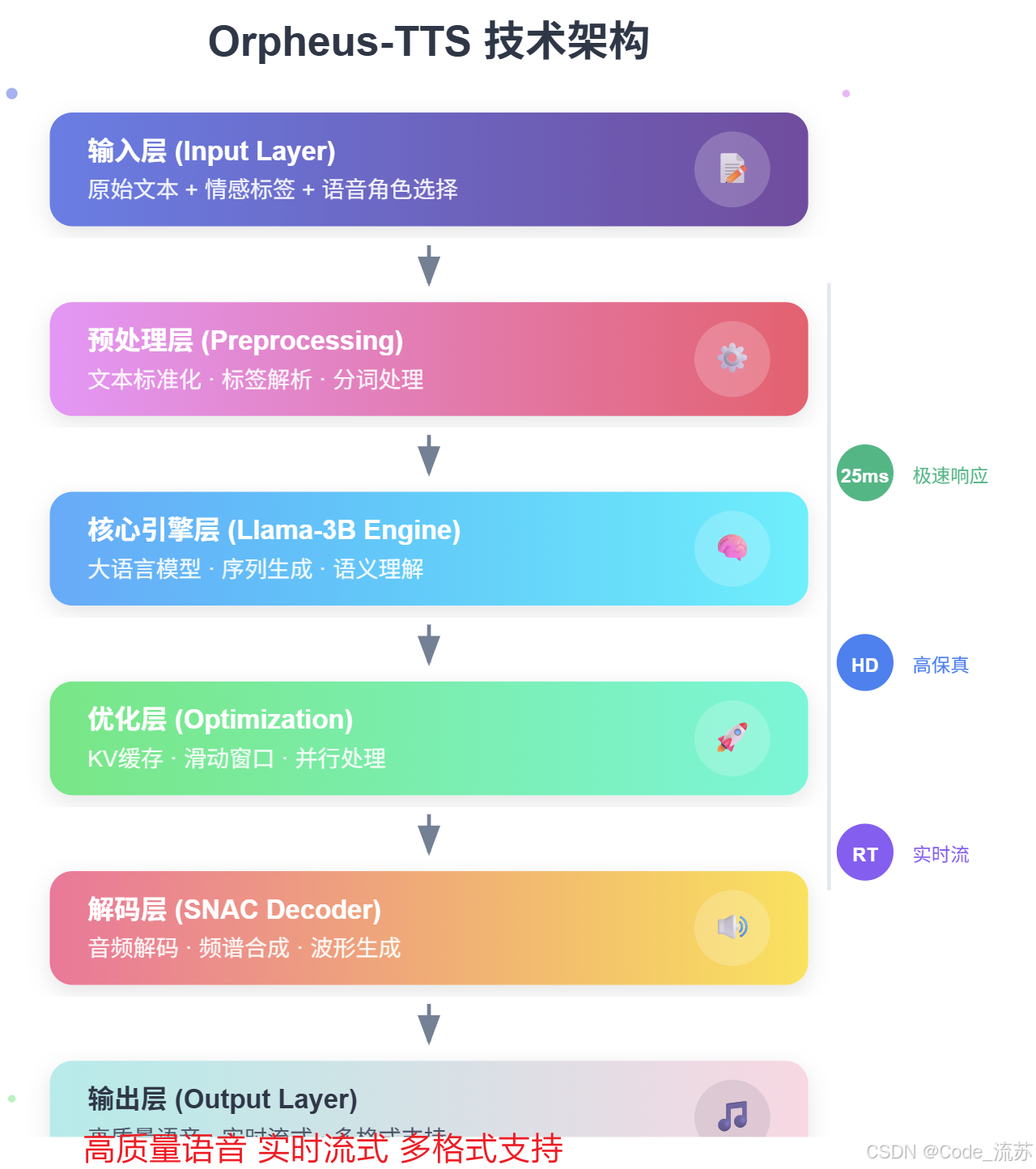
1. 基于Llama-3B的混合架构
Orpheus-TTS采用Llama-3b作为基础架构,结合混合专家(MoE)模型与KV缓存优化技术,参数规模覆盖150M至3B。这种设计既保证了模型的性能,又兼顾了部署的灵活性。
2. 训练数据规模
训练数据包含超过10万小时的英语语音及数十亿文本标记,模型在8192长度序列上进行训练,使用与TTS微调相同的数据集格式进行预训练。这种大规模的训练确保了模型具备强大的语言理解和生成能力。
3. 实时流式处理机制
通过非流式分词器与SNAC解码器的协同优化,模型实现了扁平化序列解码和滑动窗口处理,这是实现超低延迟的关键技术创新。
4. Orpheus-TTS工作流程架构
为了更好地理解Orpheus-TTS的工作原理,让我们通过流程图来看看整个系统的架构:
从上图可以看出,Orpheus-TTS采用了模块化的设计思路,从文本预处理到最终的音频输出,每个环节都经过了精心优化。
四、模型选择指南:找到最适合你的版本
1. 预训练模型 vs 微调模型
模型对比表
| 模型类型 | 模型名称 | 适用场景 | 特点 |
|---|---|---|---|
| 微调生产模型 | canopylabs/orpheus-tts-0.1-finetune-prod | 日常TTS应用 | 即插即用,8种预设声音 |
| 预训练基础模型 | canopylabs/orpheus-tts-0.1-pretrained | 高级定制任务 | 基于100k+小时英语数据 |
| 多语言模型 | canopylabs/orpheus-multilingual-research-release | 多语言研究 | 7套预训练和微调模型 |
2. 声音角色选择
微调生产模型提供8种英语声音选项,按对话真实感排序分别是:“tara”、“leah”、“jess”、“leo”、“dan”、“mia”、“zac”、“zoe”。每种声音都有其独特的特征,适合不同的应用场景。
五、快速上手:从安装到第一个语音
1. 环境准备与安装
# 克隆项目
git clone https://github.com/canopyai/Orpheus-TTS.git
cd Orpheus-TTS# 安装依赖
pip install orpheus-speech# 如果遇到版本问题,回退到稳定版本
pip install vllm==0.7.3
2. 基础使用示例
from orpheus_tts import OrpheusModel
import wave
import time# 初始化模型
model = OrpheusModel(model_name="canopylabs/orpheus-tts-0.1-finetune-prod",max_model_len=2048
)# 准备文本(支持情感标签)
prompt = '''tara: 你知道吗?<laugh> 最近的人工智能发展真是让人惊叹!
<sigh> 有时候我都觉得科技进步太快了。'''# 生成语音
start_time = time.time()
audio_data = model.generate_speech(prompt)
end_time = time.time()print(f"生成时间: {end_time - start_time:.2f}秒")# 保存音频文件
with wave.open('output.wav', 'wb') as wav_file:wav_file.setparams((1, 2, 24000, 0, 'NONE', 'NONE'))wav_file.writeframes(audio_data)
3. 高级功能:零样本语音克隆
# 零样本语音克隆示例
reference_audio = "path/to/reference.wav" # 参考音频
target_text = "这是我要合成的文本内容"# 使用预训练模型进行语音克隆
cloned_audio = model.clone_voice(reference_audio=reference_audio,text=target_text
)
六、应用场景:开启语音交互新时代
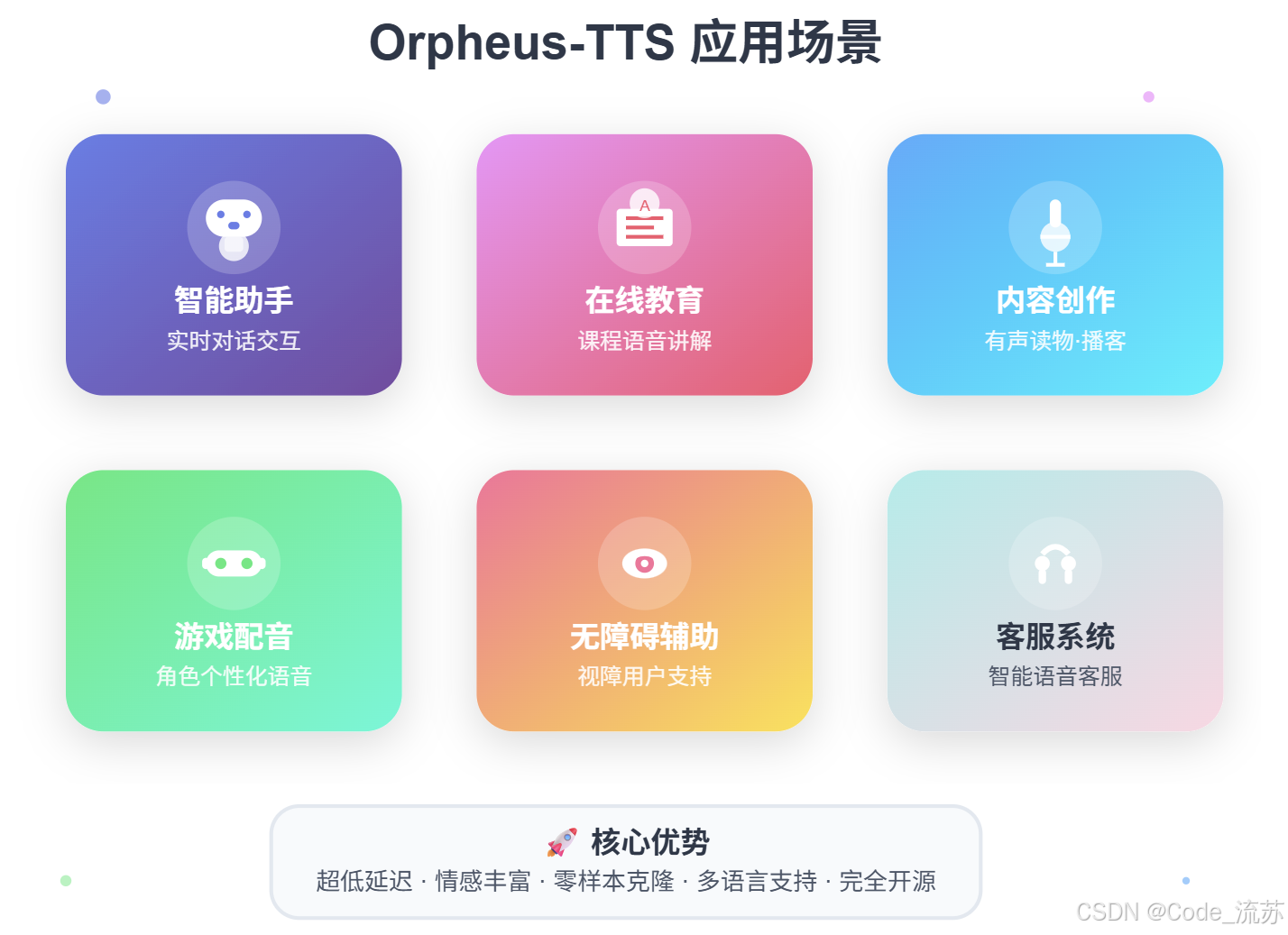
七、性能优化与部署策略
1. 硬件需求与性能优化
系统配置建议表
| 部署场景 | GPU内存 | CPU要求 | 预期延迟 |
|---|---|---|---|
| 开发测试 | 8GB | 8核以上 | 200ms |
| 生产环境 | 12GB+ | 16核以上 | 50-100ms |
| 大规模部署 | 24GB+ | 32核以上 | 25-50ms |
2. 延迟优化技巧
启用KV缓存和输入流式处理可以将延迟从200ms降低到100ms,确保足够的GPU性能。以下是一些关键的优化策略:
- 启用KV缓存:减少重复计算
- 输入流式处理:边输入边处理
- 批处理优化:提高吞吐量
- 模型量化:减少内存占用
3. 云端部署方案
Orpheus-TTS支持多种部署方式:
- Baseten平台:一键部署生产级实时流式服务
- Google Colab:快速体验和原型开发
- 本地部署:完全控制和自定义配置
八、社区生态与扩展工具
1. 社区贡献的工具集
开源性质的Orpheus-TTS吸引了社区贡献,目前已有多个实用工具:
- LM Studio本地客户端:通过LM Studio API运行
- FastAPI兼容接口:提供OpenAI风格的API接口
- Gradio WebUI:支持WSL和CUDA的Web界面
- Hugging Face Space:在线体验平台
2. 开发者资源
- GitHub仓库:https://github.com/canopyai/Orpheus-TTS
- Hugging Face模型库:包含所有预训练模型
- 技术文档:详细的API文档和使用指南
- 社区讨论:活跃的GitHub Discussions
九、与主流TTS系统对比分析
1. 开源TTS模型横向对比
主流开源TTS模型对比表
| 模型名称 | 延迟(ms) | 语言支持 | 情感表达 | 声音克隆 | 开发活跃度 |
|---|---|---|---|---|---|
| Orpheus-TTS | 25-200 | 7种语言 | ⭐⭐⭐⭐⭐ | 零样本 | ⭐⭐⭐⭐⭐ |
| XTTS-v2 | 300-500 | 17种语言 | ⭐⭐⭐ | 6秒样本 | ⭐⭐⭐ |
| ChatTTS | 200-400 | 中英文 | ⭐⭐⭐⭐ | 不支持 | ⭐⭐⭐⭐ |
| MeloTTS | 150-300 | 多种语言 | ⭐⭐ | 不支持 | ⭐⭐⭐ |
2. 商业化TTS服务对比
与ElevenLabs、Azure Speech等商业服务相比,Orpheus-TTS在保持高质量的同时,提供了完全开源的解决方案,让开发者拥有更大的自由度和控制权。
十、总结
Orpheus-TTS的出现标志着开源文本转语音技术迈入了一个新的时代。它不仅在技术指标上实现了突破性进展,更重要的是为整个行业展示了大语言模型在语音合成领域的巨大潜力。
从超低延迟的实时响应,到情感丰富的人性化表达,再到零样本的语音克隆能力,Orpheus-TTS正在重新定义我们对AI语音技术的期待。对于开发者而言,这不仅是一个强大的工具,更是一个学习和创新的平台。
随着人工智能技术的不断发展,相信Orpheus-TTS将在智能客服、教育培训、内容创作等领域发挥越来越重要的作用,真正实现让机器拥有如人类般自然动听的声音这一愿景。
很感谢你能看到这里,如果你有哪些想学习的AI,欢迎在评论区分享!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)