(aaai2025) Towards Open-Vocabulary Remote Sensing Image Semantic Segmentation
1、背景
Open-Vocabulary 是一个比较火的话题,目前我找到最好的学习资料是 VALSE2024 上李冠彬老师的课程《开放词汇视觉感知》,视频链接:https://www.bilibili.com/video/BV1uf421d7Vk/ 三个多小时的课程系统的介绍了基于开放词汇的图像分类、目标检测、分割等任务。
开放词汇可以理解为是一种特殊的 zero-shot learning。 Zero-shot 是在别的类别(base)训练模型,可以识别没见过的类别(unseen),这里有一个严格的限制:unseen类别在训练时一定是不可见的。
开放词汇可以理解为更加宽松的zero-shot,预训练的多模态大模型(如ChatGPT,CLIP等)见多识广,能够在下游任务泛化。开放词汇的实现方法是:来自vision-language model (VLM) 的 text encoder 见过了很多的图像和文本,有很强的能力将它们对齐,也有很强的能力将 unseen的目标关联到对应的类别编码上。
2、研究动机与方法
在地震、洪水应急响应任务中,需要快速解译遥感图像。没有时间对大量数据进行标注与训练,这样研究开放词汇遥感图像语义分割就尤为重要。这个工作主要有两个贡献:
- 数据集:构建了LandDiscover50K,包含 51,846 张图像、40 个类别,覆盖多种遥感场景。
- 模型:提出GSNet框架,融合遥感领域先验(RSI specialist)和通用视觉语言模型(CLIP)的能力,通过 Dual-Stream Image Encoder (DSIE)、Query-Guided Feature Fusion(QGFF)和 Residual Information Preservation Decoder (RIPD)实现精准分割。
LandDiscover50K 数据集是现有多个遥感图像语义分割数据集的集成,这里不过多介绍。作者提出的 GSNet 还是受了CVPR2024的 CAT-SEG启发,不同之处是加了一个遥感图像编码器分支。GSNet 主要框架如下图所示,视觉特征编码器包括CLIP和RSI backbone,一方面利用通用特征,另一方也利用遥感图像的特有特征。
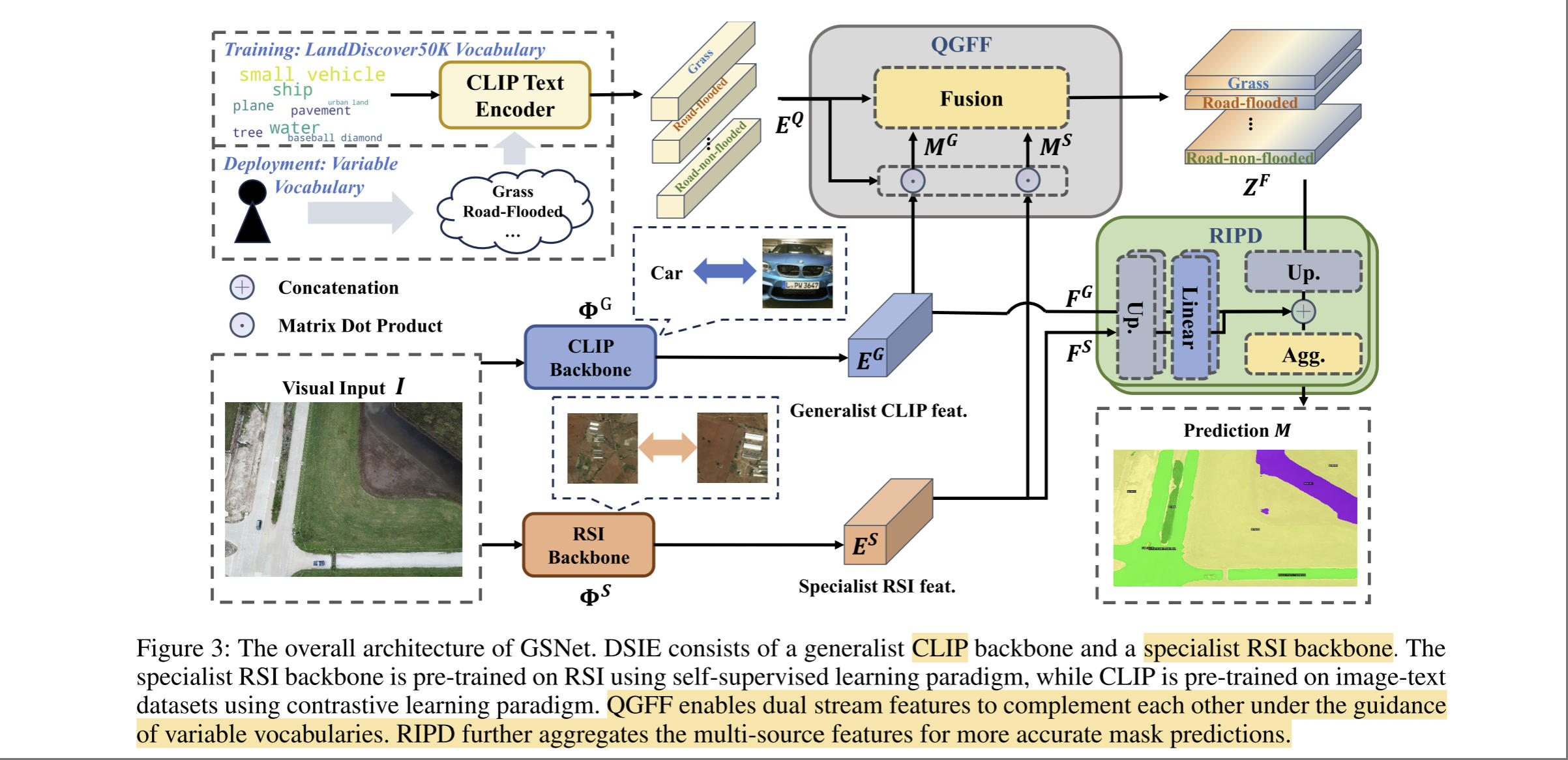
QGFF 实现图像和文本特征的融合,即计算图像和每个类的相似性。接着图像特征再与融合结果进一步精炼,通过一系列上采样与卷积,得到分割的输出结果。
实验部分可以参考作者论文,这里不过多介绍。