rStar-Math:蒙特卡洛搜索增强 LLM 逻辑推理能力
rStar-Math
- 论文大纲
- 理解
- 1. **Why:研究背景与所要解决的问题**
- 2. **Who:元数据信息**
- 3. **与前人工作的关系**
- 4. **总结归纳**
- 5. **What:论文核心发现或论点**
- 6. **How:研究方法与创新**
- 7. **How good:研究贡献与意义**
- 围绕 rStar-Math 的解法流程进行「连续提问」
- **问 1:rStar-Math 的最终目的是什么?**
- **问 2:它是如何让小模型也能达到高水平推理的?**
- **问 3:那中间步骤是怎么被“检查正确与否”的?**
- **问 4:PPM (过程偏好模型)评分时所依据的“分数” 或 “Q值”是怎么来的?**
- **问 5:为什么不直接把 Q 值当标签来训练过程奖励模型,而要做“偏好对” (Preference Pair)?**
- **问 6:在实际操作中,rStar-Math 是怎么收集到大量训练数据的?**
- **问 7:最终有什么效果?**
- **问 8:它为什么称为 “System 2 Deep Thinking”,与常规 “System 1” 有何不同?**
- **问 9:rStar-Math 流程中有提到“自我反思”(intrinsic self-reflection)的现象,是什么?**
- **问 10:那在应用层面,我该如何理解 rStar-Math 的价值?**
- 解法拆解
- 提示词
- DeepSeek-V2-Coder-Instruct 的 MCTS 提示(引导轮次)
- !!! 请记住:
- 模板结构:
- 示例1:
- 示例2:
- 提问
- 1. 关于数据合成规模与覆盖率
- 2. 关于子问题答案的准确性
- 3. 关于过程偏好模型 (PPM) 的噪声问题
- 4. 关于自发的“自我反思”现象
- 5. 关于“多轮自进化”与过拟合
- 6. 关于终端节点正确率与中间步骤正确率的权衡
- 7. 关于大模型与小模型的性能上限关系
- 8. 关于多语言或多文化背景的数学题
- 9. 关于多步推理的时空成本
- 10. 关于 PPM 的多样性与鲁棒性
- 11. 关于搜索深度与推理深度的差异
- 12. 关于负面数据与训练稳定性
- 13. 关于人类标注的角色
- 14. 关于可移植性到其它领域
- 15. 关于自进化的终止条件
- 16. 关于小模型初始水平和 bootstrap 依赖
- 17. 关于大模型蒸馏和这个方法的对比
- 18. 关于多次随机种子与重复搜
- 19. 关于过程监督的抽象层次
- 20. 关于与树状搜索的潜在冲突
论文:rStar-Math: Small LLMs Can Master Math Reasoning
with Self-Evolved Deep Thinking
代码:https://github.com/microsoft/rStar
论文大纲
├── 1 引言【研究背景与动机】
│
│ ├── 小模型(SLMs)在数学推理中的应用【现状】
│ │
│ ├── 现有方法对强大教师模型(如GPT-4)的依赖【问题】
│ │
│ └── 提升小模型自主推理能力的必要性【动机】
│
├── 2 相关工作【研究基础与对比】
│
│ ├── Math Data Synthesis【数据增强方法】
│ │ ├── GPT蒸馏(如GPT-4 产出CoT)【常见做法】
│ │ └── 其局限:数据质量受限于教师模型【不足】
│ │
│ ├── Test-time Compute Scaling【推理范式转变】
│ │ └── 系统2推理带来的性能提升【优势】
│ │
│ └── Reward Model研究【评价机制】
│ ├── Outcome Reward Model(ORM)【只看最终答案】
│ └── Process Reward Model(PRM)【逐步评估过程】
│
├── 3 方法论【rStar-Math的核心方法】
│
│ ├── Monte Carlo Tree Search(MCTS)【搜索框架】
│ │ └── 逐步生成并回溯,增强解题深度【核心机制】
│ │
│ ├── 代码辅助的多步验证(Code-augmented CoT)【关键技术】
│ │ └── 用Python执行中间步骤,过滤错误推理【质量保证】
│ │
│ ├── Process Preference Model(PPM)【过程偏好模型】
│ │ ├── 不直接使用Q值打分,而是进行正负对比【训练策略】
│ │ └── 对每个推理步骤给出偏好排序【细粒度评估】
│ │
│ └── 多轮自我进化(Self-Evolution)【迭代提升】
│ ├── 循环生成→训练→再生成【流程】
│ └── 逐步覆盖更高难度题目【扩展性】
│
├── 4 实验【性能评测与结果】
│
│ ├── 基准测试:MATH、AIME、Olympiad等【测试范围】
│ │ ├── 多个规模的小模型(1.5B-7B)【对比模型】
│ │ └── 与OpenAI o1等先进LLM的对比【对比目标】
│ │
│ ├── 与Best-of-N、GPT蒸馏等方法对比【对照实验】
│ │ └── 显示rStar-Math可优于更大规模模型【实验结论】
│ │
│ └── 展示在不同推理轨迹数量(如64条)下的表现【测试细节】
│
├── 5 发现与讨论【关键洞察】
│
│ ├── 小模型在多步推理中出现自反思(self-reflection)【意外发现】
│ │ └── 纠正之前步骤中的错误并找出新思路【机制分析】
│ │
│ ├── PPM对中间关键步骤(如应用定理)更敏感【偏好特征】
│ │
│ └── 奖励模型在系统2推理中决定性能上限【影响因素】
│
└── 6 总结【研究意义与展望】├── rStar-Math成功验证:小模型具备深度数学推理潜力【结论】 │ ├── 对其他领域的启示:可扩展到代码、通用推理【应用前景】 │ └── 后续工作:融入更多验证机制与更多题目集【未来方向】
核心方法:
├── 核心方法【顶层概念:rStar-Math整体方案】
│
│ ├── 输入【模型与数据】
│ │ ├── 小模型(SLM)【初始策略模型】
│ │ │ └── 如Qwen2.5-Math-7B、Phi3-mini-Instruct等【示例实例】
│ │ └── 747k数学题目【数据集】
│ │ ├── 题目范围:基础到奥赛级【多难度覆盖】
│ │ └── 标注信息:正确答案(终端标签)【用于验证】
│
│ └── 处理过程【技术与方法的衔接】
│ ├── (A) Monte Carlo Tree Search (MCTS)【搜索策略】
│ │ ├── 分步生成 (step-by-step generation)【子过程】
│ │ │ └── 在每一步由策略模型(SLM)输出若干候选解【并行搜索】
│ │ ├── 代码执行过滤 (code-augmented CoT)【质量保证】
│ │ │ └── 对每步生成的Python代码进行实际运行,筛掉执行失败或无效步骤【错误剔除】
│ │ ├── Q-value自适应更新【回溯机制】
│ │ │ ├── 终端奖励:答案正确为+1,错误为-1【基础打分】
│ │ │ └── 在每一次回溯时,统计能否达成正确解,从而更新中间步骤Q-value【强化正确路径】
│ │ └── 与过程奖励模型(PPM)的结合【深度搜索】
│ │ └── 搜索时用PPM评估每步生成质量,让MCTS更快找到正确方向【辅助选择】
│ │
│ ├── (B) Process Preference Model (PPM)【过程偏好模型】
│ │ ├── 训练数据构造:基于MCTS轨迹的正负对比【监督方式】
│ │ │ ├── 从同一题目的正确轨迹里选高Q-value步骤为“正例”【正偏好】
│ │ │ └── 从错误轨迹或低Q-value步骤里选“负例”【负偏好】
│ │ ├── Pairwise Ranking Loss【损失函数】
│ │ │ └── 不直接回归数值Q值,而是学习“正例得分 > 负例得分”【避免噪声】
│ │ └── 评估单步CoT的质量,从而对后续搜索形成过程级奖励【核心作用】
│ │
│ ├── (C) 多轮自我进化(Self-Evolved Deep Thinking)【迭代框架】
│ │ ├── Round 1: 初始化并用大模型或初版SLM做MCTS【初始数据】
│ │ ├── Round 2: 用更新后的SLM + 终端奖励方式精炼训练【增强】
│ │ ├── Round 3: 结合PPM评分 + 终端奖励双重导向【更强质量】
│ │ └── Round 4: 持续扩充高难度题,最终形成高覆盖高质量数据【收敛】
│ │
│ └── (D) 整合工作流【衔接方式】
│ ├── SLM作为生成器 → 生成多步推理 → 代码过滤 → 过程奖励PPM打分 → MCTS回溯更新【主循环】
│ └── 在自我进化的每一轮,都将最优轨迹用于SFT训练SLM与训练PPM【数据闭环】
│
│ └── 输出【结果与产物】
│ ├── 完整的“分步验证”推理数据【训练数据】
│ │ ├── 高质量CoT轨迹:每一步都有代码验证【可信度高】
│ │ └── 精准Q-value标签或正负偏好对【PPM学习依据】
│ ├── 进化后的强大小模型(SLM-rStar)【推理主体】
│ │ └── 已学会系统2推理,通过MCTS+PPM实现高水平解题【目标达成】
│ └── 在真实推理时的正确答案【最终输出】
理解
1. Why:研究背景与所要解决的问题
- 研究要解决的核心问题
大多数数学推理任务需要多步的演绎和严谨的中间验证。
而目前主流的数学大模型(如GPT-4、OpenAI o1 等)虽然在解决数学问题上已表现出一定实力,但常依赖于大规模参数、昂贵的推断成本或从更强大模型的蒸馏,这些都并非在资源受限场景下的理想方案。
论文希望探索 “小模型(Small LLMs)如何通过自我迭代进化,达成与大型模型比肩甚至部分超越的数学推理能力”。
-
具体要解决的问题
- 如何在资源相对有限的小模型(1.5B ~ 7B规模)上,通过“多步深度推理(System 2)”增强模型在数学推理中的准确率?
- 如何在没有高质量人工标注或者没有更强模型提供优质中间解答的情况下,自行合成高质量训练数据,进而培养出可准确识别与评价推理过程(Process)的过程奖励模型?
-
类比理解与正反例
- 正例(成功示范):将一个7B的LLM通过多轮自进化训练,最终可在竞赛水平的数学题(如AIME、MATH等)上接近或优于 o1-preview、GPT-4o 等成绩,且只需同数量级的推断资源。
- 反例(失败示范):如果只让小模型一次性输出所有推理步骤(类似常见的Chain-of-Thought一次成文),无额外的筛选与搜索机制,它往往会在中间步骤犯错并难以及时纠正,导致答题正确率很难大幅提升;或者如果仅依赖自洽(self-consistency)的简单抽样方法,也难以提供高质量的中间验证,错误率依旧偏高。
2. Who:元数据信息
- 论文提出 rStar-Math 方法,通过小模型在推理时采用蒙特卡洛树搜索(MCTS)的多步深度推理策略,配合过程偏好模型(Process Preference Model, PPM)对每一步推理进行细粒度评价与筛选,最终实现“自进化”(自举多轮迭代)的大幅性能提升。
- 实验结果显示,该方法可使7B及更小规模模型在诸多数学竞赛数据集(MATH、AIME、Olympiad Bench等)上取得超过 80~90% 的正确率,部分结果可比肩或超越 OpenAI o1-preview 等强力闭源模型。
3. 与前人工作的关系
-
与大型模型蒸馏或GPT-4 辅助数据合成的对比
过往工作(如WizardMath、NuminaMath、MetaMath等)多通过 GPT-4 等更强模型来自动生成数学训练数据,但是这会“限制”在老师模型能解题的范围内,且难以保证中间推理每一步均准确。
rStar-Math 则摒弃高性能教师模型,主打“小模型自进化”思路,即完全依靠自有模型和代码验证来淘汰错误步骤。
-
与单次推理(System 1)或只做少量抽样/自洽的对比
很多系统(如Best-of-N或self-consistency)只是在最后答案做筛选,缺乏对中间步骤的精细把关。
而 rStar-Math 明确地将多步推理拆分并在每步执行后,通过 PPM打分或代码执行结果来更新和回传奖励,从而提供更加精细的过程监督。
-
与已有的过程奖励模型(Process Reward Model)
过去的一些工作(如PRM、step-by-step verification 等)通常需要人工做密集标注,或直接用Q值做得分,受噪声影响大。
本文提出以“偏好对(preference pairs)”替代直接回归Q值,使得训练出的过程偏好模型(PPM)在细粒度鉴别正确/错误步骤时更加稳定。
4. 总结归纳
-
主要收获
- 核心: 小模型亦可通过多轮“搜索+自进化”获得高质量的数据与过程监督,从而在数学推理性能上逼近乃至超越部分大模型。
- 亮点: 与常规的GPT-4蒸馏数据相比,文中提出的“代码验证+MCTS Q值滤波”能生成更精确、更大规模的中间推理步骤,为模型提供了更丰富的训练信号。
-
进一步探索的问题
- 自进化方法是否能普适到其他领域的推理(例如编程题、常识推理、多模态推理)?
- 面对需要几何可视化或更深层抽象证明的奥赛题,是否还需额外的图形检测/定理库工具辅助?
- 是否存在一种方式,让过程偏好模型(PPM)能同时捕捉多种类型错误的严重度并在多维度打分?
5. What:论文核心发现或论点
-
多轮自进化(self-evolution)的有效性
论文在多达4轮的自进化中,平均能覆盖超过90%的收集到的竞赛级问题(如奥赛题),并不断淘汰先前轮次的噪声中间步骤,形成高质量、高难度的训练集。
-
小模型也可逼近o1 乃至超越GPT-4o
在 MATH、AIME、Olympiad Bench 等高难度数据集上,经过System 2深度推理的 7B 模型在多数指标上超过或接近了 o1-preview、Claude 3.5-Sonnet 等较强闭源模型。
-
过程偏好模型(PPM)的关键作用
相较于只在答案阶段过滤(Outcome RM)或仅用Q值回归(PQM),采用正负偏好对来训练PPM在指引多步推理时效果更优。
同时还观察到模型会在推理时自发地产生“自我反思”现象,即在中途推理发现方向不对时,会回退并尝试新的思路。
6. How:研究方法与创新
-
前人研究局限性
- 依赖更强模型的蒸馏,无法解决更强模型本身也无法解出的难题;
- 缺乏对推理过程的精细把关(很多只在最后筛答案)导致中间错误累积;
- 过程奖励模型难以大规模、高精度地获取训练信号。
-
创新视角
- (1)代码增强的CoT生成:每一步的自然语言思路都附带Python代码实时执行,若代码无法跑通或结果冲突则直接过滤;
- (2)利用Monte Carlo Tree Search(MCTS) 进行多条路径探索,并将正确率高的轨迹自动赋较高Q值,从而形成高质量的自标注数据;
- (3)提出了“过程偏好模型PPM”:用正负偏好对代替直接的Q值标注,在训练中极大减少了噪声影响,使得模型能准确地判别正确/错误或有价值/无价值的中间步骤;
- (4)多轮自进化:每一轮用最新的模型去推理并生成更多高难数据,然后再用这些数据反过来训练下一个更强的模型与奖励模型,如此循环。
-
关键数据支持
- 收集了 747k 大规模数学题库(含奥赛、AIME 竞赛以及GPT-4合成题),经过第4轮自进化后约 90% 问题都有正确解;
- 在AIME 2024 真题集上,模型可解出超过 50% 的题,相当于在顶尖高中生群体里也能排到 Top 20% 名次。
-
潜在反驳及应对
-
反驳:小模型对非常高级数学定理仍会缺少语义理解,生成的中间步骤其实只是“模式匹配”而非真正推理。
- 应对:文中以代码执行和PPM筛选相结合的方式在一定程度上保证“正确性”和“一致性”。而且在部分代数/数论/平面几何题目里,模型确实能反复更正错误思路并给出合理逻辑。
-
反驳:MCTS消耗的推理资源过大,性价比可能低于直接扩大小模型或换用大模型。
- 应对:在作者的实验中,使用 7B 模型+4轮自进化,硬件上也比调用更大闭源模型来蒸馏要经济得多,对于很多团队来说可行性更好。
-
7. How good:研究贡献与意义
-
理论贡献
- 提出了面向数学推理的“自进化”范式,将Monte Carlo Tree Search与过程偏好模型结合在小模型中,实现了无高端教师模型/大量人工标注也能不断逼近SOTA。
- 在推理可控性方面,展示了过程监督能够自然催生出“自我反思”特性,为研究“模型如何在推理中自我纠错”提供了可行路径。
-
实践价值
- 令研究者和开发者在缺乏大算力或高级教师模型的场景下,也能够构建高准确度的数学问题解答系统,对教育领域(在线作业批改、教学辅导)等极具价值;
- 多步推理与自我监督的思路还可迁移到代码生成、法律推理、财务分析等对中间步骤有强需求的场景。
围绕 rStar-Math 的解法流程进行「连续提问」
rStar-Math本质上是一种思路,我只需要知道每次探索的结果是对还是错就可以应用。
当最终结果正确时,我就认为这次探索中的每个步骤都有贡献,就会返回给它们打分,然后进行更多探索。
如果中间某个节点每次都能导向正确答案,那可能是个正确步骤;如果经常导向错误答案,可能就是错误步骤。
打完分后,我就能收集数据构造过程奖励模型,这就是rStar-Math的核心思想。
它唯一的门槛是在探索到根节点时需要判断这次outcome是否正确,这个门槛并不高,所以应用场景其实很广,泛化性没有问题。
问 1:rStar-Math 的最终目的是什么?
答 1:想让体量更小的语言模型(Small LLMs)在数学解题上,达到或超越类似 GPT-4 / OpenAI o1 这样大型模型的推理水平。
问 2:它是如何让小模型也能达到高水平推理的?
答 2:主要通过一种称为 蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS) 的多步生成过程,让模型在“中间步骤”就能检查是否正确,而不是只在最终答案时做筛选。
关联知识点:
- 蒙特卡洛树搜索的基本流程:Selection / Expansion / Rollout / Backpropagation。
- 为什么只在「最终答案」层面验证不够?因为数学推理中间一环出错就可能导致后续推理全错。
问 3:那中间步骤是怎么被“检查正确与否”的?
答 3:rStar-Math 采用了两个机制:
- 代码验证(Code-augmented CoT):每一步除了自然语言推理外,会附带 Python 代码一起执行;如果代码报错,或者跑出的数值和题意不符,就能及时过滤掉。
- 过程偏好模型(Process Preference Model, PPM):它给每个中间步骤打分,辅助搜索算法判断走哪条分支更可能得到正确答案。
关联知识点:
- “Code-augmented CoT”属于一种“边思考边运行”的过程,可以有效减少纯文本推理中的臆断或计算失误。
- 过程偏好模型(PPM)与传统只关注最终结果的奖励模型(Outcome RM)区别在于,它能提供“细粒度”的分步评价。
问 4:PPM (过程偏好模型)评分时所依据的“分数” 或 “Q值”是怎么来的?
答 4:
- 在 MCTS 中,如果一个分支最终能走到正确答案,那么该分支中每一步累积得到的
Q值会随回溯而增加;如果分支最终错误,则Q值会随回溯而扣分。 - 此外,PPM 在第三/四轮训练时,还会初步预测每一步的好坏,给出“初始 q 值”,再被 MCTS 的多轮搜索不断修正。
关联知识点:
- 与 AlphaGo 等博弈类 MCTS 类似,自我对局或自我验证的过程可以不断更新每一步的价值估计。
- 当我们采样更多轮,就能更稳健地给每个节点/步骤打出准确分值。
问 5:为什么不直接把 Q 值当标签来训练过程奖励模型,而要做“偏好对” (Preference Pair)?
答 5:
- 因为绝对的Q值可能包含噪声:一次搜索样本有限,某些本来不错的中间步骤也许偶然没有搜到正确结论,导致 Q值偏低,或反之。
- 用“偏好对”就只需要知道「哪个步骤更优 / 哪个步骤更差」,做二元对比(rank loss),更稳定、更少受噪声影响。
关联知识点:
- 类似于「人类反馈」(RLHF)里,人对两个回复进行偏好判断,比给绝对分数要更准确、容易操作。
- 排序学习(Pairwise Ranking)的常见做法:Bradley-Terry 模型或类似的一些对比损失函数。
问 6:在实际操作中,rStar-Math 是怎么收集到大量训练数据的?
答 6:
- 首先,准备了一个 747k 规模的数学题库(包含真实竞赛题 + GPT-4 生成的题)。
- 每一轮用已有模型跑 MCTS 生成完整的「步骤式解题+验证」轨迹,再把其中「正确+高 Q值」的轨迹保留下来做新一轮的 SFT(监督微调)和 PPM 训练数据。
- 总共迭代了 4 轮,越到后面,“模型水平越高+验证越严格”,能解出的题目和中间解题质量就越好,形成一个正循环。
关联知识点:
- 这是一个“自进化”或“自举” (bootstrapping) 思想:先用一个初始政策模型解简单题,得到一批相对干净的数据,然后用这批数据再去解更难的题……如此循环。
- 如果有些题实在太难,前几轮没能成功解出来,后面的模型更强时可能就能攻克,从而收录在训练集。
问 7:最终有什么效果?
答 7:在多个难度较高的比赛数据集上(如 MATH、AIME、Olympiad Bench),小模型(7B)都能达到和 OpenAI o1-preview 或更大模型相当甚至更好的成绩,比如在 MATH 上可达 90% 左右准确率,在 AIME 真题上能够解对 50%(相当于美国高中顶尖学生前 20% 水平)。
关联知识点:
- AIME(美国高中数学竞赛)一般都是难度相当高的题目,大模型能解对一半已经非常可观。
- MATH 数据集是一个典型的竞赛数学题集,用来检验模型的多步推理能力。
问 8:它为什么称为 “System 2 Deep Thinking”,与常规 “System 1” 有何不同?
答 8:
- “System 1” 往往指一次性输出整段 Chain-of-Thought,不做多样化探测,也不对中间步骤进行细化验证,速度更快但易出错。
- “System 2” 则模拟人类仔细思考过程:慢慢分解问题,每走一步都能检查,这实际上是一种搜索+评估式的深度推理,也被称作“深度思考 (Deep Thinking)”。
关联知识点:
- 心理学中,Daniel Kahneman 提出的 System 1 / System 2 理论:前者是快速直觉型思维,后者是慢速、谨慎、可校验的思维。
- 机器翻成“多轮推敲”,本质就是尝试 + 验证 + 纠错。
问 9:rStar-Math 流程中有提到“自我反思”(intrinsic self-reflection)的现象,是什么?
答 9:
- 指模型在某一步意识到当前思路不对(常由 PPM 或代码报错判断出),它会“回退”或“放弃”这条思路,另辟蹊径;这有点类似人类解题时的“嗯,我这步好像错了,重来一下”。
- 作者在文中通过示例展示,当小模型搭配 MCTS + PPM 时,就自发出现了“尝试→错误→修正”的行为,而无需专门写“我需要先反思一下”的提示词。
关联知识点:
- 在过去,大模型要实现 self-reflection 常常需要手动写提示,如“Let’s reflect on the previous step…”。
- rStar-Math 借助过程打分和搜索,使小模型也能自然学到这种纠错机制。
问 10:那在应用层面,我该如何理解 rStar-Math 的价值?
答 10:
- 对缺乏大算力或 GPT-4 API 的团队来说,能用更小型号(7B 或 3B)也做到难题解答。
- 框架通用:未来如果扩展到编程推理、法律推理,或者与外部工具交互等,这种“多步搜索 + 过程验证 + 自迭代”也很适用。
关联知识点:
- 类似手法也可在自动定理证明、机器人规划等需要中间步骤严谨性的任务中使用。
- 关键前提:必须有一种能够“反馈或验证中间步骤对错”的方式(如可执行代码、测试用例、互相佐证等)。
解法拆解

rStar-Math整体框架示意:
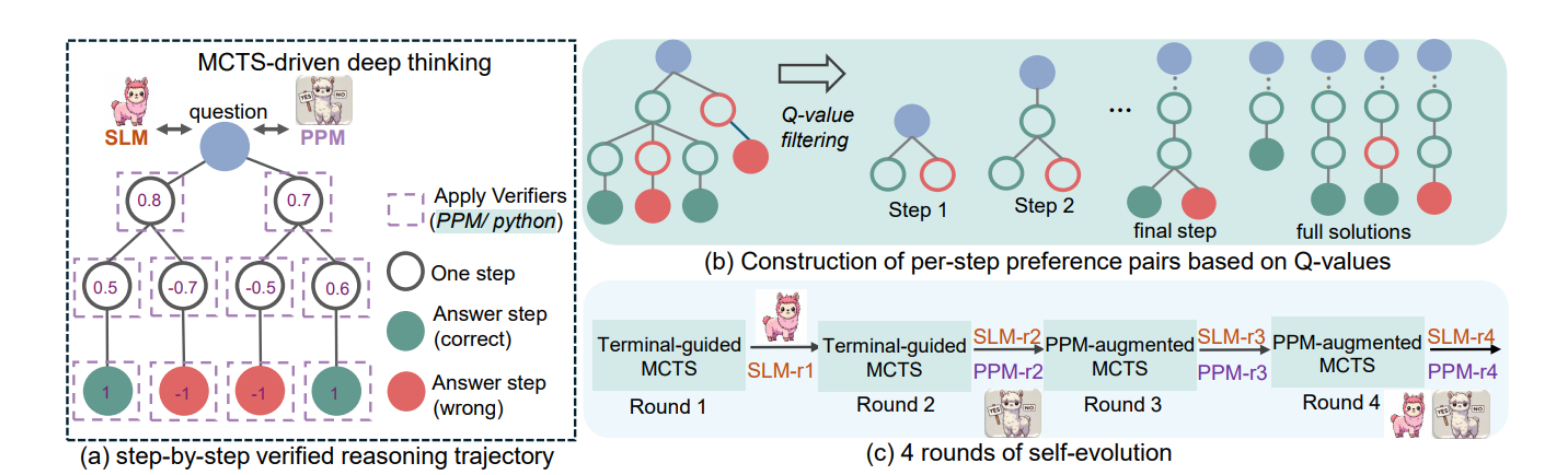
-
左侧 (a) sub-figure:
- 这是一个“单题多步搜索”示意图。根节点是问题 (question),往下每个节点代表模型生成的一小步推理(一步 CoT+对应的Python代码),而节点之间的分叉则表示不同候选的“下一步”解题思路。
- 节点上标出的数字如 0.8、-0.7、0.6 等,是由 过程偏好模型(PPM) 输出或经过回溯修正后的 Q 值,用来衡量该步推理在通往正确解答中的“价值”。
- 绿色节点表示“正确答案”,红色节点表示“错误答案”。在树形搜索(MCTS)过程中,系统会对这些节点进行反复评估与回溯更新,以决定哪条分支更值得继续展开。
- 另外,作者还在步骤中使用了 Python代码(或者PPM)做验证(小框中“Apply verifiers”),如果某一步执行代码出错,或得分偏低,就可能被剪枝或忽略。
-
右侧 (b) sub-figure:
- 图示了如何基于 Q 值构造“每一步的偏好对 (preference pair)”。即:对每个中间节点,根据它在多次搜索中得到的 Q 值,从而挑选出正样本(高Q值)和负样本(低Q值),形成正负成对,用来训练 PPM。
- 这些正负对让PPM学会区分“好一步”和“坏一步”,而不仅仅是“好的最终答案”和“坏的最终答案”。因此称之为 过程级 或 step-level 的监督。
-
下方 © sub-figure:
-
展示了 4 轮自进化 (self-evolution) 的流程:
- 第1轮采用简单的“terminal-guided MCTS”(即只有最后答案对错的回溯),训练出 SLM-r1;
- 第2轮继续“terminal-guided MCTS”并得到更多数据,训练出 SLM-r2、PPM-r2;
- 第3轮开始用“PPM-augmented MCTS”,将PPM分步打分融入搜索,迭代出 SLM-r3、PPM-r3;
- 第4轮再重复该过程,最终得到性能更高的 SLM-r4、PPM-r4。
-
通过这种多轮循环,模型能力和PPM质量不断提高。
-
从这幅图能看出,rStar-Math 核心是把“多步深度推理(MCTS)”与“细粒度过程监督(PPM)”结合起来,并且在大规模题目上反复迭代,形成了自举式的高质量训练数据和更强的推理能力。
-
子解法1:MCTS(多步搜索)
- 因为问题特征:竞赛级数学题需要逐步拆解、若只依赖一次性生成(System 1),经常在中间环节出错且无法回溯。
- 之所以用 MCTS:可以把整道题的“推理”拆成多步,每一步做决策和打分,若某一路径质量高则继续扩展,低则抛弃;同时还能保留多条候选路径比对。
-
子解法2:代码执行校验(Code-augmented CoT)
- 因为问题特征:数学中常有算式推断、数值实验,或者需要对中间结果做验证;纯自然语言易出现逻辑/算数错误。
- 之所以用代码校验:让每一步产出 Python 代码并执行,以排除无意义或错误的中间结论;可大幅减少错误传递。
-
子解法3:过程偏好模型(Process Preference Model, PPM)
- 因为问题特征:若只用“最终答案对不对”做奖励,无法区分“中间步骤的好坏”;需要更精细的过程监督。
- 之所以用 PPM:它能对每个中间步骤(节点)进行打分或排名,通过“偏好对”来训练其判断优劣——从而让 MCTS 更快收敛到正确路径。
-
子解法4:多轮自进化训练
- 因为问题特征:高难度题目数据稀缺,且答案常不完善;需要在初始基础上逐轮“滚雪球”式地生成更大量、高质量的解题轨迹。
- 之所以用自进化:前一轮产生的高质量解答可做下一轮的 SFT(Supervised Fine-tuning)数据,并不断解开更多更难的题、提升模型能力。
具体题目示例与“自我反思”现象:
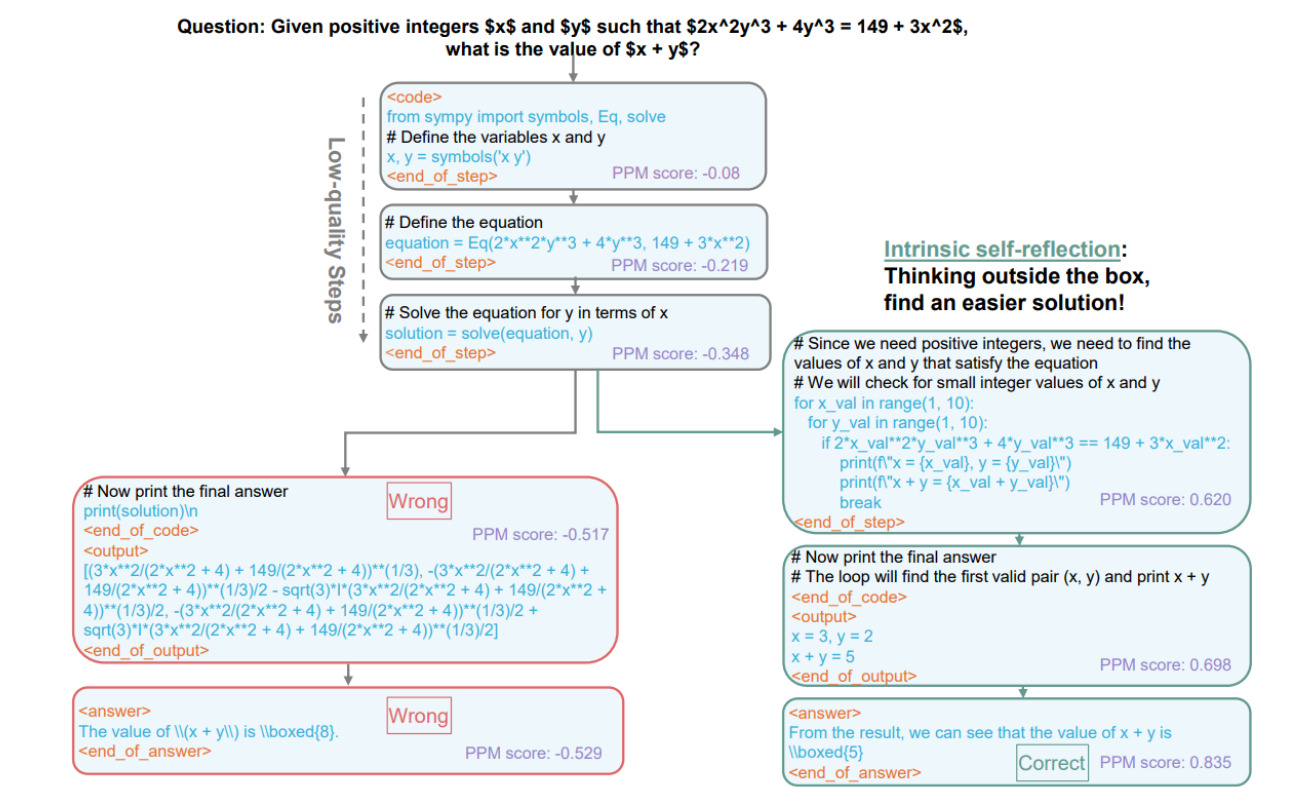
-
题目及初始思路
-
问题是:给定正整数 x x x 和 y y y,满足 2 x 2 y 3 + 4 y 3 = 149 + 3 x 2 2x^2y^3 + 4y^3 = 149 + 3x^2 2x2y3+4y3=149+3x2,求 x + y x + y x+y。
-
左侧灰色流程中,最开始三步(浅蓝框)是模型的一组“错误”思路:
- 第一步:导入
sympy并定义变量; - 第二步:建立方程
equation = Eq(2*x^2*y^3 + 4*y^3, 149 + 3*x^2); - 第三步:用
solve(equation, y)或solve(equation, x)试图符号求解; - 这些步骤的 PPM 打分相对较低(-0.08、-0.219、-0.348…),并未能直接得到一个干净的整数解,甚至跑出了很复杂的根式。
- 第一步:导入
-
当输出结果时,最终答案错误(PPM 评分也更低,如 -0.517、-0.529)。这条分支被视为“不理想”或低质量路径。
-
-
右侧绿色流程中的“自我反思”
- 接着模型做了另一条思路:用一个循环,遍历 x , y x, y x,y 在 [1, 10) 的整数范围,检验是否满足方程。
- 在找到
(x=3, y=2)时,得到x+y=5,这才是正确解。 - 作者在图中标注 “Thinking outside the box, find an easier solution!” 表示模型似乎主动“放弃”纯符号法,改用暴力穷举检验,这种切换就类似“自我反思”。实际上是因为 PPM 对前面步骤打出低分,因此 MCTS 将注意力转移到新的、更高分的候选步骤上。
- 最终结果答案是对的( 5 \boxed{5} 5),并对应的PPM分数显著更高(0.620、0.698、0.835)。
-
背后机制
- 图中每一步都显示了 PPM (Process Preference Model) 对该步骤的打分;一路分数低走向错误,一路分数高且能找到正确解。
- 这反映了 rStar-Math 中的分步验证(代码能正确执行 & 假设检验能通过)+ 过程奖励(PPM评分)如何引导模型跳脱局部错误,尝试并最终收敛到可行解答。
通过这个案例,作者想说明——在 MCTS+PPM 的框架下,LLM 的推理过程不再是“一次性写完”或“全凭运气猜最后答案”,而是可以在中间就筛掉低质量思路,转向更优策略,进而得到严谨或更易实现的解题路径。
这种在外观上类似“自我纠错”“自我反思”的行为,实际上源于搜索与过程奖励的动态结合。
提示词
DeepSeek-V2-Coder-Instruct 的 MCTS 提示(引导轮次)
你是一位拥有广泛数学知识和出色 Python 编程能力的强大智能体。你需要使用 Python 解释器准确地计算数学方程。
!!! 请记住:
- 使用代码一步步解决问题。解决方案应包含三个部分:
<code>、<output>和<answer>。 - 所有计算都应以 Python 代码完成。请用注释清晰说明推理和逻辑过程。
- 最常用的相关 Python 包包括
math、sympy、scipy和numpy。 - 请使用如下模板:
模板结构:
问题: 输入问题
<code> 构建代码,使用 <end_of_step> 表示每一步结束。确保代码能正确运行(不包括 <end_of_step>),避免未定义变量、导入错误包或语法错误。最后一步打印结果,并加一句注释:Now print the final answer.
<end_of_code>
<output> 执行代码后的输出。
<end_of_output>
<answer> 简明回答问题,仅输出数值(如果是选择题)。
<end_of_answer>
示例1:
问题: 特雷尔通常使用两个20磅的哑铃做12次。如果他改用两个15磅的哑铃,为了举起相同的总重量,他需要做多少次?
# 步骤1:计算使用两个20磅哑铃时的总重量
total_weight_20 = 2 * 20 * 12
<end_of_step># 步骤2:计算每次举两个15磅哑铃所产生的重量
weight_per_rep_15 = 2 * 15
<end_of_step># 步骤3:计算需要多少次才能举起相同的重量
reps_needed = total_weight_20 / weight_per_rep_15
<end_of_step># 打印最终答案
print(reps_needed)
<end_of_code>
<output>16.0<end_of_output>
<answer>从结果可以看出,特雷尔需要举15磅哑铃**16次**才能举起相同的总重量。
<end_of_answer>
示例2:
问题: 求满足 3 x + 5 6 x + 5 = 5 3 \sqrt{\frac{3x+5}{6x+5}} = \frac{\sqrt{5}}{3} 6x+53x+5=35 的 z 值,用最简分数形式表示。
from sympy import symbols, Eq, solve, sqrt# 定义变量 x
x = symbols('x')
<end_of_step># 定义方程
equation = Eq(sqrt((3*x + 5) / (6*x + 5)), sqrt(5) / 3)
<end_of_step># 解方程
solution = solve(equation, x)
<end_of_step># 打印结果
print(solution)
<end_of_code>
<output>[20/3]<end_of_output>
<answer>从结果可以看出,x 的值为 \(\boxed{\frac{20}{3}}\)。
<end_of_answer>
提问
1. 关于数据合成规模与覆盖率
问:作者在第 4 轮自进化后提到,其 7B 模型成功覆盖了约 90.25% 的 747k 题库,这里“覆盖”具体是指什么?是每题都能产出一个最终可用、且被验证正确的解法吗?如果剩余 9.75% 没被覆盖,是什么原因导致没能成功?
答:
“覆盖”指对每道题都至少找到了一个正确且通过验证的解答序列(且中间步骤无严重报错)。对于没被覆盖的约 9.75%,作者在文中(见第四轮部分)提到主要有两大原因:
- 部分合成题本身就是错误标注或无解;
- 即便题目可解,但在有限次数的 MCTS + 代码执行检验中未搜到正确路径。
作者抽样审查了若干道未被覆盖的题,其中大多数都属于数据源存在错误或标注不一致的问题。
2. 关于子问题答案的准确性
问:作者在引入“代码执行 + PPM 评估”来过滤掉错误或无意义的中间步骤。然而在很多奥数题或竞赛题中,往往无法单纯依靠数值计算来验证正确性(如复杂几何、抽象代数命题)。这个环节如何保证“代码执行”就能筛掉逻辑错误?
答:
作者在正文中承认,“代码验证”更适合可数值计算或可模拟的题目类型。
如果题目过于抽象、难以直接用 Python 代码数值求解,就会出现仅能部分验证或验证力度不足的情况。
这时主要依赖 PPM 的“偏好对(preference pair)”判断以及 MCTS 的多次反复尝试,在一定程度上补偿了“代码验证”不全面的不足。
但如果题目需要更高层次的纯符号推理,现阶段的做法确实存在局限性。
3. 关于过程偏好模型 (PPM) 的噪声问题
问:PPM 在训练时是以“偏好对”来代替直接回归 Q 值,这种做法虽然减少了噪声干扰,但如果某些优质路线由于采样不充分而未被发现,PPM 是否会将它们错误地视为负例?
答:
作者确实提到 Q 值本身就含一定随机性,所以直接回归数值可能更受噪声影响。
引入“偏好对”的确可以减少过分依赖绝对值。但作者也承认,如果在搜索时没能充分探索某条优质路径,该路径就不会进入 PP 对比列表里。
解决之道是通过多次 MCTS rollout 增加探索度,以及在多轮自进化里逐渐弥补早期的探索盲区。
不过仍然无法 100% 杜绝这种“漏评”现象。
4. 关于自发的“自我反思”现象
问:文中案例显示,模型似乎会“意识到前面步骤可能有问题,然后回退重来”,类似“自我反思”。可这实际上是不是只是一种在蒙特卡洛树里重新选择分支的过程?它是否真正具备“元认知”?
答:
论文没有声称它真正具备强“元认知”或“真正自省”,只是观察到在 MCTS 不断回溯和 PPM 动态打分的作用下,表现上类似人类解题时的“先尝试,发现不对就回退再来”。
作者更倾向将其视作“搜索 + 过程奖励”下的自然涌现,而非额外显式编写的 prompt 自反思机制。
5. 关于“多轮自进化”与过拟合
问:多轮自进化(4轮)会不会造成模型在那 747k 题库上“死记硬背”,从而过拟合到特定题目,而不具备真正的泛化推理能力?
答:
作者在实验部分安排了多种外部基准(如 Olympiad Bench、AIME 2024 等)来验证泛化性能,发现依旧能维持高准确率。
虽然仍难以排除出现某些题型或解题模式的“记忆”,但在整体指标上,模型在未见过的新题或变形题上依旧保持高水准,说明并未完全陷入过拟合。
此外,作者特别指出这 747k 题库来源非常多样,囊括不同竞赛、难度、甚至 GPT-4 生成题,对训练的多样性也有帮助。
6. 关于终端节点正确率与中间步骤正确率的权衡
问:在每次 MCTS rollout 过程中,对于一个可能推导正确结论、但中间步骤存在少量错误推理片段的情况,作者是如何处理的?是否会被判为“半对”还是直接过滤掉?
答:
作者采用了“step-by-step verified”策略:只有当中间步骤也能通过代码执行或 PPM 正面评价时,才视为有效节点。
换言之,如果中途“跳跃”到正确结论却带了错误中间推理,通常会被剔除或得分很低。
作者在文中指出,这样做保证了训练时“正确答案 + 高质量中间链条”一同出现,提升模型的真实推理能力,而非仅靠碰运气猜对结论。
7. 关于大模型与小模型的性能上限关系
问:Paper 标题声称“小模型可以与 o1-level 的大模型比肩甚至超越”。是否存在题目超越了 GPT-4 或 o1 的能力边界,导致小模型都能解,而 o1/gpt-4 没有解出来?这听起来不太合理。
答:
作者的意思并非“小模型样样都比大模型强”,而是指某些题型或在平均指标上达到了与 o1-preview 近似甚至略高的正确率。
也确实存在一些大模型没能在一次性推理中给对,而小模型通过更深度的搜索和验证找到正确解的个例。
然而这不是绝对性地“任何题都比它好”。
更多是系统 2 式推理对某些复杂题可以弥补模型规模弱势。
8. 关于多语言或多文化背景的数学题
问:论文中数据集含有一些中文题(如 GaokaoEn 2023),但大部分方法示例都用英文 Python code。那中文题干中有可能涉及文字陷阱或多义表达,这一套“代码验证 + MCTS”机制能处理吗?
答:
作者在实验中也测了 GaokaoEn(相当于中文环境下的大学/高中数学),结果显示依旧能有不错表现。
但如果题干存在大量语言歧义、隐喻或文化背景,纯粹的代码验证可能就乏力。
文中没有深入探讨多语言对齐问题,只是提到对中文题同样做 code-augmented CoT;遇到歧义依旧只能靠模型本身的语言理解能力去消解。
9. 关于多步推理的时空成本
问:一次 MCTS 需要多次生成 step-by-step 解答,代码执行也要花费额外算力。若对每道题都进行 64、128 次 rollouts,推理耗时会不会过长,实际应用场景是否可行?
答:
论文里在最后提到,“对一些极难题我们确实会提升到 64/128 rollouts,耗时随之增加”,但对绝大多数题只做 16 rollouts 左右就足够。
这依然比 GPT-4 大模型做一次完整推理要更便宜(作者的观点)。
同时作者也承认,若对实时交互或大批量题目场景,仍需对搜索策略做剪枝或并行化优化,否则可能不太现实。
10. 关于 PPM 的多样性与鲁棒性
问:PPM 用 pairwise preference 做训练时,是如何确保它能够适用各种类型的中间推理步骤?万一有些步骤是高分但并无数值可检验,该怎么办?
答:
论文指出,PPM 并不只依赖“数值正确”这一维度。
它在训练集里收集到无数对比样本,包括相同前缀但后续不同分支带来的最终成功或失败。
只要最终结果能验证出正确或错误,对应的中间步骤就能获得相应的正负反馈。
至于那些“表面无数值可检验”的步骤,也能通过是否引导到最终正确解(或被其他更优分支替代)获取相对打分。作者承认,这种泛化在很大程度上依赖足够多的数据覆盖。
11. 关于搜索深度与推理深度的差异
问:MCTS 中的“深度”通常指离根节点的步数,但数学推理的真正“深度”还包含不同层次的理论推导。作者是不是将两者简单等价处理?对于非常深层的理论推导,是否需要更复杂的搜索结构?
答:
作者没有将搜索深度完全等同推理深度。只是在实现里,每步生成一小段推理 + Python 代码,以此视作一个节点的扩展。
对于理论上可无限延伸的证明(尤其是竞赛级别),如果超出 16 步阈值,就无法继续在当前树内展开。
不过作者称实际大部分题 16 步足以覆盖主要思路,否则就通过对难题多次搜索来进行补充。
12. 关于负面数据与训练稳定性
问:若题目错误率相当高、采样时得到大量负面例子,会不会让模型一直在收敛到“我不行”的结论?作者在实验里如何处理过多错误生成带来的梯度影响?
答:
作者对训练样本做了严格过滤:如果某题 16 次搜索全部错误,就不会把它的生成轨迹纳入训练集(在表格中记为“hard 问题继续搜索或跳过”)。
同时,每道题只选取“平均 Q 值最高的 2 条正确解轨迹”作为最终SFT数据,因此大量负例不会直接淹没模型。
负例主要用于训练 PPM 的“负对” preference,而不是进到政策模型的 SFT 里。
13. 关于人类标注的角色
问:现有一些工作使用人类专家标注来提供 step-by-step correctness 评估,比如 PRM800k 数据集。而作者在此似乎完全不需要人工干预,真的能保证所有中间步骤都是高质量?
答:
作者的目标就是减少对人工标注的依赖。他们通过“代码执行 + 终端奖励回溯 + PPM 自进化”来在大规模题库上自动生成 step-level 验证。
作者承认,这种自动方式仍存在一定噪声,但多轮搜索与轨迹筛选可以相互抵消一部分错误。与人工标注相比,这种方法可无限规模扩张,却牺牲了某些极端情况下的精准度。
14. 关于可移植性到其它领域
问:rStar-Math 主要针对数值类数学推理。如果要移植到需要深度自然语言理解(比如法律文本)或在文本中推理、没法直接 code execution,就没法完全用同样思路吧?
答:
作者在讨论部分也提及,这套框架需要某种机制能验证中间步骤对错;数学用 Python 代码检测就行,其他领域则可能需要单独的验证器,如“事实检索 + 检查”。
如果能找到合适的外部工具或自动打分手段(比如一套 QA 验证集),一样可以仿照 MCTS+过程打分思路去做系统2推理。但实现细节要各领域定制。
15. 关于自进化的终止条件
问:4 轮后作者就停止了自进化,那怎么确定 4 轮就够了?有没有可能多跑几轮能覆盖剩下那些难题?
答:
作者在文中表述,“在第 4 轮时大部分(90.25%)题目都被覆盖且难题的成功率也大幅提升”,再加上对未覆盖题目抽查多数是无效题,所以他们认为此时边际收益已经不大。
若再增加轮次,意味着指数级地增长算力成本,对整体收益有限,因此作者做了平衡后选择终止。
16. 关于小模型初始水平和 bootstrap 依赖
问:第 1 轮用 DeepSeek-Coder-v2-Instruct (236B) 作引导,这看起来并不是真正的“小模型从零开始”,你们是借了一个非常强的初始模型做 bootstrap。若没这个 236B 模型还能行吗?
答:
论文的确在“Round 1”用了一个236B的推理模型来加速初始数据生成,这算是一种外部辅助。
作者后续几轮则全部用 7B 自己搜。
理论上也可直接从 7B 自举,但那样前期生成的数据质量会更差,迭代要更多轮才能达到同样水准。
作者称为了节省实验周期、快速迭代,选了 236B 作启动,但也不否认这是一种外部助力。
17. 关于大模型蒸馏和这个方法的对比
问:同类工作往往直接 distill GPT-4 生成的 CoT 解答。作者强调他们不需要更强模型,但实际上在启动阶段还是用了 DeepSeek 236B。那跟 GPT-4 distillation 相比,优势究竟在哪里?
答:
作者指出,在 GPT-4 distillation 里,如果 GPT-4 解不出这道题,就没有对应的高质量解答;
而 rStar-Math 用 MCTS 可以反复试错,说不定可以攻克一些 GPT-4 当场失误的题。
此外,他们也强调后续几轮基本全靠自进化和自我搜索,无需高级 teacher 模型一直在线提供解答。
相比 GPT-4 大规模蒸馏,是更具可持续的一个方法。
18. 关于多次随机种子与重复搜
问:同一题作者会用不同随机种子,做多次 MCTS 树扩展,这是否会带来数据重复、从而浪费计算资源?
答:
作者确实多次提到对难题会换随机种子重复搜索。
虽然会有一些重复的生成轨迹,但当MCTS搜索足够大时,就有更高概率发现正确解或多样化解法。
重复的部分在 SFT 数据中也会被合并或过滤(只取平均 Q 值最高的两条)。
所以即使有些浪费,但收益在作者看来是值得的。
19. 关于过程监督的抽象层次
问:论文多在数值层面展示比如“python code 执行”之类的检查,但对真正的“数论证明”、“代数恒等式”等更高抽象度推理,好像并没有演示足够多案例。如何保证过程监督同样适用?
答:
作者提供了若干有限的例子,包括用 Sympy 做符号求解,甚至奥数中“Fermat’s Little Theorem”证明的简化。
但确实主要还是倾向能程序化或半程序化检验的方向。
对于更高层次的纯演绎证明,目前只能通过 PPM 的偏好分,以及最终答案对错的回溯。他们认为这是个未来待扩展的方向。
20. 关于与树状搜索的潜在冲突
问:有的论文使用“Self-consistency”或“Random sampling + reranking”就取得不错的效果;作者为什么必须用 MCTS 这样复杂的树搜索,而不是简单抽样?是否有证据显示树搜索一定更好?
答:
作者在文中援引了一些对比实验(类似 best-of-n、self-consistency 等),展示仅依赖随机抽样 + 验证模型的做法无法在中间步骤出现错误时有效纠偏。而 MCTS 可以“分步生成 + 分步评分 + 回溯更新”,显著减少中间错误的累积。
作者认为在高难度数学上这种“System 2”式思路确实可以进一步提升性能。
只是实现成本更高,需要更深入的过程监督模块(PPM)配合。