深度学习入门6:pytorch卷积神经网络CNN实现手写数字识别准确率99%
一、卷积神经网络原理
我们都知道前馈神经网络的原理就是通过调整每一层神经元的权重w和偏置b,来寻找到最佳的输入输出拟合函数,从而解释每个输入参数。
不同于前馈神经网络通过调整神经元的权重和偏置来寻找最佳拟合函数,卷积神经网络通过寻找最佳卷积核(滤波器)来寻找最佳拟合函数。
我们在前面知道前馈神经网络训练手写数字识别时,需要把图像展平为一维数据,因此主流的解释为前馈神经网络只能处理一维信息,丢失了二维空间特征,因此它只能学习一维特征。卷积神经网络设计就是为了使网络学习数据的二维甚至高纬特征。
实际上博主认为这个说法有点牵强,真正理解卷积神经网络的话,可以理解为卷积神经网络实际上是学习数据的局部结构特征,而前馈神经网络可以看作原始数据与原始数据大小的卷积核进行卷积,因此我们可以理解为它只学习数据的全局结构特征,他们两个实际上都是在学习数据的二维特征。只不过卷积神经网络更能捕捉数据的局部结构特征。
神经网络训练只会学习数据结构信息,不会学习空间位置信息,例如手写数字识别的数字训练时都是数字都是居中放置,如果数字旋转或者换个位置挪动到左上角或者右上角,那么将无法识别出数字。
二、卷积:
卷积核,填充,步幅,最大汇聚(池化),平均汇聚(池化),这些名词都比较简单,不做过多解释,不清楚的自行查找资料理解。
卷积核:当卷积对象为二维数据时,C = 1时,称卷积对象为卷积核。
滤波器:当卷积对象为三维数据甚至高纬数据时,C>1时,称卷积对象为滤波器。
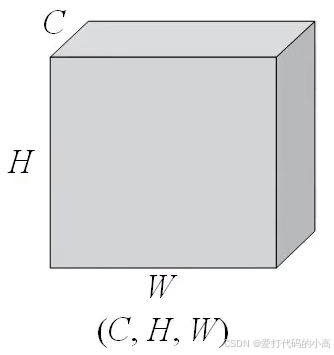
图2.1 输入数据定义
如上图所示,被卷积的数据一般定义为上述形式,C代表通道数,H,W代表二维数据的行和列。如下图所示为C=1时,填充padding=1的一次卷积运算。
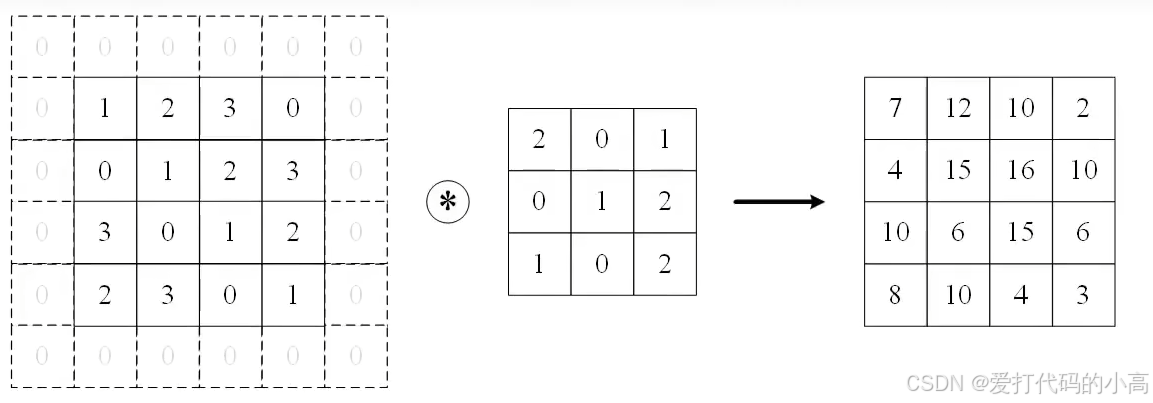
图2.2 一次填充为1卷积核为3的卷积运算
无论是二维的卷积运算,还是三维的相同通道(C值相等)卷积运算,输出结果都是一个二维结果。
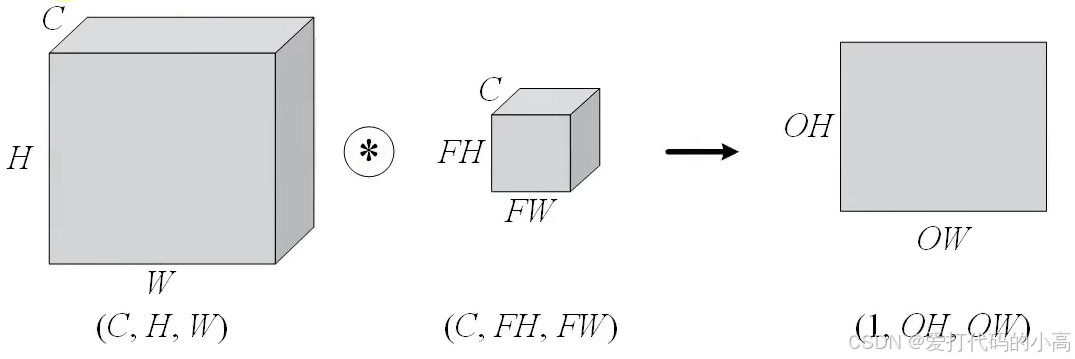
图2.3 相同通道数的数据和滤波器做卷积
如上图所示,C值相等的数据和卷积核,也就是相同通道数的数据和相同通道数的卷积核运算后C变为1,变为二维数据。
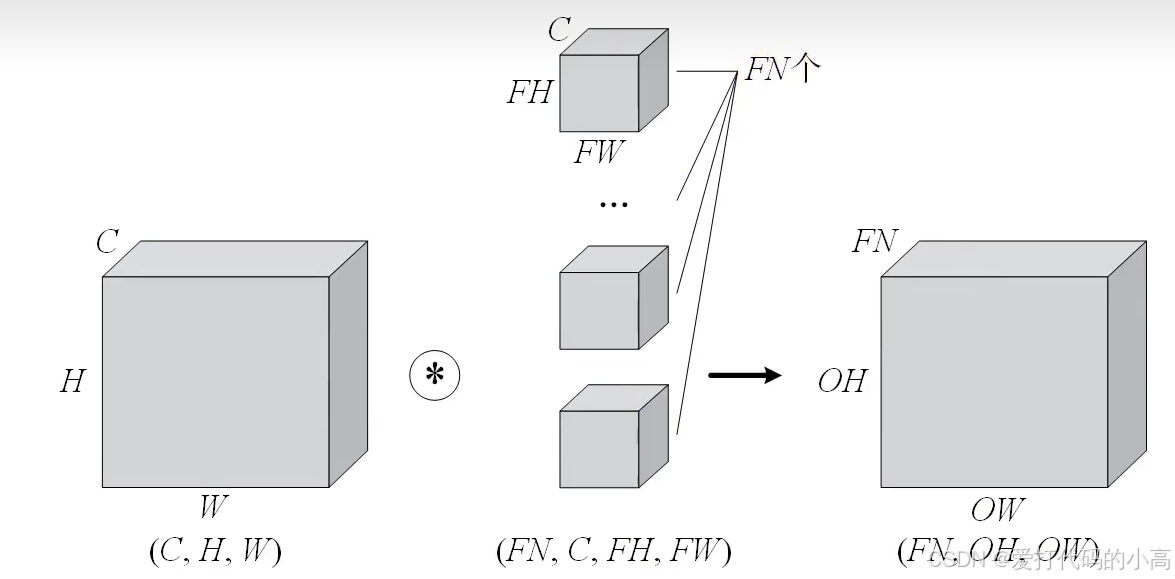 图2.4 多通道输出
图2.4 多通道输出
如上图所示,当我们需要进行多通道输出时,过滤器(卷积核)就要有多个。
输出尺寸计算:
设填充为P(padding),步幅为S(Stride),为原始数据行数,
为过滤器(卷积核)行数
为输出数据行数
输出尺寸=
输出尺寸=[(原始尺寸+2倍填充-卷积核长度)/步幅)]+1
三、 网络结构与代码实现
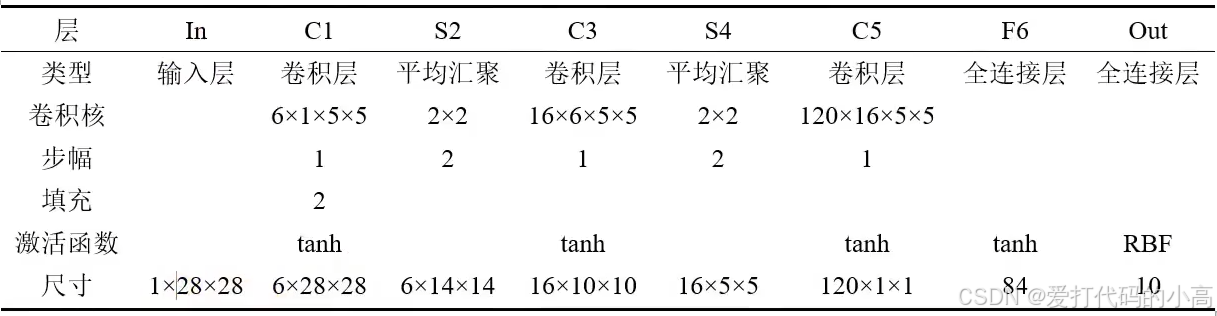
如图所示为LeNet网络结构属于卷积神经网络,卷积层的卷积核代表(输出通道数,输入通道数,过滤器行数,过滤器列数),网络输入为1x28x28的数据,通过padding = 2进行填充,经过步幅为1,过滤器(卷积核)为5*5的操作后,输出为一个通道为6,尺寸为28*28的数据。
计算过程:带入上述公式计算,输出尺寸。汇聚的原理和输出尺寸计算过程比较简单,自行查找资料计算即可。
因此可以实现网络结构代码如下:
model.py
import torch.nn as nn
import torch.nn.functional as Fclass CNN(nn.Module):def __init__(self):super().__init__()# 卷积层 1: 输入通道 1,输出通道 6,卷积核大小 5x5self.conv1 = nn.Conv2d(1, 6, kernel_size=5, padding=2)# 卷积层 2: 输入通道 6,输出通道 16,卷积核大小 5x5self.conv2 = nn.Conv2d(6, 16, kernel_size=5)#卷积层3 输入通道6,输出120,卷积核5*5self.conv3 = nn.Conv2d(16, 120, kernel_size=5)# 全连接层 1: 输入 120,输出 84self.fc1 = nn.Linear(120, 84)# 全连接层 2: 输入 84,输出类别数self.fc2 = nn.Linear(84, 10)def forward(self, x):# 卷积 -> 激活 -> 池化x = F.tanh(self.conv1(x)) # 输出大小: 6@28x28 (输入是 1@32x32)x = F.avg_pool2d(x,2)#x = F.max_pool2d(x, 2) # 输出大小: 6@14x14x = F.tanh(self.conv2(x)) # 输出大小: 16@10x10x = F.avg_pool2d(x,2)#x = F.max_pool2d(x, 2) # 输出大小: 16@5x5x = F.tanh(self.conv3(x))# 展平x = x.view(-1, 120 * 1 * 1)# 全连接层x = F.tanh(self.fc1(x))x = self.fc2(x)return x
dataset.py
import torchvision
from torch.utils.data import DataLoader
from torchvision import transformstransform = transforms.Compose([transforms.ToTensor() # 转换为张量
])
def getDataloder():train_dataset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)print("train_dataset length: ", len(train_dataset))# 小批量的数据读入train_loader = DataLoader(train_dataset, batch_size=512, shuffle=True)print("train_loader length: ", len(train_loader))return train_loader
def getTestloder():train_dataset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)print("train_dataset length: ", len(train_dataset))# 小批量的数据读入test_loader = DataLoader(train_dataset, batch_size=1000, shuffle=True)print("train_loader length: ", len(test_loader))return test_loader
if __name__ == '__main__':getDataloder()train.py
import torch
from torch import optim, nn
from dataset import getDataloder
from model import CNNdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")if __name__ == '__main__':train_loader = getDataloder()model = CNN().to(device)criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters())for epoch in range(10):for batch_idx,(data,label) in enumerate(train_loader):data = data.to(device)label = label.to(device)output = model(data)loss = criterion(output, label)loss.backward()optimizer.step()optimizer.zero_grad()if batch_idx % 10 == 0:print(f"Epoch {epoch + 1}/30 "f"| Batch {batch_idx * len(data)}/{len(train_loader.dataset)} "f"| Loss: {loss.item():.4f}")torch.save(model.state_dict(), 'mnist_CNN.pth') # 保存模型
test.py
import torch
from torch import nnfrom dataset import getTestloder
from model import CNNif __name__ == '__main__':test_loader = getTestloder()model = CNN()model.load_state_dict(torch.load('./mnist_CNN.pth'))test_loss = 0correct = 0criterion = nn.CrossEntropyLoss()for idx,(data,target) in enumerate(test_loader):predict = model(data)test_loss += criterion(predict, target).item()pred = predict.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(test_loader.dataset)print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} 'f'({100. * correct / len(test_loader.dataset):.0f}%)\n')#print(Accuracy)#if(predict == label):
四、项目下载:
卷积神经网络实现手写数字识别:点击下载MNIST_CNN.zip