哈希动态规划dp_5
一.哈希
哈希(Hashing)是计算机科学中一种非常重要的技术,用于将输入的数据映射到固定大小的值(哈希值)上。哈希算法和哈希数据结构广泛应用于各种领域,包括数据查找、加密、缓存、数据库索引等。我们来详细讨论一下与哈希相关的算法和数据结构,以及如何进行优化。
1. 哈希算法
哈希算法的作用是根据输入的元素,计算出一个固定长度的哈希值(通常是一个整数或字符串),这个哈希值通常用于唯一标识输入。常见的哈希算法有以下几种:
1.1 MD5 (Message Digest Algorithm 5)
- 用途:MD5 是一个广泛使用的哈希算法,通常用于文件的完整性校验,密码存储等。它将任意长度的输入转换为128位的哈希值。
- 缺点:MD5 已被发现存在碰撞(两个不同的输入有相同的哈希值)问题,因此在安全性要求高的场景下已经不推荐使用。
1.2 SHA系列(Secure Hash Algorithm)
- 用途:SHA 是一种更安全的哈希算法系列。SHA-1 生成160位的哈希值,而 SHA-2 和 SHA-3 分别生成256位或更大的哈希值。
- SHA-1:不再推荐使用,已被证明存在碰撞漏洞。
- SHA-256:广泛用于密码学应用,区块链(如比特币)中也使用了 SHA-256 算法。
- SHA-3:更为先进和安全,与 SHA-2 体系不同,采用了 Keccak(凯-克)算法。
1.3 CRC32(Cyclic Redundancy Check)
- 用途:CRC32 是一个广泛用于网络传输和存储的哈希算法,用于检验数据的完整性,常见于以太网协议和文件校验。
- 特点:效率高,但安全性差,适合用于错误检测,而不适合用于密码学应用。
1.4 HMAC (Hash-based Message Authentication Code)
- 用途:HMAC 是基于哈希的消息认证码,结合了哈希算法和密钥,用于消息的完整性和身份认证。
- 常用哈希算法:通常与 SHA-1 或 SHA-256 等哈希算法结合使用。
1.5 哈希碰撞与加盐
- 碰撞:哈希算法的目标是将不同的输入映射到唯一的哈希值。然而,由于输入空间大于哈希值空间,发生哈希碰撞是不可避免的。碰撞会导致两个不同的输入产生相同的哈希值。
- 加盐:为了解决哈希碰撞问题,在加密哈希中引入“盐”(salt),它是一个随机生成的值,会与原始输入一起进行哈希处理,以增加安全性。
1.6 布隆过滤器(Bloom Filter)
- 用途:布隆过滤器是一种空间效率非常高的数据结构,用于判断某个元素是否存在于集合中。布隆过滤器存在误报(可能判定元素存在但实际上不存在),但不会漏报。
- 原理:通过多个哈希函数将元素映射到一个位数组中,查询时检查多个位置的值是否为1来判断元素是否存在。
- 优化:减少哈希函数数量与位数组大小的平衡,调整误差率与空间消耗的关系。
2. 哈希数据结构
哈希数据结构使用哈希函数将数据映射到一个表格中,使得查找、插入、删除等操作可以在常数时间内完成。常见的哈希数据结构有:
2.1 哈希表(Hash Table)
- 用途:哈希表是一种键值对存储结构,能够高效地进行查找、插入和删除。哈希表的性能大多数情况下接近 O(1),但最坏情况下可能退化为 O(n)。
- 原理:使用哈希函数将键映射到数组的索引,存储值。冲突解决方法有:
- 链式法:在同一个哈希桶(数组索引位置)中存储一个链表,哈希冲突的数据通过链表连接在一起。
- 开放地址法:当发生哈希冲突时,哈希表会寻找下一个空位置进行存储。
优化:
- 动态扩容:当哈希表的负载因子(元素数量与表大小的比例)超过一定阈值时,哈希表会扩展,避免性能退化。
- 哈希函数优化:选择适当的哈希函数,尽量减少哈希冲突,提高哈希表的查询效率。
-
链式法
#include <iostream> #include <vector> #include <list> #include <iterator> using namespace std; class HashTable { private: // 哈希表的大小 static const int TABLE_SIZE = 10; // 哈希表存储数据的数组(数组的每个位置都是一个链表) vector<list<pair<int, string>>> table; // 哈希函数,将键映射到表的索引 int hashFunction(int key) { return key % TABLE_SIZE; } public: HashTable() { table.resize(TABLE_SIZE); } // 插入键值对 void insert(int key, const string& value) { int index = hashFunction(key); // 获取该键的哈希值对应的索引 // 在对应的链表中插入键值对 table[index].push_back(make_pair(key, value)); } // 查找键对应的值 string find(int key) { int index = hashFunction(key); // 获取该键的哈希值对应的索引 // 遍历链表,查找该键是否存在 for (auto& p : table[index]) { if (p.first == key) { return p.second; } } return "Not found"; // 没有找到返回“Not found” } // 删除键值对 void remove(int key) { int index = hashFunction(key); // 获取该键的哈希值对应的索引 // 遍历链表,查找该键并删除 for (auto it = table[index].begin(); it != table[index].end(); ++it) { if (it->first == key) { table[index].erase(it); return; } } } // 打印哈希表 void display() { for (int i = 0; i < TABLE_SIZE; i++) { cout << "Index " << i << ": "; for (auto& p : table[i]) { cout << "[" << p.first << ": " << p.second << "] "; } cout << endl; } } }; int main() { HashTable ht; ht.insert(1, "One"); ht.insert(2, "Two"); ht.insert(12, "Twelve"); ht.insert(22, "Twenty Two"); ht.display(); cout << "Find key 1: " << ht.find(1) << endl; cout << "Find key 12: " << ht.find(12) << endl; ht.remove(2); cout << "After removing key 2:" << endl; ht.display(); return 0; } -
开放地址
-
#include <iostream> #include <vector> #include <string> #include <cmath> using namespace std; class HashTable { private: static const int TABLE_SIZE = 10; vector<pair<int, string>> table; // 哈希函数 int hashFunction(int key) { return key % TABLE_SIZE; } public: HashTable() { table.resize(TABLE_SIZE, make_pair(-1, "")); } // 插入操作 void insert(int key, const string& value) { int index = hashFunction(key); int originalIndex = index; // 线性探查查找下一个空位置 while (table[index].first != -1 && table[index].first != key) { index = (index + 1) % TABLE_SIZE; if (index == originalIndex) { cout << "HashTable is full!" << endl; return; } } table[index] = make_pair(key, value); } // 查找操作 string find(int key) { int index = hashFunction(key); int originalIndex = index; while (table[index].first != -1) { if (table[index].first == key) { return table[index].second; } index = (index + 1) % TABLE_SIZE; if (index == originalIndex) { break; } } return "Not found"; } // 删除操作 void remove(int key) { int index = hashFunction(key); int originalIndex = index; while (table[index].first != -1) { if (table[index].first == key) { table[index] = make_pair(-1, ""); return; } index = (index + 1) % TABLE_SIZE; if (index == originalIndex) { break; } } } // 打印哈希表 void display() { for (int i = 0; i < TABLE_SIZE; i++) { if (table[i].first != -1) { cout << "[" << table[i].first << ": " << table[i].second << "] "; } else { cout << "[Empty] "; } } cout << endl; } }; int main() { HashTable ht; ht.insert(1, "One"); ht.insert(2, "Two"); ht.insert(12, "Twelve"); ht.insert(22, "Twenty Two"); ht.display(); cout << "Find key 1: " << ht.find(1) << endl; cout << "Find key 12: " << ht.find(12) << endl; ht.remove(2); cout << "After removing key 2:" << endl; ht.display(); return 0; }
2.2 哈希集合(Hash Set)
- 用途:哈希集合是一种不包含重复元素的数据结构,它是哈希表的一个变种,仅存储键,不存储值。常见于需要判断元素是否存在集合中的场景。
- 原理:通过哈希表实现,键即元素,值可以忽略。
2.3 哈希映射(Hash Map)
- 用途:哈希映射(或字典、散列表)是键值对(key-value)存储的数据结构,支持高效的查找、插入和删除。
- 原理:通过哈希表实现,键通过哈希函数映射到数组索引,值存储在对应位置。
优化:
- 负载因子控制:负载因子是哈希表中存储元素的个数与数组大小的比例。合理调整负载因子,避免哈希表频繁扩容。
- 哈希函数的选择:一个好的哈希函数应该使得输入元素均匀分布,减少哈希冲突,确保哈希表的查询效率。
3. 哈希算法与数据结构的优化
3.1 优化哈希函数
- 选择合适的哈希函数:一个好的哈希函数能够保证哈希值均匀分布,从而减少冲突。常用的哈希函数有:
- MurmurHash:一种高效、快速的非加密哈希函数。
- FNV-1a:一种简单且效率较高的哈希函数。
- CRC32:用于校验和的哈希函数。
3.2 解决哈希冲突
- 链式哈希法:每个哈希桶存储一个链表,插入冲突元素时,将其添加到链表中。虽然查询最坏情况下是 O(n),但通常情况下冲突较少,性能良好。
- 开放地址法:当发生哈希冲突时,按照某种探查方式寻找下一个空槽进行存储。常见的探查方式包括线性探查、二次探查和双重哈希。
3.3 负载因子与扩容
- 负载因子:是哈希表中元素个数与表大小的比例。负载因子过大会导致冲突频发,负载因子过小会浪费空间。一般情况下,负载因子控制在 0.75 左右。
- 动态扩容:当负载因子超过一定阈值时,哈希表需要扩展。扩容时,通常需要重新计算每个元素的哈希值并将其重新分布到新的哈希表中。
3.4 空间优化
- 布隆过滤器:对于需要存储大量数据且查询操作为 "是否存在" 的应用场景,布隆过滤器提供了一种高效的空间优化方法。
- 哈希压缩:对于哈希值过长的情况,可以使用哈希压缩算法将其映射到较小的空间,减少存储开销。
3.5 并行哈希
- 并行计算哈希值:对于大数据集,使用并行计算哈希值可以加速哈希操作。比如,在多核 CPU 上并行计算多个数据块的哈希值。
总结
哈希是计算机科学中非常重要的技术,它通过将数据映射到固定大小的哈希值来实现高效的查找、插入、删除等操作。哈希算法与哈希数据结构的优化主要集中在减少哈希冲突、优化哈希函数、控制负载因子和空间消耗等方面。常见的哈希数据结构包括哈希表、哈希集合和哈希映射,而优化的方式包括合理选择哈希函数、使用不同的冲突解决策略以及空间和并行计算的优化。
二.动态规划dp
1.
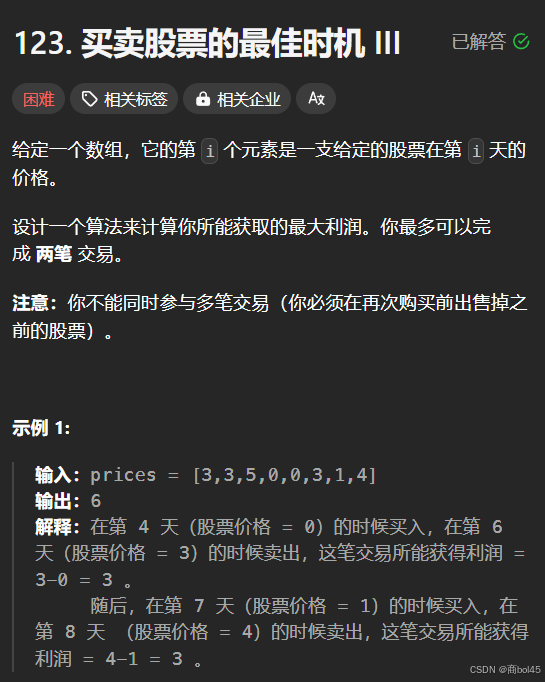
思路:模拟整个买卖股票的过程
/*
模拟买卖股票的过程每次都做出最优解
*/
class Solution {
public:
int maxProfit(vector<int>& prices) {
vector<vector<int>>dp(prices.size(),vector<int>(5,0));
dp[0][0] = 0;
dp[0][1] = -prices[0];
dp[0][2] = 0;
dp[0][3] = -prices[0];
dp[0][4] = 0;
for(int i = 1;i < prices.size(); i++){
dp[i][1] = max(dp[i - 1][1],dp[i - 1][0] - prices[i]); // 第一次买入
dp[i][2] = max(dp[i - 1][2],dp[i - 1][1] + prices[i]); // 第一次卖出
dp[i][3] = max(dp[i - 1][3],dp[i - 1][2] - prices[i]); // 第二次买入
dp[i][4] = max(dp[i - 1][4],dp[i - 1][3] + prices[i]); // 第二次卖出
}
return dp[prices.size()-1][4];
}
};题解进阶解法
class Solution {
public:
int maxProfit(vector<int>& prices) {
const int k = 2;
vector<array<int, 2>> f(k + 2, {INT_MIN / 2, INT_MIN / 2});
for (int j = 1; j <= k + 1; j++) {
f[j][0] = 0;
}
for (int p : prices) {
for (int j = k + 1; j > 0; j--) {
f[j][0] = max(f[j][0], f[j][1] + p);
f[j][1] = max(f[j][1], f[j - 1][0] - p);
}
}
return f[k + 1][0];
}
};
三.题
1.

思路:暴力枚举即可
#include<iostream>
#include<vector>
using namespace std;
int main() {
string s;
cin >> s;
vector<int> a, b, c;
for (int i = 0; i < s.size(); i++) {
if (s[i] == 'A') {
a.push_back(i);
}
else if (s[i] == 'B') {
b.push_back(i);
}
else if (s[i] == 'C') {
c.push_back(i);
}
}
int count = 0;
for (int i : a) {
for (int j : b) {
if (j <= i) continue;
for (int k : c) {
if (k <= j) continue;
if (j - i == k - j) {
count++;
}
}
}
}
cout << count << endl;
return 0;
}
2.

思路:用哈希映射来存储地图的边,记录下自连的边,同时把记录下相同小点到大点的边的个数然后统计所有这样的多余的边,输出自连的边数加所有统计多余的边数
#include <iostream>
#include <vector>
#include <unordered_map>
#include <algorithm>
using namespace std;
int main() {
int n, m;
cin >> n >> m;
int cnt = 0;
unordered_map<int, unordered_map<int, int>> coun;
for (int i = 0; i < m; i++) {
int u, v;
cin >> u >> v;
if (u == v) {
cnt++;
continue;
}
if (u > v) swap(u, v);
coun[u][v]++;
}
int del = 0;
for (const auto& pair1 : coun) {
for (const auto& pair2 : pair1.second) {
int count = pair2.second;
if (count > 1) {
del += (count - 1);
}
}
}
int sum = cnt + del;
cout << sum << endl;
return 0;
}3.

思路:思维题就2种情况要不有相同的就是1否则就是原长,也可以用头文件栈来模拟过程求解
#include <iostream>
#include<vector>
#include<algorithm>
#include<stack>
using namespace std;
using ll = long long;
int main() {
ll t;
cin >> t;
while (t--) {
string str;
cin >> str;
int key = 1;
for (ll i = 1; i < str.size(); i++) {
if (str[i - 1] == str[i]) {
cout <<"1" << endl;
key = 0;
break;
}
}
if (key == 0)continue;
cout << str.size() << endl;
}
return 0;
}4.
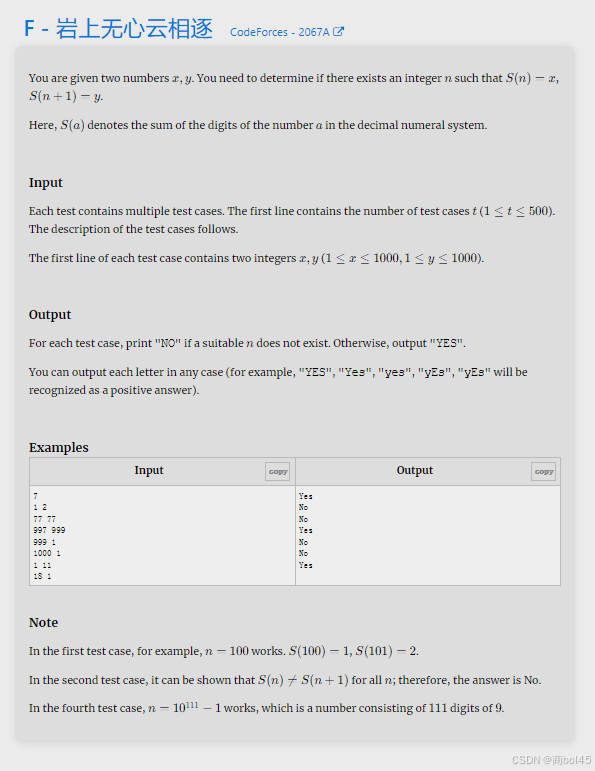
思路:思维题,用本子随便写找规律,相邻的俩个数可以输出yes,还有就是看
n = 99 , x = 18,y = 1
n = 999 , x = 27,y = 1
n = 9999, x = 36,y = 1
这就是规律
#include <iostream>
#include <vector>
#include <stack>
#include <algorithm>
#include <cstring>
using namespace std;
int main() {
int t;
cin >> t;
while (t--) {
int x, y;
cin >> x >> y;
if (x == y - 1) {
cout << "Yes" << endl;
continue;
}
if (x > y) {
int c = x - y;
if ((c + 1) % 9 == 0)
cout << "Yes" << endl;
else
cout << "No" << endl;
continue;
}
else
cout << "No" << endl;
}
return 0;
}5.算法竞赛进阶指南
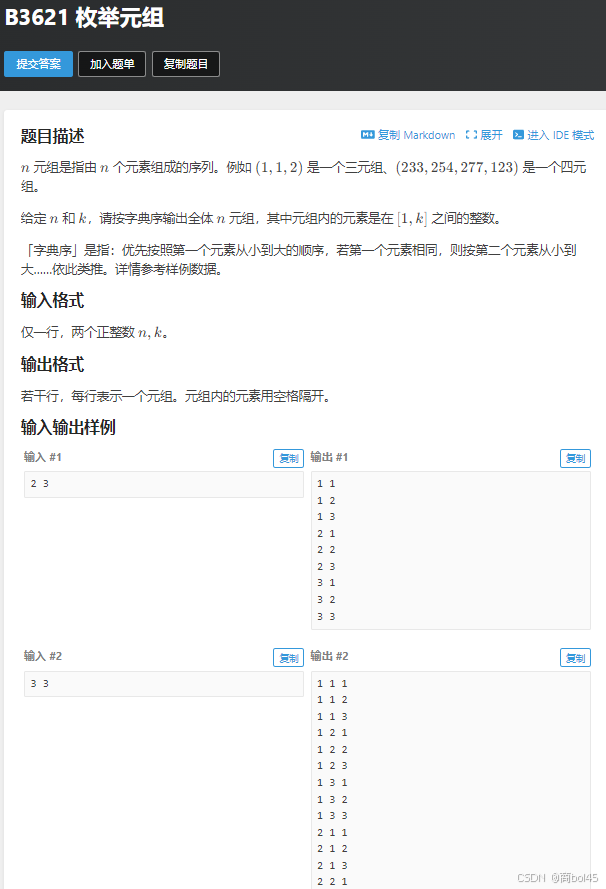
思路:dfs
#include <iostream>
#include <algorithm>
#include<stack>
#include <climits>
using namespace std;
const int N=7;
int n, k;
int arr[N];
void dfs(int x) {
if (x > n) {
for (int i = 1; i <= n; i++) {
cout << arr[i] << " ";
}
cout << endl;
return;
}
for (int i = 1; i <= k; i++) {
arr[x] = i;
dfs(x + 1);
}
}
int main() {
cin >> n >> k;
dfs(1);
return 0;
}