【C++指南】string(四):编码
💓 博客主页:倔强的石头的CSDN主页
📝Gitee主页:倔强的石头的gitee主页
⏩ 文章专栏:《C++指南》
期待您的关注

引言
在 C++ 编程中,处理字符串是一项极为常见的任务。而理解字符串在底层是如何编码存储的,对于编写高效、健壮且可移植的代码至关重要。
本文将深入探讨 C++ 中string所涉及的多种编码规则,包括 ASCII、Unicode、UTF - 8、UTF - 16 和 UTF - 32 等,并着重讲解 UTF - 8 编码以及它在string中灵活存储字符串的机制。
常见编码规则介绍
ASCII 编码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是最古老且最基础的编码方式之一。它使用 7 位二进制数来表示 128 个字符,包括英文字母(大小写)、数字、标点符号以及一些控制字符。例如,大写字母 'A' 的 ASCII 码是 65,用二进制表示为01000001。ASCII 编码的优点是简单直观,易于理解和处理,在早期的计算机系统中被广泛应用。然而,它的局限性也很明显,只能表示英文字符和少量特殊符号,无法满足全球多语言文本处理的需求。
参考文章:
【C语言指南】ASCII码完整详细介绍_c语言ascll码-CSDN博客
Unicode 编码
Unicode 旨在为世界上所有的字符提供一个唯一的数字编号,无论其语言和平台如何。
它涵盖了几乎所有已知的字符集,包括各种语言的字母、汉字、符号、表情符号等。
Unicode 有多种编码形式,常见的有 UTF - 8、UTF - 16 和 UTF - 32。
Unicode 的编码空间非常大,使用 16 位或更多位来表示字符。例如,汉字 “你” 的 Unicode 编码是U+4F60。
Unicode 解决了全球字符统一编码的问题,但由于其编码长度不固定(对于一些基本拉丁字符也使用 16 位表示),在存储和传输时可能会造成空间浪费。
UTF - 8 编码
UTF - 8(8 - bit Unicode Transformation Format)是一种变长编码方式,它可以使用 1 到 4 个字节来表示一个字符。
UTF - 8 的设计目标是既能与 ASCII 编码兼容(对于 ASCII 字符,UTF - 8 编码与 ASCII 编码完全相同,占用 1 个字节),又能高效地表示其他 Unicode 字符。
对于大多数常用字符(如英文字母、数字、标点符号等),UTF - 8 仅用 1 个字节表示,与 ASCII 编码一致,这使得基于 ASCII 的现有软件可以无缝处理 UTF - 8 编码的文本。
对于其他非 ASCII 字符,UTF - 8 会根据字符的 Unicode 值使用 2 到 4 个字节进行编码。
例如,汉字 “你” 的 UTF - 8 编码是E4 BD A0,占用 3 个字节。
UTF - 8 编码具有良好的空间效率和兼容性,在互联网上被广泛应用,是目前最常用的编码方式之一。
UTF - 16 编码
UTF - 16 也是一种 Unicode 编码形式,它使用 16 位(2 个字节)或 32 位(4 个字节)来表示一个字符。
对于基本多文种平面(BMP)内的字符,UTF - 16 使用 16 位表示;
而对于那些在 BMP 之外的字符(如一些生僻字、表情符号等),则需要使用两个 16 位的代码单元来表示,即占用 4 个字节。
UTF - 16 在 Windows 操作系统以及一些基于 Unicode 的编程语言(如 Java)中应用较为广泛,但由于其对于非 BMP 字符的处理相对复杂,在跨平台和网络传输方面不如 UTF - 8 灵活。
UTF - 32 编码
UTF - 32 是一种定长编码方式,每个字符都固定占用 4 个字节(32 位)。
它直接将 Unicode 码点映射到 32 位的二进制数,这种编码方式简单直接,字符定位和处理非常方便,因为每个字符的长度固定。
然而,其缺点也很明显,对于大量只包含基本拉丁字符的文本,会造成大量的空间浪费。
例如,一个简单的英文字符串 “hello”,在 UTF - 32 编码下需要占用 20 个字节(每个字符 4 个字节),而在 UTF - 8 编码下只需要 5 个字节。
以下将对UTF-8这一较为广泛使用的编码规则展开详细讲解:
UTF - 8 编码详解
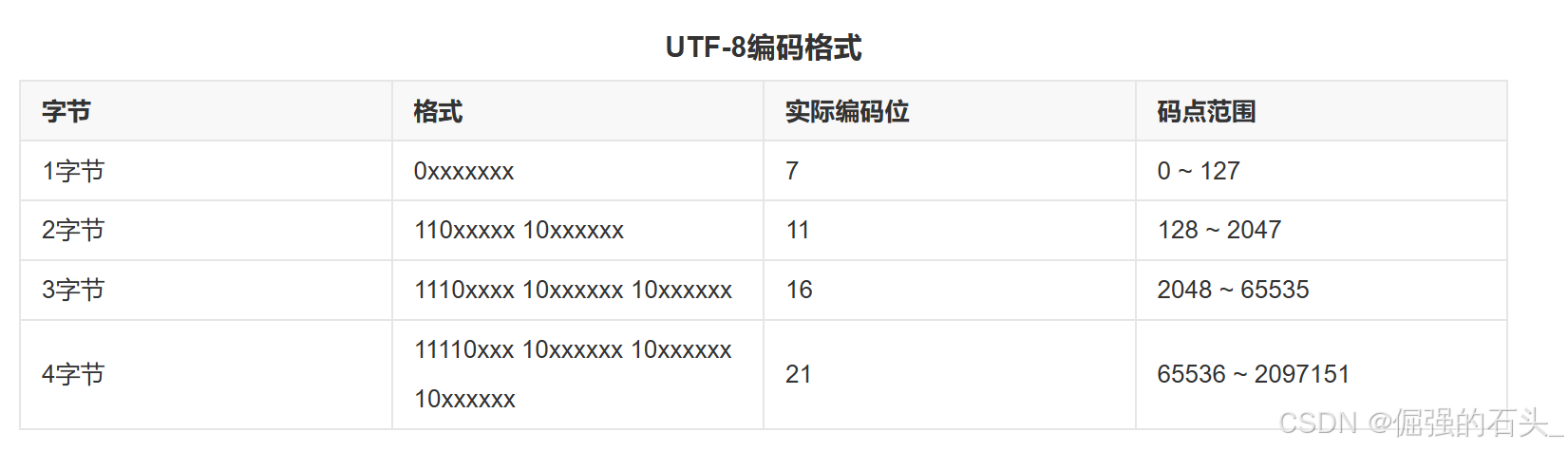
UTF - 8 编码规则
UTF - 8 的编码规则如下:
- 单字节字符(与 ASCII 兼容):对于 Unicode 码点范围在U+0000到U+007F之间的字符,UTF - 8 编码与 ASCII 编码相同,使用 1 个字节表示,且最高位为 0。例如,字符 'A' 的 Unicode 码点是U+0041,其 UTF - 8 编码为41(十六进制),二进制表示为01000001。
- 双字节字符:对于 Unicode 码点范围在U+0080到U+07FF之间的字符,UTF - 8 使用 2 个字节表示。第一个字节的前两位固定为 11,第三位到第七位是该字符 Unicode 码点的一部分;第二个字节的前两位固定为 10,其余六位是该字符 Unicode 码点的另一部分。例如,字符 'è' 的 Unicode 码点是U+00E8,转换为二进制是00000000 11101000。按照 UTF - 8 编码规则,第一个字节为11000000 | 00001110 = C0 | 0E = CE,第二个字节为10000000 | 101000 = 80 | A0 = A0,所以 'è' 的 UTF - 8 编码为CE A0。
- 三字节字符:对于 Unicode 码点范围在U+0800到U+FFFF之间的字符,UTF - 8 使用 3 个字节表示。第一个字节的前三位固定为 111,第四位到第七位是该字符 Unicode 码点的一部分;后面两个字节的前两位都固定为 10,其余六位分别是该字符 Unicode 码点的其他部分。以汉字 “中” 为例,其 Unicode 码点是U+4E2D,二进制表示为01001110 00101101。UTF - 8 编码后的第一个字节为11100000 | 01001110 = E0 | 4E = E4,第二个字节为10000000 | 00101101 = 80 | 2D = BD,第三个字节为10000000 | 00000000 = 80 | 00 = A0,所以 “中” 的 UTF - 8 编码为E4 BD A0。
- 四字节字符:对于 Unicode 码点范围在U+10000到U+10FFFF之间的字符,UTF - 8 使用 4 个字节表示。第一个字节的前四位固定为 1111,第五位到第七位是该字符 Unicode 码点的一部分;后面三个字节的前两位都固定为 10,其余六位分别是该字符 Unicode 码点的其他部分。例如,一些表情符号就属于这一类。
UTF - 8 在 C++ string 中的存储
在 C++ 中,std::string本质上是一个字符序列,默认情况下,它以字节为单位存储字符。
当使用 UTF - 8 编码时,std::string可以自然地存储 UTF - 8 编码的字符串,因为 UTF - 8 编码的每个字节都可以直接存储在std::string的字符元素中。
例如:
#include <iostream>#include <string>int main() {std::string utf8String = "你好,世界!";for (char ch : utf8String) {std::cout << std::hex << static_cast<int>(static_cast<unsigned char>(ch)) << " ";}return 0;}上述代码定义了一个包含中文字符的 UTF - 8 编码字符串utf8String,然后遍历该字符串,将每个字节以十六进制形式输出。由于 UTF - 8 编码的多字节特性,每个字符可能占用多个字节,在std::string中这些字节会依次存储。
UTF - 8 存储字符串的底层原理
在std::string内部,它维护着一块连续的内存空间,用于存放字符数据。
当存储 UTF - 8 编码的字符串时,这块内存就按照 UTF - 8 的字节序列依次填充。
比如存储 “hello” 这个字符串,每个字符都是 ASCII 字符,在 UTF - 8 中都只占 1 个字节,内存中会按顺序存放这 5 个字符对应的字节。
而当存储包含中文字符的字符串时,情况就变得复杂些。
以 “中国” 为例,“中” 的 UTF - 8 编码是E4 BD A0,“国” 的 UTF - 8 编码是E5 9B BD,在std::string的内存中,这 6 个字节会依次排列,从起始地址开始,先是 “中” 字的 3 个字节,紧接着是 “国” 字的 3 个字节。
中英文混合存储
当处理中英文混合的字符串时,UTF - 8 的变长特性就发挥了极大优势。
在std::string中,它依然是按照 UTF - 8 编码后的字节顺序依次存储。
例如字符串 “Hello,世界”,“Hello” 这 5 个英文字符,每个字符在 UTF - 8 中占用 1 个字节,共 5 个字节;英文逗号 “,” 在 UTF - 8 中占用 1 个字节;“世” 字占用 2 个字节,“界” 字占用 2 个字节'\0'占用1个字节。
所以整个字符串在std::string中存储时,从起始位置开始,先是 “H” 对应的字节,接着是 “e”“l”“l”“o”“,”“世”“界” 各自对应的字节,总共是 5 + 1 + 2 + 2 + 1 = 11 个字节。
下面通过代码来直观展示中英文混合存储的情况:
#include <iostream>#include <string>int main() {std::string mixedString = "Hello,世界";std::cout << "字符串长度(字节数): " << mixedString.size() << std::endl;for (size_t i = 0; i < mixedString.size(); ++i) {std::cout << std::hex << static_cast<int>(static_cast<unsigned char>(mixedString[i])) << " ";}return 0;} 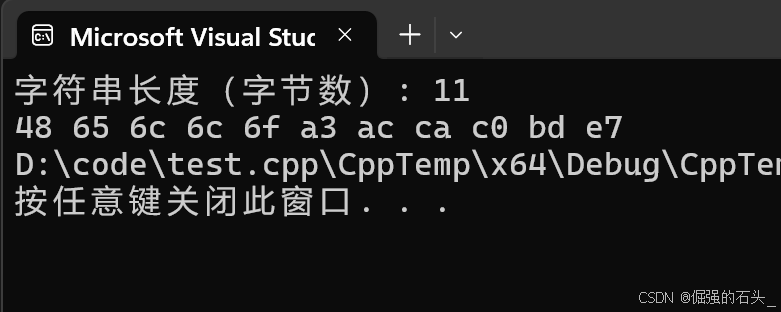
运行上述代码,输出结果中字符串长度为 11,并且能看到每个字符对应的 UTF - 8 编码字节以十六进制形式呈现。
在实际处理中英文混合字符串时,我们要特别注意std::string的操作方法。
例如,若要在字符串中查找某个字符,对于英文字符,因为其在 UTF - 8 中占 1 个字节,直接按字节查找即可;
但对于中文字符,由于它可能占用 2 个字节,不能简单地按字节遍历查找,而是要按照 UTF - 8 编码规则,每次检查 2 个字节是否构成要查找的中文字符的 UTF - 8 编码。
在进行字符串截取操作时也同理,若要截取一个中文完整字符,必须保证截取的起始和结束位置都在该中文字符 UTF - 8 编码的字节范围内,否则可能导致截取后的字符串出现乱码。
总结
不同的编码规则在 C++ string的处理中各有特点和应用场景。
ASCII 编码简单但功能有限,Unicode 提供了全球统一的字符编码方案,而 UTF - 8、UTF - 16 和 UTF - 32 则是 Unicode 的不同编码实现方式。
UTF - 8 因其良好的兼容性和空间效率,成为了目前最常用的编码方式,特别是在互联网应用和跨平台开发中。
深入理解这些编码规则以及它们在 C++ string中的存储和处理方式,对于编写高质量的 C++ 代码至关重要。
在实际开发中,应根据具体需求选择合适的编码方式,以确保程序能够正确、高效地处理各种字符集的字符串。
本文完。