认识文件系统
1.理解一下整体的文件系统
首先我们大概来了解一下,在磁盘里面,我们可以把磁盘的存储逻辑抽象成一整块,而对于一整块的存储单元,由于管理难度较大,我们又可以把他进行分区,假设说一个扇区是800GB,那我们就可以把他分成200GB,200GB,100GB,300GB这样子,大概就是这样的分区管理。
那然后,我们就可以在200GB里面进行分组,一个200GB的空间可以分成好多个组,一个基本的组假设我们可以设为10GB,而管理好这个10GB的组,那就能把其他的组管理好,进而就可以管理好200GB和更大的内存块空间。
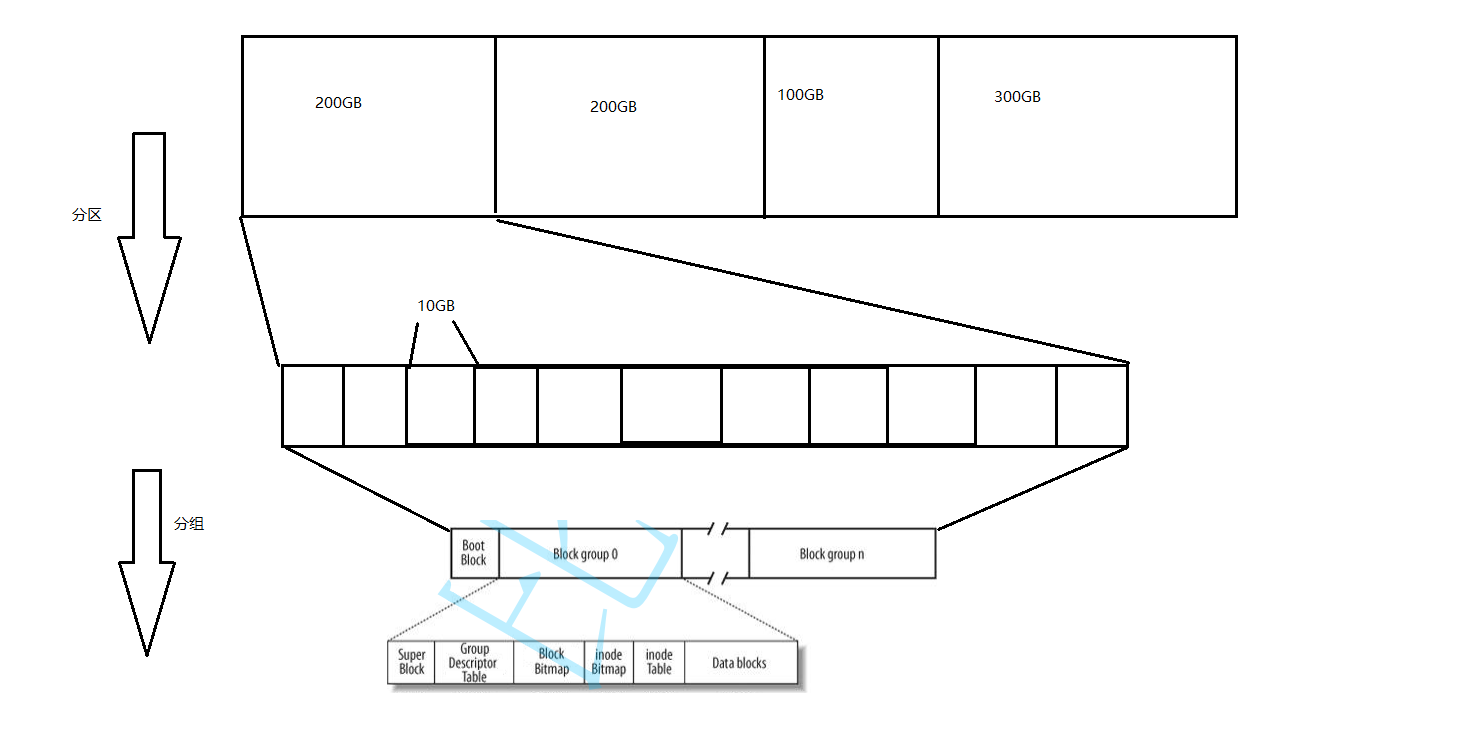
而分组出来的内存卡,就叫做磁盘级的文件
然后从图中我们可以看到,有SuperBlock,GroupDescriptorTable,BlockBitmap,inodeBitmap,inodeTable,DataBlock
那我们就分别来简单的说一下里面分别是啥意思
首先我们来回顾一个内容
文件 = 内容 + 属性
实际上,这个属性也是数据的一种
当你创建一个空文件的时候,这个时候并不代表他真的是空文件,他还是占用了一定的字节的,而这一小段的内存就是存放这个这个文件的属性
在Linux中,文件和属性的存放特性就是文件内容和文件属性分开存储
1.DataBlock
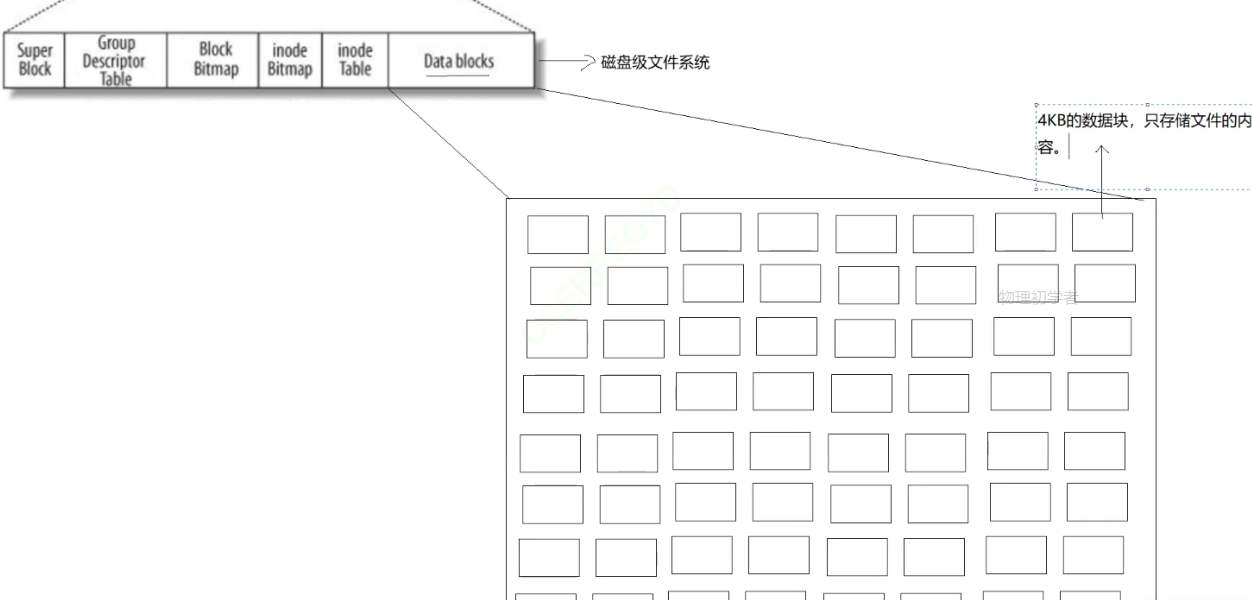
这个是整个内存空间的数据存储的地方,也叫做数据块,这个是占据整个空间最大的地方,而他里面的空间则全部都是4KB的数据块,他将会把这些数据内容存到这些数据块中,当他跟操作系统进行文件IO的时候,就会以4KB的数据块为单位进行交互
2.Block BitMap
这个就是块位图,他里面主要是一个位图的结构,比特位的位置表述块号,比特位的内容表示着DataBlock中哪个数据块已经被占用,哪个数据块没有被占用
3.inodeBitMap
每个bit都表示一个inode是否空闲可用,比特位的位置表示第几个inode,比特位的内容表示是否被占用
这句话怎么理解?
假设一个inode table 里面有312个inode,其inode bitmap就会使用312个比特位来管理这些inode的分配状态,怎么表示呢?当inode bitmap 里面对应的比特位如果是1,则表示inode bitmap里面相应的位置的inode已被占用;当为0时,表示该inode处于空闲可用状态。
i节点表,存放着文件的属性和大小,文件所有者和最近修改时间等
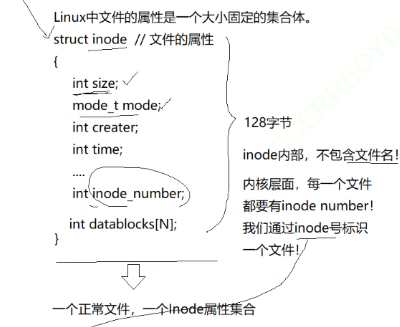
而文件的属性,在Linux中,是一个大小固定的集合体!
就比如说,你我都共同有个名字的字段,但是字段存放的名字是不同的消息,但是我们总体的属性是一样的。
而这个大小固定的集合体,在Linux中叫做struct inode // 文件的属性
我们在上面可以看到,一个DataBlock里面有很多的数据块,那么一般来说,系统是怎么从那么多数据块中找到一个准确的数据块呢?
实际上在inode 结构体里面还有一个数据类型,一个inode节点表一般来说都是128字节
int datablocks[N],这个存储的就是datablock中的数据块,当我们需要寻找数据的时候,首先就会需要找到inode入口,然后找到tatablock[N],最后通过这个下标来找到对应的数据块。
4.inodeTable
这是一个存放属性的inode表,一个文件对应着一个inode
5.通过inode编号寻找到文件内容的过程
首先是通过文件/目录所对应的inode编号,进入到某个磁盘的分区,然后分区中会区分组0,组1,组2等等,每个组都会有自己的组号,一个是start_inode,一个是end_inode,假设我这里让组0的start_inode和end_inode的编号分别为0到10000,组1的编号分别是10001到20000,组1的编号是20001到30000,然后我现在要找inode编号为10010的文件,那我们就放进去找,首先他肯定是组1的,然后就放进组1里面找,由于inode bitmap是按比特位来表示inode文件有没有被占用的,所以我们进来寻找inode bitmap需要把当前的inode编号减去组1的start_inode,也就是10010-10001=9,我们就找到inode bitmap是9,然后根据这个9来对inode table进行映射,若为1,则表示inode有效,若为0,则表示inode无效,找到inode文件属性,最后映射到data block的数据块,找到文件的具体内容
2.如何获取inode编号
我们上面说了,如果要找到一个文件的内容,必不可少的是要使用到inode的编号,那凭什么你直接就拿到了inode编号?我们不是一直使用的是文件名吗?
在此之前,我们先来谈一下目录
总所周知,目录 = 文件属性+文件内容,而其实目录的本质就是文件名和inode编号的映射关系。
所以说,当我们找到文件名的时候,就会找到对应的inode编号,然后用这个编号可以进行文件内容的查找。然后通过文件名和inode的映射关系,就可以找到相应的文件内容
明白了这个,我们就可以来讨论一下目录的r,w的本质
r的本质,实际上就是是否允许我们去读取目录的内容,也就是说,我们是否可以读取到文件名
w的本质,实际上就是新建文件,也就是向目录中写入,文件名和inode的映射关系
3.如何理解文件的增删查改?
首先我们来聊一下增加,也就是在目录里面写入文件。
前面说了,目录也是文件,他实际上跟文件=文件名+属性是一样的,也就是说,目录 = 目录名+属性。
首先我如果想在目录中写入一个文件,首先得检查我是否对目录有一个写入的权限,然后,在inode表里面,寻找一个空闲的inode,来分配到写进这个目录的文件,然后再把这个inode映射到相应的表里面,就可以把这个文件写进目录了