网络接收的流程理解
以下是结合TCP协议对图表中各组件及数据流程的详细解析:
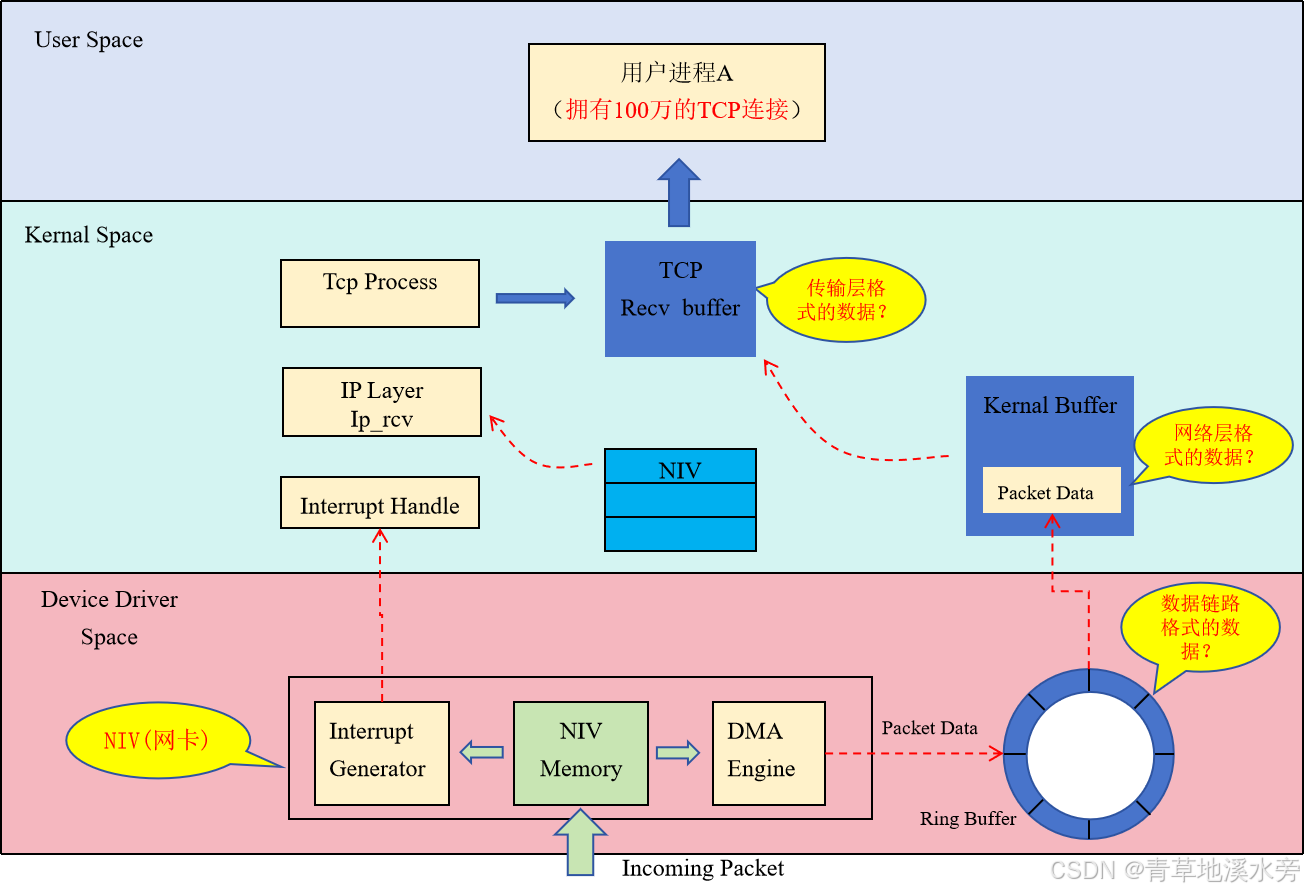
1. 用户空间与内核空间划分
- 用户进程A:
代表应用程序,负责处理业务逻辑,通过系统调用与内核交互。拥有100万TCP连接,需高效管理连接状态和数据收发。 - 内核空间:
包含网络协议栈的核心组件,处理底层网络通信细节。
2. 数据接收流程(自下而上)
2.1 数据链路层(NIC与DMA)
- 网卡(NIC)接收数据:
物理层接收比特流,组装为数据链路层帧(如以太网帧)。 - DMA传输:
网卡通过DMA引擎直接将帧数据写入内核环形缓冲区(Ring Buffer),无需CPU参与,减少开销。 - 中断触发:
网卡发送硬件中断(IRQ),通知内核有数据到达。
2.2 中断处理与协议栈解析
- 中断处理程序(Interrupt Handle):
响应中断,快速记录数据到达事件,并触发软中断(NET_RX_SOFTIRQ),进入协议栈处理流程。 - IP层处理(ip_rcv):
解析IP头部,校验目标IP地址和校验和。若有效,剥离IP头部,将数据包传递给TCP层。 - TCP层处理:
解析TCP头部(端口号、序列号、标志位等),验证数据完整性(校验和)。- 根据四元组(源IP、源端口、目标IP、目标端口)找到对应的TCP连接。
- 数据按序列号排序后存入该连接的接收缓冲区(Recv Buffer)。
2.3 用户进程读取数据
- 用户进程调用read():
通过系统调用从TCP接收缓冲区读取数据。- 若缓冲区为空,进程可能被阻塞(BIO模式)或通过IO多路复用(如epoll)等待通知。
- 数据传输至用户空间:
内核将接收缓冲区的数据拷贝到用户空间内存,供应用程序处理。
3. 高并发场景下的关键优化
3.1 环形缓冲区(Ring Buffer)
- 作用:
作为网卡与内核间的共享内存区域,通过循环队列结构高效管理数据包,避免频繁内存分配。 - DMA与零拷贝:
网卡直接写入环形缓冲区,减少CPU拷贝次数,提升吞吐量。
3.2 中断优化(NAPI机制)
- 问题:
传统每包触发一次中断,高并发下导致中断风暴,CPU忙于处理中断。 - 解决方案:
- NAPI(New API):
混合中断与轮询模式。首个数据包触发中断,后续数据包通过轮询批量处理,减少中断次数。 - 软中断批处理:
内核在软中断上下文中批量处理环形缓冲区中的数据,提升协议栈处理效率。
- NAPI(New API):
3.3 TCP连接管理
- 100万连接挑战:
- 内存占用:每个连接需维护接收/发送缓冲区、状态机等元数据,需高效内存管理(如slab分配器)。
- 事件通知:传统轮询(select/poll)效率低,需epoll等事件驱动机制,仅关注活跃连接。
- epoll核心机制:
- 红黑树维护所有监听的socket,就绪事件通过双向链表(rdllist)快速通知用户进程。
- 水平触发(LT)与边缘触发(ET)模式适应不同场景。
4. 关键组件功能总结
| 组件 | 功能 |
|---|---|
| NIC(网卡) | 接收物理层数据,组装为数据链路层帧,通过DMA写入内核环形缓冲区。 |
| DMA引擎 | 实现网卡与内存间的直接数据传输,减少CPU负担。 |
| 环形缓冲区 | 高效缓存接收的数据包,避免频繁内存操作。 |
| 中断处理程序 | 响应硬件中断,触发协议栈处理流程。 |
| IP层(ip_rcv) | 解析IP头部,路由决策,传递数据至传输层。 |
| TCP层 | 管理连接状态,确保数据可靠传输,排序并存入接收缓冲区。 |
| 接收缓冲区 | 临时存储已接收但未读取的TCP数据,供用户进程读取。 |
5. 性能瓶颈与优化方向
- 瓶颈:
- 中断处理延迟、内存拷贝开销、频繁上下文切换。
- 海量连接下的元数据管理压力。
- 优化:
- 零拷贝技术:如sendfile、splice,减少内核与用户空间的数据拷贝。
- 多队列网卡:将中断分配到不同CPU核心,均衡负载。
- 内核旁路(如DPDK):绕过内核协议栈,直接在用户态处理网络数据。
6. 总结
该图表完整展示了从物理层数据接收,到用户进程处理的TCP通信全流程。通过DMA、环形缓冲区、NAPI中断优化及epoll事件驱动机制,内核实现了高并发TCP连接的高效管理。理解各组件协作关系,有助于针对性能瓶颈进行针对性优化。