Elasticsearch实操案例
需求分析
在 面试刷题平台 项目中,用户基于 MyBatis-Plus 的 QueryWrapper 构造动态查询条件,实现对题目的模糊匹配与多字段过滤。
| 字段名 | 对应数据库字段 | 条件构造方式 | 说明 |
|---|---|---|---|
searchText | title、content | .like("title", searchText).or().like("content", searchText) | 通用搜索,会在标题或内容里查关键字 |
title | title | like(StringUtils.isNotBlank(title), "title", title) | 单独查标题模糊匹配 |
content | content | like(StringUtils.isNotBlank(content), "content", content) | 单独查内容模糊匹配 |
answer | answer | like(StringUtils.isNotBlank(answer), "answer", answer) | 查题目答案模糊匹配 |
具体代码如下:
/*** 从数据库中获取查询条件** @param questionQueryRequest* @return*/@Overridepublic QueryWrapper<Question> getQueryWrapper(QuestionQueryRequest questionQueryRequest) {QueryWrapper<Question> queryWrapper = new QueryWrapper<>();if (questionQueryRequest == null) {return queryWrapper;}// todo 从对象中取值Long id = questionQueryRequest.getId();Long notId = questionQueryRequest.getNotId();String title = questionQueryRequest.getTitle();String content = questionQueryRequest.getContent();String searchText = questionQueryRequest.getSearchText();String sortField = questionQueryRequest.getSortField();String sortOrder = questionQueryRequest.getSortOrder();List<String> tagList = questionQueryRequest.getTags();Long userId = questionQueryRequest.getUserId();String answer = questionQueryRequest.getAnswer();// todo 补充需要的查询条件// 从多字段中搜索if (StringUtils.isNotBlank(searchText)) {// 需要拼接查询条件queryWrapper.and(qw -> qw.like("title", searchText).or().like("content", searchText));}// 模糊查询queryWrapper.like(StringUtils.isNotBlank(title), "title", title);queryWrapper.like(StringUtils.isNotBlank(content), "content", content);queryWrapper.like(StringUtils.isNotBlank(answer), "answer", answer);// JSON 数组查询if (CollUtil.isNotEmpty(tagList)) {for (String tag : tagList) {queryWrapper.like("tags", "\"" + tag + "\"");}}// 精确查询queryWrapper.ne(ObjectUtils.isNotEmpty(notId), "id", notId);queryWrapper.eq(ObjectUtils.isNotEmpty(id), "id", id);queryWrapper.eq(ObjectUtils.isNotEmpty(userId), "userId", userId);// 排序规则queryWrapper.orderBy(SqlUtils.validSortField(sortField),sortOrder.equals(CommonConstant.SORT_ORDER_ASC),sortField);return queryWrapper;}
采用like模糊匹配的问题——案例
首先在搜索框中搜索 “CSS”,能查询出两个相关的题目
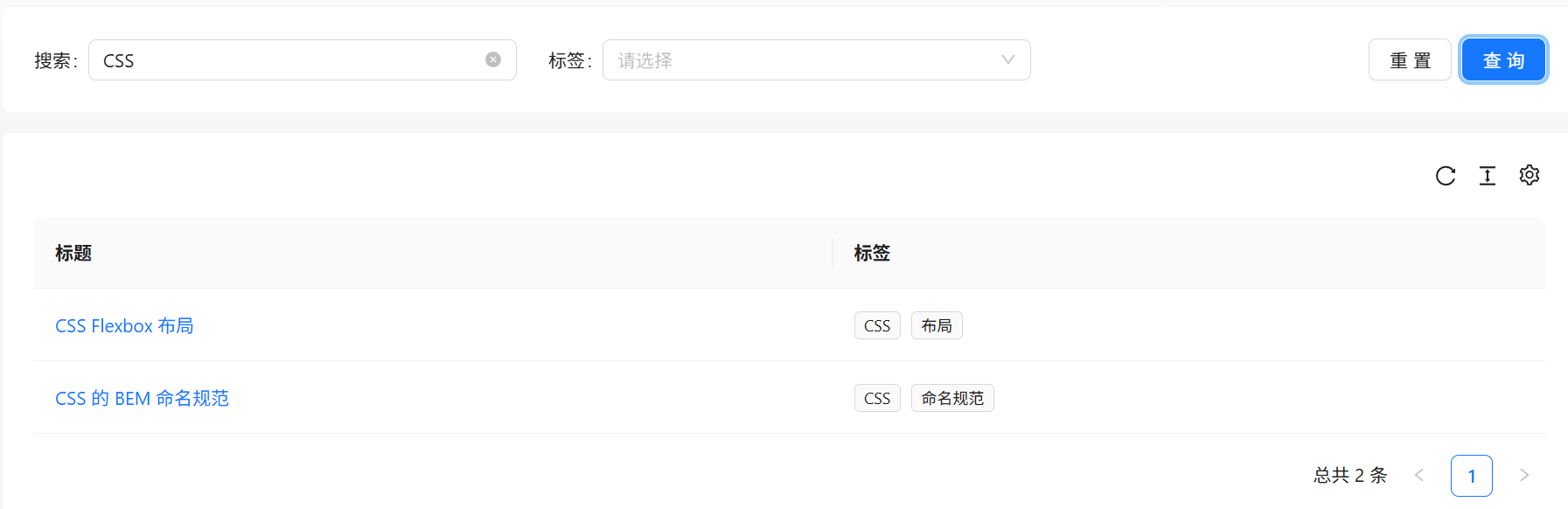
现在我想搜索标题中带有 “CSS” 和 “布局”这两个关键词,但是模糊匹配 like 显然不能满足我们的需求
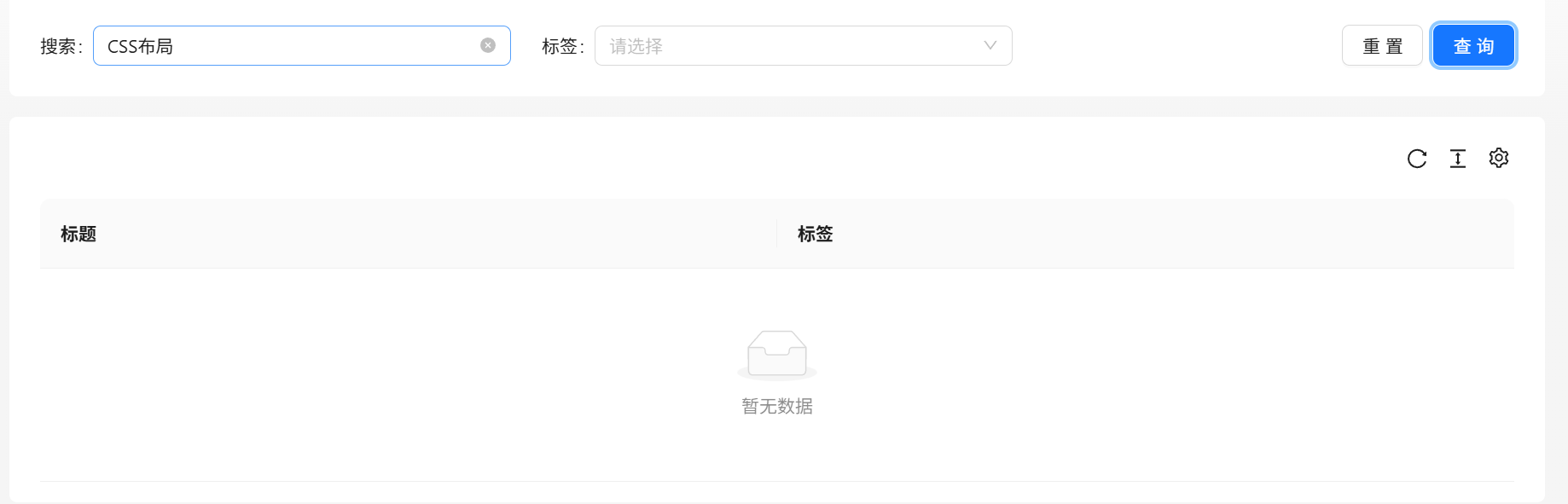
解决方案——采用Elasticsearch搜索
Elasticsearch简介
Elasticsearch 生态系统
Elasticsearch 生态系统非常丰富,包含了一系列工具和功能,帮助用户处理、分析和可视化数据,Elastic Stack 是其核心组成部分。
Elastic Stack(也称为 ELK Stack)由以下几部分组成:
- Elasticsearch:核心搜索引擎,负责存储、索引和搜索数据。
- Kibana:可视化平台,用于查询、分析和展示Elasticsearch 中的数据。
- Logstash:数据处理管道,负责数据收集、过滤、增强和传输到 Elasticsearch。
- Beats:轻量级的数据传输工具,收集和发送数据到 Logstash 或 Elasticsearch。
Elasticsearch 的核心概念
索引(Index):类似于关系型数据库中的表,索引是数据存储和搜索的 基本单位。每个索引可以存储多条文档数据。
文档(Document):索引中的每条记录,类似于数据库中的行。文档以 JSON 格式存储。
字段(Field):文档中的每个键值对,类似于数据库中的列。
映射(Mapping):用于定义 Elasticsearch 索引中文档字段的数据类型及其处理方式,类似于关系型数据库中的 Schema 表结构,帮助控制字段的存储、索引和查询行为。
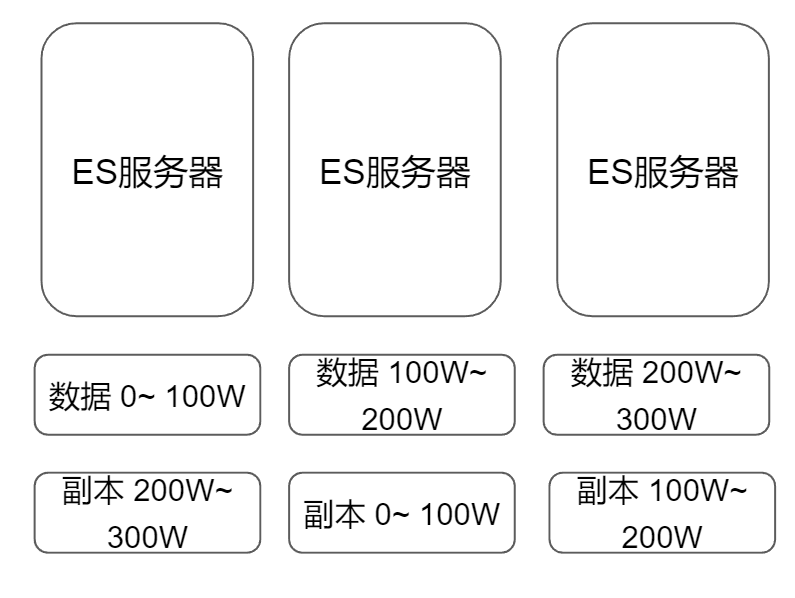
集群(Cluster):多个节点组成的群集,用于存储数据并提供搜索功能。集群中的每个节点都可以处理数据。
分片(Shard):为了实现横向扩展,ES 将索引拆分成多个分片,每个分片可以分布在不同节点上。
副本(Replica):分片的复制品,用于提高可用性和容错性,如图所示:
Elasticsearch 实现全文检索的原理
分词:Elasticsearch 的分词器会将输入文本拆解成独立的词条(tokens),方便进行索引和搜索。分词的具体过程包括以下几步:
- 字符过滤:去除特殊字符、HTML 标签或进行其他文本清理。
- 分词:根据指定的分词器(analyzer),将文本按规则拆分成一个个词条。例如,英文可以按空格拆分,中文使用专门的分词器处理。
- 词汇过滤:对分词结果进行过滤,如去掉停用词(常见但无意义的词,如 “the”、“is” 等)或进行词形归并(如将动词变为原形)。
倒排索引:倒排索引是 Elasticsearch 实现高效搜索的核心数据结构。它将文档中的词条映射到文档 ID,实现快速查找。
工作原理:
- 每个文档在被索引时,分词器会将文档内容拆解为多个词条。
- 然后,Elasticsearch为每个词条生成一个倒排索引,记录该词条在哪些文档中出现。
还有打分规则,可以查看官方文档,这里不做详细介绍。
查询条件
重点了解:
- 精确匹配 vs. 全文检索:term 是精确匹配,不分词;match 用于全文检索,会对查询词进行分词。
- 组合查询:bool查询可以灵活组合多个条件,适用于复杂的查询需求。
- 模糊查询:fuzzy 和 wildcard提供了灵活的模糊匹配方式,适用于拼写错误或不完全匹配的场景
数据同步方案
一般情况下,如果做查询搜索功能,使用 ES 来模糊搜索,但是数据是存放在数据库 MySQL 里的,所以说我们需要把 MySQL 中的数据和 ES 进行同步,保证数据一致(以 MySQL 为主)。
数据流向:MySQL => ES (单向)
数据同步一般有 2 个过程:全量同步(首次)+ 增量同步(新数据)
对于本项目,由于数据量不大,题目更新也不频繁,容忍丢失和不一致,所以定时任务方案,实现成本最低。
定时任务:比如 1 分钟 1 次,找到 MySQL 中过去几分钟内(至少是定时周期的 2 倍)发生改变的数据,然后更新到 ES。