数据库MySQL进阶
前情回顾:
数据表
1)创建表
creat table 表名(列名 类型,列名 类型。。。);
2)查看数据库中的所有表
show tables;
3)查看指定表的表结构
desc 表名;
4)删除表
drop table 表名;
插入
insert into 表名 values (值,值。。。);(个数和类型要和表结构一致)
insert into 表名 (列名,列名。。。) values (值,值。。。);(只给某些指定的列进行插入数据)
insert into 表名 values (值,值),(值,值)。。。; (一次插入多行记录)
查询
1)全列查询
select * from 表名; (这样的操作,在公司的生产环境数据库中,一定要慎重使用)
2)指定列查询
select 列名,列名 from 表名;(按需进行查询)
3)表达式查询
select 表达式 from 表名;(加减乘除之类的运算,针对列进行的运算,会把当前表的每一行这里的对应列进行计算~ 【此处的运算只是针对从数据库服务器查询出的数据进行运算的,是临时的数据,不会影响到数据库服务器原有的保存的数据】)
4)带别名的查询
select 表达式 as 别名 from 表名;(查询结果的临时表中,列名就是刚才的别名了)
as 别名,可以是针对 表达式,列,表名,as也可以省略(通常不建议省略)
1.增删查改(CRUD)
查询
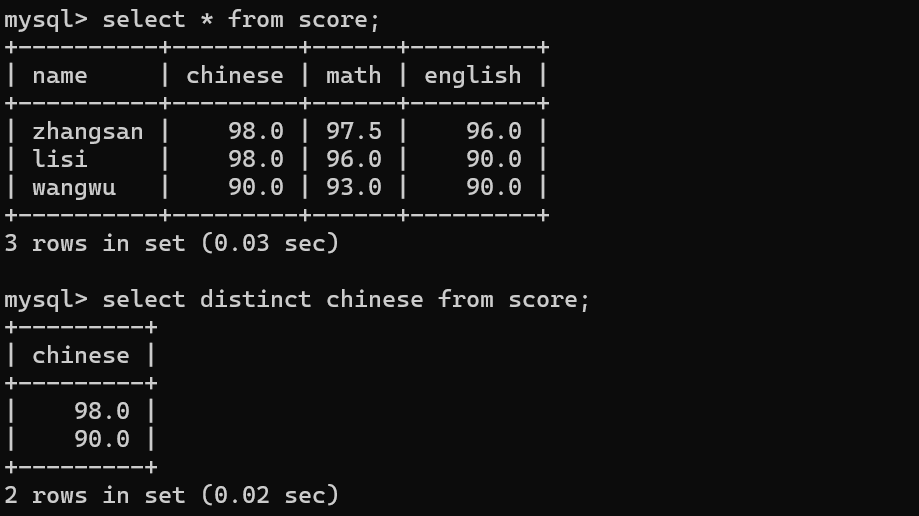
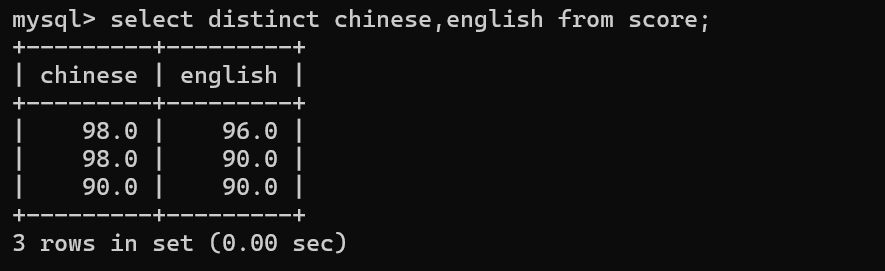
去重
distinct 修饰某个列/多个列 值相同的行,只会保留一个
查询的时候排序
把行进行排序
-》明确排序规则~~
a)针对哪个列作为比较规则
b)排序的时候是升序还是降序
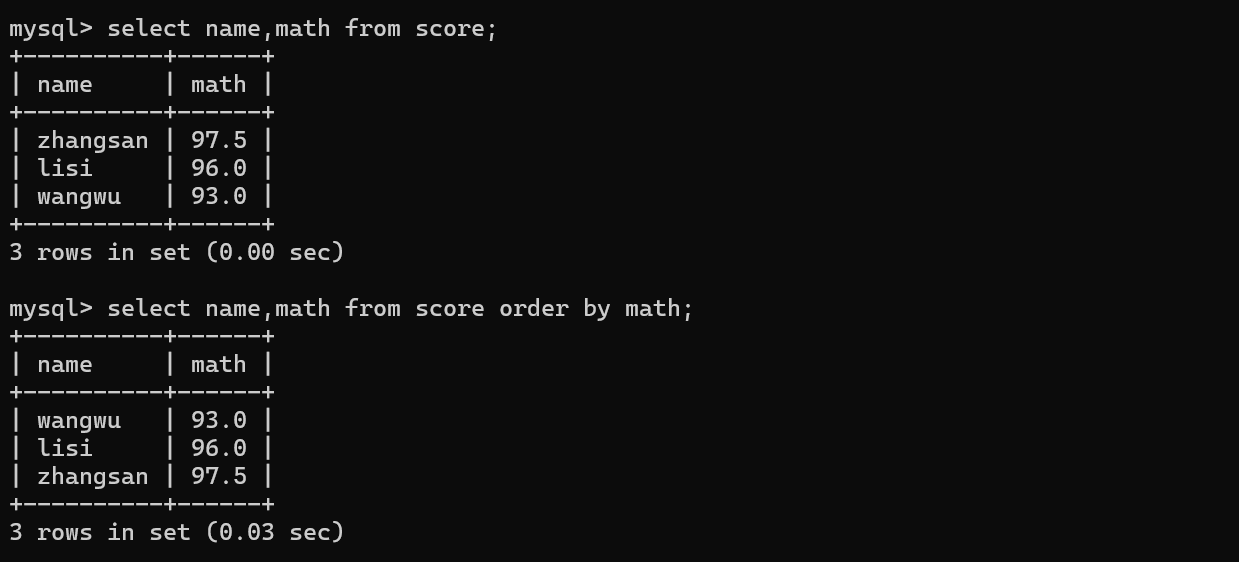
select 列名 from 表名 order by 列名 asc/desc;(指定某个列进行排序)
-》asc升序(如果省略,就是升序排序) desc 降序
-》mysql是一个客户端服务器结构的程序 把请求发给服务器之后,服务器进行查询数据,并且把查询到结果进行排序之后,再组织成相应数据返回给客户端【排序仍然是针对临时数据来展开的,此处的排序,不影响原有数据在mysql服务器上存储的顺序】
-》 如果一个sql不加order by此时查询的结果数据的顺序,是“不确定的”/“无序的”
当前只是咱们在自己的机器上进行了一些简单的操作,看起来好像顺序没变,但是如果进行一些更复杂的操作,就不一定了~
如果不加order by 代码就不应该依赖上述顺序,尤其在代码中,就不能依靠上述的顺序来展开一些逻辑,数据库没有承诺过你这个数据是有顺序的~
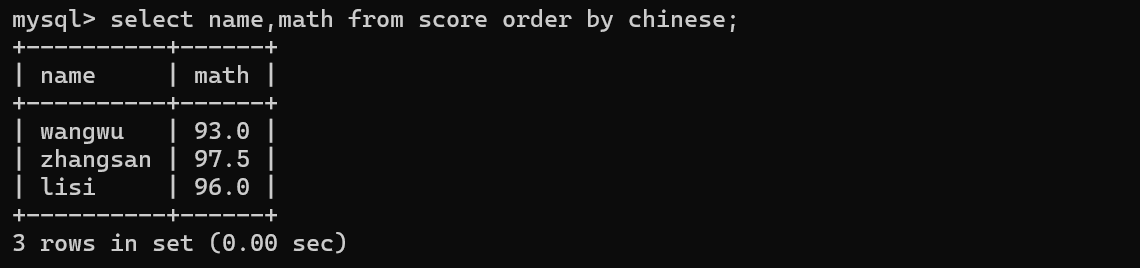
-》order by 指定的列,如果你select 的时候没有把这一列查出来,也不影响排序
->order by 还可以针对表达式进行排序
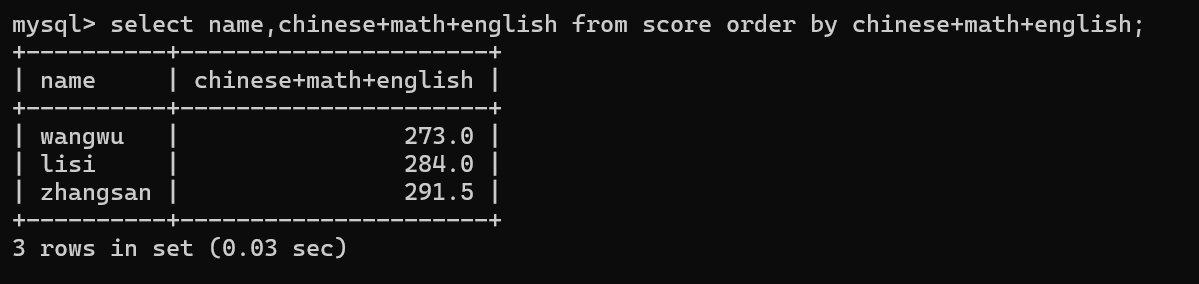
->指定多个列来排序,order by 后面可以写多个列,使用,来分隔开
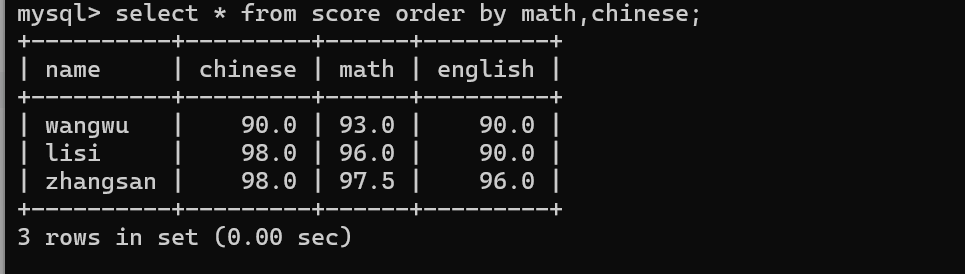
先按照数学成绩来排序,如果数学成绩相同,再按照语文排序
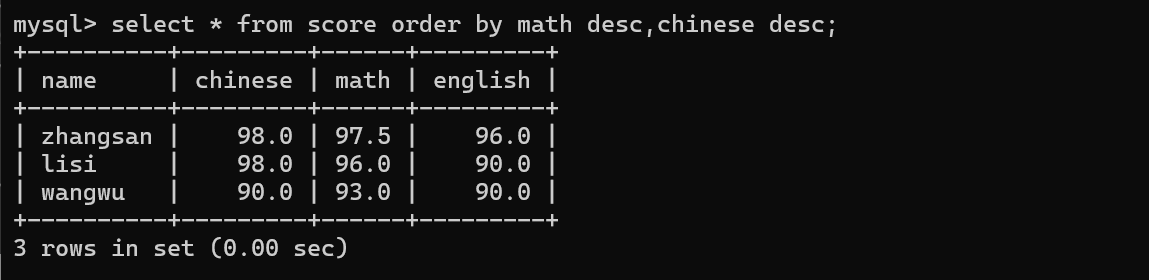
->null参与各种运算,结果还是null
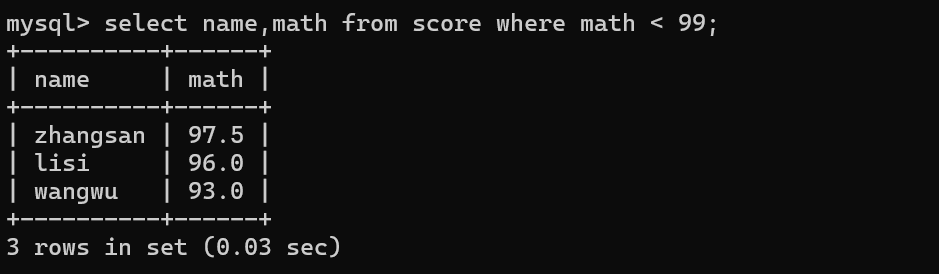
条件查询:where
会指定具体的条件,按照条件针对数据进行筛选
select 列名 from 表名 where 条件;
->遍历这个表的每一行记录,把每一行的数据分别带入到条件中
如果条件成立,这个记录就会被放入结果集合中,如果条件不成立,这个记录就pass
比较运算符
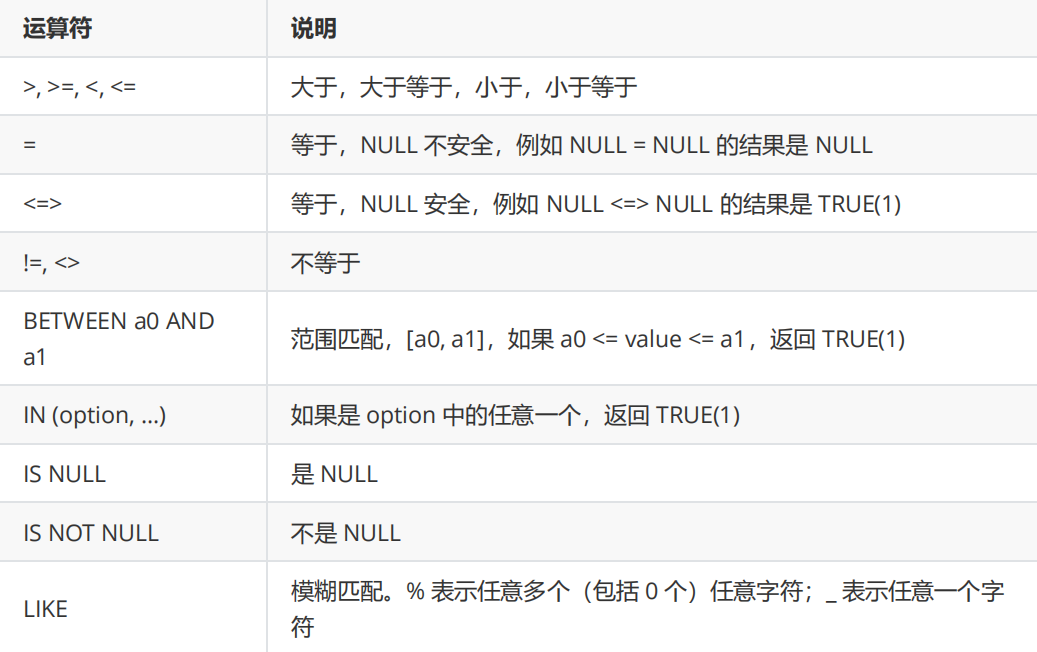
-》sql中没有==,是使用=表示比较相等
-》<>上古时期的写法
-》模糊匹配,通过一些特殊符号,描述出规则/特征 后续哪些值,符合上述特征
逻辑运算符
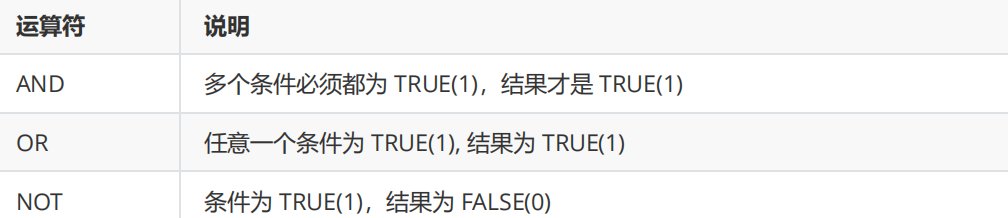
-》无论有几个列,都可以使用上述运算符来描述条件的 
-》条件查询搭配表达式

唐三藏 null 98.0 null 不会显示出来是因为 null<200=>null=>false
-》注意理解,select 条件查询执行的顺序:
- 遍历表中的每个记录
- 把当前记录的值代入条件,根据条件进行筛选
- 如果这个记录条件成立 ,就要保留,进行列上的表达式计算
- 如果有order by,会在所有的行都被获取到之后(表达式也算完了)再针对所有的结果进行排序
第三步定义的别名,where是第二步执行的,执行where的时候,total还处于“未定义”的状态,所以报错(算是理由,但是也不算是,实现sql解析引擎的时候,是完全可以做到,把这里的别名预先的定义好,然后再执行1 2 3 ,保证执行到where的时候也能访问到别名,但是mysql当前没这样实现,不知道为啥没这么做)

-》and or
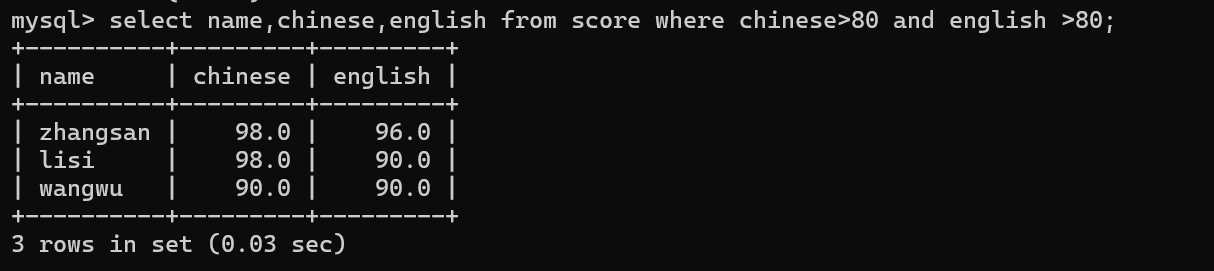
sql中and的运算符优先级更高,不建议大家来记这个优先级,可以加上括号!
-》between and 双闭区间
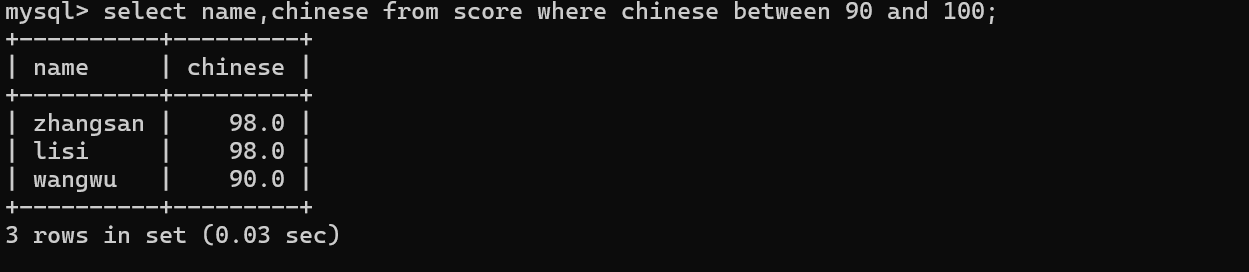

-》使用in来表示一个离散的集合
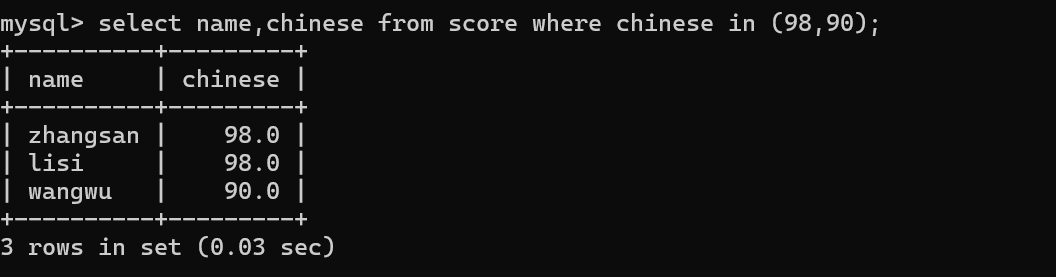
-》like 模糊匹配
通配符,就是一些特殊的字符,能够表示特定的含义
%代指任意个任意字符
- 代指一个任意字符
通配符,类似于扑克中的“会儿”
特殊牌,可以用来代替任意的点数和花色
4 5 7 少了6,但是你手里有一个王,王就可以代替6
查询姓孙的同学的成绩,名字中,以孙开头~
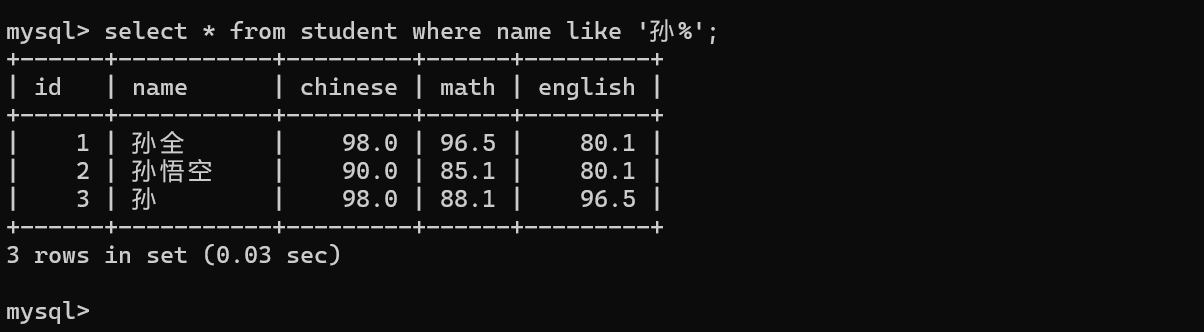
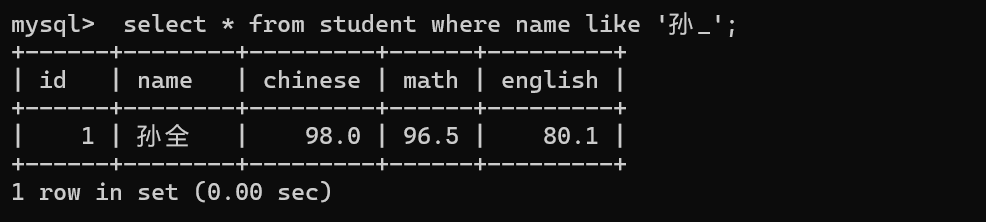
 孙%:查询以孙开头的内容:孙
孙%:查询以孙开头的内容:孙
%孙:查询以孙结尾的内容:孙
%孙%:查询包含孙的
此处模糊查询的功能是有限的,在计算机中,进行模糊匹配字符串,还有“正则表达式”【一般都是去现查,要不然光靠背,还是很容易搞错的】这样的方式来实现(JavaSE有个章节String 其中有个方法是split 参数其实就是一个正则表达式)
正则表达式,匹配的效率是很慢的,对于mysql本身就不快~

-》只能看到一个列~
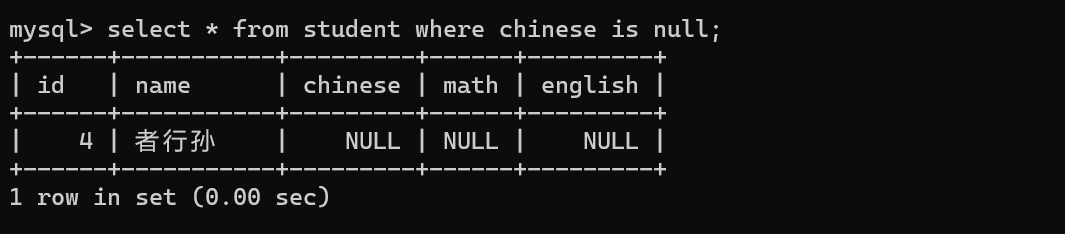
-》可以针对两个列比较的
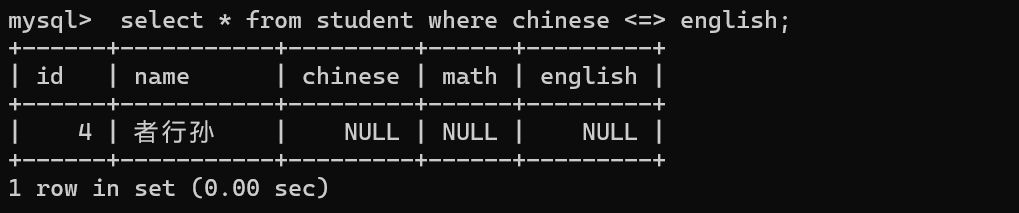
分页查询:limit
使用select*这种方式查询,是比较危险的~需要保证一次查询,不要查出来东西太多
limit 可以限制这次查询最多能查出来多少个结果
有的时候,数据非常多,一次全都显示出来,会影响到效率,也会不方便用户去看
分页查询的效果 limit 这次查询,查出几个记录;offset偏移量 也就是一个下标 从0开始的
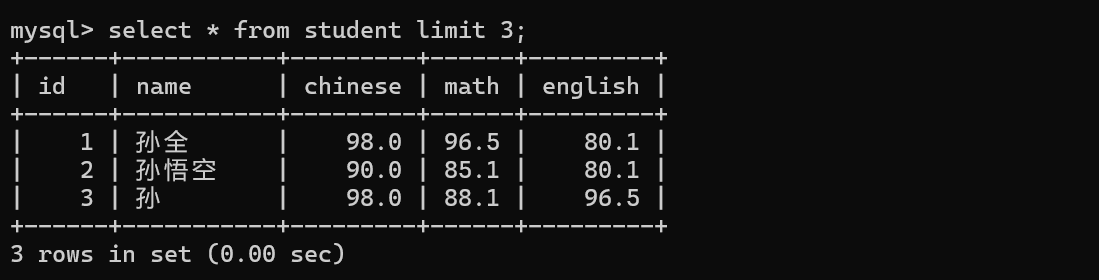
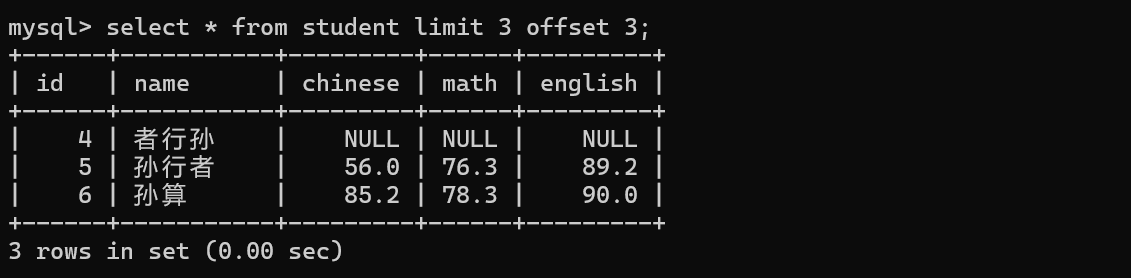
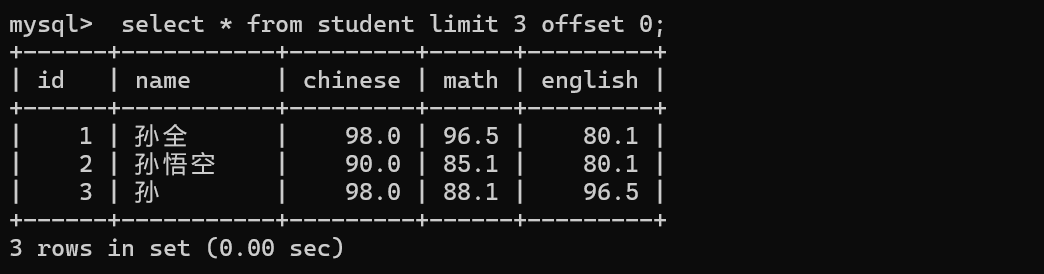
offset偏移量 是计算机中广泛使用的概念 寻址(找指定的内存)
什么是汇编
编程语言,分成三个大类
1.机器语言(计算机,CPU能认识的二进制指令)
计算机干活,具体要干啥,咋干,都是由cpu来完成的,干的活的内容,就是“指令”
每一小步都可以进一步的拆成更小的步骤,拆到一定程度,就不能再拆了,叫做指令
CPU研发的时候,就会确定我这个cpu都支持哪些指令~【以二进制的方式来进行表示的】
咱们市面上最主要cpu是两个大类:
x86系列的cpu,intel,amd给电脑用的(虽然现在cpu x86系列是8086的后裔,实际上支持的指令已经差异极大了)
arm系列的cpu,高通,苹果给手机用的
这两类CPU支持的指令是截然不同的
2.汇编语言
机器语言是二进制(一串010101)不方便人来看,所以就引入了一些“助记符”
简单的英文单词,用英文单词来代替各种指令的二进制形式
汇编语言中的每个代码都是和cpu支持的指令(机器语言)是一一对应的
由于cpu差别很大,对应的也就产生了不同的汇编~
汇编语言这么多,咱们在学校学的汇编语言一般是8086 cpu的汇编
3.高级语言(C Java)
408:计组 计网 数据结构 操作系统
编译原理
计算机系统结构(计组的进阶课)
总结mysql的具体操作:
查询:
1.全列查询
select * from 表名;
2.指定列查询
select 列名 from 表名;
3.表达式查询
select 表达式 from 表名;(不会影响到数据库服务器硬盘上存储的原始数据)
4.查询字段指定别名
select 表达式 as 别名 from 表名;
5.查询的时候进行去重,把值相同的行,只保留一个
select distinct 列名 from 表名;
6.查询的时候进行排序
select 列名 from 表名 order by 列名 asc/desc;(不会影响到数据库服务器硬盘上存储的原始数据)
7.条件查询
select 列名 from 表名 where 条件;(通过一些关系运算符/逻辑运算符构成表达式)
8.分页查询
select 列名 from 表名 limit N offset M;
N 表示这次查询最多查出几个记录
M表示这次查询的这N 个记录,是从第几个下标开始算
上述写法都属于最基础的查询操作
修改✨
update 表名 set 列名 = 值 where 条件;限制这次操作具体 要修改哪些行数据
set 这个词,计算机里,有两种典型含义
1)设置 gatter/setter
2)集合 TreeSet/HashSet
计算机中,一个术语,往往有多种含义,必须要结合上下文来理解这个含义是啥意思

Rows matched where 条件筛选出了一行记录 Changed 修改成功了一行
-》使用update ,可以一次修改多个列

set 列 = 值,列= 值。。。 相当于是赋值了
-》将总成绩倒数前三的3位同学的数学成绩减上30

Rows matched : 3 3行 所有的行数 正好是3 Changed :2 只修改2个记录 ,没修改的那个是NULL,没法被修改
假如Warnings:2 show warnings 警告
原来87.5 /2 =》43.75 最后输出变成43.8 超出了decimal(3,1)这样的范围,于是就进行了截断(truncated),暴出警告
-》update 后面不写任何条件,就是针对所有行都进行修改
删除
delete from 表名 where 条件/order by /limit;(会把符合条件的行,从表中删除掉)

-》不指定任何条件,就是删除整个表
delete from student;
和 drop table 还不太一样
drop table 是删除了表,也删除了表里的记录
delete 是只删除了表里的记录,表还在(空表)
delete 和 update 都是很危险的操作!
delete 一旦删除的条件没设置好 ,就可能把不该删除的给删掉了~
sql步步都是危险操作
这里的修改/删除持久生效的,都会影响到数据库服务器硬盘中的数据~
数据库的备份,有很多种方式 拷贝~
1.数据库最终都是存储在硬盘上,以文件的形式体现的(文件是二进制),可以把这里的文件直接拷贝走放到别的机器上(全量备份)
2.mysqldump工具(mysql自带的一个程序)会把你mysql中的数据导出成一系列的insert语句,再把这些insert语句,放到另一个mysql中进行执行(全量&增量都行)
3.mysql 还有一个binlog功能(把Mysql中的各种操作,都通过日志记录下来)借助binlog(让另一个数据库按照binlog的内容执行,就也能得到一样的数据)(增量备份/实时备份)
mysql服务器在启动的时候,需要绑定一个端口号3306(后面再解释),要想搞多个mysql服务器,需要把端口给设置成不同的,数据目录也需要设置成不同的。
一般不会一个主机部署多个mysql服务器~
增删改 没有进阶的,查询是有进阶的~
2.进阶版
数据库约束
有的时候,数据库中的数据,是有一定要求的~
有些数据认为是合法数据,有些是非法数据,相对于计算机来说,靠人工检查不靠谱,所以数据库有自动的对数据的合法性进行校验检查的一系列机制~
目的就是为了保证数据库中能够避免被插入/修改一些非法的数据
mysql中提供了一下约束:

NOT NULL

 UNIQUE
UNIQUE
唯一的


-》duplicate 重复 entry 入口 条目账目记录
Map遍历
Java遍历集合类,都是通过迭代器来进行的
对应的集合类,得实现Iterable interface才能够进行 迭代器遍历
Map没实现Iterable
entrySet方法 把Map转换成个Set,里面的元素就是一个一个的Entry(条目,包含了key和value)
这个东西不仅仅是限制插入,也会限制修改~
-》unique约束,会让后续插入数据/修改数据的时候,都先触发一次查询操作,通过这个查询,来确定当前这个记录是否已经存在
-》数据库引入约束之后,执行效率就会受到影响,就可能会降低很多,这就意味着数据库其实是比较慢的系统,也比较吃资源的系统,部署数据库的服务器,很容易成为一整个系统的“性能瓶颈”
DEFAULT
规定没有给列赋值时的默认值
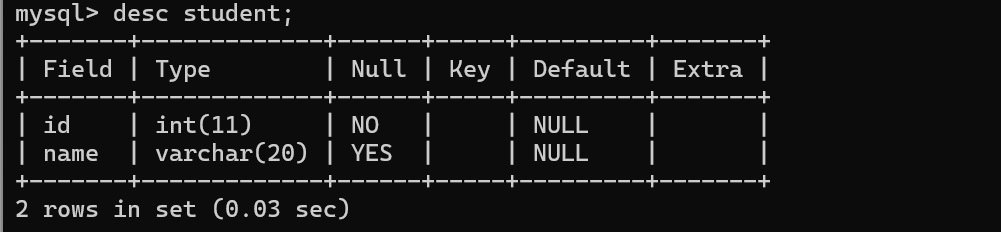
描述这一列的默认值,默认的默认值是null,可以通过default约束,来修改默认值
-》desc 表名;desc=>describe 描述
order by 列名 desc; desc=>descend 降序
写代码,不要随便搞缩写,缩写了之后,代码的含义就可能变得难以理解了
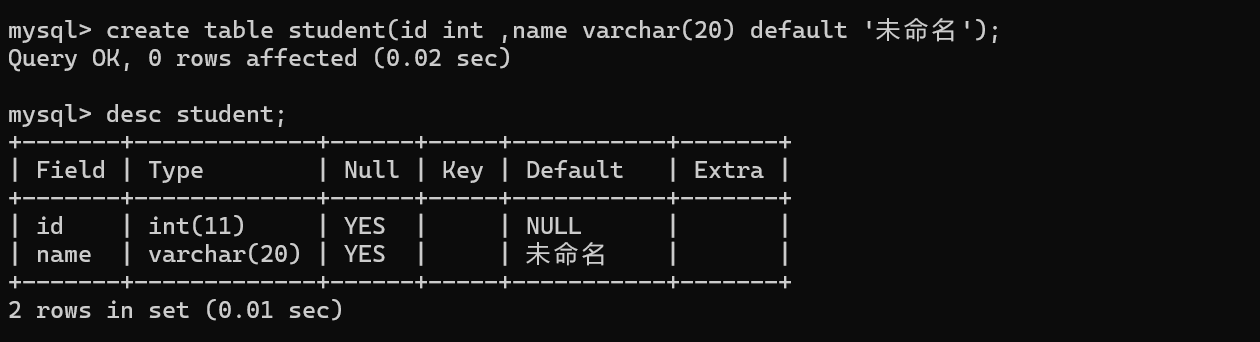
后续插入数据的时候,default 就会在没有显示指定插入的值的时候生效了
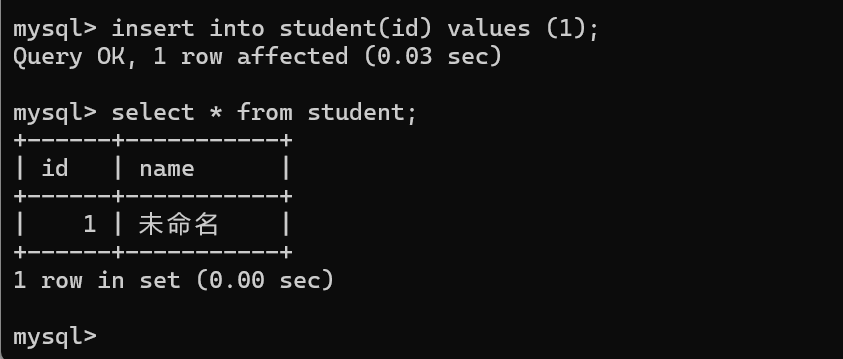
上述设置约束的过程,都是先删除表,再重新创建表,能不能不删除表,直接设置约束呢?也是可以的,但是比较麻烦,暂且不提
-》可以实现一个列有多个限制

PRIMARY KEY
(相当于unique + not null)
这个是最重要的约束,一行记录的身份标识!!!

一张表里只能有一个primary key
一张表里的记录,只能有一个作为身份标识的数据~
虽然只能有一个主键,但是主键不一定只是一个列,也可以用多个列共同构成一个主键(联合主键)
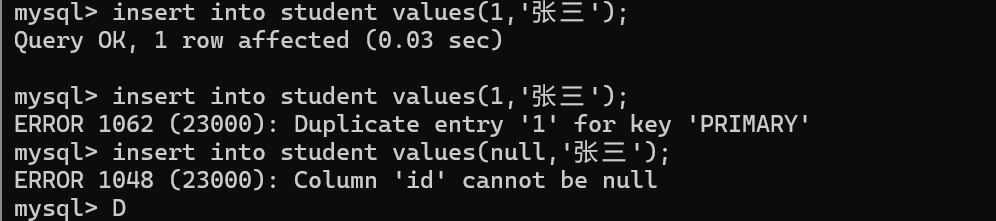
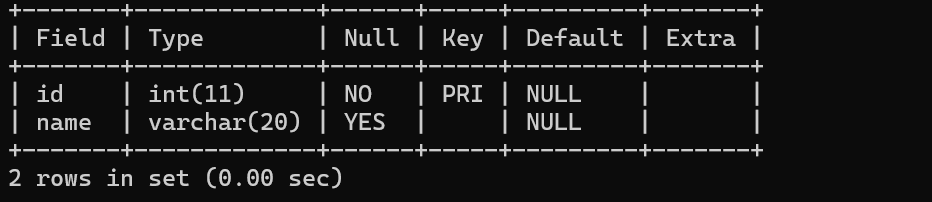
对于带有主键的表来说,每次插入数据/修改数据,也会涉及到进行先查询的操作
mysql会把带有unique 和primary key的列自动生成索引,从而加快查询速度
如何保证主键唯一呢?
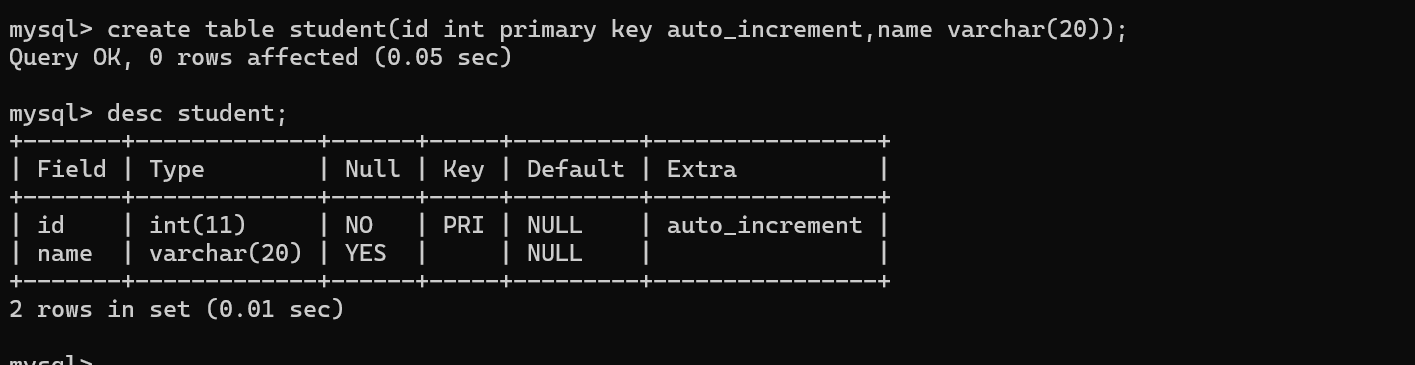
mysql提供了一种‘‘自增主键’’这样的机制~
主键经常会使用int/bigint,程序猿插入数据的时候,不必手动指定主键值~
由数据库服务器自己给你分配一个主键,会从1开始,依次递增的分配主键的值
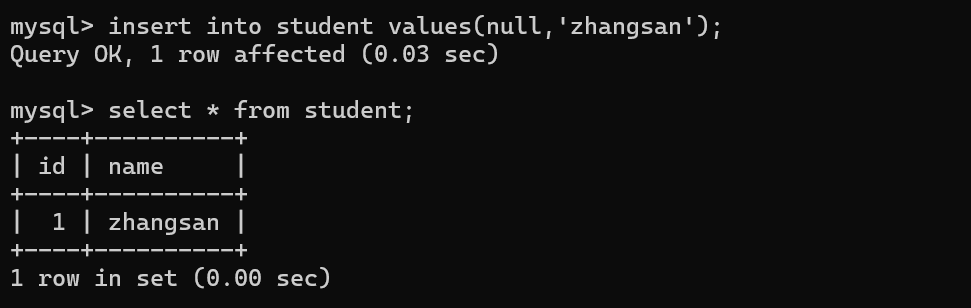
这里写作null其实是交给数据库服务器自行分配! 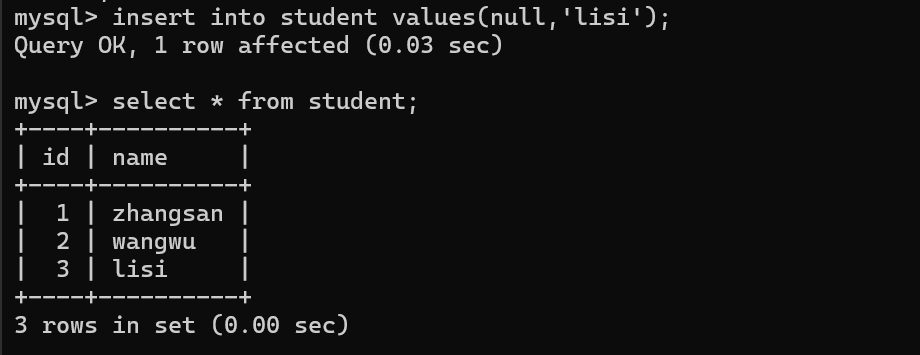
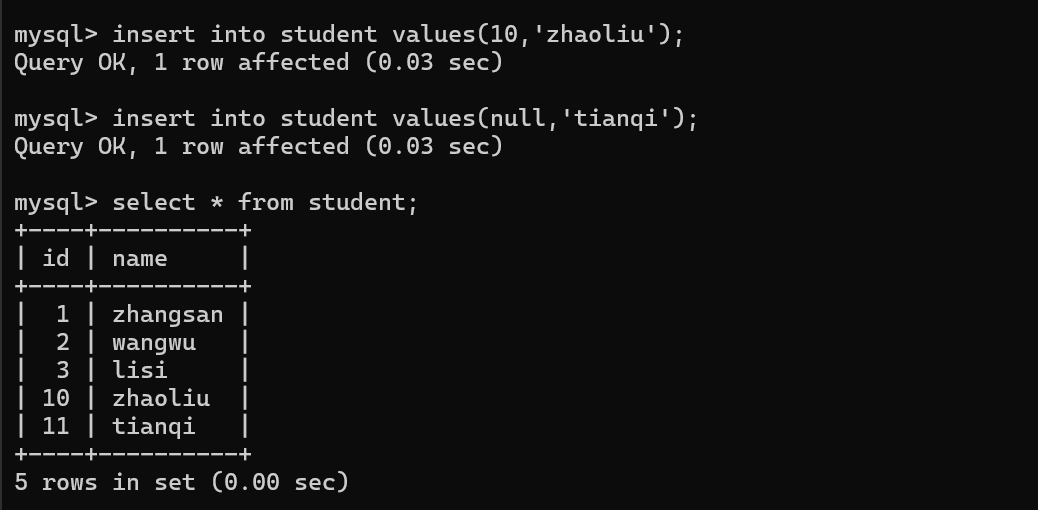
就是从刚才最大的数值开始,继续往后分配的~
相当于使用了一个变量,来保存了当前表id的最大值,后续分配自增主键都是根据这个最大值来分配的,如果手动指定id,也会更新最大值
4~9之间的id是不是就用不上了?浪费了呢?确实如此,浪费就浪费,没事儿【手动插入能插进去,自动分配就分配不到了】
此处这里的id的自动分配,也是有一定局限性的,如果是单个mysql服务器,没问题的;如果是一个分布式系统,有多个mysql服务器构成的集群,这个时候依靠自增主键就不行了~
分布式系统:
面临的数据量大(大数据),客户端的请求量比较大(高并发),一台服务器搞不定,就需要多台机器(分布式)【引入多个数据库服务器的主机,分库分表,某一个表或某几个表,数据量特别大】
此时来了一个新商品,商品id该如何分配呢?肯定是要把这个记录保存在某个数据库的表中,但是如何保证这里的id和另外两个数据库中id不重复呢?
分布式系统中生成唯一id的算法,这里的实现算法有很多种具体的方式~
公式:
分布式唯一id=时间戳+机房编号/主机编号+随机因子(随机因子这里有一定概率生成相同的因子,但是概率比较小)【+是指字符串拼接,不是算术相加,拼出来的结果是一个比较长的字符串】
如果添加商品的速度慢,直接使用时间戳就够了,但是如果一个时间内,添加了多个商品,添加的多个商品,是要落到不同的主机上的,就可以保证统一时间内,添加到不同主机上的商品的编号,是不同的了
✨经典的面试题~进阶类问题
同一个ms之内,给同一个机器上添加的多个数据,随机因子恰好相同了~
理论上来说,这样的情况可能存在的,概率不为0,但是咱们是程序猿(工程师),做的事工程,不涉及理论计算,做工程的一定会涉及到误差的,只要误差在合理的范围之内,就可以忽略不计~
总结
修改:
update 表名 set 列名 = 值,列名 = 值 where 条件/order by/limit
实际修改的列 定位到要修改的行
删除:
delete from 表名 where 条件;
把匹配条件的行,删除掉了,如果不写条件,就相当于把整个表里的所有数据都删除了
insert into 表名;
select *from 表名;
update 表名;
delete from 表名;
这是一个典型反面教材,设计一个东西,给别人使用,要尽量降低使用成本,保持接口风格一致
Java也是
获取数组长度:arr.length;
获取字符串长度:str.length();
获取list长度:list.size();
约束:
not null 非空
unique 唯一
default 默认值
primary key 主键 每一行记录的身份标识
FOREIGN KEY
外键 描述了两个表之间的关联关系~

外键就是用来描述这样的约束过程的,class表中的数据,约束了student表中的数据,把class表,称为‘‘父表;约束别人的表’’,把student表称为‘‘子表;被别人约束的表’’
references JavaSE 引用 此处表示了当前这个表的这一列中的数据,应该出自于另一个表的哪一列

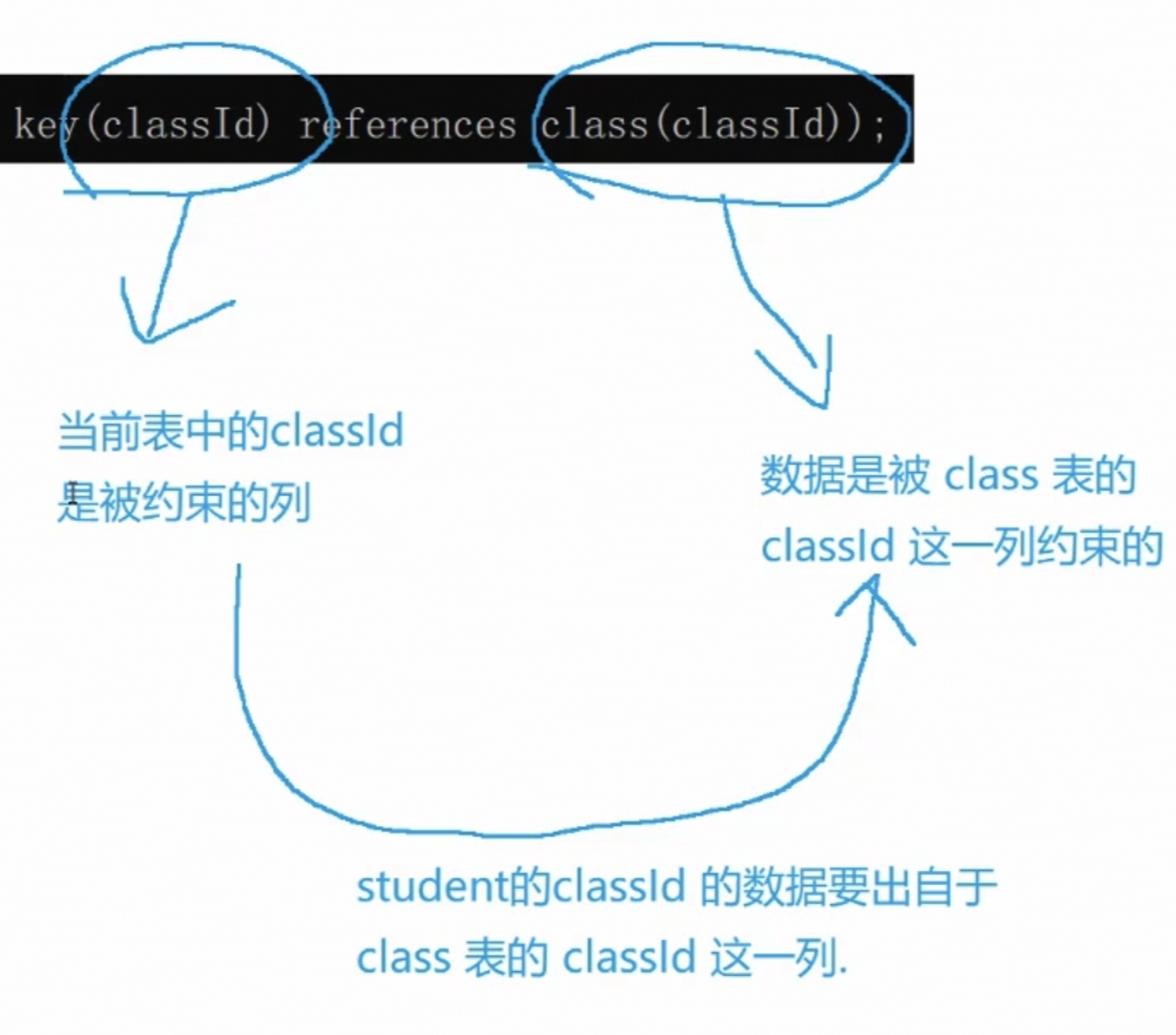
![]()
执行这个插入操作,就会触发针对class表的查询,就会查200是否在class表中存在~
父表约束子表~~言传身教:
比如,针对父表进行修改/删除操作,如果当前被修改/删除的值,已经被子表引用了,这样的操作也会失败!
外键约束始终要保持,子表中的数据在对应的父表的列中,要存在~~此时万一把父表的这条数据删除了,也就打破了刚才的约束了~

-》那可以修改父表的班级名吗?
可以。外键准确来说,是两个表的列产生关联关系~其他的列是不受影响的
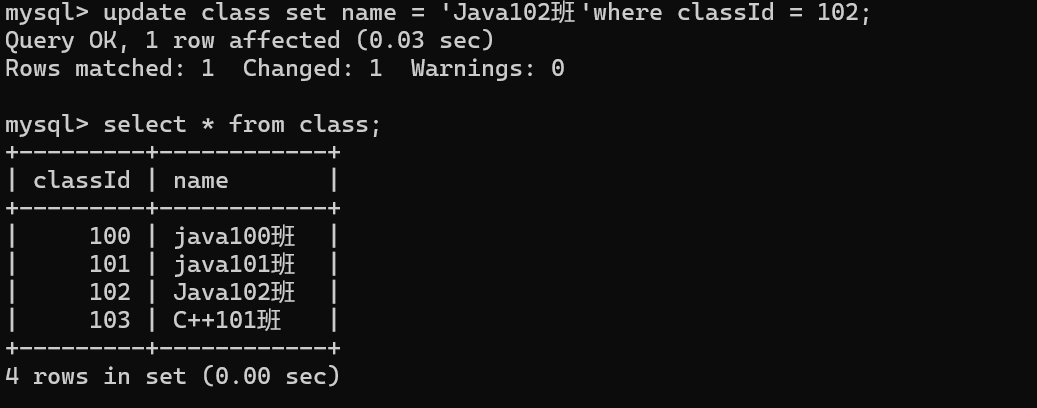
-》我如果直接尝试drop table class 你认为能否删除整个表??
要想删除表,就得先删除记录~~此处的删表,必然不可以的,父表没了,子表后续添加新元素,就没得参考了

正确的删除方式 先删子表 再删父表

-》为啥这次不行了?
class表没有主键,因为指定外键约束的时候,要求父表中被关联的这一列,得是主键或者unique
应用场景 :
考虑现在是一个电商网站的场景
商品表(googsId,。。。)
1 衬衫
订单表(orderId,goodsId 。。。)foreign key (goodsId )references 商品表(goodsId)
100 1
过了一段时间之后,商家想把这个衬衫给下架(删除掉),如何完成删除??尝试删除父表数据的时候,如果父表的数据被子表引用了,是不能删除的,就报错了~电商网站,如何做到保证外检约束存在的前提下实现"商品下架"功能?
方法:给商品表新增一个单独的列,表示是否在线(不在线,就相当于下架了)
商品表(googsId,。。。,isOk)
值为1,表示商品在线 值为0,表示商品下线 如果需要下架商品,使用update 把isOk从1-》0即可
查询商品的时候 都加上WHERE isOk = 1这样的条件
这种就叫做逻辑删除
电脑上有个xx 文件,你想删除掉,也是通过逻辑删除的方式实现的.
在硬盘上,数据还有,被标记成无效了.后续其他文件就可以重复利用这块硬盘空间了.比如想把电脑的某个文件彻底删除掉,通过扔进回收站,清空回收站……没有用的~~
硬盘上的数据啥时候彻底消亡,就需要时间,需要后续有文件把这块标记无效的空间重复利用,才会真正消失~~
如何才是正确的,彻底删除数据的方式呢?
物理删除-》把硬盘砸了
咱们在公司中,工作使用的电脑,就会存储很多公司的核心数据(商业机密)
比如,你要换电脑了~~
旧的电脑怎么处理??尤其是一些大公司,都是有专门的团队来负责处理的~~按照逻辑删除的思路,表中的数据,会无限的扩张?是否就会导致硬盘空间被占满?
当然会有的,不过硬盘比较便宜,也可以通过增加主机(分布式)来进一步的扩充存储空间