分布式锁总结
文章目录
- 分布式锁
- 什么是分布式锁?
- 分布式锁的实现方式
- 基于数据库(mysql)实现
- 基于缓存(redis)
- 多实例并发访问问题演示
- 项目代码(使用redis)
- 配置nginx.conf
- jmeter压测复现问题
- 并发是1,即不产生并发问题
- 并发30测试,产生并发问题(虽然单实例是`synchronized`,但是这是分布式多实例)
- redis 分布式锁:setnx实现
- 分布式锁的过期时间和看门狗
- 附:redis setnx相关命令和分布式锁
- Redisson
- 代码&测试
- Redisson 底层原理
- 实现可重入锁
- redis分布式锁的问题?
- redis主从架构问题?
- Redlock(超半数加锁成功才成功)
- 高并发分布式锁如何实现
- 基于ZooKeeper实现
- zookeeper节点类型
- zookeeper的watch机制
- zookeeper lock
- 普通临时节点(羊群效应)
- 顺序节点(公平,避免羊群效应)
- Curator InterProcessMutex(可重入公平锁)
- code&测试
- InterProcessMutex 内部原理
- 初始化
- 加锁
- watch
- 释放锁
- redis vs zookeeper AI回答
分布式锁
什么是分布式锁?
锁:共享资源;共享资源互斥的;多任务环境
分布式锁:如果多任务是多个JVM进程,需要一个外部锁,而不是JDK提供的锁
在分布式的部署环境下,通过锁机制来让多客户端互斥的对共享资源进行访问
-
排它性:在同一时间只会有一个客户端能获取到锁,其它客户端无法同时获取
-
避免死锁:这把锁在一段有限的时间之后,一定会被释放(正常释放或异常释放)
-
高可用:获取或释放锁的机制必须高可用且性能佳
分布式锁的实现方式
基于数据库(mysql)实现
新建一个锁表
CREATE TABLE `methodLock` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`method_name` varchar(64) NOT NULL DEFAULT '' COMMENT '锁定的方法名',
`desc` varchar(1024) NOT NULL DEFAULT '备注信息',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '保存数据时间,自动生成',
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_method_name` (`method_name `) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='锁定中的方法';
-
insert, delete(method_name有唯一约束)
缺点:- 数据库单点会导致业务不可用
- 锁没有失效时间:一旦解锁操作失败,就会导致锁记录一直在数据库中,其它线程无法再获得到锁。
- 非重入锁:同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在记录了
- 非公平锁
-
通过数据库的
排它锁来实现
在查询语句后面增加for update(表锁,行锁),数据库会在查询过程中给数据库表增加排它锁。当某条记录被加上排他锁之后,其它线程无法再在该行记录上增加排它锁。可以认为获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,再通过connection.commit()操作来释放锁
public boolean lock(){connection.setAutoCommit(false)while (true) {try {result = select * from methodLock where method_name=xxx for update;if (result == null) {return true;}} catch (Exception e) {}sleep(1000);}return false;
}public void unlock(){connection.commit();
}
基于缓存(redis)
多实例并发访问问题演示
项目代码(使用redis)
见项目代码:减库存的例子
- 让Springboot项目启动两个实例(即有两个JVM进程)
curl -X POST \http://localhost:8088/deduct_stock_sync \-H 'Content-Type: application/json'curl -X POST \http://localhost:8089/deduct_stock_sync \-H 'Content-Type: application/json'
减库存调用测试
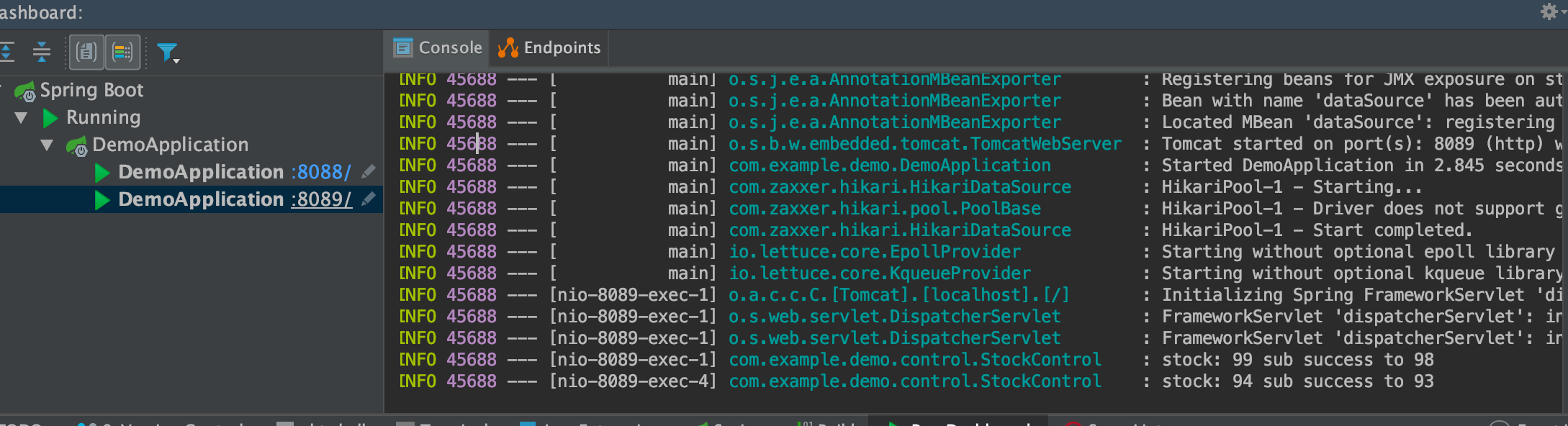
配置nginx.conf
http {include mime.types;default_type application/octet-stream;#log_format main '$remote_addr - $remote_user [$time_local] "$request" '# '$status $body_bytes_sent "$http_referer" '# '"$http_user_agent" "$http_x_forwarded_for"';#access_log logs/access.log main;sendfile on;#tcp_nopush on;#keepalive_timeout 0;keepalive_timeout 65;#gzip on;upstream redislock{server localhost:8088 weight=1;server localhost:8089 weight=1;}server {listen 8080;server_name localhost;#charset koi8-r;#access_log logs/host.access.log main;location / {root html;index index.html index.htm;proxy_pass http://redislock;}}
}
- nginx启动和关闭命令
mubi@mubideMacBook-Pro nginx $ sudo nginx
mubi@mubideMacBook-Pro nginx $ ps -ef | grep nginx0 47802 1 0 1:18下午 ?? 0:00.00 nginx: master process nginx-2 47803 47802 0 1:18下午 ?? 0:00.00 nginx: worker process501 47835 20264 0 1:18下午 ttys001 0:00.00 grep --color=always nginx
mubi@mubideMacBook-Pro nginx $
sudo nginx -s stop
- 访问测试
curl -X POST \http://localhost:8080/deduct_stock_sync \-H 'Content-Type: application/json'
jmeter压测复现问题
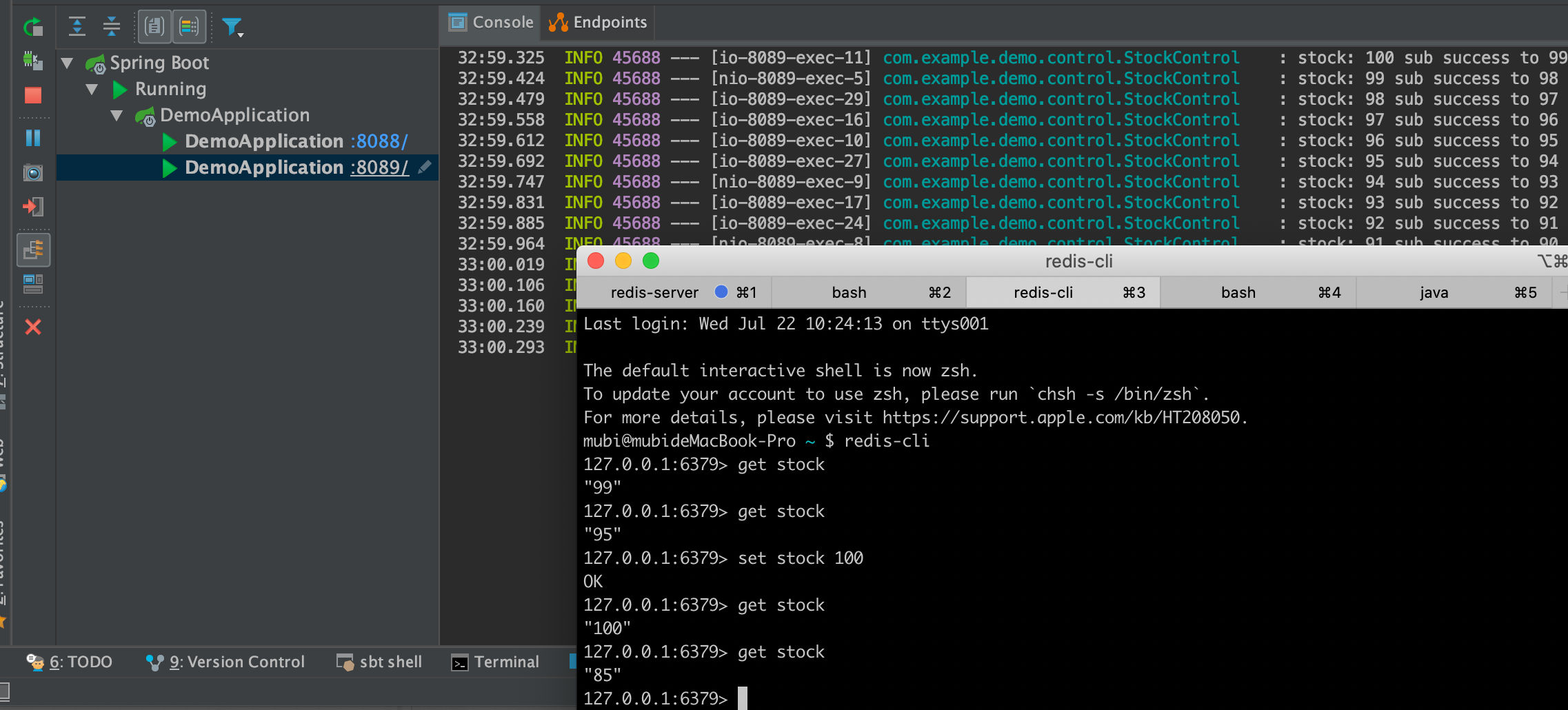
- redis 设置 stock 为 100
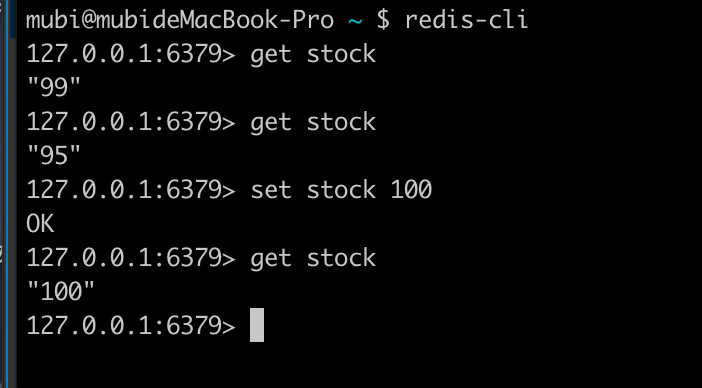
并发是1,即不产生并发问题

库存减少30, redis get结果会是最终的70,符合
并发30测试,产生并发问题(虽然单实例是synchronized,但是这是分布式多实例)
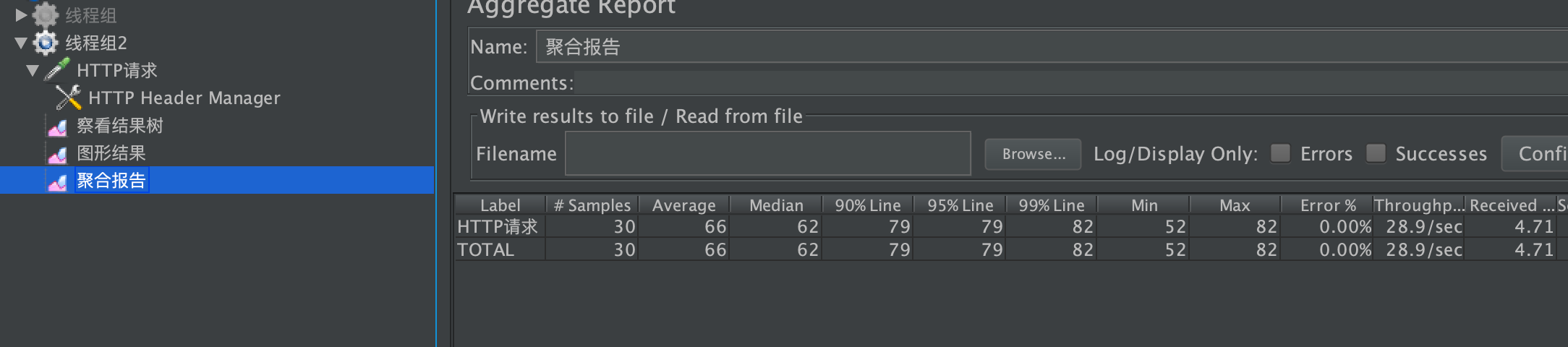
- 并发30访问测试结果:并不是最后的
70
redis 分布式锁:setnx实现
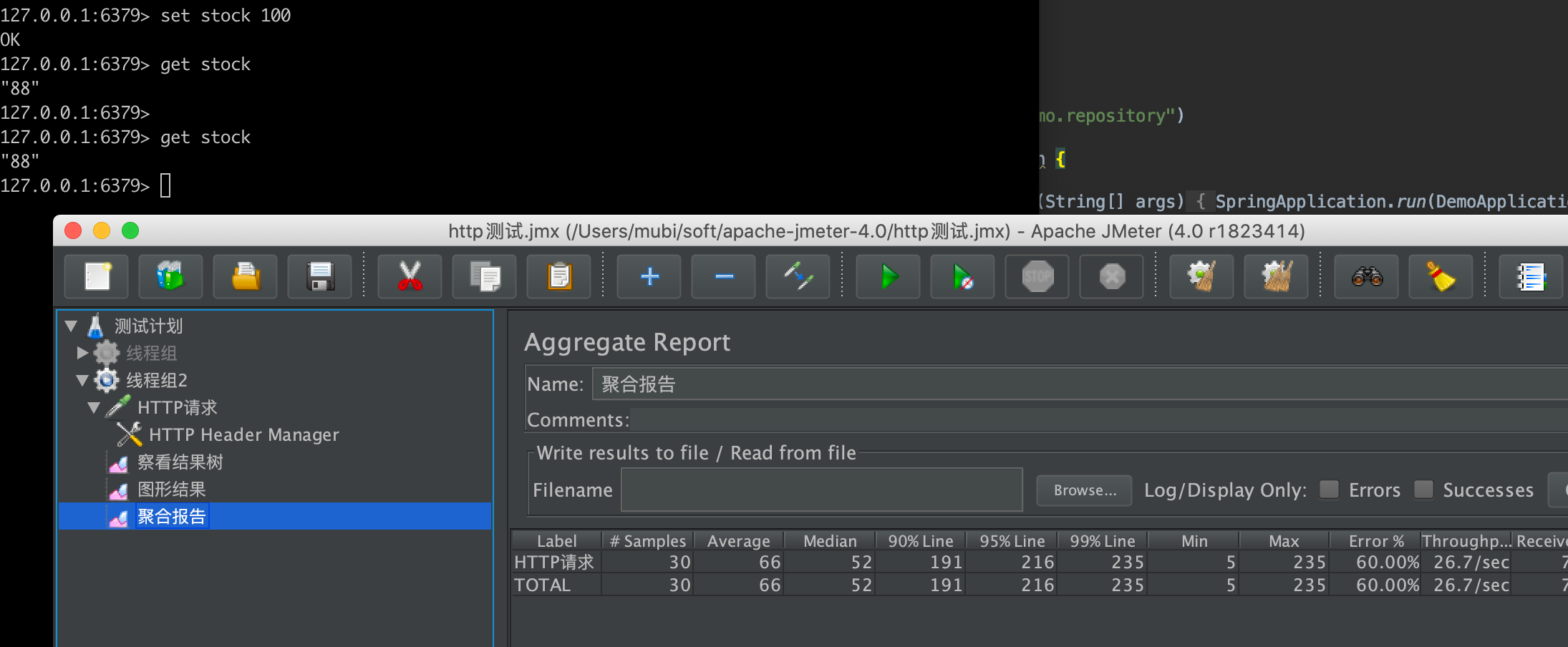
- 30的并发失败率是60%,即只有12个成功的,最后redis的stock值是88符合预期
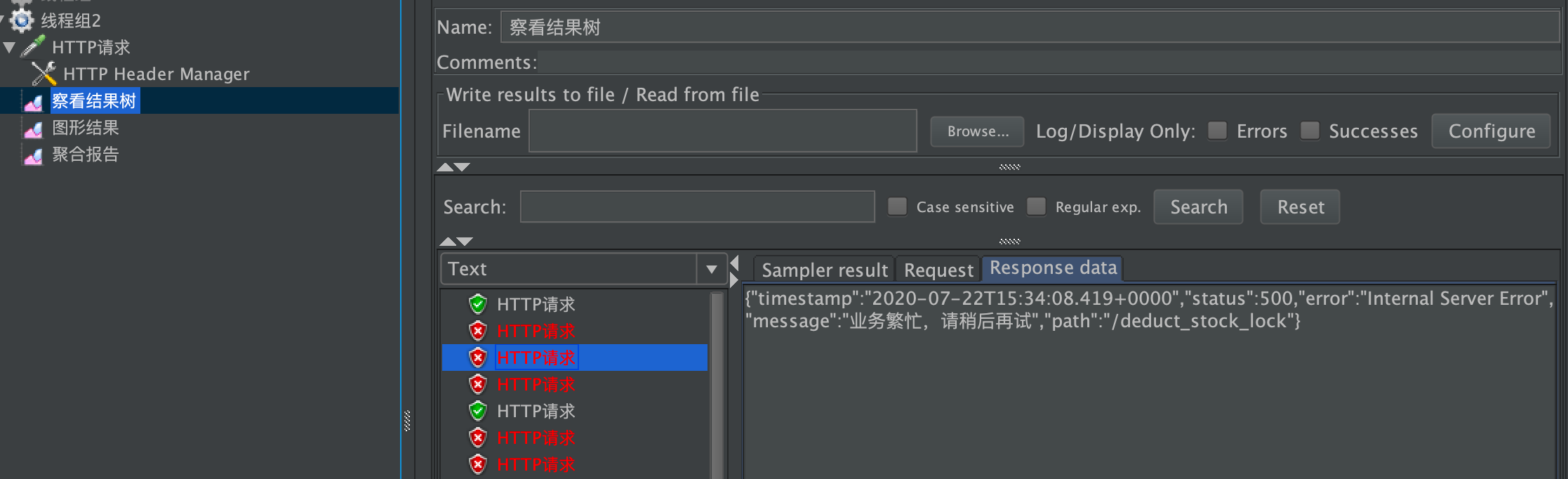
可以看到大部分没有抢到redis锁,而返回了系统繁忙错误
分布式锁的过期时间和看门狗
机器宕机可能导致finally释放锁失败,所以必须为redis key设置一个过期时间,但是设置的过期时间是多少是个问题?
-
超时时间是个问题:因为业务时长不确定的;如果设置短了而业务执行很长,那么会由于过期时间删除了可以,那么锁会被其它业务线程给抢了
-
其它线程可能删除别的线程的锁,因为锁没有什么标记
-
改进1
@PostMapping(value = "/deduct_stock_lock")
public String deductStockLock() throws Exception {// setnx,redis单线程String lockKey = "lockKey";String clientId = UUID.randomUUID().toString();// 如下两句要原子操作
// Boolean setOk = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, lockVal);
// stringRedisTemplate.expire(lockKey, 10 , TimeUnit.SECONDS); // 设置过期时间Boolean setOk = stringRedisTemplate.opsForValue().setIfAbsent(lockKey, clientId, 10, TimeUnit.SECONDS);if (!setOk) {throw new Exception("业务繁忙,请稍后再试");}String retVal;try {// 只有一个线程能执行成功,可能有业务异常抛出来,可能宕机等等;但无论如何要释放锁retVal = stockReduce();} finally {// 可能失败if (clientId.equals(stringRedisTemplate.opsForValue().get(lockKey))) {stringRedisTemplate.delete(lockKey);}}return retVal;
}
- 过期时间短不够的问题:可以不断的定时设置,给锁续命: 看门狗;开启新线程,每隔一段时间,判断锁还在不在,然后重新设置过期时间
- set key,value的时候,value设置为当前线程id,然后删除的时候判断下,确保删除正确
附:redis setnx相关命令和分布式锁
-
setnx(SET if Not eXists)
-
EXPIRE key seconds:设置key 的生存时间,当key过期(生存时间为0),会自动删除
如下,一个原子操作设置key:value,并设置10秒的超时
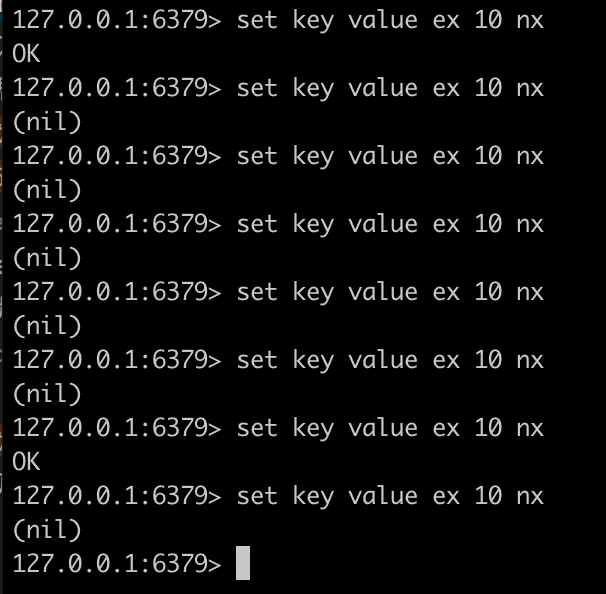
boolean lock(){ret = set key value(thread Id) 10 nx;if (!ret) {return false;}return true;
}void unlock(){val = get keyif ( val != null && val.equals( thread Id) ) {del key;}
}
Redisson
Redisson是一个基于Redis的Java客户端,提供了分布式锁的实现。其核心通过Redis的Lua脚本和原子操作保证锁的互斥性,支持可重入、公平锁、锁续期等功能。
代码&测试
@Bean
public Redisson redisson(){Config config = new Config();config.useSingleServer().setAddress("redis://localhost:6379").setDatabase(0);return (Redisson)Redisson.create(config);
}
@Autowired
private Redisson redisson;@PostMapping(value = "/deduct_stock_redisson")
public String deductStockRedisson() throws Exception {String lockKey = "lockKey";RLock rLock = redisson.getLock(lockKey);String retVal;try {rLock.lock();// 只有一个线程能执行成功,可能有业务异常抛出来,可能宕机等等;但无论如何要释放锁retVal = stockReduce();} finally {rLock.unlock();}return retVal;
}
如下并发请求毫无问题:
Redisson 底层原理
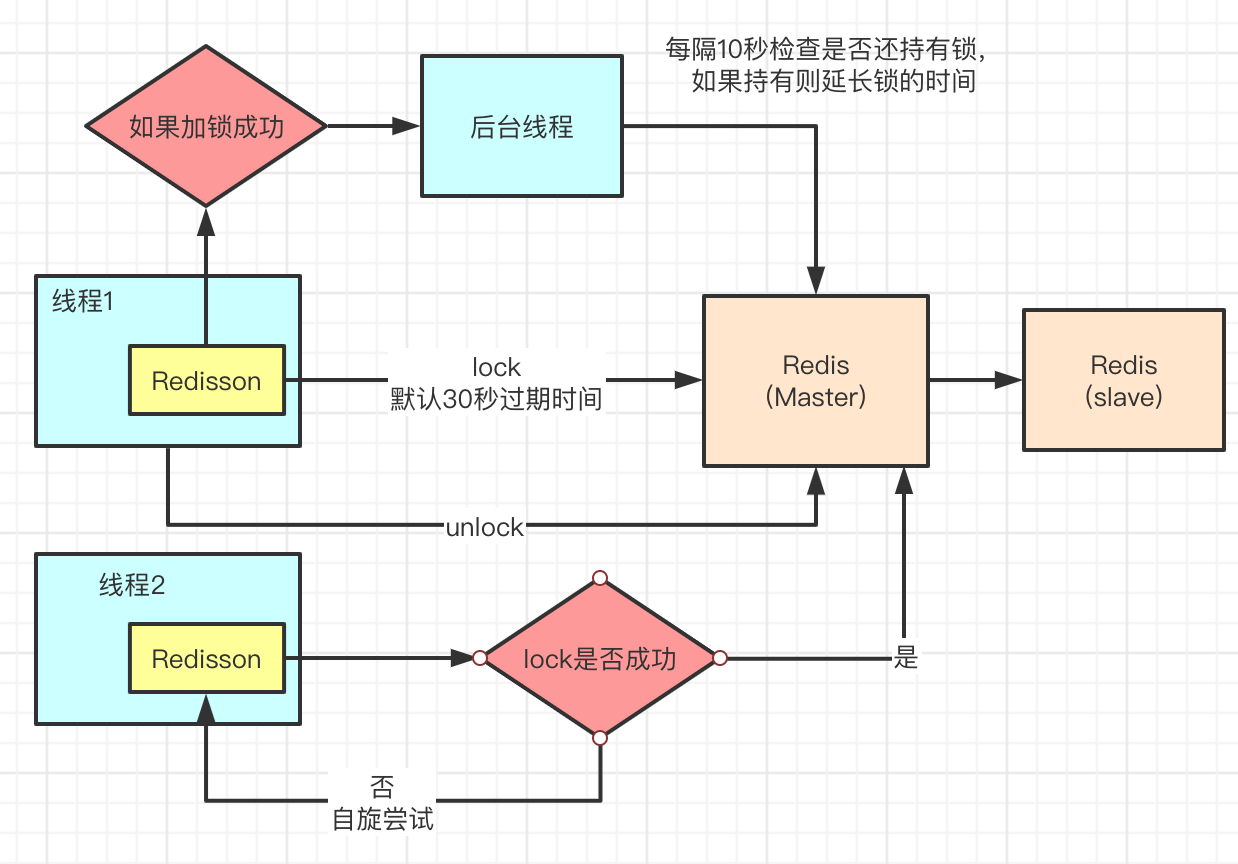
- setnx的设置key与过期时间用脚本实现原子操作
- key设置成功默认30s,则有后台线程每10秒(1/3的原始过期时间定时检查)检查判断,延长过期时间
- 未获取到锁的线程会自旋,直到那个获取到锁的线程将锁释放
实现可重入锁
value中多存储全局信息,可重入次数相关信息
{"count":1,"expireAt":147506817232,"jvmPid":22224, // jvm进程ID"mac":"28-D2-44-0E-0D-9A", // MAC地址"threadId":14 // 线程Id
}
redis分布式锁的问题?
Redis分布式锁会有个缺陷,就是在Redis哨兵模式下:
客户端1对某个master节点写入了redisson锁,此时会异步复制给对应的slave节点。但是这个过程中一旦发生master节点宕机,主备切换,slave节点从变为了master节点(但是锁信息是没有的)。这时客户端2来尝试加锁的时候,在新的master节点上也能加锁,此时就会导致多个客户端对同一个分布式锁完成了加锁。
这时系统在业务语义上一定会出现问题,导致各种脏数据的产生。缺陷在哨兵模式或者主从模式下,如果master实例宕机的时候,可能导致多个客户端同时完成加锁。
redis主从架构问题?
补充知识:redis单机qps支持:10w级别
redis主从架构是主同步到从,如果主设置key成功,但是同步到从还没结束就挂了;这样从成为主,但是是没有key存在的,那么另一个线程又能够加锁成功。(redis主从架构锁失效问题?)
redis无法保证强一致性?zookeeper解决,但是zk性能不如redis
Redlock(超半数加锁成功才成功)
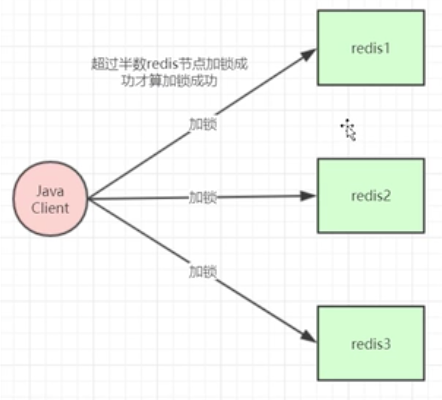
- 加锁失败的回滚
- redis加锁多,性能受影响
高并发分布式锁如何实现
- 分段锁思想
基于ZooKeeper实现
回顾zookeeper的一些相关知识: 文件系统+监听通知机制
zookeeper节点类型
- PERSISTENT-持久节点
除非手动删除,否则节点一直存在于 Zookeeper 上; 重启Zookeeper后也会恢复
- EPHEMERAL-临时节点
临时节点的生命周期与客户端会话绑定,一旦客户端会话失效(客户端与zookeeper连接断开不一定会话失效),那么这个客户端创建的所有临时节点都会被移除。
- PERSISTENT_SEQUENTIAL-持久顺序节点
基本特性同持久节点,只是增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
- EPHEMERAL_SEQUENTIAL-临时顺序节点
基本特性同临时节点,增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
zookeeper的watch机制
- 主动推送:watch被触发时,由zookeeper主动推送给客户端,而不需要客户端轮询
- 一次性:数据变化时,watch只会被触发一次;如果客户端想得到后续更新的通知,必须要在watch被触发后重新注册一个watch
- 可见性:如果一个客户端在读请求中附带 Watch,Watch 被触发的同时再次读取数据,客户端在得到 Watch消息之前肯定不可能看到更新后的数据。换句话说,更新通知先于更新结果
- 顺序性:如果多个更新触发了多个 Watch ,那 Watch 被触发的顺序与更新顺序一致
zookeeper lock
普通临时节点(羊群效应)

比如1000个并发,只有1个客户端获取锁成功,其它999个客户端都处在监听并等待中;如果成功释放锁了,那么999个客户端都监听到,再次继续进行创建锁的流程。
所以每次锁有变化,几乎所有客户端节点都要监听并作出反应,这会给集群带来巨大压力,即为:羊群效应
顺序节点(公平,避免羊群效应)
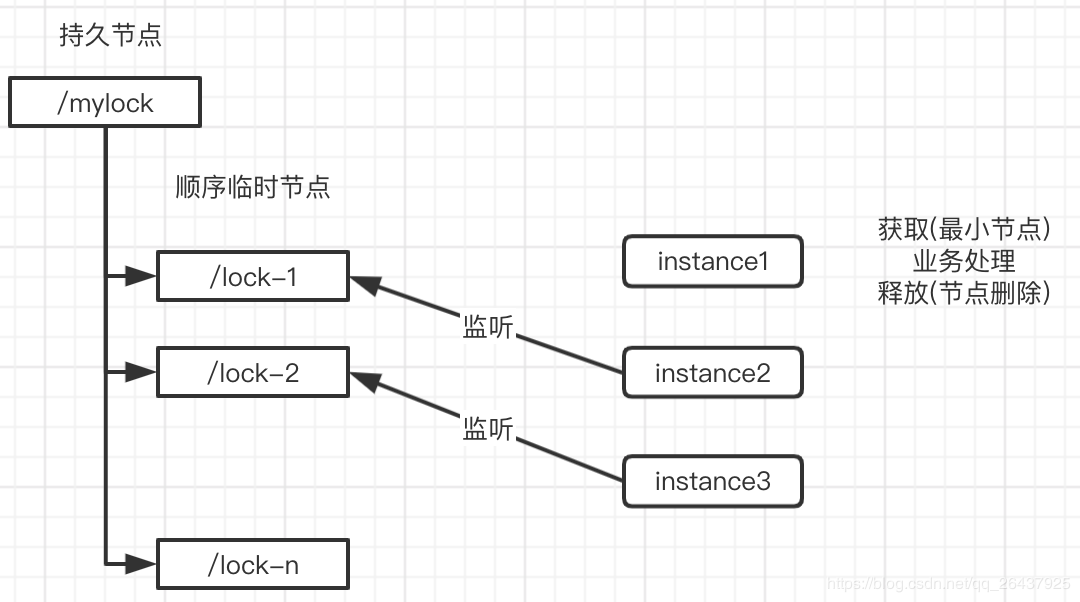
-
首先需要创建一个父节点,尽量是持久节点(PERSISTENT类型)
-
每个要获得锁的线程都会在这个节点下创建个临时顺序节点,
-
由于序号的递增性,可以规定排号最小的那个获得锁。
-
所以,每个线程在尝试占用锁之前,首先判断自己是排号是不是当前最小,如果是,则获取锁。
利用顺序性:每个线程都只监听前一个线程,事件通知也只通知后面都一个线程,而不是通知全部,从而避免羊群效应
Curator InterProcessMutex(可重入公平锁)
curator官方文档
code&测试
实践代码链接
@Component
public class CuratorConfiguration {@Bean(initMethod = "start")public CuratorFramework curatorFramework() {RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181", retryPolicy);return client;}
}
@Autowired
private CuratorFramework curatorFramework;@PostMapping(value = "/deduct_stock_zk")
public String deductStockZk() throws Exception {String path = "/stock";InterProcessMutex interProcessMutex = new InterProcessMutex(curatorFramework, path);String retVal;try {interProcessMutex.acquire();retVal = stockReduce();} catch (Exception e) {throw new Exception("lock error");} finally {interProcessMutex.release();}return retVal;
}
- 压测结果正常

InterProcessMutex 内部原理
初始化
/**
* @param client client
* @param path the path to lock
* @param driver lock driver
*/
public InterProcessMutex(CuratorFramework client, String path, LockInternalsDriver driver)
{this(client, path, LOCK_NAME, 1, driver);
}
/*** Returns a facade of the current instance that tracks* watchers created and allows a one-shot removal of all watchers* via {@link WatcherRemoveCuratorFramework#removeWatchers()}** @return facade*/
public WatcherRemoveCuratorFramework newWatcherRemoveCuratorFramework();
加锁
private boolean internalLock(long time, TimeUnit unit) throws Exception
{/*Note on concurrency: a given lockData instancecan be only acted on by a single thread so locking isn't necessary*/Thread currentThread = Thread.currentThread();// 获取当前线程锁数据,获取到的化,设置可重入LockData lockData = threadData.get(currentThread);if ( lockData != null ){// re-enteringlockData.lockCount.incrementAndGet();return true;}// 尝试获取锁String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());if ( lockPath != null ){// 获取到锁,锁数据加入`threadData`的map结构中LockData newLockData = new LockData(currentThread, lockPath);threadData.put(currentThread, newLockData);return true;}// 没有获取到锁return false;
}
String attemptLock(long time, TimeUnit unit, byte[] lockNodeBytes) throws Exception
{final long startMillis = System.currentTimeMillis();final Long millisToWait = (unit != null) ? unit.toMillis(time) : null;final byte[] localLockNodeBytes = (revocable.get() != null) ? new byte[0] : lockNodeBytes;int retryCount = 0;String ourPath = null;boolean hasTheLock = false;boolean isDone = false;while ( !isDone ){isDone = true;try{ourPath = driver.createsTheLock(client, path, localLockNodeBytes);hasTheLock = internalLockLoop(startMillis, millisToWait, ourPath);}catch ( KeeperException.NoNodeException e ){// gets thrown by StandardLockInternalsDriver when it can't find the lock node// this can happen when the session expires, etc. So, if the retry allows, just try it all againif ( client.getZookeeperClient().getRetryPolicy().allowRetry(retryCount++, System.currentTimeMillis() - startMillis, RetryLoop.getDefaultRetrySleeper()) ){isDone = false;}else{throw e;}}}if ( hasTheLock ){return ourPath;}return null;
}
创建锁是创建的临时顺序节点
@Override
public String createsTheLock(CuratorFramework client, String path, byte[] lockNodeBytes) throws Exception
{String ourPath;if ( lockNodeBytes != null ){ourPath = client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path, lockNodeBytes);}else{ourPath = client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path);}return ourPath;
}
watch
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception
{boolean haveTheLock = false;boolean doDelete = false;try{if ( revocable.get() != null ){client.getData().usingWatcher(revocableWatcher).forPath(ourPath);}while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock ){// 获取lock下所有节点数据,并排序List<String> children = getSortedChildren();String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash// 判断获取到锁PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);if ( predicateResults.getsTheLock() ){haveTheLock = true;}else{String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();synchronized(this){try{// use getData() instead of exists() to avoid leaving unneeded watchers which is a type of resource leak// 监听前一个节点,并等待client.getData().usingWatcher(watcher).forPath(previousSequencePath);if ( millisToWait != null ){millisToWait -= (System.currentTimeMillis() - startMillis);startMillis = System.currentTimeMillis();if ( millisToWait <= 0 ){doDelete = true; // timed out - delete our nodebreak;}wait(millisToWait);}else{wait();}}catch ( KeeperException.NoNodeException e ){// it has been deleted (i.e. lock released). Try to acquire again}}}}}catch ( Exception e ){ThreadUtils.checkInterrupted(e);doDelete = true;throw e;}finally{if ( doDelete ){deleteOurPath(ourPath);}}return haveTheLock;
}
是不是加锁成功:是不是最小的那个节点
@Override
public PredicateResults getsTheLock(CuratorFramework client, List<String> children, String sequenceNodeName, int maxLeases) throws Exception
{int ourIndex = children.indexOf(sequenceNodeName);validateOurIndex(sequenceNodeName, ourIndex);boolean getsTheLock = ourIndex < maxLeases;String pathToWatch = getsTheLock ? null : children.get(ourIndex - maxLeases);return new PredicateResults(pathToWatch, getsTheLock);
}
释放锁
可重入判断;删除watchers,删除节点
/*** Perform one release of the mutex if the calling thread is the same thread that acquired it. If the* thread had made multiple calls to acquire, the mutex will still be held when this method returns.** @throws Exception ZK errors, interruptions, current thread does not own the lock*/
@Override
public void release() throws Exception
{/*Note on concurrency: a given lockData instancecan be only acted on by a single thread so locking isn't necessary*/Thread currentThread = Thread.currentThread();LockData lockData = threadData.get(currentThread);if ( lockData == null ){throw new IllegalMonitorStateException("You do not own the lock: " + basePath);}int newLockCount = lockData.lockCount.decrementAndGet();if ( newLockCount > 0 ){return;}if ( newLockCount < 0 ){throw new IllegalMonitorStateException("Lock count has gone negative for lock: " + basePath);}try{internals.releaseLock(lockData.lockPath);}finally{threadData.remove(currentThread);}
}
final void releaseLock(String lockPath) throws Exception
{client.removeWatchers();revocable.set(null);deleteOurPath(lockPath);
}
redis vs zookeeper AI回答
- 一致性模型
Zookeeper 提供强一致性,这意味着当客户端在一个服务器上看到某个状态更新后,其他服务器也会立即反映这一变化。这种特性使得 Zookeeper 非常适合用于需要严格一致性的场景。
相比之下,Redis 默认提供最终一致性。虽然可以通过 Redlock 算法来增强其一致性保障4,但在某些极端情况下(如网络分区或主从延迟较高时),仍然可能存在短暂的数据不一致问题。
- 可靠性与容错能力
Zookeeper 使用 Paxos 或 ZAB 协议构建高可用集群,在部分节点失效的情况下仍能保持服务正常运行。因此,即使少数节点发生故障,整个系统依然能够继续运作。
然而,标准的 Redis 实现存在单点故障风险。尽管引入 Sentinel 或 Cluster 模式可以在一定程度上缓解此问题,但如果主节点崩溃且未及时完成 failover,则可能导致锁丢失的情况出现。此外,由于 Redis 主从之间采用异步复制机制,可能会进一步加剧该类问题的发生概率。
- 性能表现
在高频次、低延时需求下,Redis 显示出了显著的优势。它是一种内存级数据库,所有操作几乎都在 O(1) 时间复杂度内完成,这使其成为高性能应用场景下的理想选择。
而 Zookeeper 更注重于稳定性和一致性而非极致速度。对于那些对实时响应要求不高但强调可靠性的业务来说,Zookeeper 是更合适的选择。
- 功能扩展性
借助 Redisson 库的支持,开发者能够在 Redis 基础之上轻松获得诸如可重入锁、自动续期以及公平锁等功能。这些额外的功能极大地增强了 Redis 锁机制的实际应用价值。
至于 Zookeeper,虽然原生 API 较为简单直接,但它允许用户自定义复杂的逻辑流程以满足特定需求。不过相较于 Redisson 所提供的开箱即用型解决方案而言,开发成本相对更高一些。