AI 理论- 模型优化 - 注意力机制
注意力机制
- 简介
- 优势与挑战
- 优势
- 挑战
- 研究方向
- 理解
- Encoder-Decoder 框架
- 基本结构
- 应用场景
- 分类
- 计算方式分类
- 输入来源分类
- 结构设计分类
- 任务特性分类
- 常见的注意力机制模块
- 通道注意力(Channel Attention)
- 空间注意力(Spatial Attention)
- 自注意力(Self-Attention)
- 多头注意力(Multi-Head Attention)
- 参考
简介
注意力机制是深度学习中一种模仿人类选择性关注重要信息的行为,通过动态分配权重来聚焦输入数据的关键部分,在自然语言处理(NLP)、计算机视觉(CV)和多模态任务中广泛应用,尤其因Transformer模型的成功而成为现代AI的核心组件。
传统的序列模型(如RNN、LSTM)在处理长序列时,所有输入信息会被压缩成一个固定长度的向量,导致信息丢失或难以捕捉远距离依赖关系。注意力机制通过以下方式解决这一问题:
- 选择性聚焦:模型可以自动学习输入中哪些部分对当前任务更重要。
- 动态权重分配:根据输入和当前状态,为不同部分分配不同的重要性权重。
注意力机制一般组合使用,实际应用中的组合
- Transformer = 自注意力 + 交叉注意力 + 多头注意力
- Squeeze-and-Excitation Network = 通道注意力 + 空间注意力
- Longformer = 稀疏注意力(局部+全局) + 自注意力
优势与挑战
优势
- 提高模型对关键信息的敏感度;
- 增强模型的可解释性;
- 适用于长序列依赖任务。
挑战
- 计算复杂度高(尤其是自注意力),需通过稀疏化或高效算法优化。
研究方向
注意力机制的效率优化
- 大规模深度学习模型中,注意力机制的计算成本可能非常高。因此,优化注意力机制的计算效率成为一个重要研究方向
- 包括减少注意力计算的复杂度,如稀疏化注意力或低秩近似,有助于减少模型的训练和推理时间,对于能源消耗和环境影响也很重要
融合局部和全局注意力
- 这种方法中,模型被设计为同时关注局部细节和全局上下文,从而提高其在复杂任务上的表现
- 在图像处理任务中,全局注意力可以帮助模型捕捉图像的整体布局,局部注意力则关注于细节特征
- 这种融合方法特别适用于需要精细理解和全局视野的任务,如医学图像分析或场景理解
可解释性和透明度的提升
- 注意力机制的决策过程缺乏透明度,需新的方法和工具来解释和可视化注意力权重
- 在对准确性和可靠性要求较高的应用(如医疗诊断)中, 帮助研究人员和从业者更好地理解模型的决策过程
注意力机制与其他深度学习技术的融合
- 可以增强模型处理特定数据类型的能力,还可以带来新的模型架构和应用
- 在图像处理任务中,结合卷积层和注意力层可以提高模型在特征提取和空间关系理解方面的能力
理解
Encoder-Decoder 框架
常见的深度学习模型有 CNN、RNN、LSTM、AE 等,其实都可以归为一种通用框架 - Encoder-Decoder.
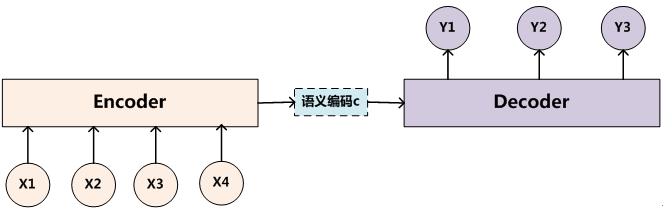
在文本处理领域,有一类常见的任务就是从一个句子(Source)生成另一个句子(Target),比如翻译,其中 xi 是输入单词的向量表示,yi 表示输出单词.
Source ------ Encoder------> 语义编码 C ------ Decoder ------> Targer
在循环神经网络中,先根据 C 生成 y1,再基于(C,y1)生成 y2,依此类推,如下图所示:
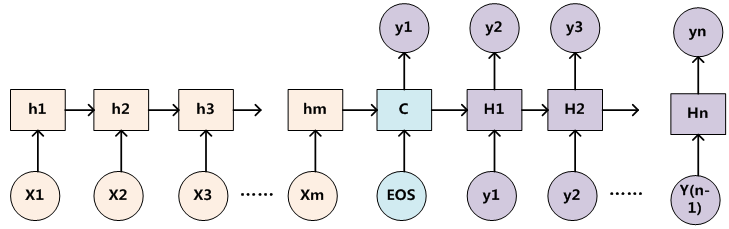
传统的循环神经网络中,y1、y2 和 y3 的计算都是基于同一个 C,此方案不是很优,因为Source 中不同单词对 y1、y2 和 y3 的影响是不同的,所以,针对此问题产生如下方案:
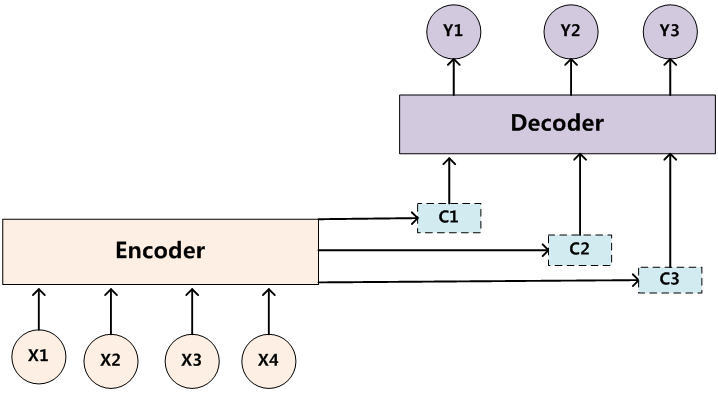
在计算 C1、C2 和 C3 时,分别使用不同的权重向量:
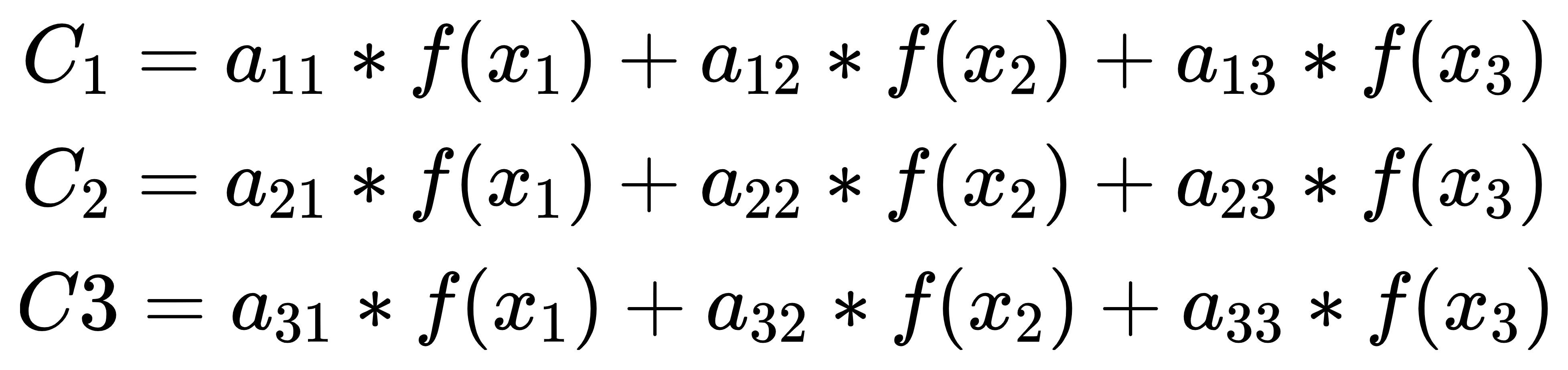
权重向量 (a11, a12, a13)、(a21, a22, a23)、(a31, a32, a33) 计算方式
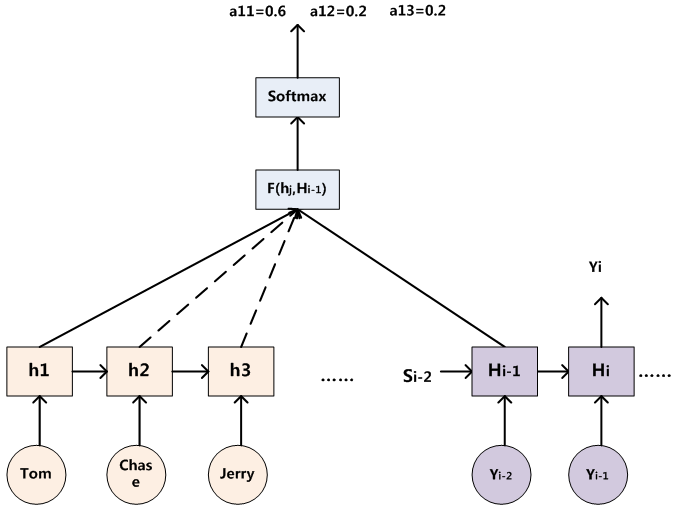
基本结构
- 注意力机制包含三个核心组件,通过计算三个组件间的相关性来动态分配权重,使模型聚焦于输入数据中的关键部分。
(1)查询(Query, Q):当前需要生成输出的目标(如解码器的当前状态)
(2)键(Key, K):输入元素的标识,用于与查询计算相关性
(3)值(Value, V):输入元素的实际内容,根据权重聚合后生成输出 - 数学本质:通过计算输入元素之间的相关性权重,对信息进行加权融合。
- Q、K、V 是参数矩阵,需要通过学习得到的
- 计算步骤 (缩放点积注意力为例)
(1)相似度计算:查询与键的点积,度量相关性
Score = Q ⋅ K T
(2)权重归一化:通过Softmax将得分转换为概率分布
Attention_Weights = Softmax ( Score )
(3)加权求和:用权重对值进行聚合,生成上下文向量
Output = Attention_Weights ⋅ V
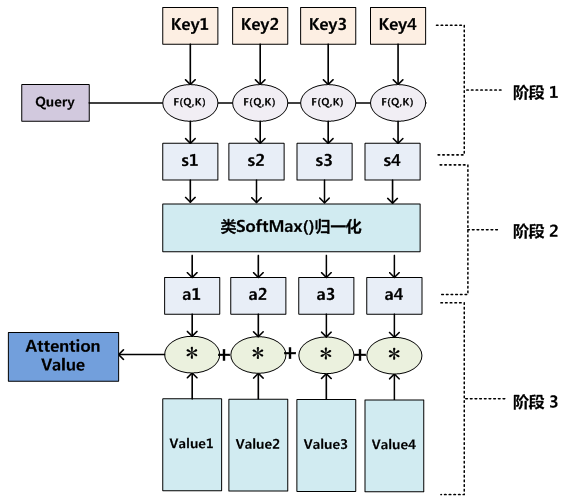
应用场景
- 自然语言处理:机器翻译、文本分类、问答系统等场景中提升语义对应关系捕捉能力。
- 计算机视觉:图像分类、目标检测等任务中关注关键区域或特征。
- 其他领域:时间序列预测、推荐系统等。
分类
| 分类维度 | 核心区别 | 典型联系 |
|---|---|---|
| 计算方式 | 权重是否连续、是否可微 | 软注意力是大多数模型的基础 |
| 输入来源 | Query/Key/Value的来源是否相同 | 自注意力和交叉注意力常配合使用 |
| 结构设计 | 是否并行或多层级 | 多头注意力可结合自注意力或交叉注意力 |
| 任务特性 | 关注时序、空间或通道维度 | 空间注意力常用于CV,时序用于NLP |
计算方式分类
软注意力(Soft Attention)
- 特点:对所有输入分配连续的权重(通过Softmax归一化),通过加权求和,可微且易于训练
- 应用场景:大多数主流任务(如Transformer、机器翻译)
硬注意力(Hard Attention)
- 特点:选择单一输入(离散决策,如直接取最大值),通过随机采样选择信息,不可微,需强化学习训练
- 应用场景:图像局部区域聚焦、部分生成任务
局部注意力(Local Attention)
- 特点:软注意力和硬注意力的折中,仅对输入的一个子集计算权重(如滑动窗口)
- 应用场景:长序列处理(降低计算复杂度)
输入来源分类
自注意力(Self-Attention)
- 特点:Query、Key、Value来自同一输入序列,捕捉序列内部的长距离依赖(如句子中词与词的关系)
- 应用场景:Transformer编码器处理文本或图像时,分析词与词、像素与像素的关系
- 示例:句子中的代词(如“它”)通过自注意力找到指代的名词(如“苹果”)
- 典型模型:Transformer编码层(Transformer的核心)
交叉注意力(Cross-Attention)
- 特点:Query来自一个序列,Key和Value来自另一个序列
- 作用:跨序列交互(如解码器关注编码器的输出)。
- 典型模型:Transformer解码层。
外部注意力(External Attention)
- 特点:Key和Value来自外部可学习的全局记忆单元(而非输入本身)。
- 作用:减少计算量并增强泛化能力。
结构设计分类
多头注意力(Multi-Head Attention)
- 特点:通过多个查询并行处理输入数据,捕捉不同子空间的特征。将Q、K、V投影到多个子空间,并行计算多组注意力,增强模型表达能力,捕捉不同特征。
- 优势:允许模型同时关注不同位置和不同语义层面的信息,增强对不同特征的关注能力
- 计算步骤:
(1)将Q、K、V拆分为h hh个头(如8头)。
(2)每个头独立计算注意力。
(3)拼接所有头的输出,并通过线性层融合。
层次化注意力(Hierarchical Attention)
- 特点:在多层级(如词级、句级)分别应用注意力。
- 应用场景:文档分类、长文本理解。
稀疏注意力(Sparse Attention)
- 特点:限制注意力计算的范围(如局部窗口、随机采样)。
- 目的:降低长序列的计算复杂度。
- 典型模型:Longformer(滑动窗口)、BigBird(随机+全局token)。
任务特性分类
时序注意力(Temporal Attention)
- 特点:关注时间维度上的重要时刻。
- 应用场景:时间序列预测、视频处理。
空间注意力(Spatial Attention)
- 特点:关注图像或特征图的特定区域。
- 应用场景:图像分割、目标检测。
通道注意力(Channel Attention)
- 特点:关注特征图的通道维度(如Squeeze-and-Excitation Network)。
- 作用:动态调整通道重要性。
常见的注意力机制模块
通道注意力(Channel Attention)
学习特征图中不同通道的权重,增强与人脸相关的特征通道。
- 典型方法:SENet(Squeeze-and-Excitation Network):通道注意力模块通过学习每个通道的权重,增强与人脸相关的特征通道。
import torch
import torch.nn as nnclass ChannelAttention(nn.Module):def __init__(self, in_channels, reduction_ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.fc = nn.Sequential(nn.Linear(in_channels, in_channels // reduction_ratio),nn.ReLU(),nn.Linear(in_channels // reduction_ratio, in_channels))self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.fc(self.avg_pool(x).squeeze(-1).squeeze(-1))max_out = self.fc(self.max_pool(x).squeeze(-1).squeeze(-1))out = avg_out + max_outreturn self.sigmoid(out).unsqueeze(-1).unsqueeze(-1)# 添加到Backbone中
class BackboneWithAttention(nn.Module):def __init__(self):super(BackboneWithAttention, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)self.ca = ChannelAttention(64)self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)def forward(self, x):x = self.conv1(x)x = self.ca(x) * x # 应用通道注意力x = self.conv2(x)return x
空间注意力(Spatial Attention)
学习特征图中不同空间位置的权重,增强人脸区域的特征。
- 典型方法:CBAM(Convolutional Block Attention Module)
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)out = torch.cat([avg_out, max_out], dim=1)out = self.conv(out)return self.sigmoid(out)# 添加到Backbone中
class BackboneWithSpatialAttention(nn.Module):def __init__(self):super(BackboneWithSpatialAttention, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)self.sa = SpatialAttention()self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)def forward(self, x):x = self.conv1(x)x = self.sa(x) * x # 应用空间注意力x = self.conv2(x)return x
自注意力(Self-Attention)
计算特征图中不同位置之间的关系,捕捉长距离依赖。
- 典型方法:Non-local Networks
class SelfAttention(nn.Module):def __init__(self, in_channels):super(SelfAttention, self).__init__()self.query = nn.Conv2d(in_channels, in_channels // 8, kernel_size=1)self.key = nn.Conv2d(in_channels, in_channels // 8, kernel_size=1)self.value = nn.Conv2d(in_channels, in_channels, kernel_size=1)self.gamma = nn.Parameter(torch.zeros(1))def forward(self, x):batch_size, C, H, W = x.size()query = self.query(x).view(batch_size, -1, H * W).permute(0, 2, 1)key = self.key(x).view(batch_size, -1, H * W)energy = torch.bmm(query, key)attention = F.softmax(energy, dim=-1)value = self.value(x).view(batch_size, -1, H * W)out = torch.bmm(value, attention.permute(0, 2, 1))out = out.view(batch_size, C, H, W)return self.gamma * out + x# 添加到Backbone中
class BackboneWithSelfAttention(nn.Module):def __init__(self):super(BackboneWithSelfAttention, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)self.sa = SelfAttention(64)self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)def forward(self, x):x = self.conv1(x)x = self.sa(x) # 应用自注意力x = self.conv2(x)return x
多头注意力(Multi-Head Attention)
并行计算多个注意力头,捕捉不同子空间的特征。
- 计算机视觉任务中,多头注意力机制可以添加到CNN中,用于捕捉空间或通道间的依赖关系
class MultiHeadAttention2D(nn.Module):def __init__(self, in_channels, num_heads):super(MultiHeadAttention2D, self).__init__()self.in_channels = in_channelsself.num_heads = num_headsself.head_dim = in_channels // num_headsassert self.head_dim * num_heads == in_channels, "in_channels must be divisible by num_heads"self.query = nn.Conv2d(in_channels, in_channels, kernel_size=1)self.key = nn.Conv2d(in_channels, in_channels, kernel_size=1)self.value = nn.Conv2d(in_channels, in_channels, kernel_size=1)self.fc_out = nn.Conv2d(in_channels, in_channels, kernel_size=1)def forward(self, x):batch_size, C, H, W = x.size()# 线性变换并分割多头Q = self.query(x).view(batch_size, self.num_heads, self.head_dim, H * W).permute(0, 1, 3, 2)K = self.key(x).view(batch_size, self.num_heads, self.head_dim, H * W).permute(0, 1, 3, 2)V = self.value(x).view(batch_size, self.num_heads, self.head_dim, H * W).permute(0, 1, 3, 2)# 计算缩放点积注意力energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / (self.head_dim ** 0.5)attention = F.softmax(energy, dim=-1)# 加权求和并合并多头x = torch.matmul(attention, V)x = x.permute(0, 1, 3, 2).contiguous()x = x.view(batch_size, C, H, W)x = self.fc_out(x)return x
- 在多任务学习或特征融合任务中,多头注意力机制可以用于融合不同来源的特征
class FeatureFusionWithMHA(nn.Module):def __init__(self, embed_dim, num_heads):super(FeatureFusionWithMHA, self).__init__()self.mha = MultiHeadAttention(embed_dim, num_heads)def forward(self, feature1, feature2):# 将两个特征拼接作为输入combined_features = torch.cat([feature1, feature2], dim=1)# 使用多头注意力机制融合特征fused_features = self.mha(combined_features, combined_features, combined_features)return fused_features
参考
注意力机制的四大创新点
注意力机制(Attention Mechanism)讲解
详解深度学习中的注意力机制(Attention)