YOLO-SLD:基于注意力机制改进的YOLO车牌检测算法
车辆车牌检测在智能交通系统中起着关键作用。对汽车、卡车和货车等车牌进行检测,在执法、监控和收费站运营等场景中具有重要应用价值。
如何快速准确地检测车牌,是车牌识别技术的关键所在。
然而,在实际复杂的拍摄场景中,待检测车牌面临光照条件不均匀、拍摄角度倾斜等问题,这些因素的剧烈变化使得检测难度显著增加。同时,车牌检测对距离、光照、角度等条件要求较高,严重影响了检测性能。
视频教程,戳蓝字即可学习
【YOLOV5】计算机视觉实战——基于YOLO&Deepsort的车速&车流量检测系统,YOLOV4论文解读+代码复现!人工智能/深度学习/神经网络
概述
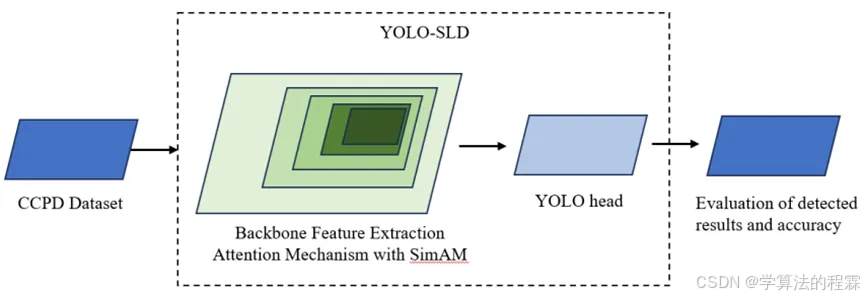
为此,本研究提出了一种改进的YOLOv7算法——YOLO-SLD,该算法集成了无参数注意力模块SimAM,专门用于车牌检测。在不修改YOLOv7核心组件ELAN架构的前提下,通过在ELAN模块末尾添加SimAM机制,能够更好地提取车牌特征并提高计算效率。更为重要的是,SimAM模块无需在原始YOLOv7网络中添加任何参数,有效降低了模型计算量并简化了计算流程。
研究首次在CCPD数据集上测试了不同注意力机制的检测模型性能,验证了所提方法的有效性。实验结果表明,YOLO-SLD模型具有更高的检测精度和更轻量级的特点:在mAP@0.5指标上,整体精度从原始YOLOv7模型的98.44%提升至98.91%,提高了0.47%;在CCPD测试子集的暗光和强光图像中,检测精度从93.5%提升至96.7%,提高了3.2%;模型参数规模相比原始YOLOv7减少了120万个,性能优于当前主流的车牌检测算法。
背景
近年来,基于深度卷积神经网络(ConvolutionalNeuralNetwork,CNN)的目标检测技术取得了突破性进展。一个典型的ALPR系统通常由三个核心模块组成,以确保高效准确的识别性能:车牌检测(LicensePlateDetection,LPD)、字符分割(CharacterSegmentation,CS)和光学字符识别(OpticalCharacterRecognition,OCR)。在车牌检测的早期阶段,主要面临的挑战包括:多样化的车牌布局和语言导致的遮挡问题、不同的尺寸和纵横比、以及在各种光照和天气条件下输入图像的噪声或不清晰问题,如下图所示。
这一阶段的理想目标是精确检测出所有车牌区域,其性能直接决定了整个系统的最终表现。对非车牌目标的错误分类可能会导致后续处理阶段的连锁错误。
随着卷积神经网络(CNN)的飞速发展与广泛应用,当前目标检测网络主要分为以下两类:单阶段检测器(single-stagedetectors)和双阶段检测器(two-stagedetectors)。典型的单阶段检测器包括单次多框检测(SingleShotDetector,SSD)和你只看一次(YouOnlyLookOnce,YOLO)系列;而基于区域的卷积神经网络(Region-basedConvolutionalNeuralNetwork,R-CNN、快速R-CNN(FastR-CNN)、更快R-CNN(FasterR-CNN)以及掩码R-CNN(MaskR-CNN)则属于双阶段检测器。然而,如何在复杂环境下提升车牌检测的准确性和实时性,仍是亟待解决的关键问题。
YOLO目标检测算法及其升级版因其高精度、快速处理和实时检测能力而备受关注。Zou等人分别采用YOLOv3和YOLOv4作为车牌检测框架,在中国城市停车数据集(ChineseCityParkingDataset,CCPD)上取得了96.0%(YOLOv3)和95.1%(YOLOv4)的检测准确率。最新的YOLO架构——由Wang等人提出的YOLOv7,作为单阶段检测器,兼具高精度和快速处理的优势。
本文提出了YOLO-SLD算法,这是YOLOv7的升级版,通过集成注意力机制进一步提升了车牌检测的效率和精度。
本文的主要贡献有三点:
1.首次将YOLOv7应用于CCPD数据集的车牌检测,并对比了多种注意力机制的效果,包括卷积块注意力模块(ConvolutionalBlockAttentionModule,CBAM)、坐标注意力(CoordinateAttention,CA)、混洗注意力(ShuffleAttention,SA)和挤压激励(Squeeze-and-Excitation,SE)。
2创新集成无参数注意力模块SimAM:通过替换和添加卷积层,将简单无参数注意力模块(ASimple,Parameter-FreeAttentionModule,SimAM)融入YOLOv7的骨干网络(Backbone)和检测头(Head),增强特征提取能力。为评估算法性能提升,在CCPD数据集上进行了全面实验。
3.性能超越现有网络:在CCPD数据集上,YOLO-SLD的mAP@0.5达到98.91%,较YOLOv7提升0.47%,证明了其优越性。该模型不仅检测效率更高,而且在模型参数方面更加轻量级。
新算法框架解析
基于完善的神经科学理论,梁等人于2021年提出了SimAM,这是一种全三维、加权且无参数的注意力机制。与其他现有注意力机制相比,SimAM考虑了空间和通道因素之间的相关性,并且能够高效地为特征映射生成逼真的三维权重,无需额外参数。它通过在速度和准确性方面实现高性能,提高了网络有效表示特征的能力。
在视觉神经科学中,与相邻神经元相比,信息最丰富的神经元表现出不同的放电模式,这种现象被称为信息丰富神经元。这些神经元通常表现出显著的空间抑制效应。这种效应通常对视觉处理任务的结果产生更强的影响。通过评估目标神经元与其他神经元之间的线性可分性,可以区分这些神经元。
此外,图像的边缘属性与空间抑制神经元的属性相匹配,在周围纹理特征方面表现出特别高的对比度。因此,利用能量函数为不同的视觉任务分配三维权重,无需额外参数。
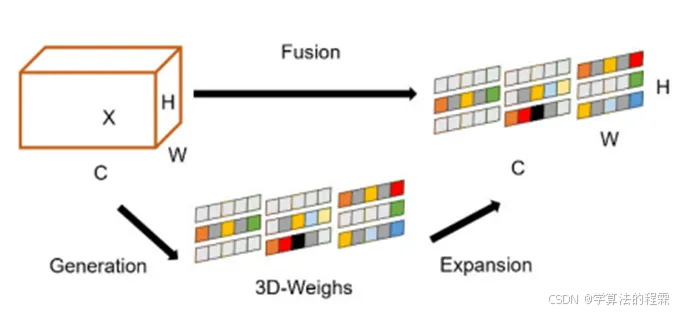
如上图所示,SimAM注意力机制有效地增强了卷积神经网络(CNN)的特征提取能力。在这种情况下,车牌特征图的每个像素都被视为能量函数中的一个神经元,该神经元的最小能量可以表示为。
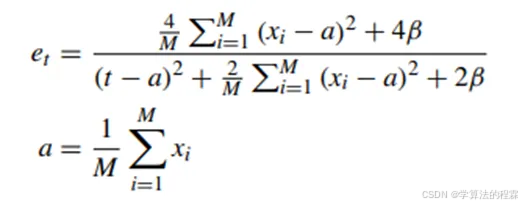
其中t和i分别表示输入特征X∈R(H×W×C次方)的目标神经元以及空间维度的索引。H、W和C分别表示车牌包含H×W个像素和C个光谱波段。M表示通道上的神经元数量,M=H×W,β是一个参数值,通常取为1e-4。α表示针对通道中所有神经元(目标神经元f除外)计算出的平均值,xi表示输入特征X同一通道内的其他神经元(目标神经元f除外)。
由于在空间上受到抑制的神经元表现出显著的线性可分性,它们在α值和t值上都存在明显的变化,这导致了et的值较低。此外,公式(1)表明,神经元的能量越低,神经元t与周围神经元的差异就越明显。因此,每个神经元的权重参数值可以计算为(1/et)。随后,根据注意力机制的定义对特征矩阵进行增强,计算公式如下:
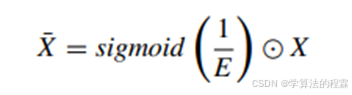
改进的YOLOv7网络架构
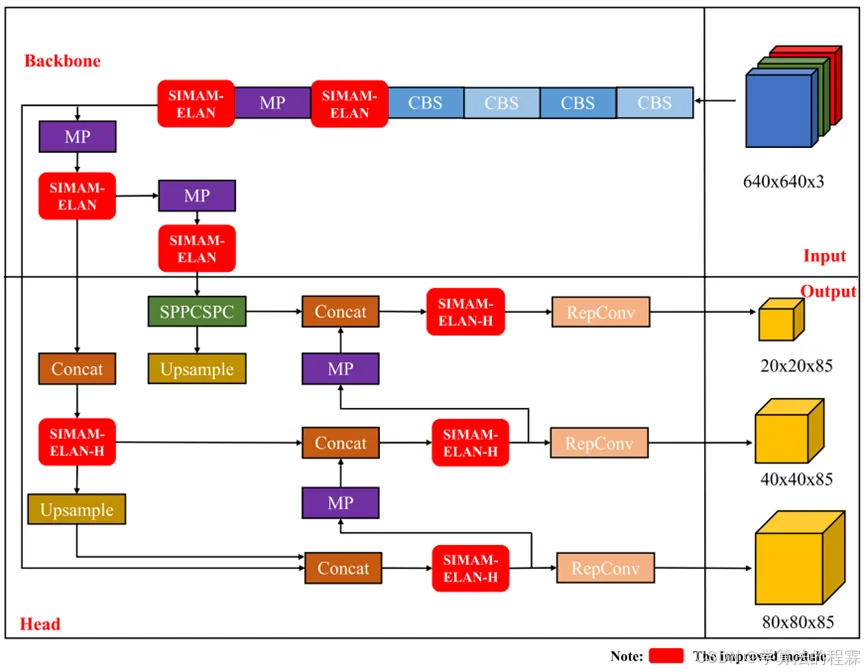
在本节中,基于传统图像识别技术和深度学习目标检测技术的优势,将改进的SimAM嵌入到YOLOv7模型中。这种整合旨在改进其网络架构,提高车牌检测的识别准确率。所提方法的具体流程如下图所示。
1)骨干网络的改进
在特征提取中,骨干网络起着至关重要的作用。原始的YOLOv7架构的骨干网络由50个模块组成,包括CBS模块、最大池化(MP)模块、ELAN和ELAN-H模块。
ELAN和ELAN-H模块是YOLOv7的关键组件,旨在提高网络性能和效率。ELAN模块聚合多层特征,以有效地融合来自不同层次的信息,并利用跳跃连接和多层融合来减少深度网络中常见的梯度消失问题。在ELAN的基础上,E-ELAN进一步增强了特征聚合能力,采用了更高效的层聚合策略来降低计算复杂度,并使用扩展的层聚合技术来提取更丰富的特征。
SimAM注意力机制具有三维权重,将其添加到ELAN和E-ELAN的特征提取能力和计算效率之后,能够更好地优化所提取的车牌特征,并且能够在照明条件复杂的情况下自适应地突出车牌的目标特征,抑制不相关的背景特征,同时不会增加模型的复杂度。与原始主干网络相比,本文提出的改进是在主干网络的ELAN模块和ELAN-H模块中添加SimAM,并引入SimAM注意力机制,从而形成新的SimAM-ELAN和SimAM-ELAN-H模块,如下图所示。
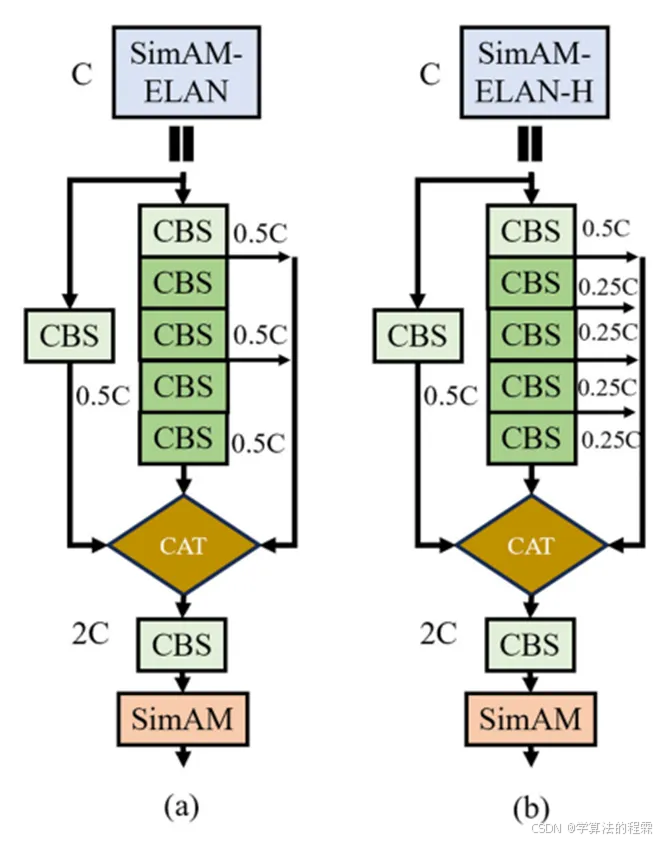
2)Neck层和Head层的改进传统ELAN模块
作为一种高效的远程网络,可通过移位卷积有效提取图像局部结构,并通过共享注意力机制减少模型推理时间。
此外,引入SimAM模块处理原始图像,通过整合SimAM空间和通道注意力机制,可有效解决这一问题,同时基于完善的神经科学理论。
Liang等人于2021年提出的SimAM是一种全三维、加权且无参数的注意力机制。与现有其他注意力机制相比,SimAM兼顾了空间和通道因素间的相关性,能够高效生成真实的三维权重,提升模型的收敛性能。SimAM注意力机制通过评估神经元的重要性来提高模型的注意力能力,其中具有空间抑制效应的神经元被认为更有价值。
我们网络的主要结构如下图所示。对原始网络结构的显著改进包括在头部的SPPCSPC模块之后引入了一个SimAM注意力模块。
实验及可视化
验平台本文实验使用的硬件环境为AMDRyzen55600X6核处理器(主频3.70GHz)和NVIDIAGeForceRTX3060GPU,用于各模块的训练和测试。实验基于Python3.9和PyTorch1.12.0框架实现了YOLO-SLD。此外,在训练阶段采用了YOLOv7的部分预训练模型。在YOLO-SLD中,为在训练阶段针对主干和头部网络结构更有效地提取特征,使用了具有通用性的预训练权重。

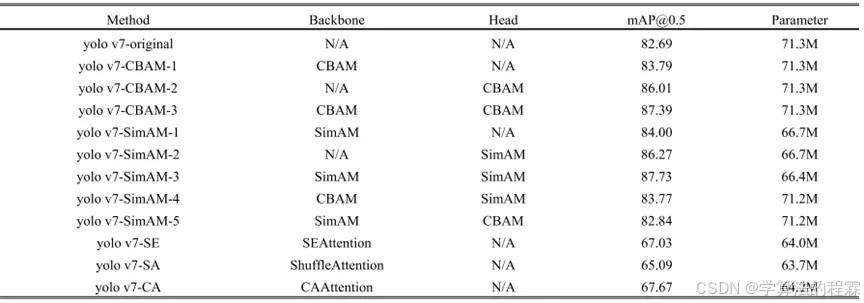
如上表所示,本文进行了11次实验,每次实验都将各种注意力机制集成到卷积层中,并以精度为0.5时的mAP作为评估指标,将其性能与原始的YOLOv7模型进行对比。
为方便起见,将原始的YOLOv7模型命名为YOLOv7-original,将在卷积层中使用不同注意力机制的YOLOv7模型命名为YOLOv7-SimAM,并且将在不同位置添加注意力机制的网络按顺序编号并命名(例如,YOLOv7-SimAM-1)。
结论
针对先进的YOLOv7模型,本文提出了YOLO-SLD网络模型,主要目的是解决和改进车牌检测问题。该模型网络的改进方法主要基于对人类视觉注意力机制的模仿。它采用了SimAM注意力机制,该机制考虑了空间和通道信息,并且可以即时使用。这种机制对YOLOv7主干网络的特征提取和检测组件都进行了优化。这一优化包括替换和添加检测层,同时首次在CCPD数据集上测试了不同注意力机制在车牌检测中的应用。
与多篇研究论文中的其他各种检测网络相比,本文提出的YOLO-SLD模型在CCPD数据集上表现出色。该模型的精度为0.5时的平均平均精度(mAP)达到了98.91%,分别比VertexNet、RLLPDR和YOLOv7模型网络高出0.17%、0.5%和0.47%。Db子集在精度为0.5时的mAP从原始YOLOv7模型的93.5%显著提高到了本文所提模型的96.7%,提升了3.2%。
在参数轻量化方面,YOLO-SLD模型有7010万个参数,少于YOLOv7的7130万个参数。因此,可以推断出本研究中优化后的模型在精度上有显著提高,并且便于部署,非常适合在不同环境中进行车牌检测。在未来的工作中,本文将继续优化模型网络结构。例如,可以专注于车牌内的文本识别,或者整合其他文本识别网络,以充分利用车牌图像中的相关信息,从而增强车牌识别(ALPR)在不同场景下的能力。