Mistral AI 开源最新 Small 模型——Devstral-Small-2505
Devstral 是一款专为软件工程任务设计的代理型大语言模型(LLM),由 Mistral AI 和 All Hands AI 合作开发 🙌。Devstral 擅长使用工具探索代码库、编辑多个文件以及驱动软件工程代理。该模型在 SWE-bench 上表现出色,使其成为该基准测试中排名第一的开源模型。
它基于 Mistral-Small-3.1 进行微调,因此具有长达 128k token 的上下文窗口。作为一款编码代理,Devstral 仅支持文本处理,且在从 Mistral-Small-3.1 微调之前移除了视觉编码器。
对于需要特殊能力(如扩展上下文、领域特定知识等)的企业,我们将发布超越 Mistral AI 社区贡献的商业模型。
了解更多关于 Devstral 的信息,请阅读我们的博客文章。
主要特点:
- 代理编码:Devstral 专为代理编码任务而设计,是软件工程代理的理想选择。
- 轻量级:其紧凑的尺寸仅为 240 亿参数,轻巧到可以在单个 RTX 4090 或 32GB 内存的 Mac 上运行,使其成为本地部署和设备使用的合适模型。
- Apache 2.0 许可证:开放许可证,允许商业和非商业用途的使用和修改。
- 上下文窗口:128k 的上下文窗口。
- 分词器:使用词汇量为 131k 的 Tekken 分词器。
基准测试结果
SWE-Bench
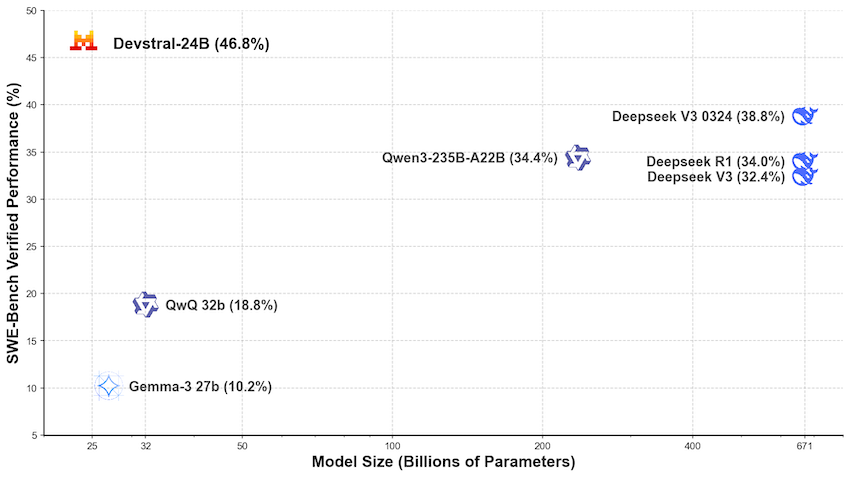
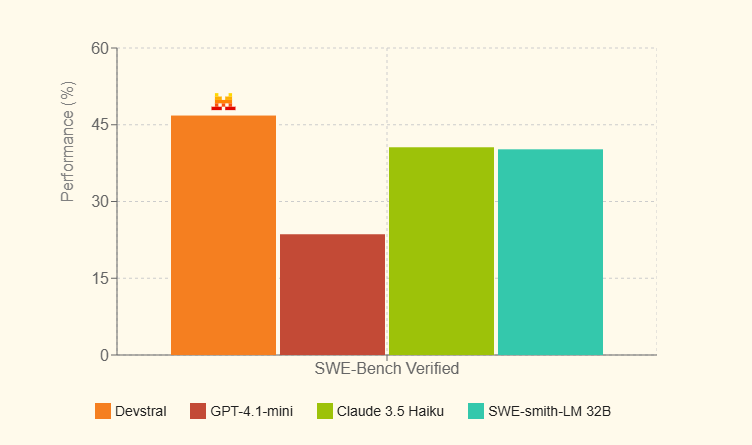
Devstral 在 SWE-Bench Verified 上取得了 46.8% 的分数,比之前的开源 SoTA 高出 6%。
| Model | Scaffold | SWE-Bench Verified (%) |
|---|---|---|
| Devstral | OpenHands Scaffold | 46.8 |
| GPT-4.1-mini | OpenAI Scaffold | 23.6 |
| Claude 3.5 Haiku | Anthropic Scaffold | 40.6 |
| SWE-smith-LM 32B | SWE-agent Scaffold | 40.2 |
在相同的测试框架(由All Hands AI 🙌提供的OpenHands)下进行评估时,Devstral的表现远超更大的模型,如Deepseek-V3-0324和Qwen3 232B-A22B。
使用
我们建议将 Devstral 与 OpenHands 脚手架一起使用。您可以通过我们的 API 或本地运行来使用它。
API
按照以下说明创建 Mistral 账户并获取 API 密钥。
然后运行这些命令以启动 OpenHands docker 容器。
export MISTRAL_API_KEY=<MY_KEY>docker pull docker.all-hands.dev/all-hands-ai/runtime:0.39-nikolaikmkdir -p ~/.openhands-state && echo '{"language":"en","agent":"CodeActAgent","max_iterations":null,"security_analyzer":null,"confirmation_mode":false,"llm_model":"mistral/devstral-small-2505","llm_api_key":"'$MISTRAL_API_KEY'","remote_runtime_resource_factor":null,"github_token":null,"enable_default_condenser":true}' > ~/.openhands-state/settings.jsondocker run -it --rm --pull=always \-e SANDBOX_RUNTIME_CONTAINER_IMAGE=docker.all-hands.dev/all-hands-ai/runtime:0.39-nikolaik \-e LOG_ALL_EVENTS=true \-v /var/run/docker.sock:/var/run/docker.sock \-v ~/.openhands-state:/.openhands-state \-p 3000:3000 \--add-host host.docker.internal:host-gateway \--name openhands-app \docker.all-hands.dev/all-hands-ai/openhands:0.39OpenHands(推荐)
启动服务器以部署 Devstral-Small-2505
确保您已启动如上所述的 OpenAI 兼容服务器,例如 vLLM 或 Ollama。然后,您可以使用 OpenHands 与 Devstral-Small-2505 进行交互。
在本教程中,我们通过运行以下命令启动了一个 vLLM 服务器:
vllm serve mistralai/Devstral-Small-2505 --tokenizer_mode mistral --config_format mistral --load_format mistral --tool-call-parser mistral --enable-auto-tool-choice --tensor-parallel-size 2
服务器地址应采用以下格式:http://<your-server-url>:8000/v1
启动 OpenHands
您可以在此处按照 OpenHands 的安装步骤进行操作。
启动 OpenHands 的最简单方法是使用 Docker 镜像:
docker pull docker.all-hands.dev/all-hands-ai/runtime:0.38-nikolaikdocker run -it --rm --pull=always \-e SANDBOX_RUNTIME_CONTAINER_IMAGE=docker.all-hands.dev/all-hands-ai/runtime:0.38-nikolaik \-e LOG_ALL_EVENTS=true \-v /var/run/docker.sock:/var/run/docker.sock \-v ~/.openhands-state:/.openhands-state \-p 3000:3000 \--add-host host.docker.internal:host-gateway \--name openhands-app \docker.all-hands.dev/all-hands-ai/openhands:0.38然后,您可以在 http://localhost:3000 访问 OpenHands UI。
连接到服务器
当访问 OpenHands UI 时,系统会提示您连接到服务器。您可以使用高级模式连接到您之前启动的服务器。
填写以下字段:
- 自定义模型: openai/mistralai/Devstral-Small-2505
- 基础 URL: http://:8000/v1
- API 密钥: token(或您启动服务器时使用的任何其他令牌,如果有的话)
使用由 Devstral 驱动的 OpenHands
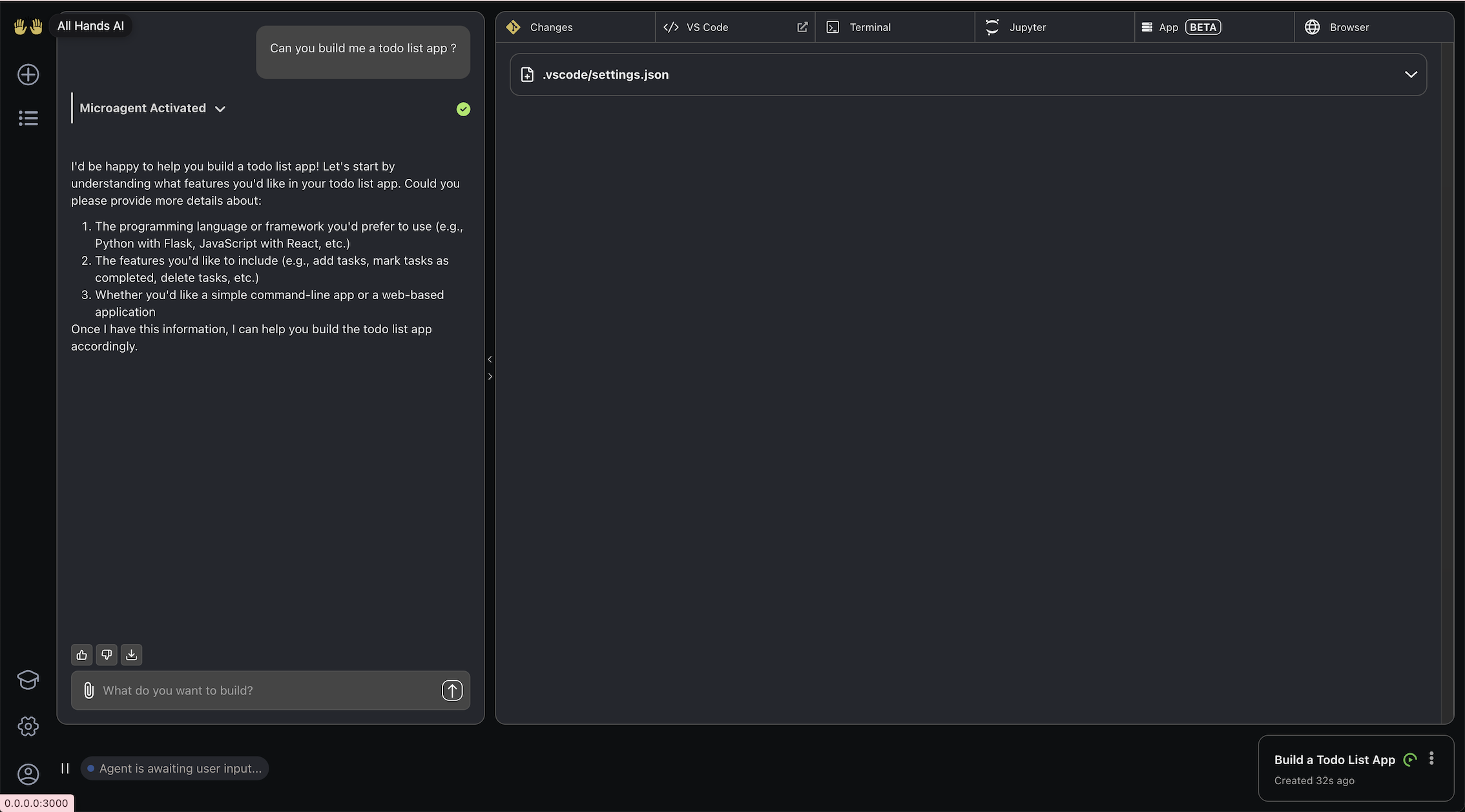
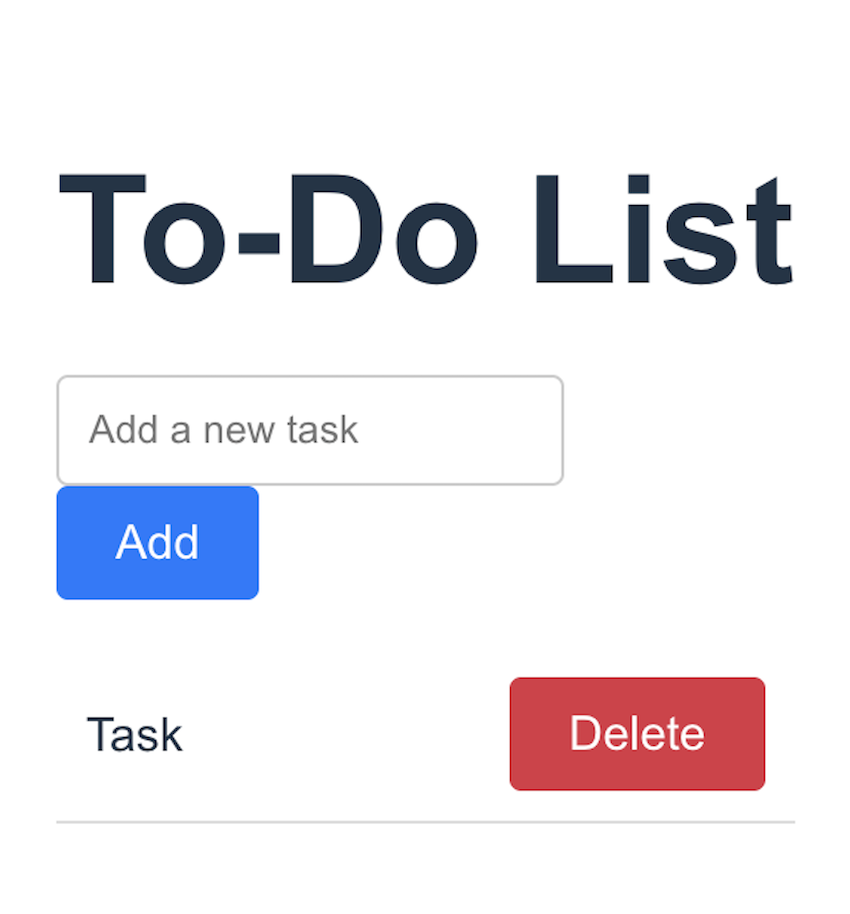
现在,您可以通过开始新对话在 OpenHands 中使用 Devstral Small。让我们构建一个待办事项列表应用程序。
To-Do list app
-
让我们请Devstral用以下提示生成应用程序:
Build a To-Do list app with the following requirements:- Built using FastAPI and React.- Make it a one page app that:- Allows to add a task.- Allows to delete a task.- Allows to mark a task as done.- Displays the list of tasks.- Store the tasks in a SQLite database.
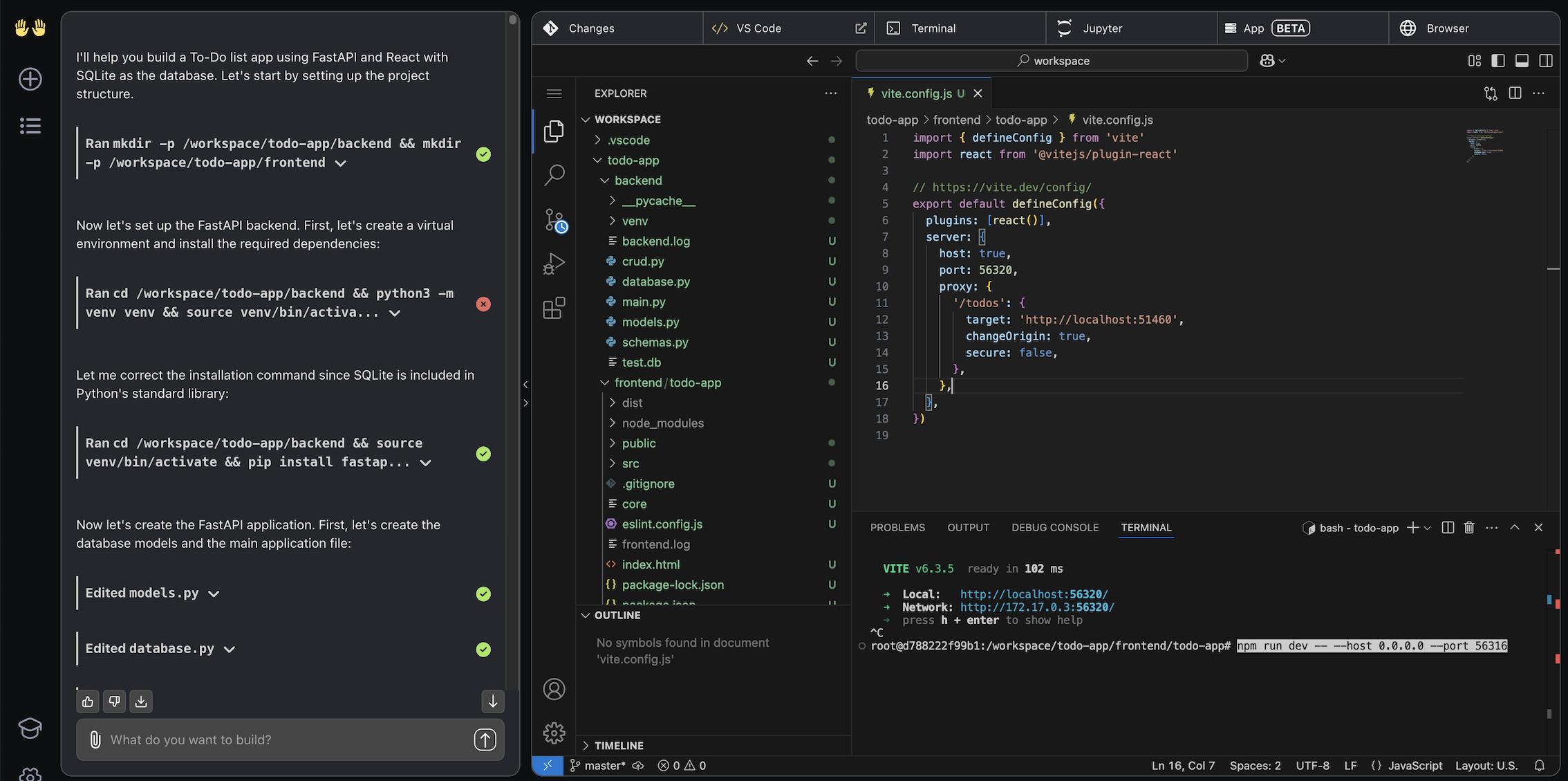
2. 让我们看看结果
你应该会看到代理构建应用程序,并能够探索它生成的代码。
如果它没有自动完成,请让 Devstral 部署应用程序或手动完成,然后前往前端部署 URL 查看应用程序。
3. 迭代
现在你已经有了第一个结果,你可以通过让你的代理改进它来进行迭代。例如,在生成的应用程序中,我们可以点击任务来标记为已完成,但添加一个复选框会提升用户体验。你也可以要求它添加一个编辑任务的功能,或者添加一个按状态过滤任务的功能。
享受使用 Devstral Small 和 OpenHands 进行构建的乐趣吧!
vLLM(推荐)
我们建议使用此模型与vLLM库一起实现生产就绪的推理管道。
安装
确保安装vLLM >= 0.8.5:
pip install vllm --upgrade
检查:
python -c "import mistral_common; print(mistral_common.__version__)"
你也可以使用现成的 Docker 镜像或在 Docker Hub 上查找。
服务器
我们建议您在服务器/客户端设置中使用 Devstral。
- 启动服务器:
vllm serve mistralai/Devstral-Small-2505 --tokenizer_mode mistral --config_format mistral --load_format mistral --tool-call-parser mistral --enable-auto-tool-choice --tensor-parallel-size 2
- 要 ping 客户端,你可以使用一个简单的 Python 代码片段。
import requests
import json
from huggingface_hub import hf_hub_downloadurl = "http://<your-server-url>:8000/v1/chat/completions"
headers = {"Content-Type": "application/json", "Authorization": "Bearer token"}model = "mistralai/Devstral-Small-2505"def load_system_prompt(repo_id: str, filename: str) -> str:file_path = hf_hub_download(repo_id=repo_id, filename=filename)with open(file_path, "r") as file:system_prompt = file.read()return system_promptSYSTEM_PROMPT = load_system_prompt(model, "SYSTEM_PROMPT.txt")messages = [{"role": "system", "content": SYSTEM_PROMPT},{"role": "user","content": [{"type": "text","text": "<your-command>",},],},
]data = {"model": model, "messages": messages, "temperature": 0.15}response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.json()["choices"][0]["message"]["content"])Transformers
为了充分利用我们的模型与变压器,请确保已安装 mistral-common >= 1.5.5 以使用我们的分词器。
pip install mistral-common --upgrade
然后加载我们的分词器以及模型并生成:
import torchfrom mistral_common.protocol.instruct.messages import (SystemMessage, UserMessage
)
from mistral_common.protocol.instruct.request import ChatCompletionRequest
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.tokens.tokenizers.tekken import SpecialTokenPolicy
from huggingface_hub import hf_hub_download
from transformers import AutoModelForCausalLMdef load_system_prompt(repo_id: str, filename: str) -> str:file_path = hf_hub_download(repo_id=repo_id, filename=filename)with open(file_path, "r") as file:system_prompt = file.read()return system_promptmodel_id = "mistralai/Devstral-Small-2505"
tekken_file = hf_hub_download(repo_id=model_id, filename="tekken.json")
SYSTEM_PROMPT = load_system_prompt(model_id, "SYSTEM_PROMPT.txt")tokenizer = MistralTokenizer.from_file(tekken_file)model = AutoModelForCausalLM.from_pretrained(model_id)tokenized = tokenizer.encode_chat_completion(ChatCompletionRequest(messages=[SystemMessage(content=SYSTEM_PROMPT),UserMessage(content="<your-command>"),],)
)output = model.generate(input_ids=torch.tensor([tokenized.tokens]),max_new_tokens=1000,
)[0]decoded_output = tokenizer.decode(output[len(tokenized.tokens):])
print(decoded_output)