DAY 34 GPU训练及类的call方法
- CPU性能的查看:看架构代际、核心数、线程数
- GPU性能的查看:看显存、看级别、看架构代际
- GPU训练的方法:数据和模型移动到GPU device上
- 类的call方法:为什么定义前向传播时可以直接写作self.fc1(x)
(一)CPU性能的查看
!pip install wmi -i https://pypi.tuna.tsinghua.edu.cn/simple
# 查看一下CPU的型号和核心数
import wmic = wmi.WMI()
processors = c.Win32_Processor()for processor in processors:print(f"CPU 型号: {processor.Name}")print(f"核心数: {processor.NumberOfCores}")print(f"线程数: {processor.NumberOfLogicalProcessors}")CPU 型号: 11th Gen Intel(R) Core(TM) i5-11300H @ 3.10GHz
核心数: 4
线程数: 8- 11th Gen:代表第十一代智能英特尔酷睿处理器 ,表明其所属代数,新一代往往在制程、性能、功能特性上有改进提升。
- Intel Core:Intel 即英特尔,是生产厂商;Core 指酷睿系列,是英特尔面向中高端消费级市场的产品系列。
- i5:酷睿系列下的产品定位标识 。i5 属于主流性能级别,定位在 i3(入门级)和 i7(高性能级)、i9(发烧级)之间,平衡多任务处理与单线程性能。
- 11300H:
- 11:与前面 “11th Gen” 呼应,再次明确是第十一代产品。
- 3:代表产品系列中相对性能定位,数字越大性能越强,如 i5 系列中,3 开头定位低于 5、7 开头产品 。
- 00:通常为预留编号,用于区分不同配置、特性或小改款等,此处无特殊明确意义。
- H:处理器后缀字母,代表 High - performance Graphics and Memory,即高性能图形处理和内存支持,属于标压处理器,适用于高性能需求的笔记本,功耗和性能释放较高。
- 3.10GHz:CPU 的基础主频 ,即处理器在默认稳定状态下的运行频率,单位是吉赫兹(GHz) ,该频率下处理数据的速度基准。
判断 CPU 的好坏需要综合考虑硬件参数、性能表现、适用场景。
1. 看架构代际,新一代架构通常优化指令集、缓存设计和能效比。如Intel 第 13 代 i5-13600K 比第 12 代 i5-12600K 多核性能提升约 15%
2. 看制程工艺,制程越小,晶体管密度越高,能效比越好,如AMD Ryzen 7000 系列(5nm)比 Ryzen 5000 系列(7nm)能效比提升约 30%。
3. 看核心数:性能核负责高负载任务(如游戏、视频剪辑),单核性能强。能效核负责多任务后台处理(如下载、杀毒),功耗低。如游戏 / 办公:4-8 核足够,内容创作 / 编程:12 核以上更优。
4. 看线程数目
5. 看频率,高频适合单线程任务(如游戏、Office),低频多核适合多线程任务(如 3D 渲染)
6. 支持的指令集和扩展能力。
(二)GPU性能的查看
(我的电脑无CUDA,仅供代码代考)
- 衡量GPU好坏
以RTX 3090 Ti, RTX 3080, RTX 3070 Ti, RTX 3070, RTX 4070等为例
- 通过“代”
前两位数字代表“代”: 40xx (第40代), 30xx (第30代), 20xx (第20代)。“代”通常指的是其底层的架构 (Architecture)。每一代新架构的发布,通常会带来工艺制程的进步和其他改进。也就是新一代架构的目标是在能效比和绝对性能上超越前一代同型号的产品。
- 通过级别:后面的数字代表“级别”,
- xx90: 通常是该代的消费级旗舰或次旗舰,性能最强,显存最大 (如 RTX 4090, RTX 3090)。
- xx80: 高端型号,性能强劲,显存较多 (如 RTX 4080, RTX 3080)。
- xx70: 中高端,甜点级,性能和价格平衡较好 (如 RTX 4070, RTX 3070)。
- xx60: 主流中端,性价比较高,适合入门或预算有限 (如 RTX 4060, RTX 3060)。
- xx50: 入门级,深度学习能力有限。
- 通过后缀
Ti 通常是同型号的增强版,性能介于原型号和更高一级型号之间 (如 RTX 4070 Ti 强于 RTX 4070,小于4080)。
- 通过显存容量 VRAM (最重要!!)
他是GPU 自身的独立高速内存,用于存储模型参数、激活值、输入数据批次等。单位通常是 GB(例如 8GB, 12GB, 24GB, 48GB)。如果显存不足,可能无法加载模型,或者被迫使用很小的批量大小,从而影响训练速度和效果
- 检查CUDA是否可用
import torch# 检查CUDA是否可用
if torch.cuda.is_available():print("CUDA可用!")# 获取可用的CUDA设备数量device_count = torch.cuda.device_count()print(f"可用的CUDA设备数量: {device_count}")# 获取当前使用的CUDA设备索引current_device = torch.cuda.current_device()print(f"当前使用的CUDA设备索引: {current_device}")# 获取当前CUDA设备的名称device_name = torch.cuda.get_device_name(current_device)print(f"当前CUDA设备的名称: {device_name}")# 获取CUDA版本cuda_version = torch.version.cudaprint(f"CUDA版本: {cuda_version}")# 查看cuDNN版本(如果可用)print("cuDNN版本:", torch.backends.cudnn.version())else:print("CUDA不可用。")CUDA可用!
可用的CUDA设备数量: 1
当前使用的CUDA设备索引: 0
当前CUDA设备的名称: NVIDIA GeForce RTX 3080 Ti
CUDA版本: 11.1
cuDNN版本: 8005# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")使用设备: cuda:0(三)GPU训练的方法
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU
# 分类问题交叉熵损失要求标签为long类型
# 张量具有to(device)方法,可以将张量移动到指定的设备上
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10)self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3)def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
# MLP继承nn.Module类,所以也具有to(device)方法
model = MLP().to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 20000
losses = []
start_time = time.time()for epoch in range(num_epochs):# 前向传播outputs = model(X_train)loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 记录损失值losses.append(loss.item())# 打印训练信息if (epoch + 1) % 100 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')time_all = time.time() - start_time
print(f'Training time: {time_all:.2f} seconds')# 可视化损失曲线
plt.plot(range(num_epochs), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()输出结果:
显然cpu跑了3s,gpu跑了11s。并没有出现我们如前所说gpu比cpu快很多的情况。
原因:
- 数据传输开销 (CPU 内存 <-> GPU 显存)
-
核心启动开销 (GPU 核心启动时间)
-
性能浪费:计算量和数据批次
总结:数据传输和各种固定开销的总和,超过了 GPU 在这点计算量上通过并行处理所能节省的时间,导致了 GPU 比 CPU 慢的现象。
- CPU (12th Gen Intel Core i9-12900KF): 对于这种小任务,CPU 的单核性能强劲,且没有显著的数据传输到“另一块芯片”的开销。它可以非常迅速地完成计算。
- GPU (NVIDIA GeForce RTX 3080 Ti):需要花费时间将数据和模型从 CPU 内存移动到 GPU 显存。
- 每次在 GPU 上执行运算(如 model(X_train)、loss.backward()) 都有核心启动的固定开销。
- loss.item() 在每个 epoch 都需要将结果从 GPU 传回 CPU,这在总共 20000 个 epoch 中会累积。
- GPU 强大的并行计算能力在这种小任务上完全没有用武之地。
这些特性导致GPU在处理鸢尾花分类这种“玩具级别”的问题时,它的优势无法体现,反而会因为上述开销显得“笨重”。那么什么时候 GPU 会发挥巨大优势?
- 大型数据集: 例如,图像数据集成千上万张图片,每张图片维度很高。
- 大型模型: 例如,深度卷积网络 (CNNs like ResNet, VGG) 或 Transformer 模型,它们有数百万甚至数十亿的参数,计算量巨大。
- 合适的批处理大小: 能够充分利用 GPU 并行性的 batch size,不至于还有剩余的计算量没有被 GPU 处理。
- 复杂的、可并行的运算: 大量的矩阵乘法、卷积等。
所以,为了缩短时间,我们可以有以下两个思路进行改进:
1. 直接不打印训练过程的loss了,但是这样会没办法记录最后的可视化图片,只能肉眼观察loss数值变化。
2. 每隔200个epoch保存一下loss,不需要20000个epoch每次都打印
我们使用第二个方法进行改进:
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 将数据转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型并移至GPU
model = MLP().to(device)# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每100个epoch的损失值和对应的epoch数
losses = []start_time = time.time() # 记录开始时间for epoch in range(num_epochs):# 前向传播outputs = model(X_train) # 隐式调用forward函数loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 记录损失值if (epoch + 1) % 200 == 0:losses.append(loss.item()) # item()方法返回一个Python数值,loss是一个标量张量print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')# 打印训练信息if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')time_all = time.time() - start_time # 计算训练时间
print(f'Training time: {time_all:.2f} seconds')# 可视化损失曲线
plt.plot(range(len(losses)), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()
此时问题来了:作业
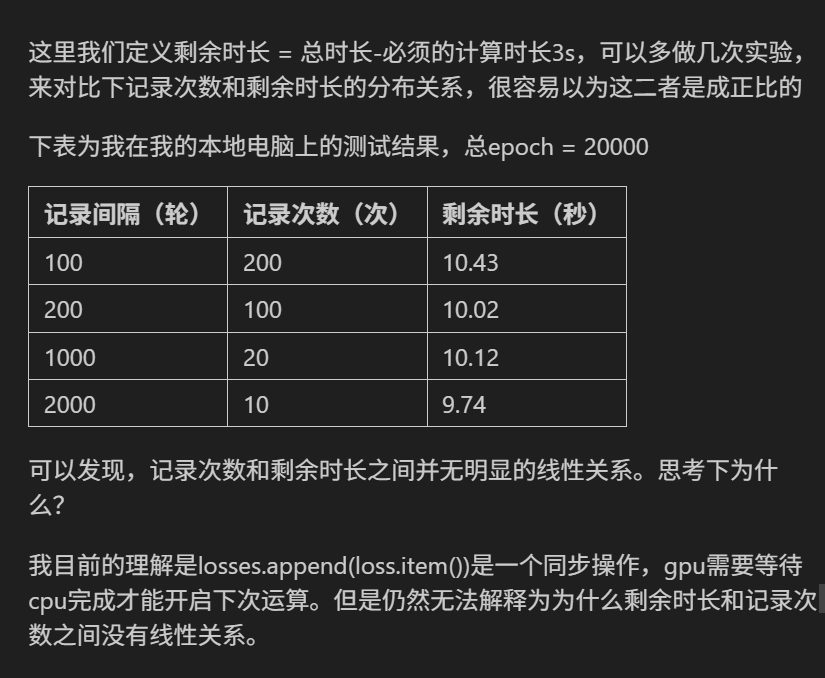
以下为推测的可能原因:
- 同步操作(
.item())的固定开销
在PyTorch中,loss.item() 是一个同步操作,它会强制GPU完成当前计算并将数据传输到CPU。这一过程会引入短暂的等待时间(同步开销),但每次同步的时间大致固定。当记录次数减少时,总同步次数的减少会被固定开销的线性累积所抵消。然而,实验结果显示剩余时长的差异仅为约0.7秒(10.43 → 9.74),说明同步开销可能远小于假设值,导致其总开销在总时长中占比极小
-
打印操作的耗时
代码中存在双重打印逻辑,当记录间隔为100时,实际上会每100轮打印两次(当轮数是100的倍数但不是200的倍数时)。这会显著增加打印次数,而打印到控制台是一个相对耗时的操作(涉及I/O等待)。不同记录间隔下的实际打印次数可能差异较大,导致总时间无法按记录次数线性减少。
-
系统噪声与测量误差(关系不大)
Python全局解释器锁(GIL):在频繁的CPU操作(如列表追加losses.append())中可能引入微小延迟。
(四)__call__方法
__call__ 方法是一个特殊的魔术方法(双下划线方法),它允许类的实例像函数一样被调用。这种特性使得对象可以表现得像函数,同时保留对象的内部状态。当对实例使用 实例名() 语法时,Python 会自动调用该实例的 __call__ 方法。
__call__ 方法让对象具备“函数化”的能力,适用于需要维护状态的场景(如计数器、缓存)或需要封装复杂逻辑的类(如深度学习模型)
代码示例
# 我们来看下昨天代码中你的定义函数的部分
class MLP(nn.Module): # 定义一个多层感知机(MLP)模型,继承父类nn.Moduledef __init__(self): # 初始化函数super(MLP, self).__init__() # 调用父类的初始化函数# 前三行是八股文,后面的是自定义的self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层
# 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,交叉熵函数内部有softmax函数,会把输出转化为概率def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out可以注意到,self.fc1 = nn.Linear(4, 10) 此时,是实例化了一个nn.Linear(4, 10)对象,并把这个对象赋值给了MLP的初始化函数中的self.fc1变量。那为什么下面的前向传播中却可以out = self.fc1(x) 呢?,self.fc1是一个实例化的对象,为什么具备了函数一样的用法,这是因为nn.Linear继承了nn.Module类,nn.Module类中定义了__call__方法。(可以ctrl不断进入来查看)
在 Python 中,任何定义了 __call__ 方法的类,其实例都可以像函数一样被调用。当调用 self.fc1(x) 时,实际上执行的是:
- self.fc1.__call__(x)(Python 的隐式调用)
- 而 nn.Module 的 __call__ 方法会调用子类的 forward 方法(即 self.fc1.forward(x))。这个方法就是个前向计算方法。
relu是torch.relu()这个函数为了保持写法一致,又封装成了nn.ReLU()这个类。来保证接口的一致性PyTorch 官方强烈建议使用 self.fc1(x),因为它会触发完整的前向传播流程(包括钩子函数)这是 PyTorch 的核心设计模式,几乎所有组件(如 nn.Conv2d、nn.ReLU、甚至整个模型)都可以这样调用。
# 不带参数的call方法
class Counter:def __init__(self):self.count = 0def __call__(self):self.count += 1return self.count# 使用示例
counter = Counter()
print(counter()) # 输出: 1
print(counter()) # 输出: 2
print(counter.count) # 输出: 2类名后跟(),表示创建类的实例(对象),仅在第一次创建对象时发生。call方法无参数的情况下,在实例化之后,每次调用实例时触发 __call__ 方法。
注意点:
- 参数传递 : __call__ 方法可以接受任意数量的参数,就像普通函数一样。第一个参数通常是 self ,表示类的实例本身。
- 可调用对象 :定义了 __call__ 方法的类实例被称为可调用对象。可以使用 callable() 函数来检查一个对象是否可调用。
- 与其他特殊方法结合使用 : __call__ 方法可以与其他特殊方法(如 __init__ 、 __str__ 等)结合使用,以实现更复杂的功能。
- 性能考虑 :虽然 __call__ 方法提供了很大的灵活性,但频繁调用可能会带来一定的性能开销,因为每次调用都需要查找和执行 __call__ 方法。
总结:__call__ 方法为Python类提供了函数式编程的能力,使得类的实例可以像函数一样被调用,增加了代码的灵活性和可读性