根据Cortex-M3(STM32F1)权威指南讲解MCU内存架构与如何查看编译器生成的地址具体位置
首先我们先查看官方对于Cortex-M3预定义的存储器映射
1.存储器映射
1.1 Cortex-M3架构的存储器结构
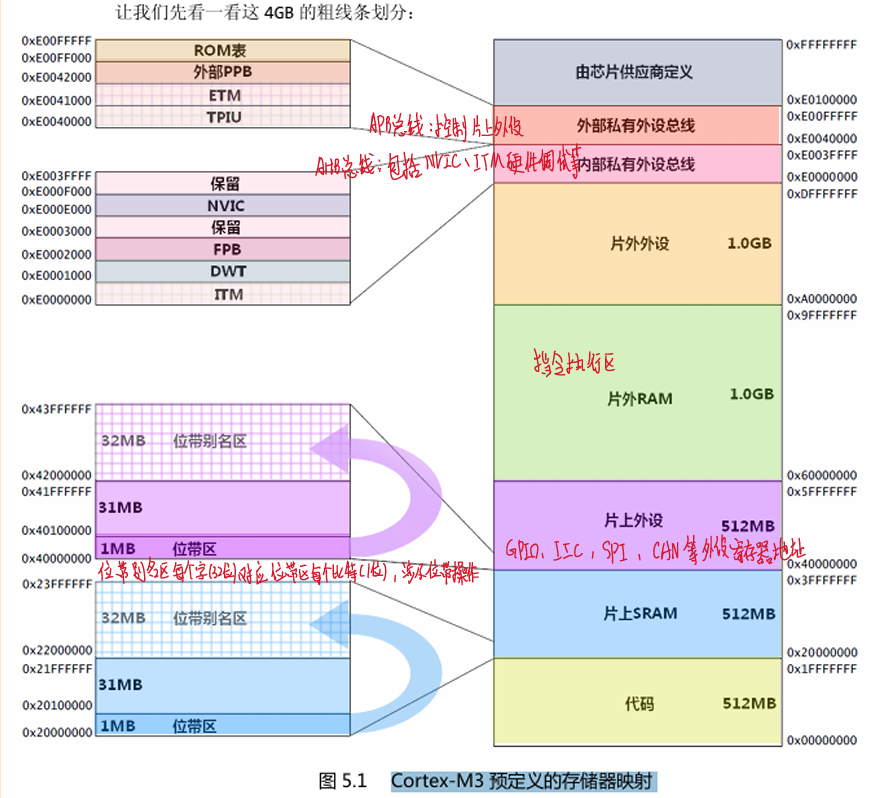
内部私有外设总线:即AHB总线,包括NVIC中断,ITM硬件调试,FPB, DWT。
外部私有外设总线:即APB总线,用于内部“外设”的操作(SPI,IIC,USART)等,也用于些片上APB外设到APB私有总线上(SD卡,LCD显示屏)的访问。
他们的物理地址关系如下图所示:
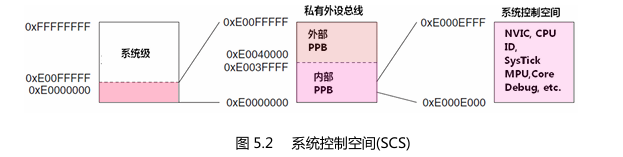
2.RAM和FLASH的基本概念与作用
从上面的描述可以知道,其实Cortex-M3分配的地址很多都是不允许修改的,能修改的只有代码区的FLASH和上电后代码运行的片上SRAM区的RAM,我们这章就着重讲一下这两个地方。
1.2.1RAM的基本概念与作用
RAM(随机存取存储器)在STM32中主要用于存储运行时的数据和变量。它是易失性存储器,断电后数据会丢失。RAM的作用包括:
- 存储程序运行时的临时数据,如局部变量、堆栈和动态分配的内存。
- 提供快速的数据访问,支持CPU的高效运行。
- 用于存储中断向量表、全局变量和静态变量。
1.2.2 FLASH的基本概念与作用
FLASH存储器在STM32中用于存储程序代码和常量数据。它是非易失性存储器,断电后数据不会丢失。FLASH的作用包括:
- 存储固件程序代码,包括主程序、中断服务程序和库函数。
- 存储常量数据,如查找表、配置参数和字符串。
- 支持程序更新和固件升级,通过编程接口可以擦除和写入数据。
1.2.3 程序的典型内存分布和用途
内存分布:
+------------------+ 0x20005000 (RAM 结束)
| Heap | 动态分配(malloc)
+------------------+
| Stack | 栈(局部变量、返回地址)
+------------------+
| .bss | 未初始化数据(RAM)
+------------------+
| .data | 已初始化全局变量(RAM)
+------------------+ 0x20000000 (RAM 起始)+------------------+ 0x08010000 (Flash 结束)
| .rodata | 只读数据(Flash)
+------------------+
| .text | 代码段(Flash)
+------------------+ 0x08000000 (Flash 起始)各个区域用途:
| 存储区域 | 用途 | 存储位置 |
|---|---|---|
| .text(Code) | 存放编译后的程序指令(代码) | Flash(只读) |
| .rodata(RO-data) | 存放只读常量(const 变量等) | Flash(只读) |
| .data(RW-data) | 已初始化的全局/静态变量 | Flash + RAM |
| .bss(ZI-data) | 未初始化的全局/静态变量,启动时清零 | RAM(自动清零) |
| Heap(堆) | malloc() 动态分配的内存 | RAM(向上增长) |
| Stack(栈) | 局部变量、函数调用返回地址 | RAM(向下增长) |
注意:
.data段在 Flash 里存有初值,但运行时会被复制到 RAM。.bss段不会占用 Flash,但会在 RAM 里初始化为 0。- 栈和堆共享 RAM,栈 Stack 从 高地址→ 低地址方向增长。
- 堆 Heap 从 低地址→ 高地址 方向增长。
- 当 Stack 和 Heap 彼此增长到一个临界点(即二者相遇),就会导致 Stack Overflow(栈溢出)。
下面举一个例子供大家更深入了解代码变量的存储方式:
int a = 0; //全局初始化区
char *p1; //全局未初始化区
main()
{ int b;//栈 char s[] = "abc";//栈 char * p2;//栈 char * p3 = "123456";//123456\0在常量区,p3在栈上。 static int c =0;//全局(静态)初始化区 p1 = (char *)malloc(10);//堆 p2 = (char *)malloc(20);//堆
}3.如何查看自己代码的各个区的地址位置
3.1 为什么要查看各个区的地址
虽然我们在官方文档中知道了Cortex-M3的各个部分的大概范围,但我们使用CUBEMX或者操作系统生成的项目肯定不会规规矩矩的完全按照官方文档来配置各个区。比如RT-Thread的内存管理将.data段和.bss段一起管理起来了,创建各种任务所使用的内存都由RT-Thread统一分配。或者在CUBEMX中你可以自行设计堆区和栈区的大小等等。
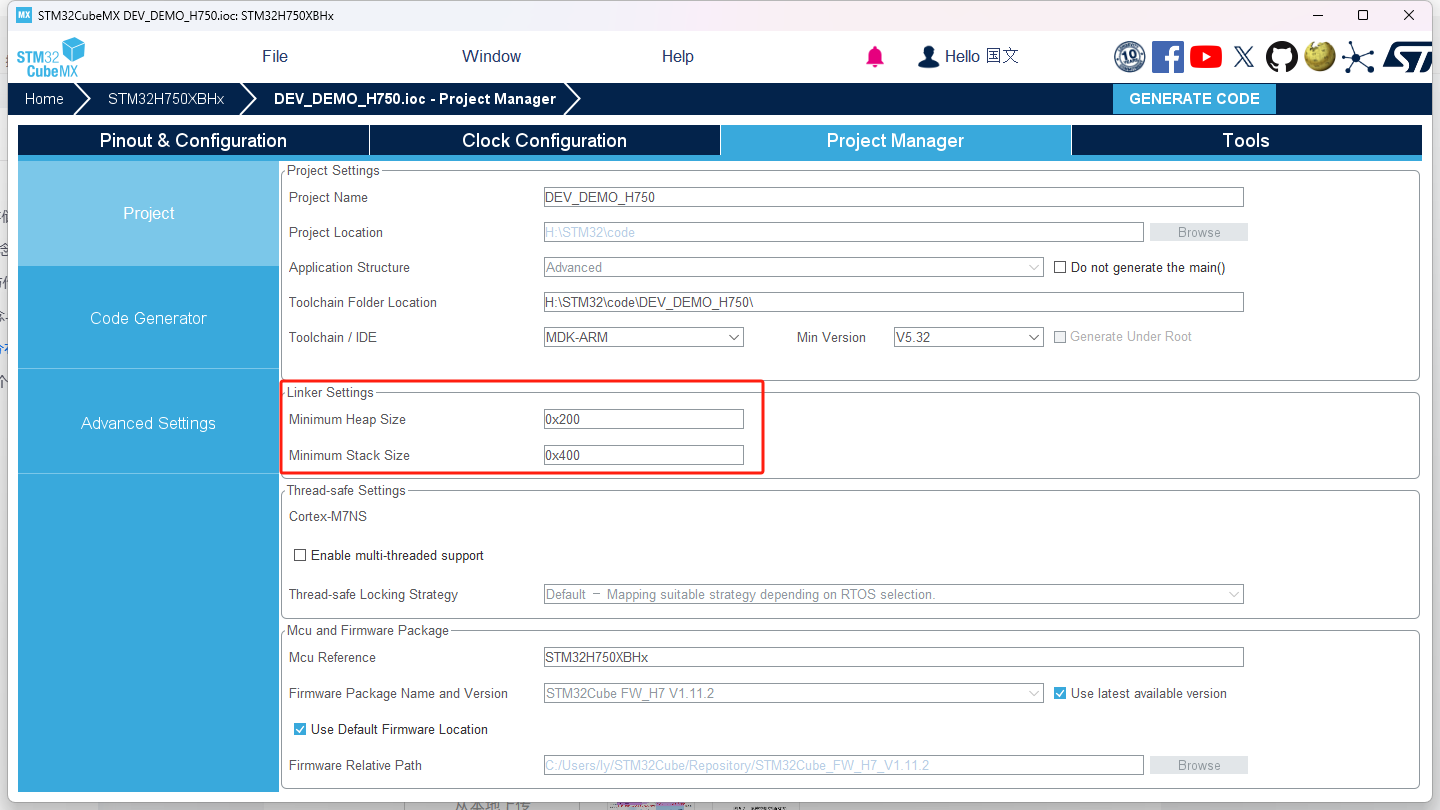
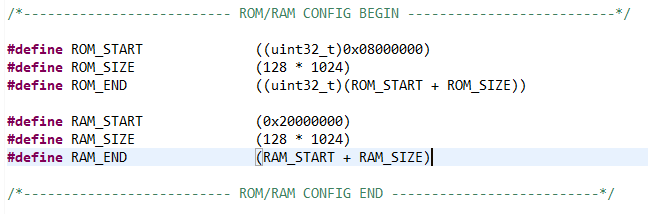
而我们在使用内存管理的时候开辟一个专门存放变量的空间,我们需要的不只是简单的知道这个变量的大小,我们还需要知道它的地址(要不然你使用这个变量还要编译器找这个地址在哪里这样才能提升项目的管理分配和运行效率,那根我直接开辟一个变量有什么区别?)而我开辟的地方也有讲究,因为只有Heap(堆区)才能给与我们自由分配空间并进行读写的权利。因此找到各个区的地址我认为是有必要的。
那我们应该怎么找到各个区的地址呢?
那就是查看代码编译后生成的.map文件
3.2 解析查找地址的.map文件的代码含义
代码来源:https://www.waveshare.net/w/upload/3/39/E-Paper_code.7z
注意:你要使用了malloc等函数才会存在heap区的开辟,要不然你在.map文件中是找不到heap的创建地址的。
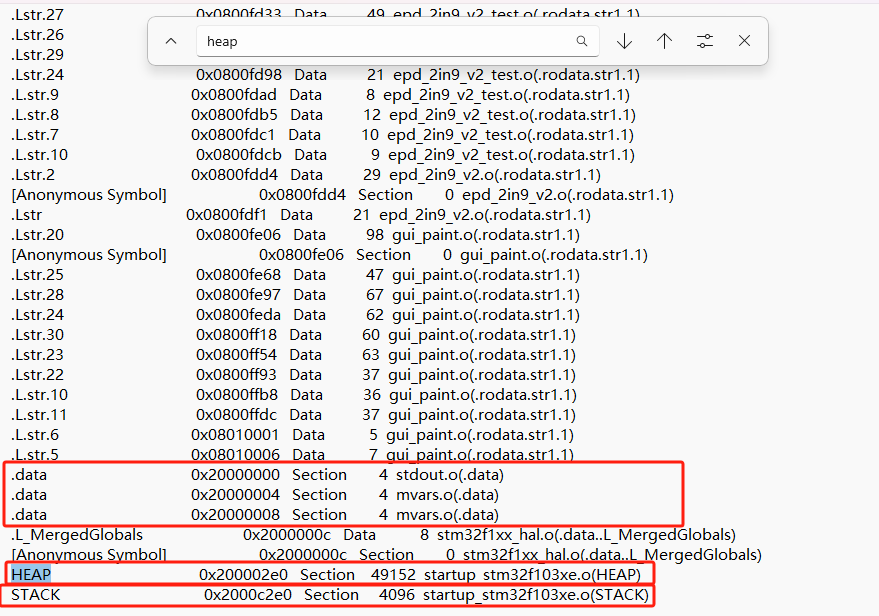

我们得到了下面的关于堆的说明
HEAP 0x200002e0 Section 49152 startup_stm32f103xe.o(HEAP)
STACK 0x2000c2e0 Section 4096 startup_stm32f103xe.o(STACK)
__heap_base 0x200002e0 Data 0 startup_stm32f103xe.o(HEAP)
__heap_limit 0x2000c2e0 Data 0 startup_stm32f103xe.o(HEAP)
__initial_sp 0x2000d2e0 Data 0 startup_stm32f103xe.o(STACK)
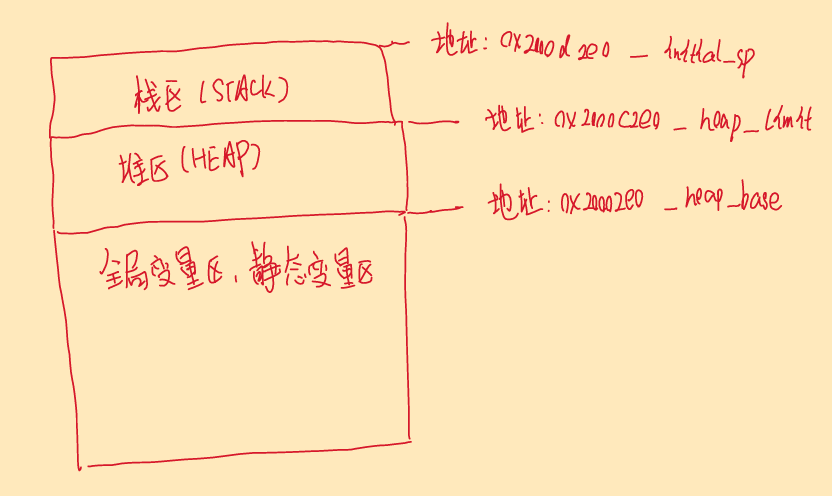
HEAP:是堆的基地址
__initial_sp:是栈的起始地址(栈顶)。
__heap_base:堆的起始地址。
__heap_limit:堆的结束地址。
示意图如下
4. 总结
如果我们设置了堆的空间大小,但是我们程序中没有进行malloc申请,那么在程序事假运行的时候,我们栈的空间超过本身设置的空间,进入到堆里面,那么程序是不会出错的,但是超过了堆的空间了,进入到全局变量区域,就会出现莫名其妙的错误。
不使用malloc,我们可以将堆设置成0,这是没有问题的,但是栈的空间大小要设置成合适的,不然就会因为栈溢出,进入harderror,程序奔溃。