embedding的微调
1.Embedding模型评价维度
-
基础性能指标
- 最大输入长度:决定单次可处理的文本长度(越长越好)
- 数据维度上限:维度越高,语义表征越全面精准(需平衡效率与复杂度)
-
具体任务能力评估
-
分类任务(Classification)
目标:对文本进行准确分类
衡量:分类准确率 -
聚类任务(Clustering)
目标:将无标签文本分组为有意义类别
衡量:聚类质量指标(如轮廓系数) -
句子对分类(Pair Classification)
目标:判断文本对的标签关系(如是否相似/相关)
衡量:分类准确率、F1值 -
语义文本相似度(STS)
目标:量化句子对的语义相似程度
衡量:模型生成的向量余弦相似度与人工标注的相关性 -
检索任务(Retrieval)
目标:根据查询从语料库中匹配相关文档
衡量:以nDCG@10为核心指标(兼顾排序质量与相关性) -
重排序(Reranking)
目标:对检索结果按相关性重新排序
衡量:基于余弦相似度的排序质量平均值
-
关键特点总结
- 多维度验证:涵盖分类、检索、语义理解等核心场景,全面评估模型能力。
- 量化指标驱动:依赖
nDCG@10、余弦相似度等客观指标,减少主观偏差。 - 实用导向:强调模型在长文本处理、高维语义表征等实际需求中的表现。
2.RAG场景下Embedding模型与Rerank模型的分工协作
一、模型性能对比
| 对比维度 | Embedding模型 | Rerank模型 |
|---|---|---|
| 模型架构 | 双向编码器(Bi-Encoder) | 交叉编码器(Cross-Encoder) |
| 计算时间成本 | 低(横向对比) | 高(横向对比) |
| 语义匹配精度 | 基础精度(适合初筛) | 高精度(适合精排) |
| 输入处理方式 | 文本对独立编码 | 文本对联合交互计算 |
二、RAG场景协作流程
-
召回阶段
使用Embedding模型快速生成文本向量,通过向量相似度从海量数据中召回Top100-200相关文档(高效率优先)。 -
精排阶段
将初筛结果输入Rerank模型,通过交叉注意力机制计算细粒度语义匹配分数,输出Top5-10精准结果(精度优先)。
三、技术原理差异
-
Bi-Encoder
对Query和Passage分别独立编码为固定向量,通过余弦相似度计算匹配度。
优势:预计算文档向量可实现毫秒级检索
局限:无法捕捉细粒度交互特征 -
Cross-Encoder
将Query和Passage拼接后联合编码,通过[SEP]标记进行注意力交互计算。
优势:捕捉词级/短语级语义交互,匹配判断更精准
局限:需实时计算,无法预存向量
四、工程实践建议
- 数据规模>1万条时必须采用两级流水线,避免直接用Rerank模型全量计算
- 精度敏感场景(如医疗问答)建议设置Rerank阈值过滤,如仅保留相似度>0.85的结果
- 延迟敏感场景可对Embedding模型量化压缩(如INT8量化),提速30%以上
3.微调实践
1)准备数据
1)下载数据集
pip install -U datasetsfrom datasets import load_datasetds = load_dataset("virattt/financial-qa-10K", split="train")2)重构数据集结构,使其更适合检索或问答任务(如RAG场景)
ds = ds.select_columns(column_names=["question", "context"])
ds = ds.rename_column("question", "query")
ds = ds.rename_column("context", "pos")
ds = ds.add_column("id", [str(i) for i in range(len(ds))])3)构造包含负样本的训练数据
import numpy as npnp.random.seed(520)
neg_num = 10def str_to_lst(data):data["pos"] = [data["pos"]]return data# sample negative texts
new_col = []
for i in range(len(ds)):ids = np.random.randint(0, len(ds), size=neg_num)while i in ids:ids = np.random.randint(0, len(ds), size=neg_num)neg = [ds[i.item()]["pos"] for i in ids]new_col.append(neg)
ds = ds.add_column("neg", new_col)# change the key of 'pos' to a list
ds = ds.map(str_to_lst)4)为数据集中的每个样本添加一个统一的指令前缀(prompt)
instruction = "Represent this sentence for searching relevant passages: "
ds = ds.add_column("prompt", [instruction]*len(ds))5)数据集举例
ds[0]
{'query': 'What area did NVIDIA initially focus on before expanding to other computationally intensive fields?','pos': ['Since our original focus on PC graphics, we have expanded to several other large and important computationally intensive fields.'],'id': '0','neg': ['Kroger expects that its value creation model will deliver total shareholder return within a target range of 8% to 11% over time.','CSB purchased First Mortgages of $2.9 billion during 2023.','See Note 13 to our Consolidated Financial Statements for information on certain legal proceedings for which there are contingencies.','Diluted earnings per share were $16.69 in fiscal 2022 compared to $15.53 in fiscal 2021.','In the year ended December 31, 2023, Total net sales and revenue increased primarily due to: (1) increased net wholesale volumes primarily due to increased sales of crossover vehicles and full-size pickup trucks, partially offset by decreased sales of mid-size pickup trucks; (2) favorable Price as a result of low dealer inventory levels and strong demand for our products; (3) favorable Mix associated with increased sales of full-size pickup trucks and full-size SUVs and decreased sales of vans, passenger cars and mid-size pickup trucks, partially offset by increased sales of crossover vehicles; and (4) favorable Other due to increased sales of parts and accessories.','As of December 31, 2023, we had 3,157 full-time employees.','Item 3. Legal Proceedings. The information contained in Note 18 ‘‘Commitments and Contingencies’’ included in Item 8 of this 10-K is incorporated herein by reference.','Under the amended 2019 Secured Facility, the maturity date is set to July 20, 2026.','Accounts receivable for Las Vegas Sands Corp. on December 31, 2023, totaled $685 million, with a provision for credit losses of $201 million, resulting in a net balance of $484 million.','Operating expenses as a percentage of segment net sales decreased 25 basis points for fiscal 2023 when compared to the previous fiscal year, primarily driven by strong sales growth and lower incremental COVID-19 related costs, partially offset by increased wage costs.'],'prompt': 'Represent this sentence for searching relevant passages: '}6)划分训练集和测试集
split = ds.train_test_split(test_size=0.1, shuffle=True, seed=520)
train = split["train"]
test = split["test"]
train.to_json("ft_data/training.json")7) 从测试集数据中提取查询文本(query)并重命名列,生成一个专门用于检索任务的标准查询数据集
queries = test.select_columns(column_names=["id", "query"])
queries = queries.rename_column("query", "text")
queries[0]8)从数据集 ds 中提取文档(正样本)数据,并重命名列以生成标准化的语料库数据集。
corpus = ds.select_columns(column_names=["id", "pos"])
corpus = corpus.rename_column("pos", "text")9)构建一个标准的相关性评估数据集(qrels),用于衡量检索系统返回的文档与查询之间的相关性
qrels = test.select_columns(["id"])
qrels = qrels.rename_column("id", "qid")
qrels = qrels.add_column("docid", list(test["id"]))
qrels = qrels.add_column("relevance", [1]*len(test))10)
queries.to_json("ft_data/test_queries.jsonl")
corpus.to_json("ft_data/corpus.jsonl")
qrels.to_json("ft_data/test_qrels.jsonl")2)微调
%%bash
torchrun --nproc_per_node 1 \-m FlagEmbedding.finetune.embedder.encoder_only.base \--model_name_or_path /mnt/workspace/dir \--cache_dir ./cache/model \--train_data /mnt/workspace/training.json \--cache_path ./cache/data \--train_group_size 8 \--query_max_len 512 \--passage_max_len 512 \--pad_to_multiple_of 8 \--query_instruction_for_retrieval 'Represent this sentence for searching relevant passages: ' \--query_instruction_format '{}{}' \--knowledge_distillation False \--output_dir ./test_encoder_only_base_bge-large-en-v1.5 \--overwrite_output_dir \--learning_rate 1e-5 \--fp16 \--num_train_epochs 2 \--per_device_train_batch_size 2 \--dataloader_drop_last True \--warmup_ratio 0.1 \--gradient_checkpointing \--deepspeed /mnt/workspace/ds_stage0.json \--logging_steps 1 \--save_steps 1000 \--negatives_cross_device \--temperature 0.02 \--sentence_pooling_method cls \--normalize_embeddings True \--kd_loss_type kl_div \--report_to none参数说明
以下是针对模型微调参数的 中文详细说明,按功能模块分类整理:
一、模型相关参数
参数名称 类型 说明 默认值/选项 model_name_or_path str 预训练模型的路径或HuggingFace Hub名称,用于初始化微调 必填 config_name str 预训练配置文件的路径(若与模型名不一致时指定) 同模型名 tokenizer_name str 预训练分词器的路径(若与模型名不一致时指定) 同模型名 cache_dir str 预训练模型/分词器的缓存目录(避免重复下载) ~/.cache trust_remote_code bool 是否信任远程代码(用于加载自定义模型) False token str 访问私有模型的HuggingFace认证token None
二、数据相关参数
参数名称 类型 说明 默认值/选项 train_data List[str] 训练数据路径(支持多个文件),需包含字段: query(str),pos(List[str]),neg(List[str])必填 cache_path str 预处理后数据的缓存路径 ./cache train_group_size int 每组训练样本包含的正负例数量(如每组1正例+7负例) 8 query_max_len int 查询文本的最大token长度(超长截断) 512 passage_max_len int 正/负文本的最大token长度 512 pad_to_multiple_of int 将序列填充至该值的整数倍(优化GPU显存) 8 max_example_num_per_dataset int 单个数据集的最大样本数(防止内存溢出) 1e8 query_instruction_for_retrieval str 查询指令模板(如 "Represent this query: ")"" query_instruction_format str 查询指令格式化方式(如 "{instruction}{query}")"{}{}" knowledge_distillation bool 是否启用知识蒸馏(需数据包含 pos_scores和neg_scores)False passage_instruction_for_retrieval str 文档指令模板(如 "Represent this document: ")None passage_instruction_format str 文档指令格式化方式 "{}{}" shuffle_ratio float 训练时文本的随机打乱比例(增强鲁棒性) 0.0 same_dataset_within_batch bool 是否限制同一批数据来自同一数据集 False small_threshold int 小数据集合并阈值(低于此值的目录内数据集合并) 0 drop_threshold int 合并后小数据集的丢弃阈值(低于此值丢弃) 0
三、训练优化参数
参数名称 类型 说明 默认值/选项 negatives_cross_device bool 是否跨设备共享负例(分布式训练时节省显存) False temperature float 相似度计算时的温度参数(缩放logits) 0.02 fix_position_embedding bool 是否冻结位置编码参数(减少可训练参数量) False sentence_pooling_method str 句子向量的池化方法: cls/mean/last_tokencls normalize_embeddings bool 是否对输出向量做L2归一化(影响相似度计算) True sub_batch_size int 子批次大小(用于梯度累积中的内存优化) None kd_loss_type str 知识蒸馏的损失函数类型: kl_div/m3_kd_losskl_div
以下是针对模型微调参数的 中文详细说明,按功能模块分类整理:
一、模型相关参数
参数名称 类型 说明 默认值/选项 model_name_or_path str 预训练模型的路径或HuggingFace Hub名称,用于初始化微调 必填 config_name str 预训练配置文件的路径(若与模型名不一致时指定) 同模型名 tokenizer_name str 预训练分词器的路径(若与模型名不一致时指定) 同模型名 cache_dir str 预训练模型/分词器的缓存目录(避免重复下载) ~/.cache trust_remote_code bool 是否信任远程代码(用于加载自定义模型) False token str 访问私有模型的HuggingFace认证token None
二、数据相关参数
参数名称 类型 说明 默认值/选项 train_data List[str] 训练数据路径(支持多个文件),需包含字段: query(str),pos(List[str]),neg(List[str])必填 cache_path str 预处理后数据的缓存路径 ./cache train_group_size int 每组训练样本包含的正负例数量(如每组1正例+7负例) 8 query_max_len int 查询文本的最大token长度(超长截断) 512 passage_max_len int 正/负文本的最大token长度 512 pad_to_multiple_of int 将序列填充至该值的整数倍(优化GPU显存) 8 max_example_num_per_dataset int 单个数据集的最大样本数(防止内存溢出) 1e8 query_instruction_for_retrieval str 查询指令模板(如 "Represent this query: ")"" query_instruction_format str 查询指令格式化方式(如 "{instruction}{query}")"{}{}" knowledge_distillation bool 是否启用知识蒸馏(需数据包含 pos_scores和neg_scores)False passage_instruction_for_retrieval str 文档指令模板(如 "Represent this document: ")None passage_instruction_format str 文档指令格式化方式 "{}{}" shuffle_ratio float 训练时文本的随机打乱比例(增强鲁棒性) 0.0 same_dataset_within_batch bool 是否限制同一批数据来自同一数据集 False small_threshold int 小数据集合并阈值(低于此值的目录内数据集合并) 0 drop_threshold int 合并后小数据集的丢弃阈值(低于此值丢弃) 0
三、训练优化参数
参数名称 类型 说明 默认值/选项 negatives_cross_device bool 是否跨设备共享负例(分布式训练时节省显存) False temperature float 相似度计算时的温度参数(缩放logits) 0.02 fix_position_embedding bool 是否冻结位置编码参数(减少可训练参数量) False sentence_pooling_method str 句子向量的池化方法: cls/mean/last_tokencls normalize_embeddings bool 是否对输出向量做L2归一化(影响相似度计算) True sub_batch_size int 子批次大小(用于梯度累积中的内存优化) None kd_loss_type str 知识蒸馏的损失函数类型: kl_div/m3_kd_losskl_div
四、关键参数使用示例
1. 指令模板配置
# 查询指令:"为以下问题生成检索向量: [问题]" query_instruction_for_retrieval = "为以下问题生成检索向量: " query_instruction_format = "{}{}" # 文档指令:"相关文档内容: [文本]" passage_instruction_for_retrieval = "相关文档内容: " passage_instruction_format = "{}{}"2. 训练组配置
train_group_size = 8 # 每组包含1正例 + 7负例 query_max_len = 256 # 短查询场景优化 passage_max_len = 384 # 长文档场景优化3. 知识蒸馏启用
knowledge_distillation = True # 需数据包含pos_scores和neg_scores kd_loss_type = "m3_kd_loss" # 使用多任务蒸馏损失
五、注意事项
- 数据格式验证:确保训练数据包含必需的
query、pos、neg字段,且pos/neg为列表格式。- 硬件适配:根据GPU显存调整
query_max_len和passage_max_len,避免OOM错误。- 指令冲突:若模型本身已内置指令(如BGE),建议通过实验选择是否叠加外部指令。
- 池化方法选择:
cls:适用于BERT系列模型mean:更适合无[CLS] token的模型(如GPT)last_token:常用于因果语言模型
3)评估
1)from datasets import load_datasetqueries = load_dataset("json", data_files="ft_data/test_queries.jsonl")["train"]
corpus = load_dataset("json", data_files="ft_data/corpus.jsonl")["train"]
qrels = load_dataset("json", data_files="ft_data/test_qrels.jsonl")["train"]queries_text = queries["text"]
corpus_text = [text for sub in corpus["text"] for text in sub]qrels_dict = {}
for line in qrels:if line['qid'] not in qrels_dict:qrels_dict[line['qid']] = {}qrels_dict[line['qid']][line['docid']] = line['relevance']数据加载:读取查询、语料和相关标注
结构转换:将标注数据转换为快速查询的字典格式
字段提取:获取纯文本列表用于模型输入2) 一个 基于稠密向量检索的标准流程,核心价值在于:高效检索:利用Faiss优化相似度计算
灵活扩展:通过替换索引类型适配不同规模数据
评估友好:结果格式兼容信息检索评估协议import faiss
import numpy as np
from tqdm import tqdmdef search(model, queries_text, corpus_text):queries_embeddings = model.encode_queries(queries_text)corpus_embeddings = model.encode_corpus(corpus_text)# create and store the embeddings in a Faiss indexdim = corpus_embeddings.shape[-1]index = faiss.index_factory(dim, 'Flat', faiss.METRIC_INNER_PRODUCT)corpus_embeddings = corpus_embeddings.astype(np.float32)index.train(corpus_embeddings)index.add(corpus_embeddings)query_size = len(queries_embeddings)all_scores = []all_indices = []# search top 100 answers for all the queriesfor i in tqdm(range(0, query_size, 32), desc="Searching"):j = min(i + 32, query_size)query_embedding = queries_embeddings[i: j]score, indice = index.search(query_embedding.astype(np.float32), k=100)all_scores.append(score)all_indices.append(indice)all_scores = np.concatenate(all_scores, axis=0)all_indices = np.concatenate(all_indices, axis=0)# store the results into the format for evaluationresults = {}for idx, (scores, indices) in enumerate(zip(all_scores, all_indices)):results[queries["id"][idx]] = {}for score, index in zip(scores, indices):if index != -1:results[queries["id"][idx]][corpus["id"][index]] = float(score)return results3)对嵌入模型(原始版与微调版)进行检索性能评估from FlagEmbedding.abc.evaluation.utils import evaluate_metrics, evaluate_mrr
from FlagEmbedding import FlagModelk_values = [10,100]raw_name = "BAAI/bge-large-en-v1.5"
finetuned_path = "test_encoder_only_base_bge-large-en-v1.5"
4)评估原始模型在 Top-k 的精度(如nDCG@10、Recall@100)和 MRR
raw_model = FlagModel(raw_name, query_instruction_for_retrieval="Represent this sentence for searching relevant passages:",devices=[0],use_fp16=False
)results = search(raw_model, queries_text, corpus_text)eval_res = evaluate_metrics(qrels_dict, results, k_values)
mrr = evaluate_mrr(qrels_dict, results, k_values)for res in eval_res:print(res)
print(mrr)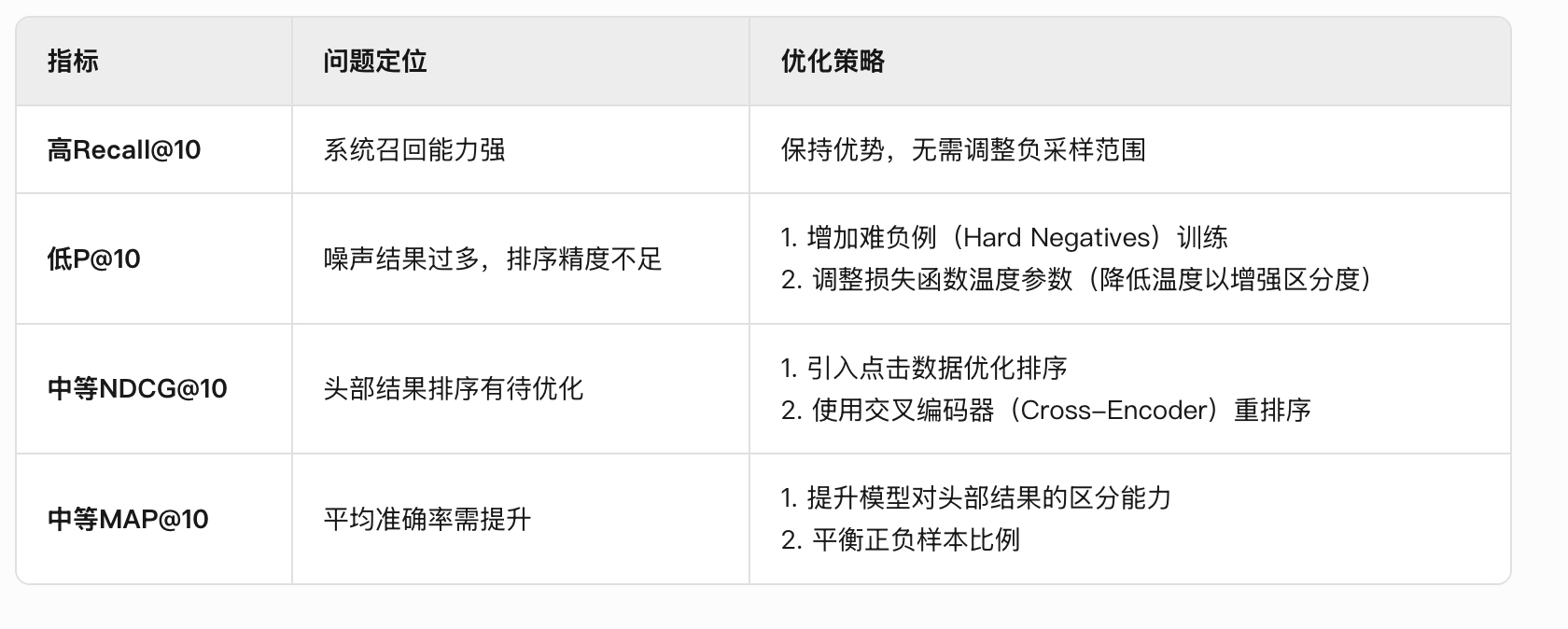
5)对 微调后的嵌入模型(Fine-tuned Model) 进行检索性能评估,评估模型在 Top-k 检索中的精度和 MRR(平均倒数排名)
ft_model = FlagModel(finetuned_path, query_instruction_for_retrieval="Represent this sentence for searching relevant passages:",devices=[0],use_fp16=False
)results = search(ft_model, queries_text, corpus_text)eval_res = evaluate_metrics(qrels_dict, results, k_values)
mrr = evaluate_mrr(qrels_dict, results, k_values)for res in eval_res:print(res)
print(mrr)