Python的文本操作和try语句使用
目录
一. 文本操作
1. 打开文件的模式
(1) 示例:打开文件并使用模式
2. 读取文件
(1) read()方法
(2) readline()方法
(3) readlines()方法
3. 写入文件
(1) 使用write()方法写入文件a
(2) 使用wirtelines()方法写入多行数据
二. 错误处理与异常捕获
1:try 语句的使用
2:示例:捕获常见异常
一. 文本操作
文件操作是 Python编程中常见的任务。Python提供了多种方法来读取、写入和管理文件,能够处理文本文件、二进制文件以及目录操作等。拿握文件操作的基础和技巧是高效编程的关键。
1. 打开文件的模式
Python使用内置的 open()函数来打开文件。打开文件时,我们需要指定文件模式(即操作文件的方式)。
常见的文件打开模式:
- r:只读模式(默认模式)。文件必须存在。如果文件不存在,会抛出FileNotFoundError 异常。
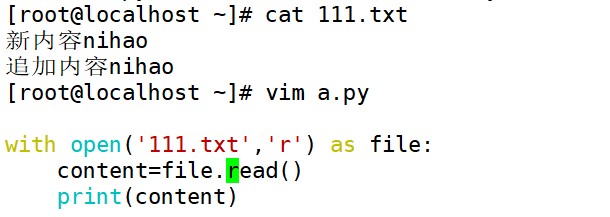
- w:写入模式。如果文件存在,会覆盖文件内容。如果文件不存在,会创建新文件。
- a:追加模式。如果文件存在,写入的数据会追加到文件末尾;如果文件不存在,会创建新文件。
- x:独占创建模式。若文件已存在,操作会失败并抛出 FileExistsError 异常。此模式通常用于创建文件时防止覆盖现有文件。
- rb:二进制读职模式,用于读取非文本文件(如图片、音频文件)。
- wb:二进制写入模式,用于写入非文本文件。
- r+:读写模式。文件必须存在。既可以读取文件内容,也可以写入数据,
- w+:读写模式。如果文件存在,会覆盖文件内容;如果文件不存在,会创建新文件。
- a+:读写模式。文件存在时,数据会追加到文件末尾;如果文件不存在,会创建新文件。
- rb+:二进制读写模式。
(1) 示例:打开文件并使用模式
创建要打开的文件

以只读模式打开文件 要打开的文件必须存在
以写入模式打开文件,文件内容会被覆盖


以追加模式打开文件,新的内容会追加到文件末尾


以二进制模式打开文件(如读取图片)



2. 读取文件
Python中的文件读取功能非常强大
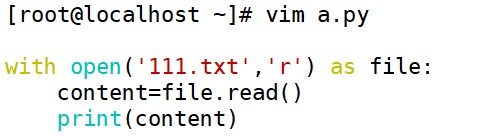
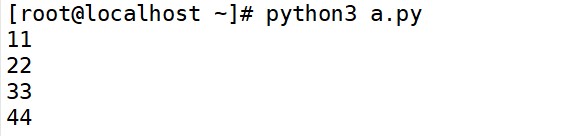
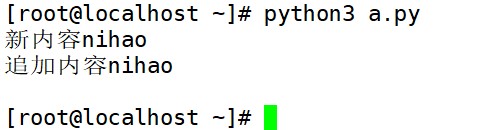
(1) read()方法
read()方法用于读取文件中的所有内容。读取后会作为字符串返回
(2) readline()方法
readline()方法每次读取一行文件内容,适用于需要逐行处理文件的情况
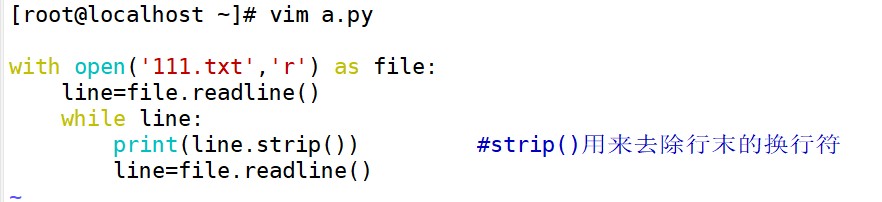
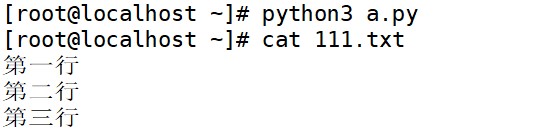
(3) readlines()方法
readlines()方法会一次性读取文件中所有的行,并将每行数据存储为一个列表的元素,适用于需要读取整个文件并进行处理的情况

3. 写入文件
Python提供了几种方法将数据写入文件。写入操作常用于日志记录、数据导出等场景
(1) 使用write()方法写入文件a
write()方法将指定的字符串写入文件。若将以w模式打开,原文件内容会被覆盖;若以a模式打开内容会别追加到文件末尾


(2) 使用wirtelines()方法写入多行数据
wirtelines()方法接受一个可迭代对象(如列表、元组等),将其元素写入文件中,每个元素将作为一行写入文件

二. 错误处理与异常捕获
在进行 Web 请求时,可能会发生各种错误,例如网络超时、服务器错误等。requests 库通过异常处理机制帮助我们捕获这些错误。Python 的 try语句能够捕获和处理代码块中的异常,从而避免程序崩溃,并且提供了处理错误的机会。
1:try 语句的使用
try语句用于捕获和处理异常,它由三部分组成:
try块:包含可能会引发异常的代码。当代码运行过程中发生错误时,程序会跳到相应的 except
块进行处理。
except块:当 try块中的代码出现异常时,程序会跳转到 except块执行。在 except 中可以指定要捕获的异常类型,如Timeout、HTTPError等。else 块 (可选):如果try块中的代码没有抛出异常,则会执行 else块中的代码.
finally块(可选):无论是否发生异常,finally 块中的代码都会执行,通常用于清理资源(如关闭文件、数据库连接等)
2:示例:捕获常见异常
import requests
from requests.exceptions import RequestException, Timeout, HTTPError
try:#发送 GET请求,并设置超时时间为5秒response =requests.get('https://www.example.com',timeout-5)#如果状态码不是 200,抛出 HTTPError 异常response.raise_for_status() # 如果状态码是 404或 500,抛出异常#如果请求成功,则输出响应内容print('Response Body:",response.text)# 捕获请求超时异常
except Timeout:print('Request timed out')# 捕获 HTTP 错误(如状态码 404、500等)
except HTTPError as http err:print(f'HTTP error occurred: {http_err}')# 捕获其他网络相关的错误
except RequestException as reg err:print(f'Request error occurred:{reg_err}')# 可以在 finally 块中清理资源(如关闭文件或连接)
finally :print('Request attempt completed.")代码解释:
1.try块:首先发起 HTTP请求,设置超时时间为5秒,并使用response.raise for status()来检查响应的状态码。如果服务器返回了错误的状态码(如 404、500),raise for status(0)会抛出HTTPError 异常。
2. except块:
- Timeout: 如果请求超时(超过设置的5秒),程序会捕获到 Timeout 异常,并打印“Request
- timed out"
- HTTPError:如果响应的状态码表明出现 HTTP 错误(例如 404 表示未找到页面),程序会捕获到 HTTPError 异常,并打印相关错误信息。
- RequestException:捕获其他类型的网络相关错误(如连接问题、DNS 解析失败等)RequestException 是所有 requests 库异常的基类,可以捕获任何requests 库抛出的异常
3. finally 块: finally 中的代码无论是否发生异常都会被执行,通常用于释放资源或做一些收尾工作。这里我们仅打印“Request attempt completed.”表示请求的结束。
异常处理总结:
- 异常处理让我们在程序运行中捕获到错误并做出相应处理,避免程序崩溃。
- 通过 try...except结构,可以精确捕获并处理不同类型的异常
- finally 块用于清理工作,在请求处理完成后可以释放资源(如关闭文件、数据库连接等)