PARSCALE:大语言模型的第三种扩展范式

----->更多内容,请移步“鲁班秘笈”!!<-----
随着人工智能技术的飞速发展,大语言模型(LLM)已成为推动机器智能向通用人工智能(AGI)迈进的核心驱动力。然而,传统的模型扩展方法正面临着前所未有的挑战:参数扩展需要巨大的存储空间,推理时扩展则带来显著的时间成本。在这一背景下,最近有研究团队提出了一种全新的扩展范式——PARSCALE(并行扩展),为大语言模型的发展开辟了第三条道路。
在深入了解PARSCALE之前,当前主流扩展方法所面临的挑战。传统的参数扩展方法主要有两种:
-
Dense Scaling(密集扩展)**是最直接的扩展方式,通过同比例增加模型各层的参数来扩大模型规模。具体来说,就是增加隐藏层维度、注意力头数量、层数等,让模型的每一部分都变得更大更复杂。这种方法的特点是所有参数在推理时都会被激活和使用,因此称为"密集"扩展。例如,从GPT-3的1750亿参数扩展到PaLM的5400亿参数,就是典型的密集扩展。
-
混合专家模型MoE 则采用了"稀疏激活"的思路,虽然模型总参数很大,但每次推理只激活其中一部分专家模块,从而在保持高性能的同时控制计算成本。
无论是密集扩展还是MoE,都需要大幅增加模型参数数量来提升性能。例如,DeepSeek-V3模型拥有高达672B参数,这种规模的模型对边缘设备部署提出了几乎无法满足的内存需求。密集扩展的问题尤为突出:模型越大,所需的存储空间和计算资源就越多,部署成本也呈指数级增长。
另一种方法是推理时扩展,通过生成更多推理token来增强模型的推理能力。虽然这种方法在某些场景下有效,但它需要专门的训练数据,且通常会带来显著的时间成本。

PARSCALE
PARSCALE的核心思想来源于扩散模型中广泛使用的无分类器引导(Classifier-Free Guidance,CFG)技术。要理解PARSCALE的创新之处,我们首先需要深入了解CFG的工作原理。
CFG最初在图像生成的扩散模型(如DALL-E、Stable Diffusion)中获得巨大成功,其基本思想是通过对比"好"和"坏"的预测来提升模型性能。
传统单次推理方法:
-
输入:一个条件提示(比如"画一只在草地上的橙色猫")
-
处理:模型进行一次前向传播
-
输出:直接生成结果
CFG的双重推理方法:
-
第一次推理(有条件):使用完整的提示"画一只在草地上的橙色猫"进行前向传播,得到输出A
-
第二次推理(无条件或降级条件):移除或削弱条件信息,比如只用"画一只猫"或完全无条件生成,得到输出B
-
智能聚合:最终输出 = 输出A + w × (输出A - 输出B)
这里w是一个权重参数。数学上表示为:最终输出 = 有条件输出 + w × (有条件输出 - 无条件输出)
CFG的有效性在于它创造了一种"对比学习"机制:有条件输出代表模型对具体要求的理解。无条件输出代表模型的"基础倾向"。两者的差值突出了条件信息的关键影响放大这个差值。
研究团队从CFG的成功中得到了关键启发:CFG之所以有效,核心不在于条件与无条件的对比,而在于使用了双重计算。也就是说,模型进行了两次独立的思考过程,然后聚合结果。
基于这一观察,他们提出了革命性的假设:如果双重计算能带来性能提升,那么更多的并行计算是否能带来更大的提升?
PARSCALE将CFG的思想进行了重大扩展。CFG是两个固定的变换(有条件 vs 无条件) + 固定的聚合规则。PARSCALE则是P个可学习的变换 + 可学习的动态聚合。
这就像是从"两个人讨论得出更好答案"扩展到"多个专家团队协作得出最优方案"。每个并行流都可以从不同角度思考同一个问题,最终通过智能聚合产生比单一思路更优秀的结果。
PARSCALE将这一思想扩展到更一般的形式:给输入添加P个不同的可学习前缀,将它们并行输入到模型中,然后使用动态加权和将P个输出聚合成单一输出。这种方法通过重复使用现有参数来高效地扩展并行计算,适用于各种训练算法、数据和任务。
在具体实现上,PARSCALE采用了经过精心设计的技术方案。对于输入变换,研究团队使用前缀调优(prefix tuning)作为输入变换方法,这等价于使用不同的KV缓存来区分不同的流。对于输出聚合,他们采用动态加权平均方法,利用多层感知机将多个流的输出转换为聚合权重。
这种设计的巧妙之处在于,每个流只增加约0.2%的额外参数,相比完整的参数扩展,这是一个微不足道的增加。同时,该方法充分利用了GPU友好的并行计算,将LLM解码中的内存瓶颈转移为计算瓶颈,因此不会显著增加延迟。

新的扩展定律
PARSCALE不仅在实践中表现出色,研究团队还为其提供了坚实的理论基础。他们基于著名的Chinchilla扩展定律,推导出了新的并行扩展定律。
传统的Chinchilla扩展定律表明,语言模型的交叉熵损失与参数数量N存在幂律关系:L = A/N^α + E,其中A、E、α是正常数,E是自然文本的熵。
在PARSCALE框架下,研究团队推导出新的扩展定律:
L = A/(N · P^(1/α) · DIVERSITY^α) + E,
其中DIVERSITY定义为多个流之间预测相关性的函数。这一理论结果表明,扩展P倍的并行计算等价于将模型参数扩展O(log P)倍。
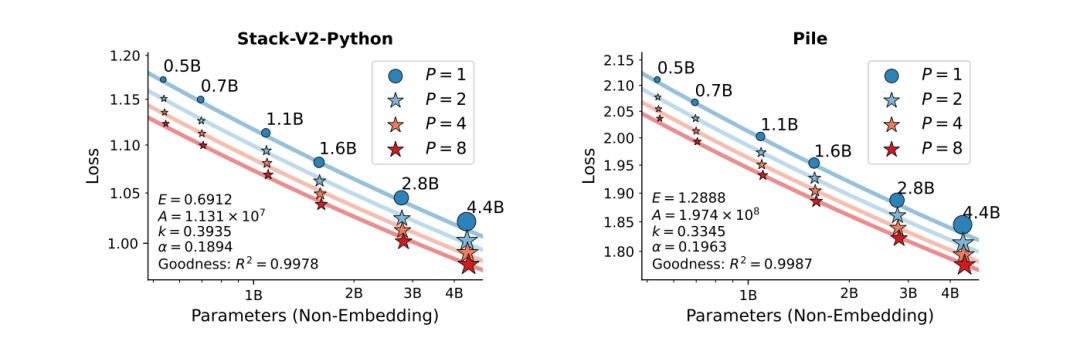
通过大规模预训练实验验证,研究团队在Stack-V2和Pile数据集上训练了参数规模从0.5B到4.4B、并行流数从1到8的多个模型。实验结果高度符合理论预测,拟合优度R²高达0.998,验证了并行扩展定律的有效性。
实验结果充分证明了PARSCALE的优越性。在代码生成任务上,使用Stack-V2-Python数据集训练的模型表现尤为突出。1.6B参数的模型在P=8时,其代码能力与4.4B参数的传统模型相当,而在通用任务上则相当于2.8B参数的模型。
这一发现揭示了一个重要规律:模型参数主要影响记忆能力,而计算主要影响推理能力。由于Stack-V2强调编码和推理能力,而Pile强调记忆能力,PARSCALE在推理密集型任务上显示出更大的优势。
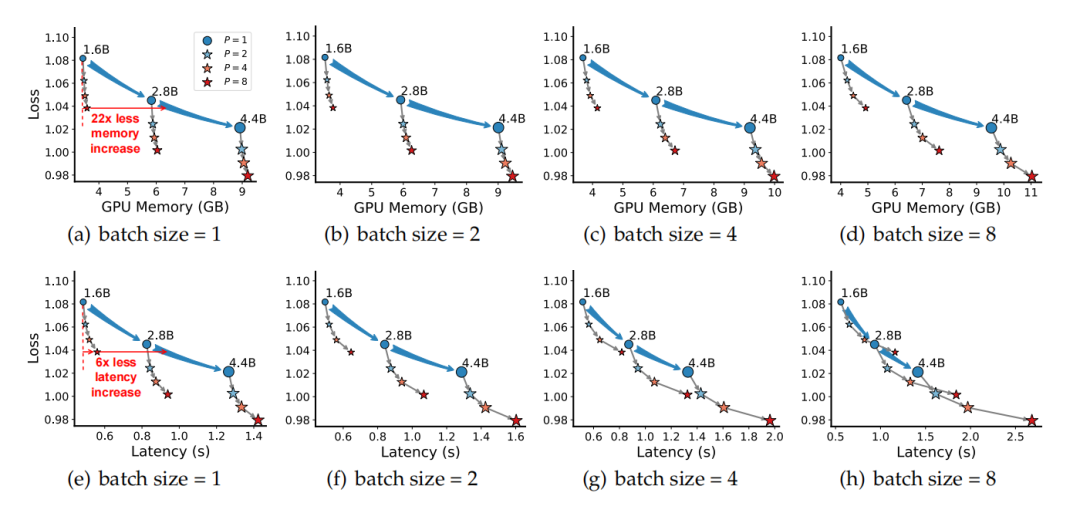
在推理成本分析中,PARSCALE展现出显著的效率优势。对于16亿参数的模型,当扩展到P=8时,相比达到相同性能的参数扩展方法,PARSCALE的内存增加减少了22倍,延迟增加减少了6倍。这种优势在批处理大小较小的场景下尤为明显,使得PARSCALE特别适合智能手机、智能汽车和机器人等资源受限的边缘设备。

生产级别验证
为了验证PARSCALE在生产级别训练中的有效性,研究团队训练了一个18亿参数的模型,使用1万亿token的训练数据。他们采用了两阶段训练策略:第一阶段使用传统训练方法处理大部分训练数据,第二阶段仅在少量token上应用PARSCALE。
虽然PARSCALE在推理阶段非常高效,但它仍然会引入约P倍的浮点运算,在计算密集的训练过程中会显著增加开销。为了解决这一限制,研究团队提出了两阶段策略:
第一阶段:使用传统预训练方法处理1万亿token
第二阶段:进行PARSCALE训练,仅使用200亿token
由于第二阶段仅占第一阶段的2%,这种策略可以大大降低训练成本。这种两阶段策略类似于长上下文微调,同样将更消耗资源的阶段放在最后。
研究团队遵循Allal等人的建议,使用了Warmup Stable Decay (WSD)学习率调度策略:
-
第一阶段:采用2K步预热,然后使用3e-4的固定学习率
-
第二阶段:学习率从3e-4退火到1e-5
在第一阶段,他们构建了包含3700亿通用数据、800亿数学数据和500亿代码数据的训练集。
具体组成包括:
-
通用文本:3450亿来自FineWeb-Edu,280亿来自Cosmopedia 2
-
数学数据:800亿来自FineMath
-
代码数据:470亿来自Stack-V2-Python,40亿来自Stack-Python-Edu
在第二阶段,他们增加了数学和代码数据的比例,最终包含:
-
70亿通用文本数据
-
70亿数学数据
-
70亿Stack-Python-Edu数据
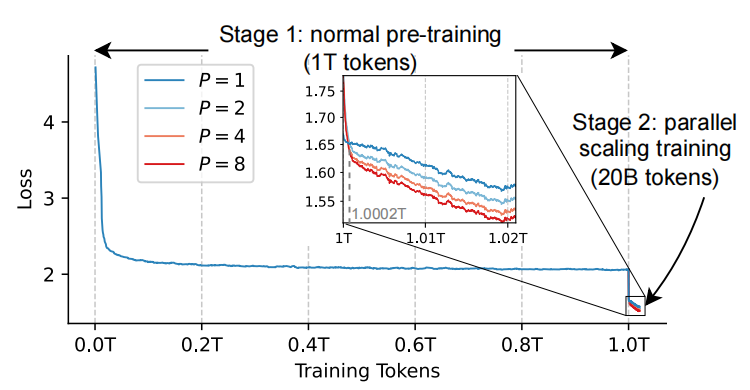
训练损失曲线直观地展示了两阶段训练的效果。在第二阶段开始时,由于引入了随机初始化的参数,P > 1的损失最初会超过P = 1的情况。然而,在处理少量数据(0.0002万亿token)后,模型迅速适应了这些新引入的参数并保持稳定。这证明了PARSCALE只需要很少的数据就能快速生效。
在后期阶段,PARSCALE产生了类似的对数增益,这与之前的扩展定律发现一致,表明早期从头预训练的结论——P个流的并行等价于O(N log(P))倍参数增加——同样适用于持续预训练。此外,较大的P值(如P = 8)可以逐渐扩大与较小P值(如P = 4)的差距,这表明并行扩展也能从数据扩展中受益。

下游任务
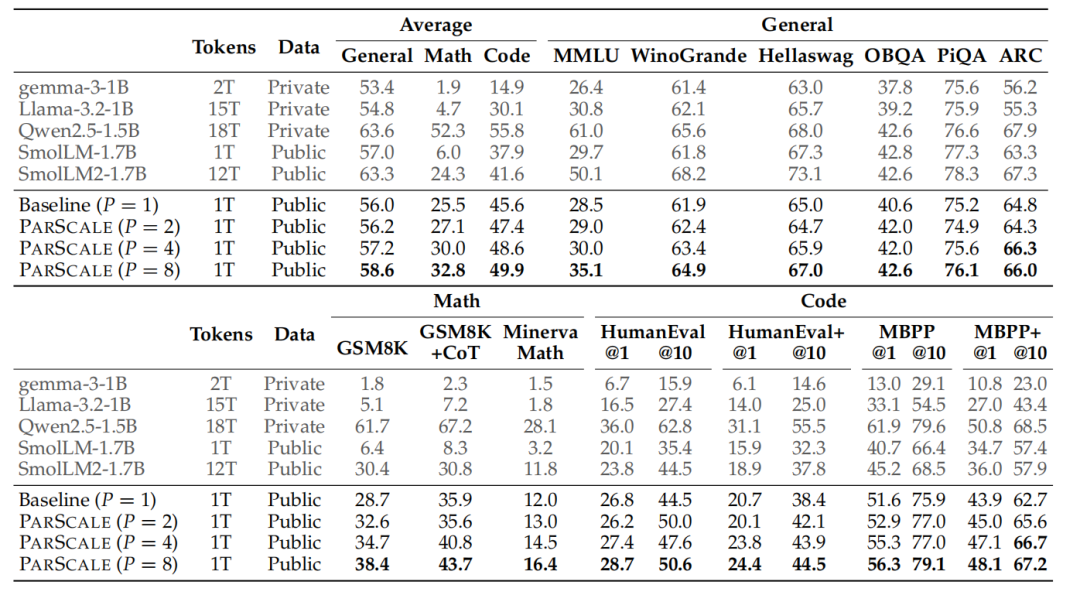
如上图所示,在完成两阶段训练后,研究团队在21个下游基准测试中评估了模型表现,包括7个通用任务、3个数学任务和8个编程任务。结果显示,随着P的增加,大多数基准测试的性能呈上升趋势,验证了在大数据集上训练的PARSCALE的有效性。
研究团队进一步调查了在两种设置下将PARSCALE应用于现成模型的效果:持续预训练和参数高效微调(PEFT)。具体而言,他们使用Pile和Stack-V2 (Python)对Qwen-2.5 (3B)模型进行持续预训练。
-
在Stack-V2 (Python)和Pile上的持续预训练结果显示了训练损失的变化。值得注意的是,Qwen2.5已经在18万亿数据上进行了预训练,这些数据可能与Pile和Stack-V2有显著重叠。这表明即使使用经过充分训练的基础模型和常用的训练数据集,仍然可以实现改进。
-
研究团队进一步利用PEFT来微调引入的参数,同时冻结主干权重。结果表明,这种策略仍然可以显著改进下游代码生成性能。
-
更重要的是,这展示了动态并行扩展的广阔前景:可以部署相同的主干,并在各种场景中灵活地在不同数量的并行流之间切换(例如,高吞吐量和低吞吐量),这使得能够在不同级别的模型能力之间快速转换。
例如,在计算资源充足时,可以使用较大的P值获得更好的性能;在资源受限时,可以降低P值以减少计算开销。这种动态调整能力使得同一个模型可以适应从高性能服务器到边缘设备的各种部署环境。
模型的能力是由参数决定的,还是由计算决定的?传统的机器学习模型通常同时扩展参数和计算,难以确定它们各自的贡献比例。PARSCALE和相应的并行扩展定律为这一问题提供了新的定量视角。
研究结果表明,大计算能够促进大智能的涌现。这一发现为人工智能的发展指明了新的方向:除了追求更大的模型参数之外,我们还可以通过更高效的计算方式来提升模型能力。

鲁班号导读火热上线!!
------>敬请移步“鲁班秘笈”!<------