vLLM v1源码阅读 : 整体流程梳理(详细debug)
vLLM v1整体流程梳理:offline inference
在阅读了知乎猛猿小姐姐的图解Vllm V1系列1后,为了更好的和实际代码结合,因此debug了vLLM的0.8.4版本的源码,从源码上结合来学习v1的设计会更加深入和具体。
前言:强烈建议先看一下知乎猛猿小姐姐的图解Vllm V1系列1解读,先知道原理再看代码比较好理解!
介绍
这篇blog主要针对vLLM v1的离线推理的模块设计进行源码级别的讲解,我们会从一个入口开始debug,从用户的prompt输入开始,一直到返回模型输出结束。这里会包含大量的源码截图,出于篇幅考虑,本篇blog不会详细介绍每一行代码,只会对模块进行大致的介绍,读者可以根据截图自己对源码进行详细调试。
overview
下图摘自猛猿小姐姐的图解Vllm V1系列1,本篇blog用这张图作为overview,会对vLLM源码debug图中讲解的所有模块,因此读者可以结合猛猿小姐姐的图解Vllm V1系列1一起学习。

debug入口:vllm/examples/offline_inference/basic/basic.py
- step in并跳过装饰器后进入了LLM类的__init__函数中:
- 打断点跳转到LLMEngine的创建入口:
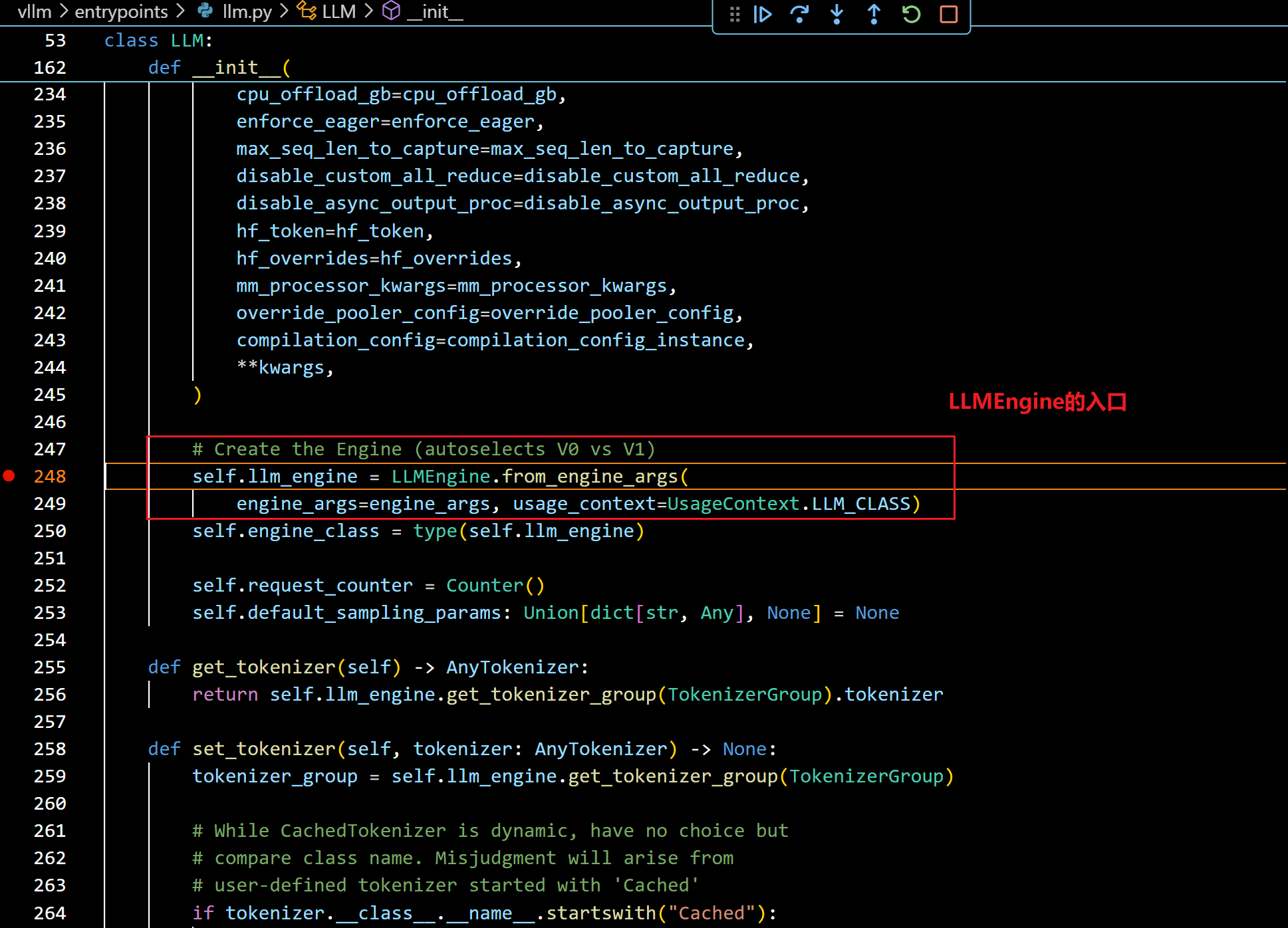
- 进入这个from_engine_args函数后,可以看到:
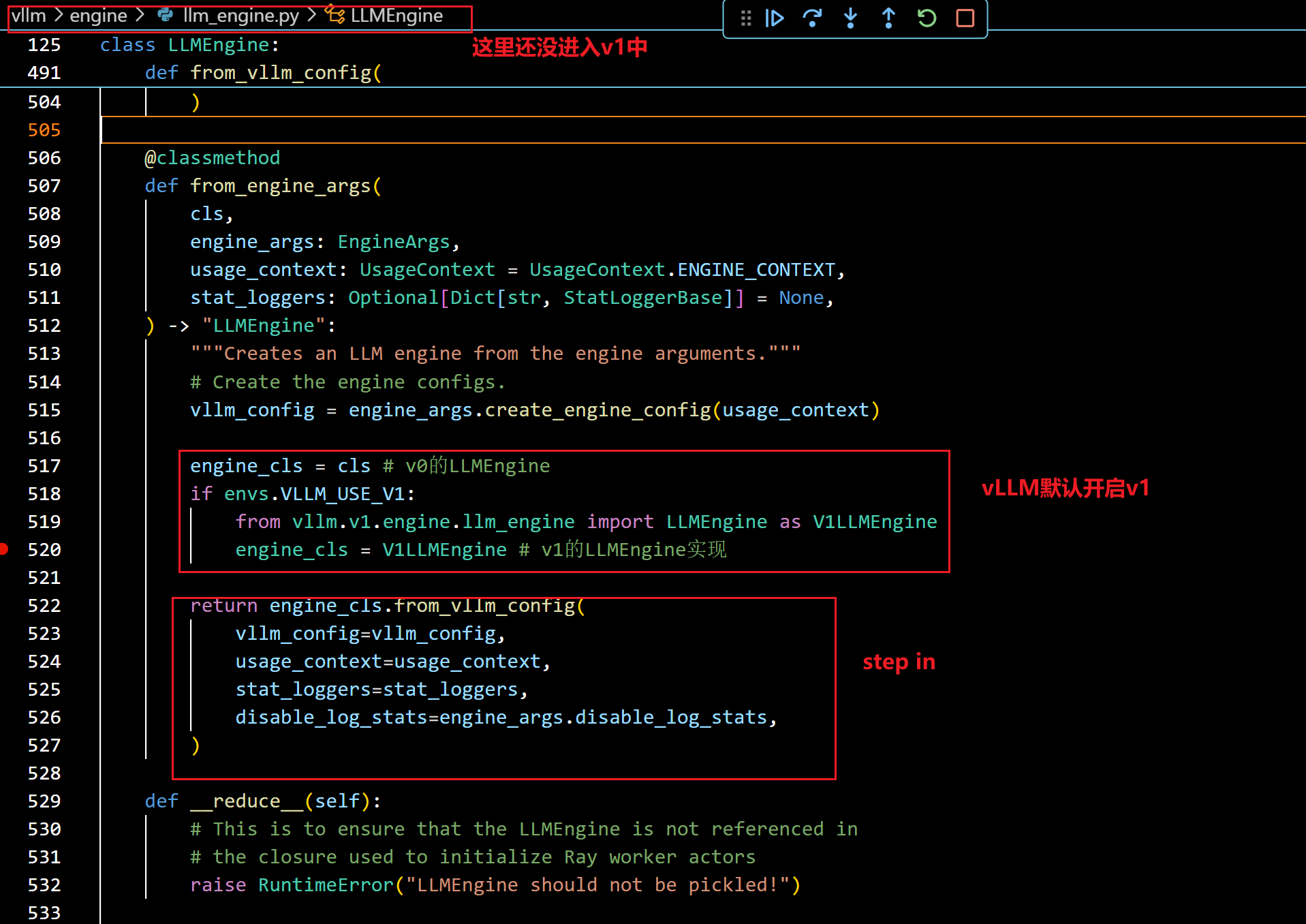
- vLLM默认是启用VLLM_USE_V1环境变量的,因此默认会使用v1的LLMEngine实现
- 我们接着step in(from_vllm_config函数):
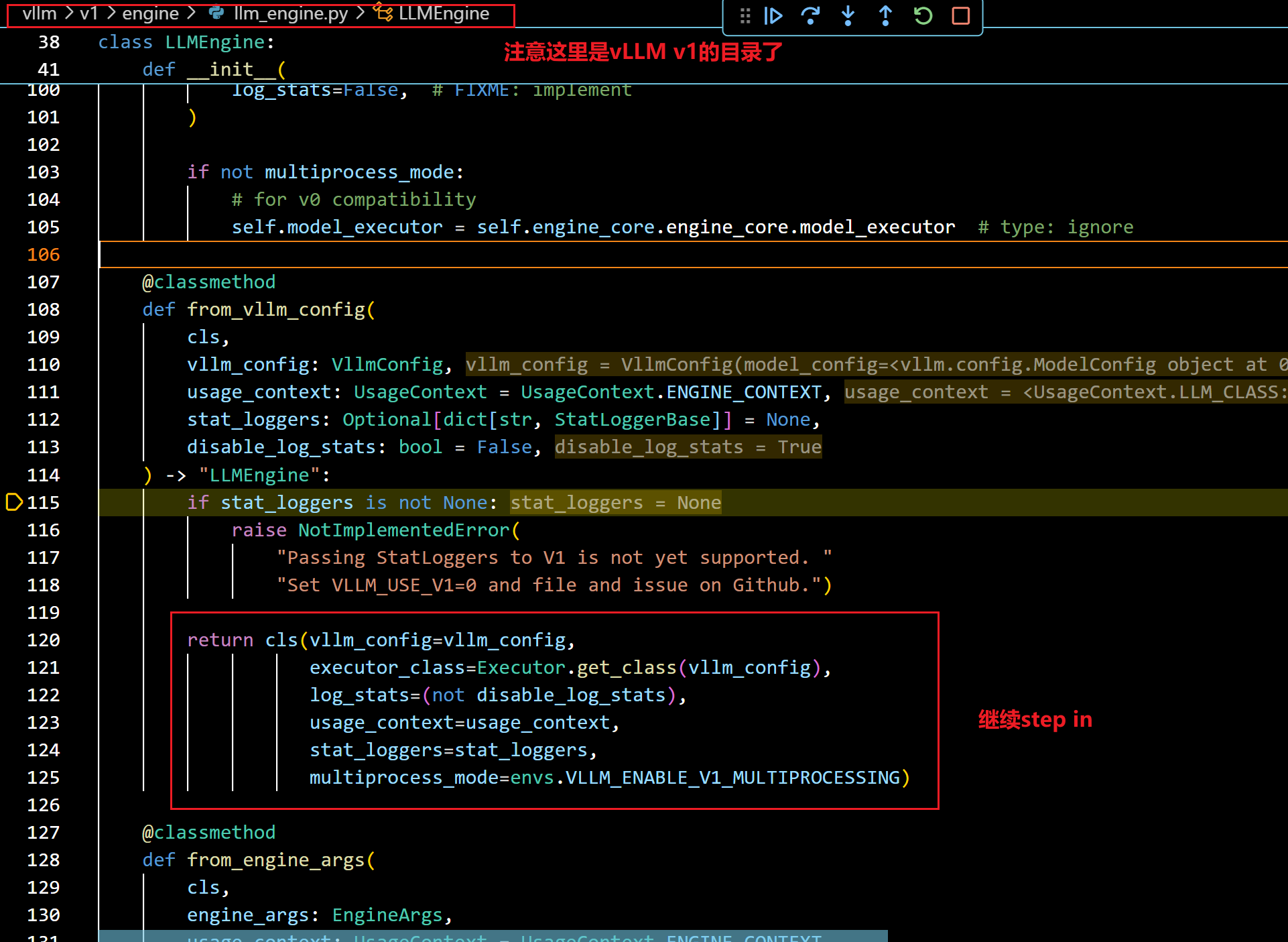
- 按照上图继续step in,就进入了v1 LLMEngine的构造函数中:
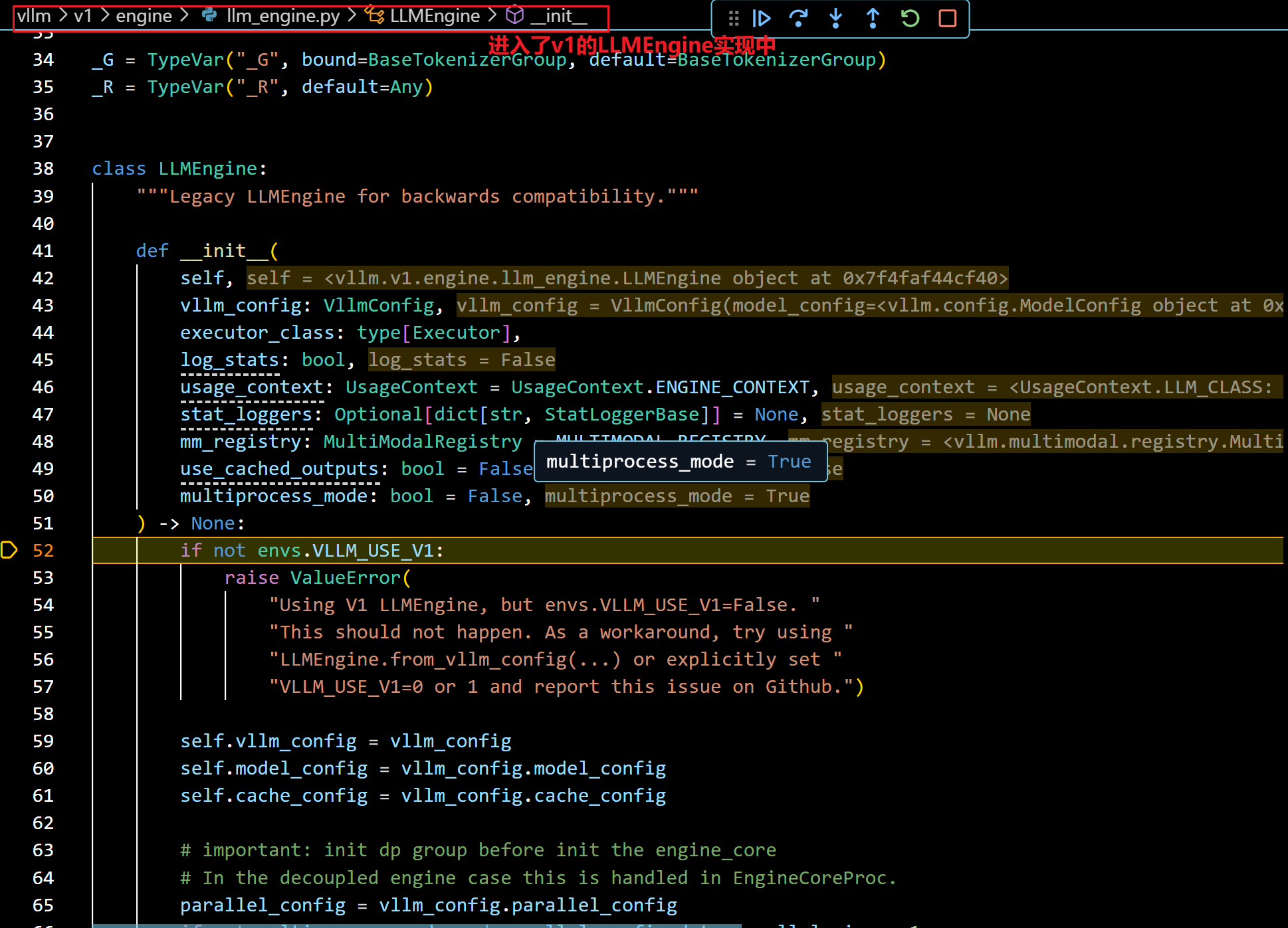
- 接着往下看,会看到:
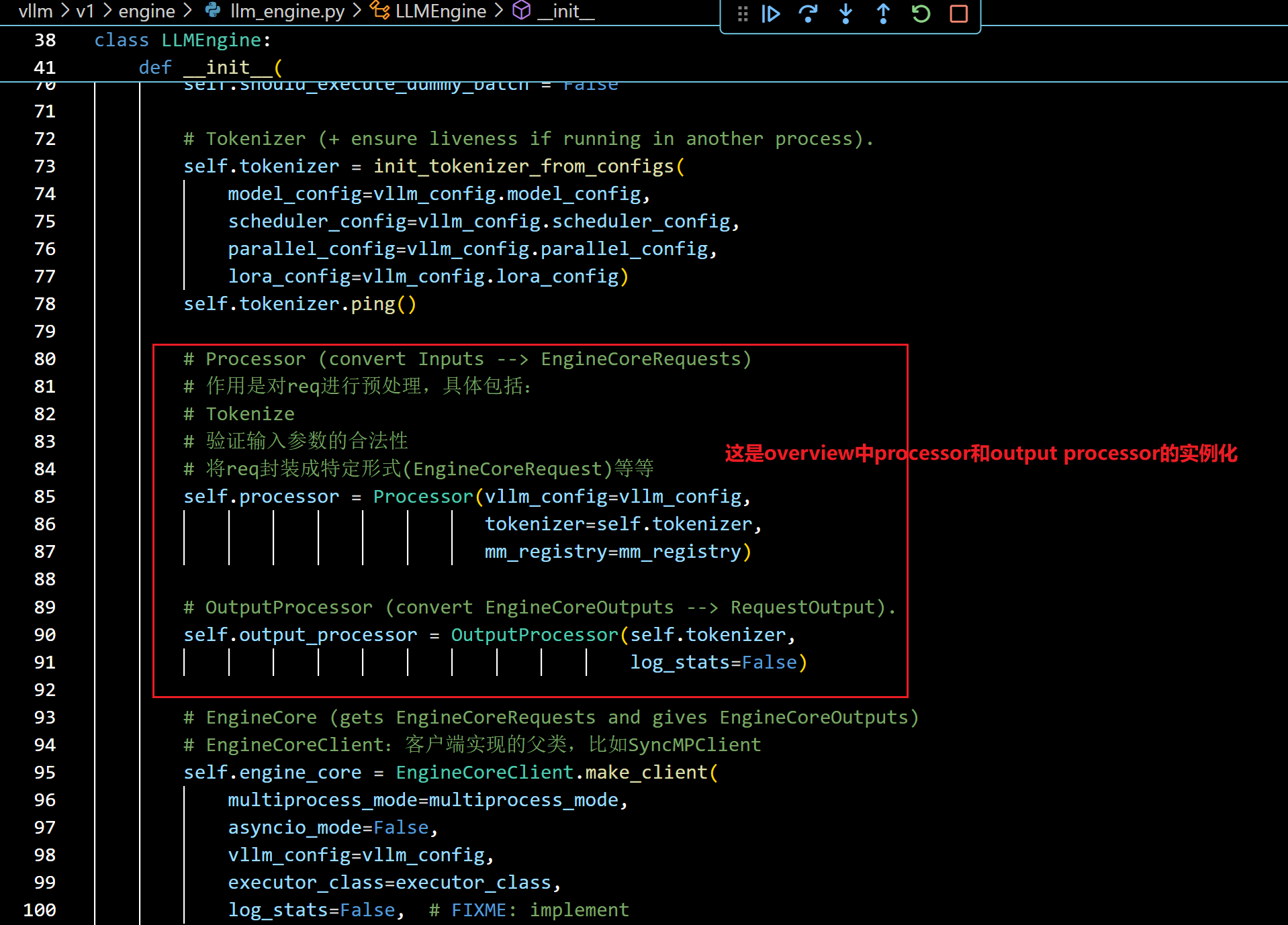
- 继续往下看:
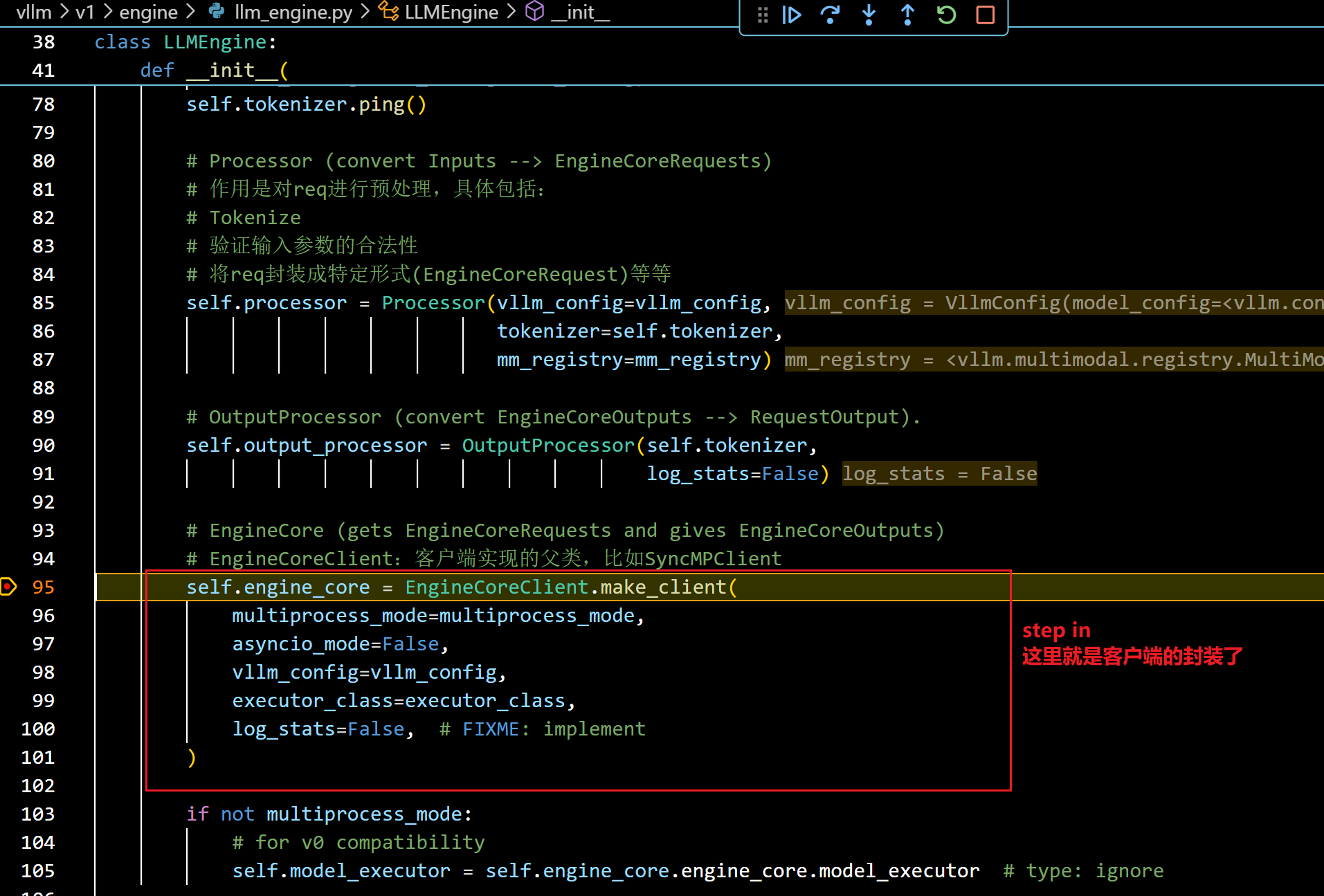
- 看图:
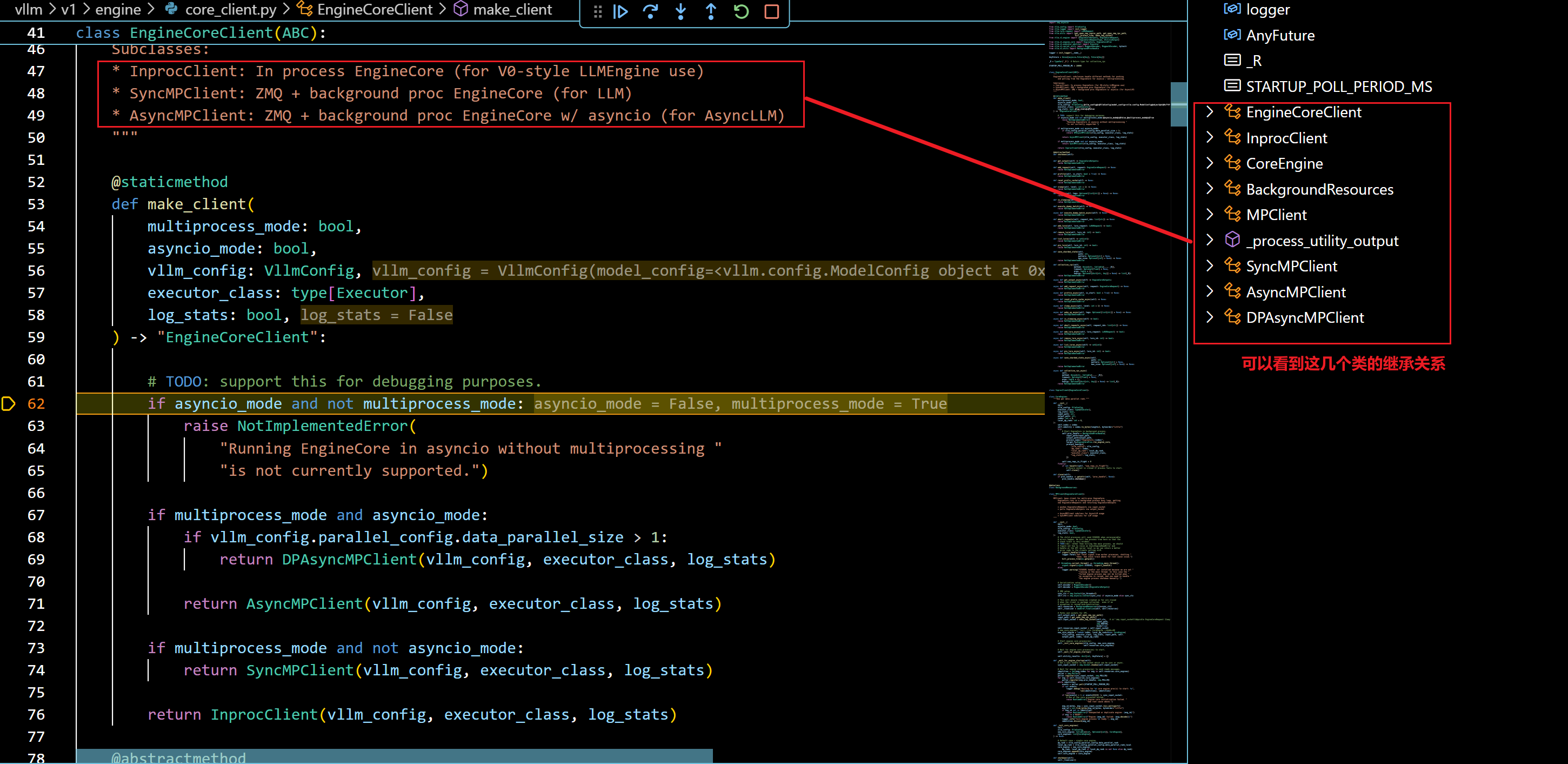
- make_client函数根据是否启用多进程和 asyncio,创建适合的 EngineCoreClient 子类实例:

- 离线推理是同步+多进程,我们从这里继续step in:
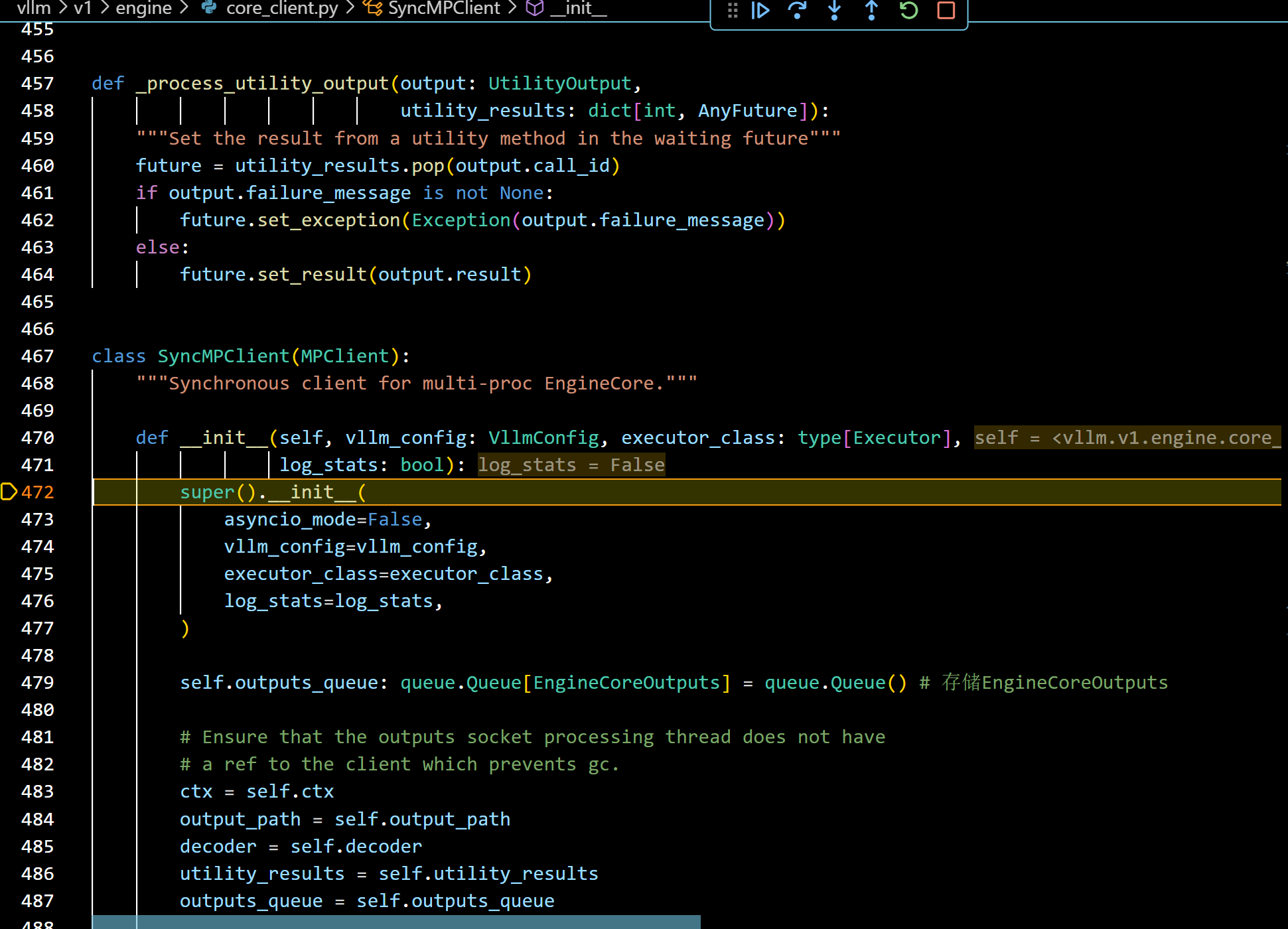
- 这里就到了overview中的SyncMPClient模块中,这里调用super().init(), 我们step in进去:
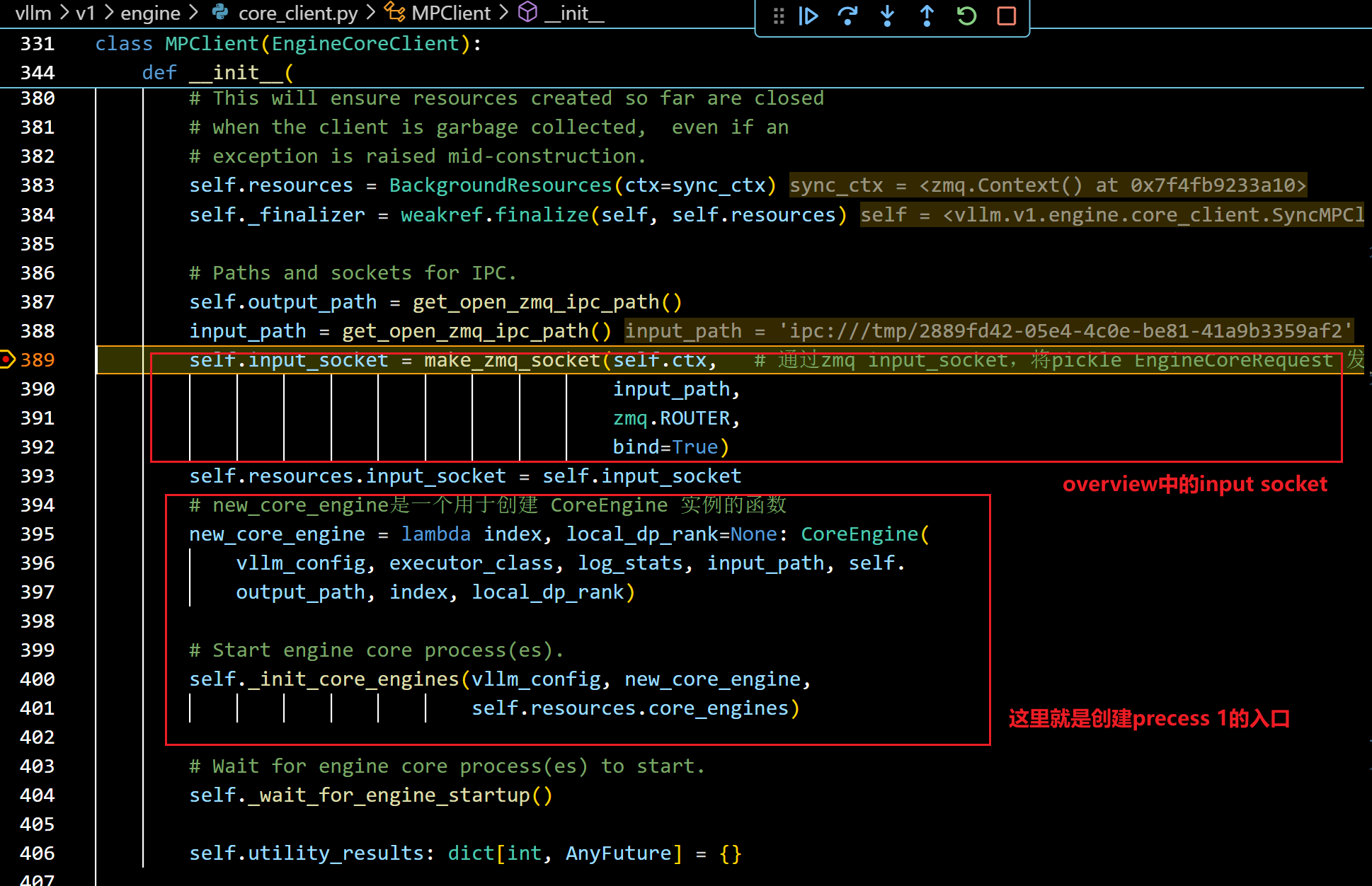
- 继续debug
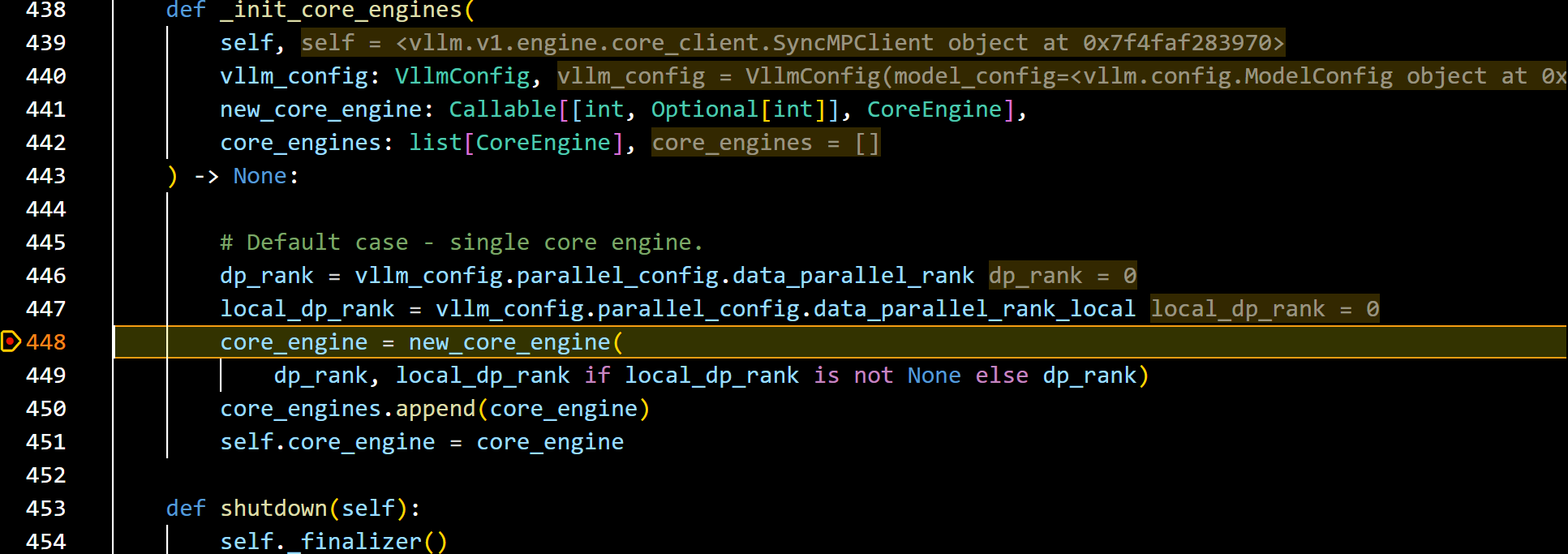
- 进入到CoreEngine类中:
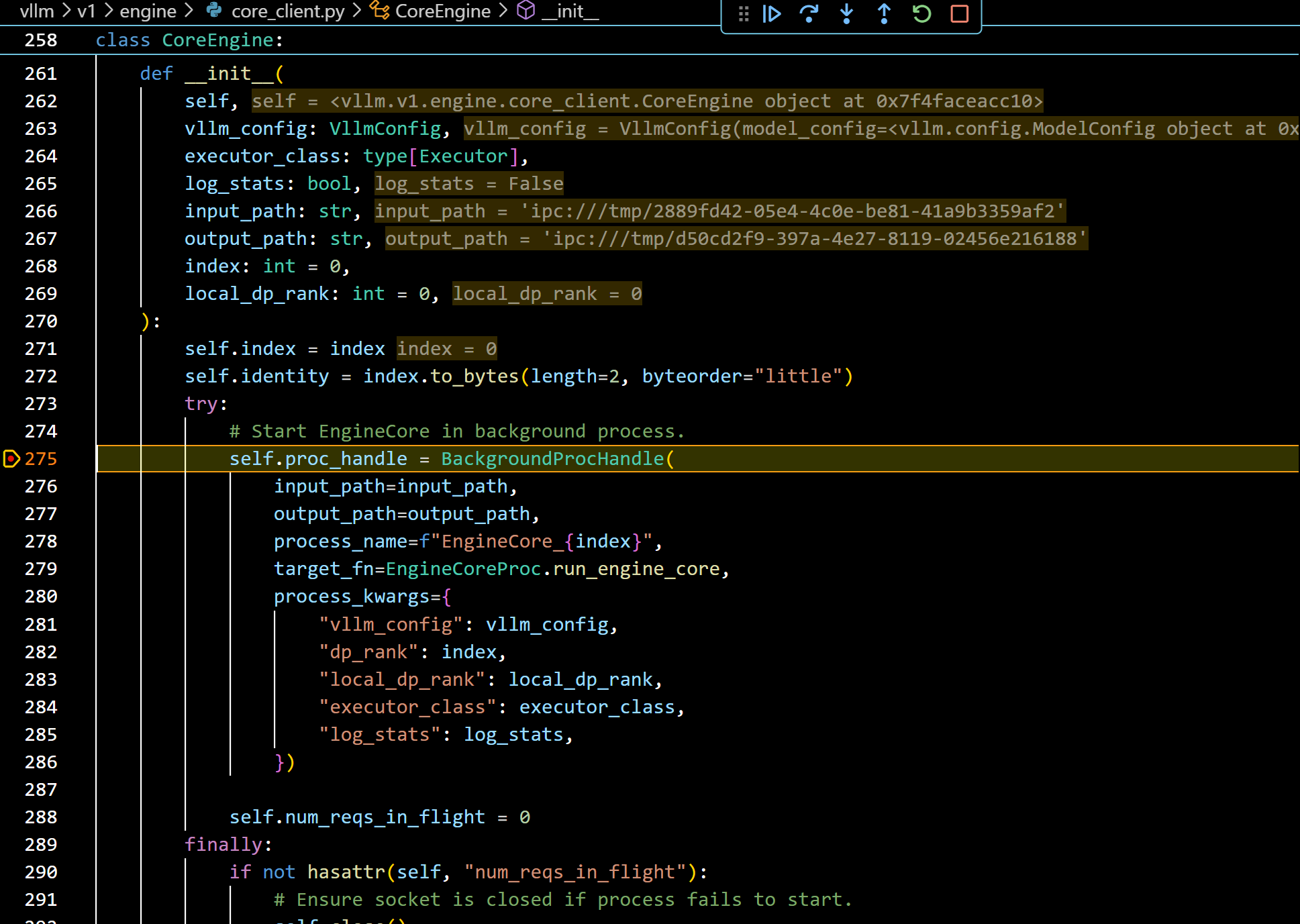
- 这里就要创建进程了,target_fn=EngineCoreProc.run_engine_core,因此现在这个函数里面打个断点,防止追不到:
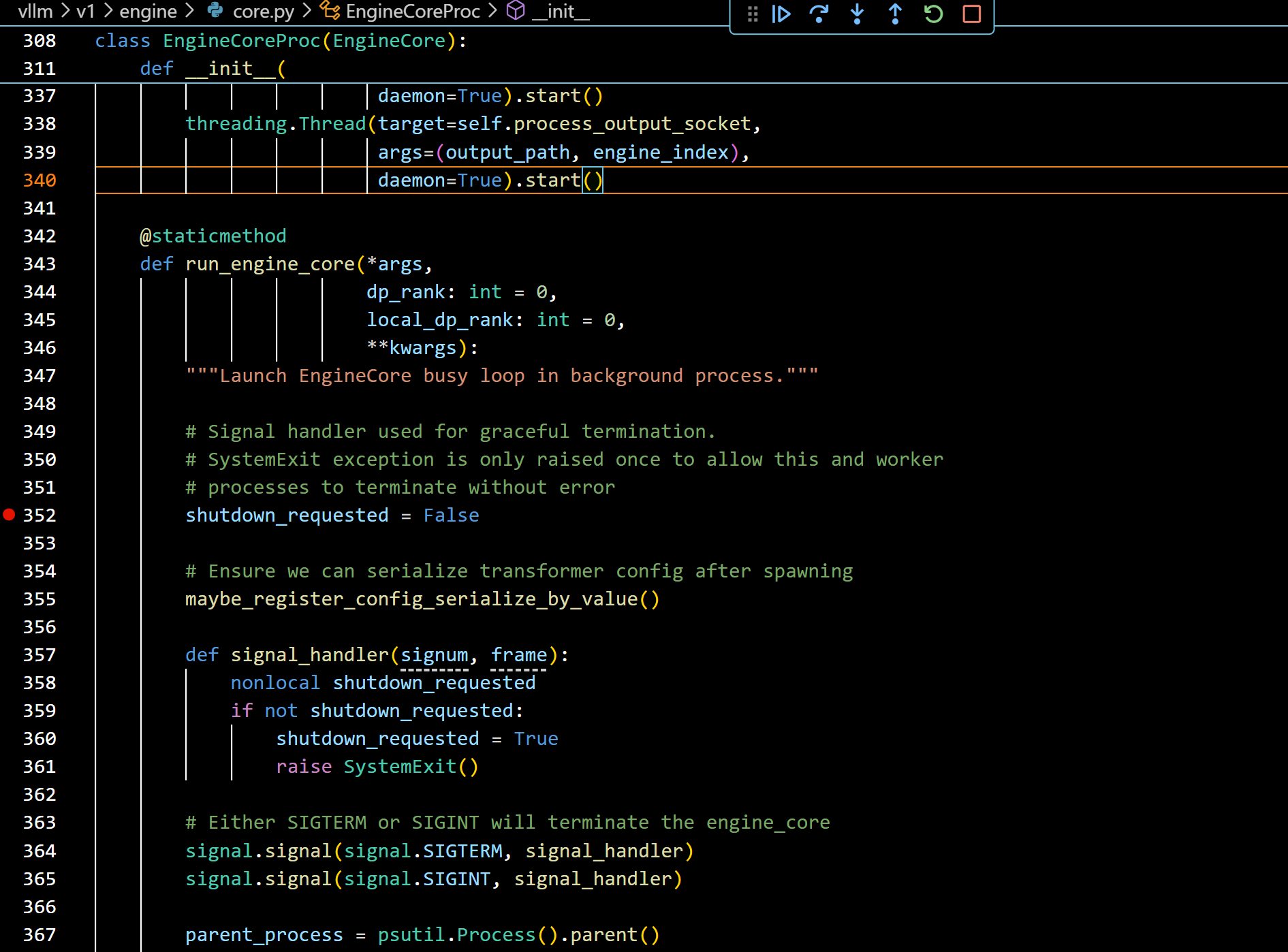
- 我们在BackgroundProcHandle跳过之后可以观察到调用堆栈中创建了一个新的进程:
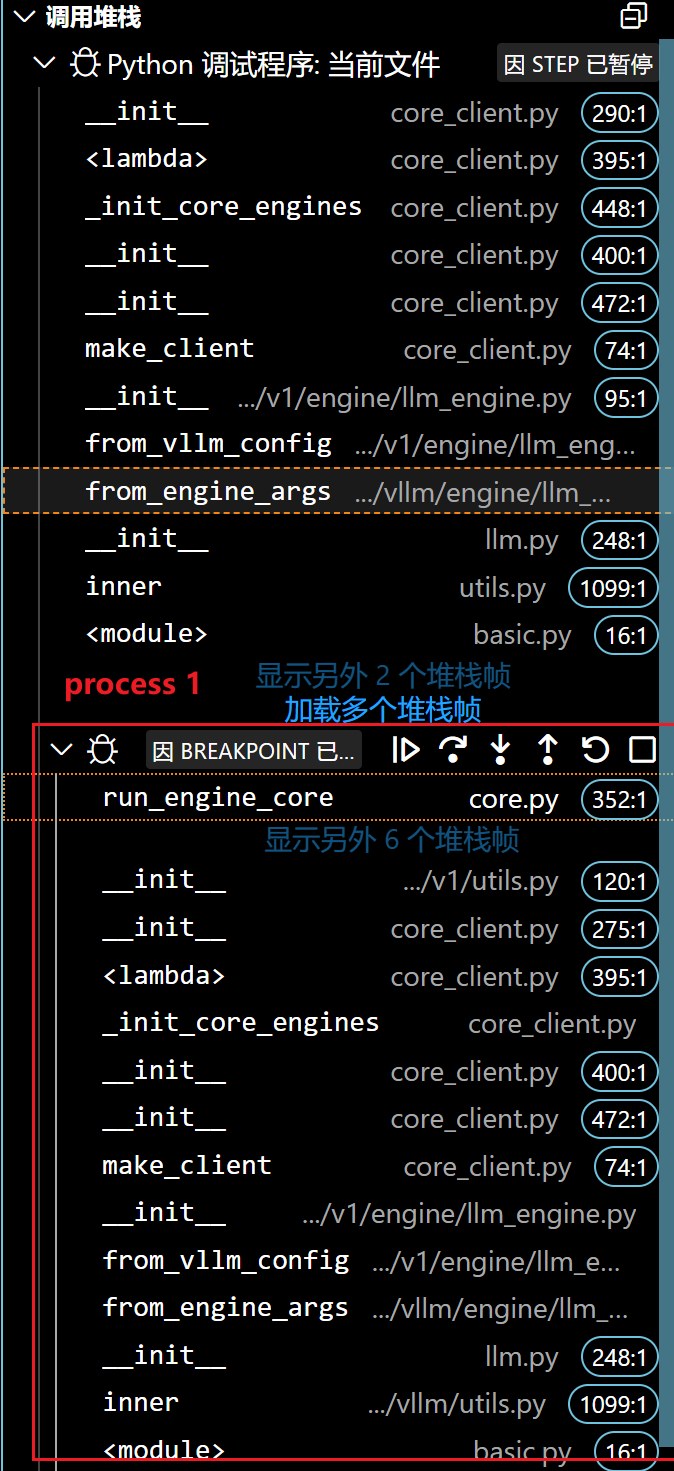
- 点击之后就会停在刚刚我们打的断点处:
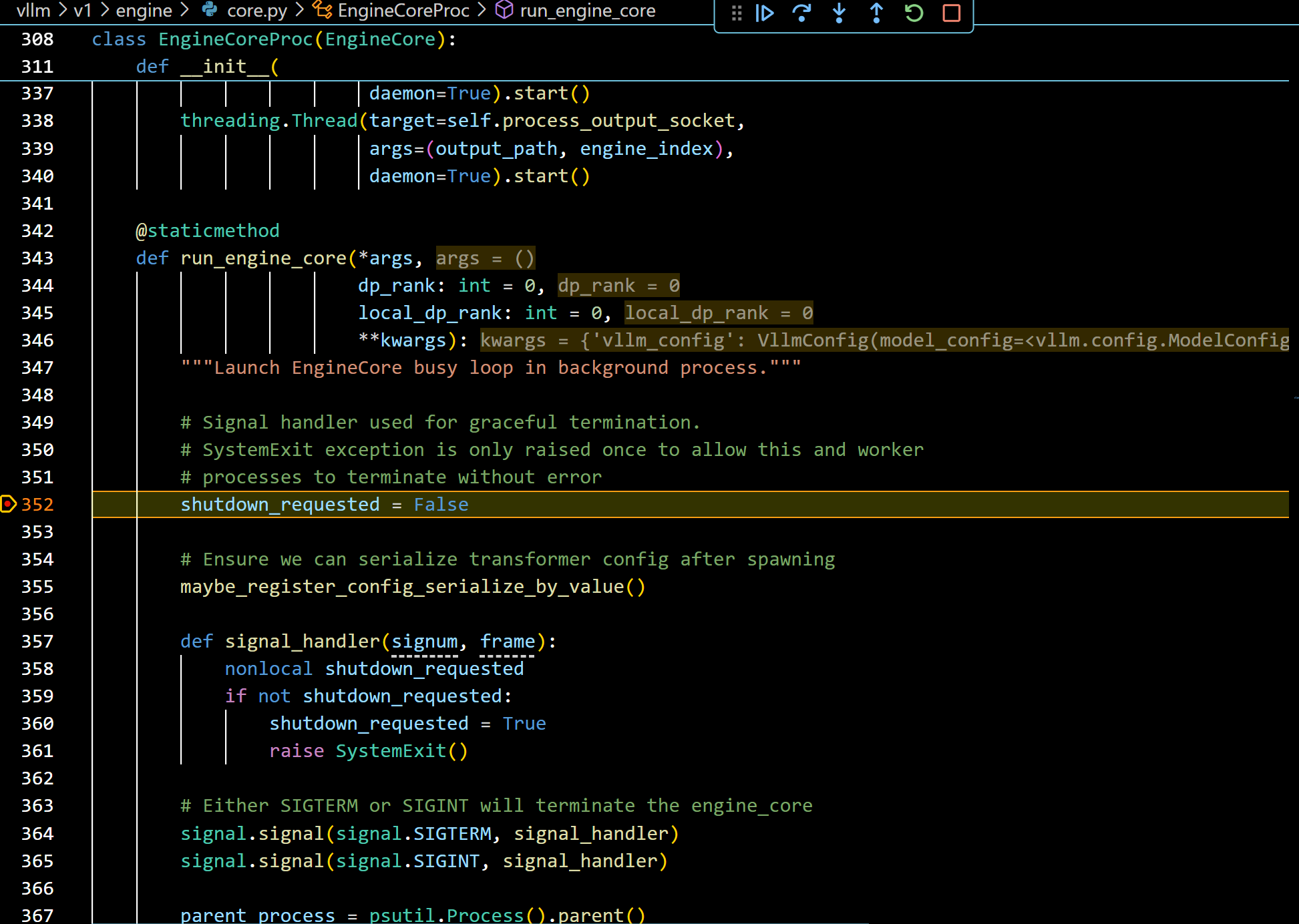
- 往下看,接着打断点:
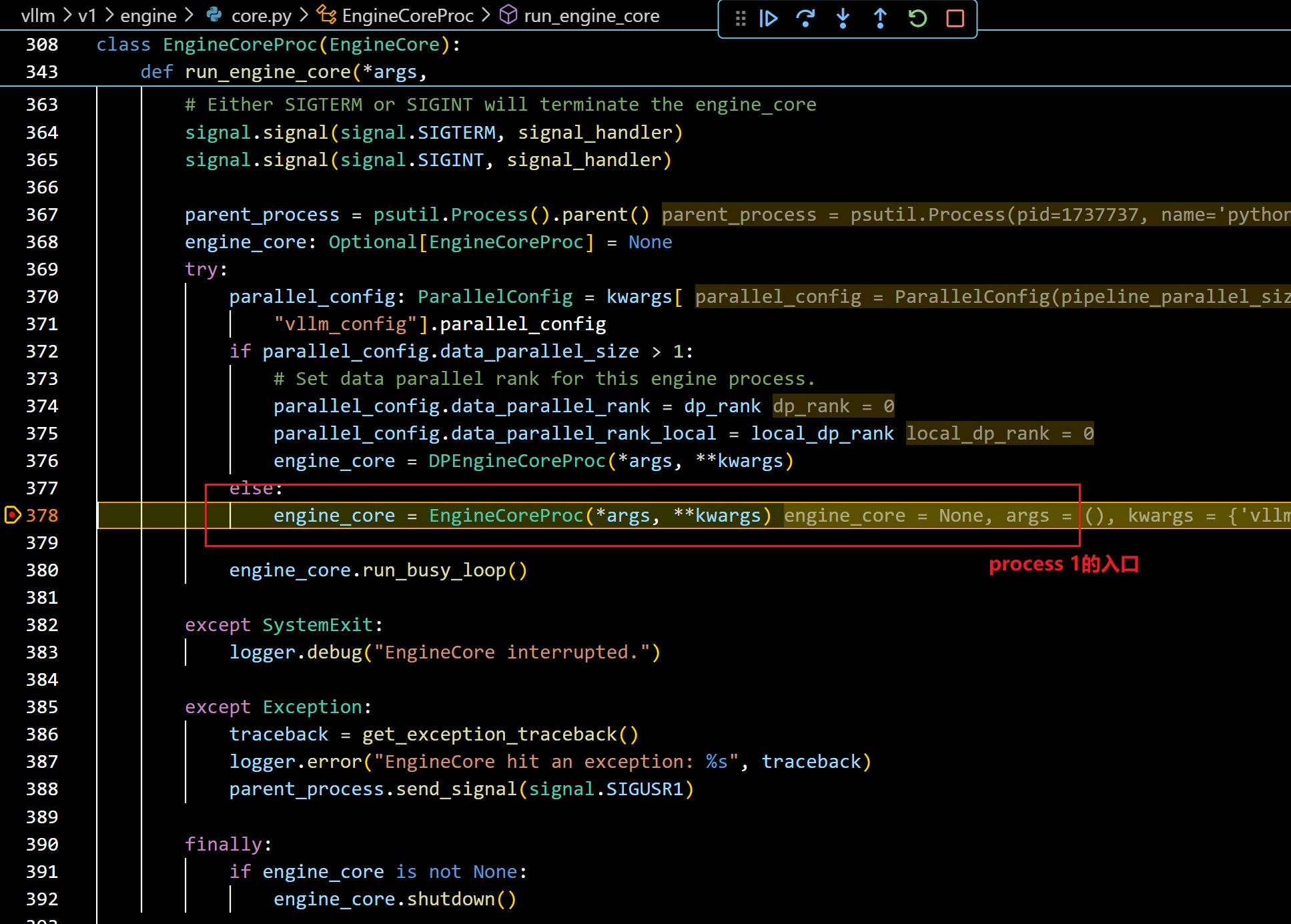
- 进入这个EngineCoreProc的实例化方法后:
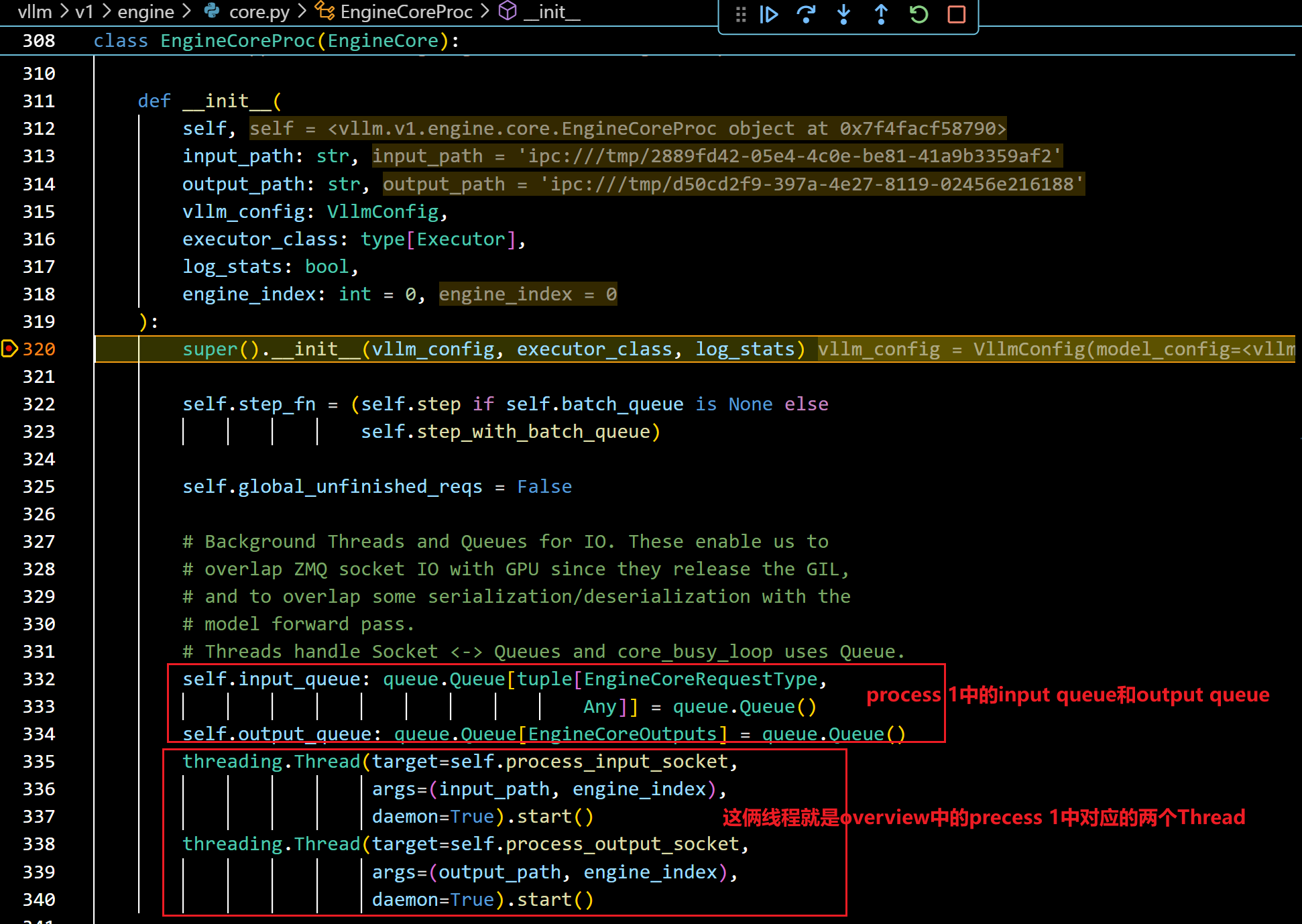
- 我们接着debug进入上图中的super().init()中:
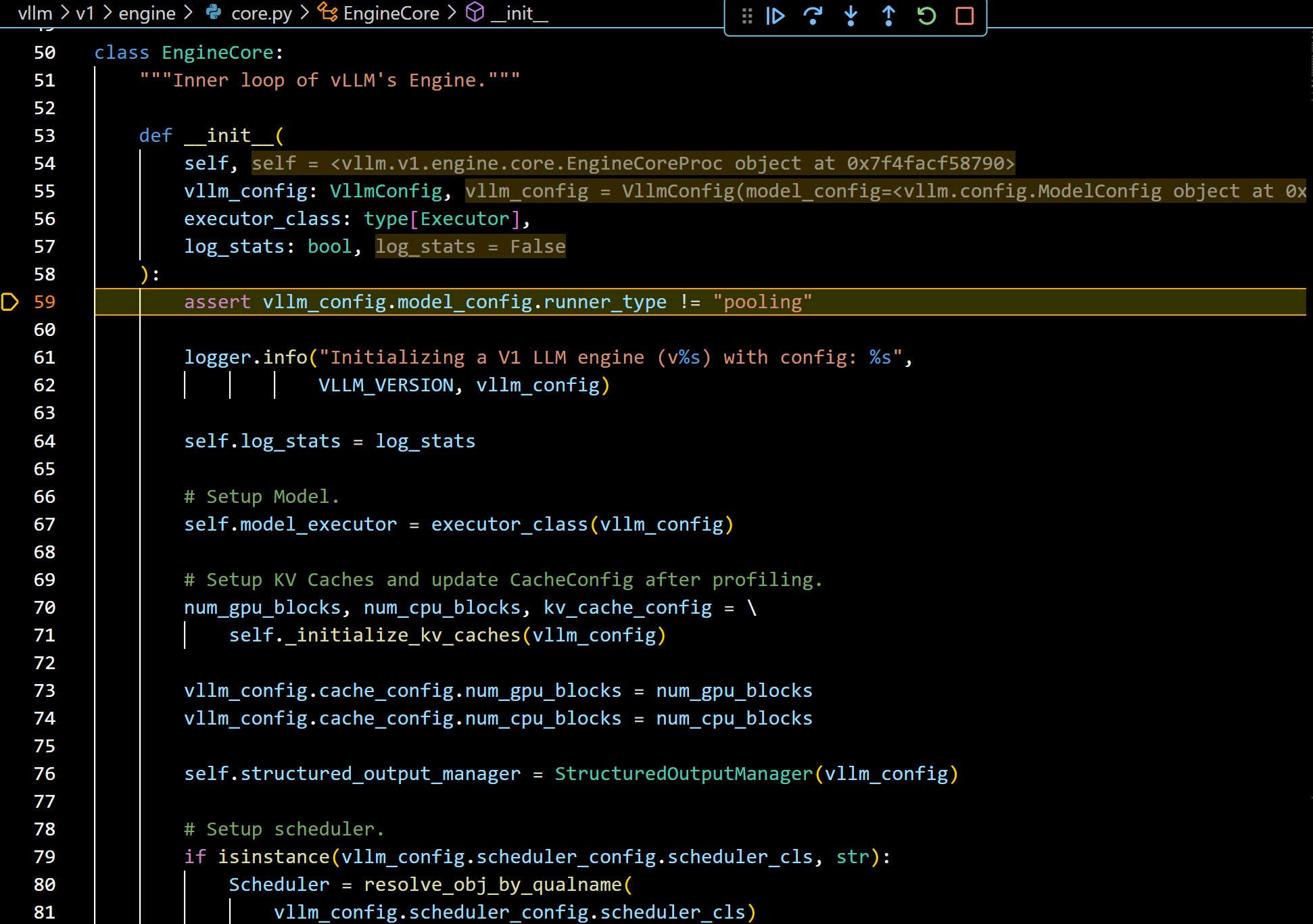
- 看过vLLM v0代码的读者,看到这个EngineCore构造函数中的内容应该会觉得很熟悉(至少我觉得)
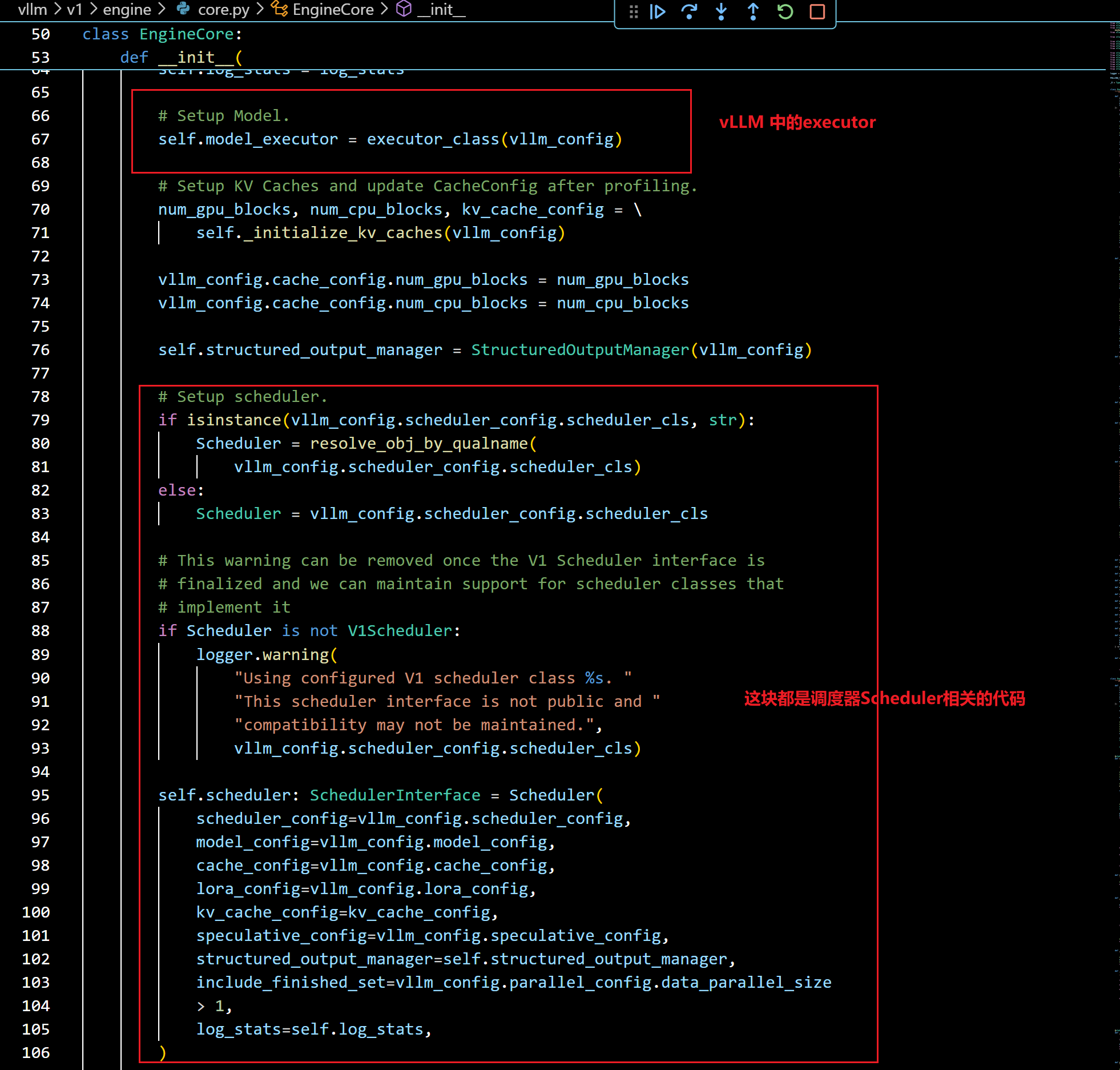
- 我们再进入调度器实现看看:
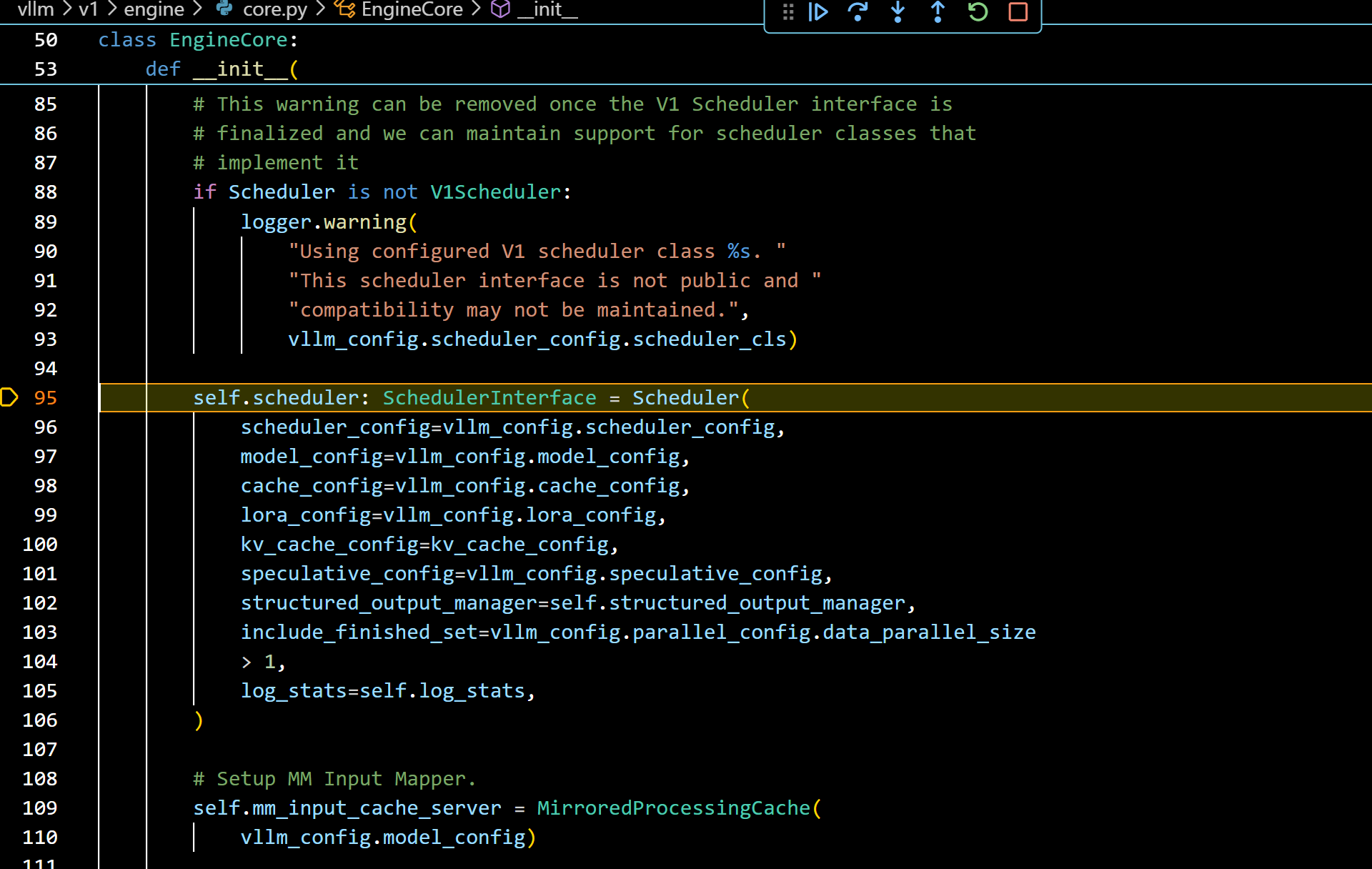
- 下图就是调度器模块了,v1中调度器是prefill和decode混合的,而且没有cpu offload了,这要和v0调度器区分一下:
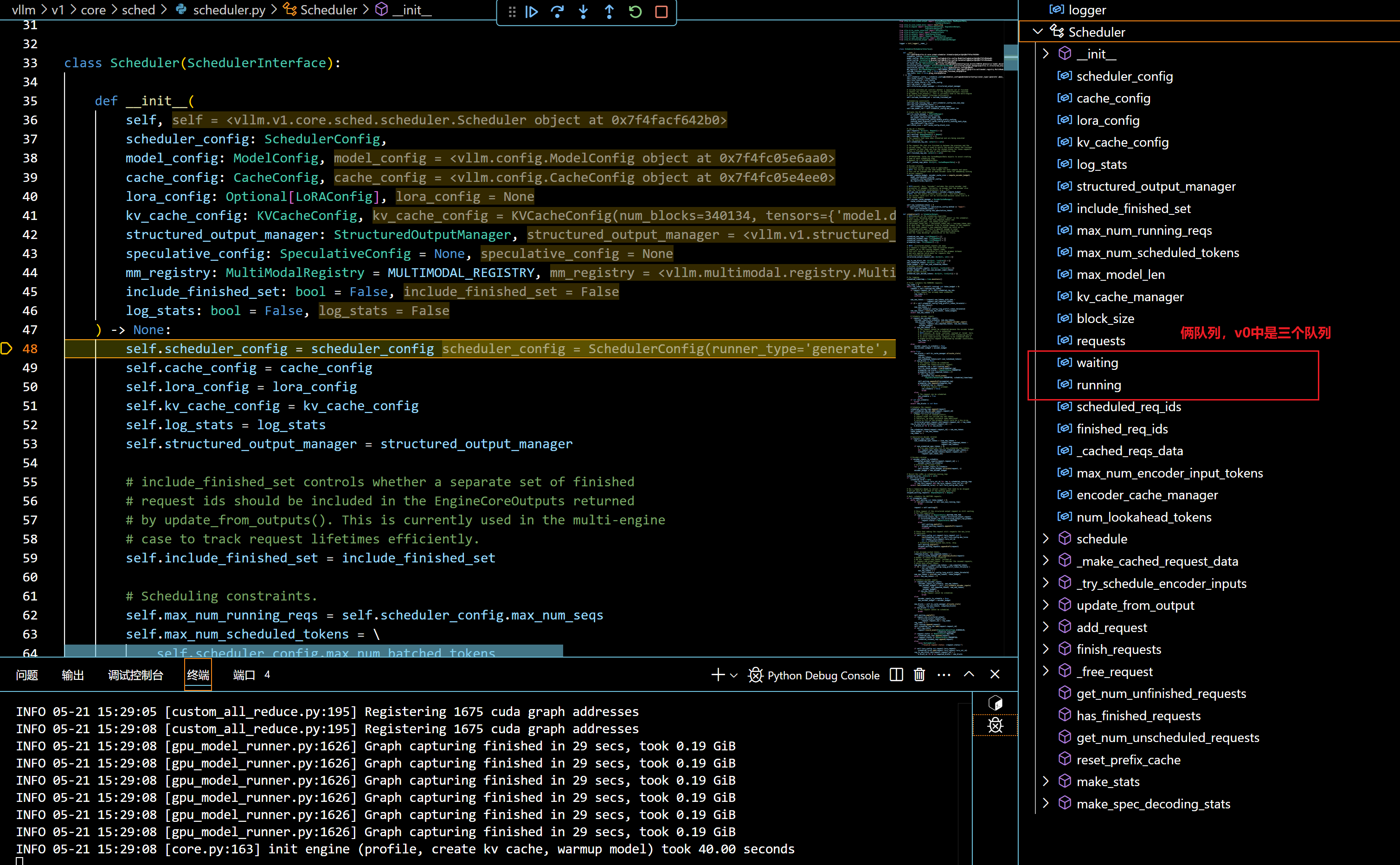
- debug到这里,其实overview中所有的模块都包含了,具体细节读者可以边debug,边print。
- 我们直接step out到最初始的离线推理入口函数中:
- 进入到LLM的generate()函数中:
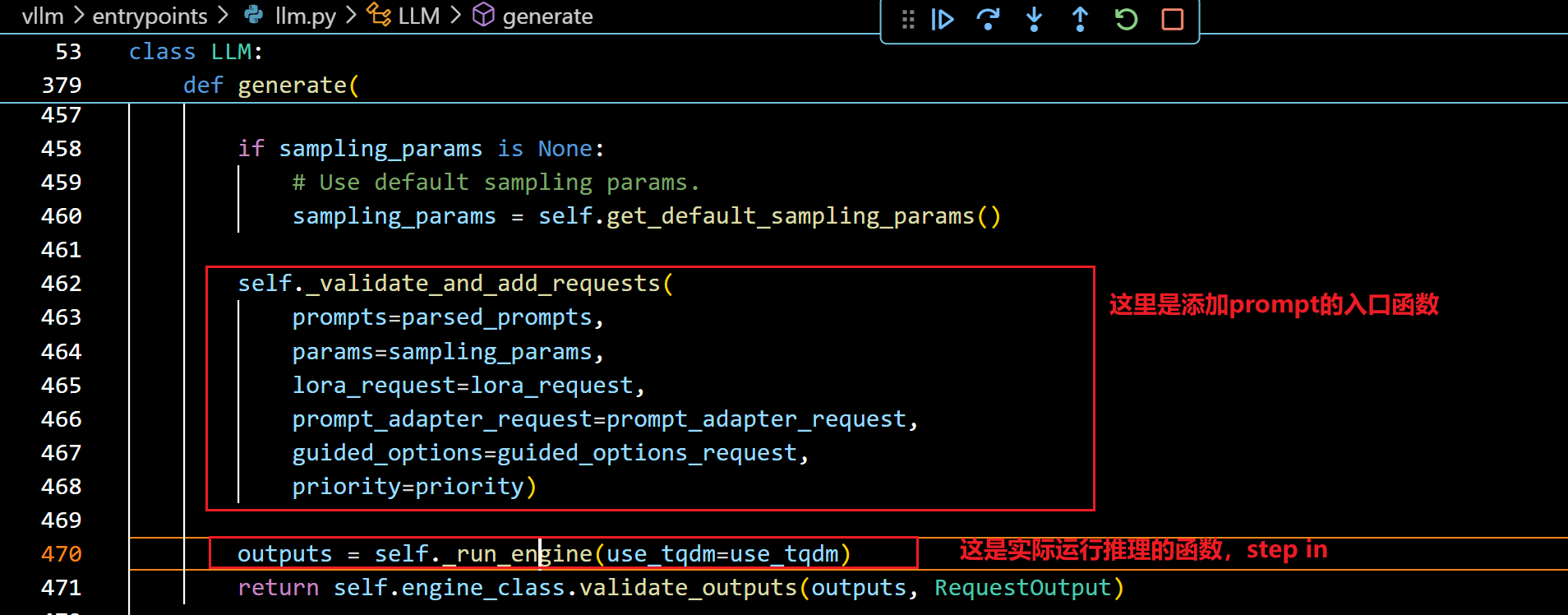
- 进入run_engine():
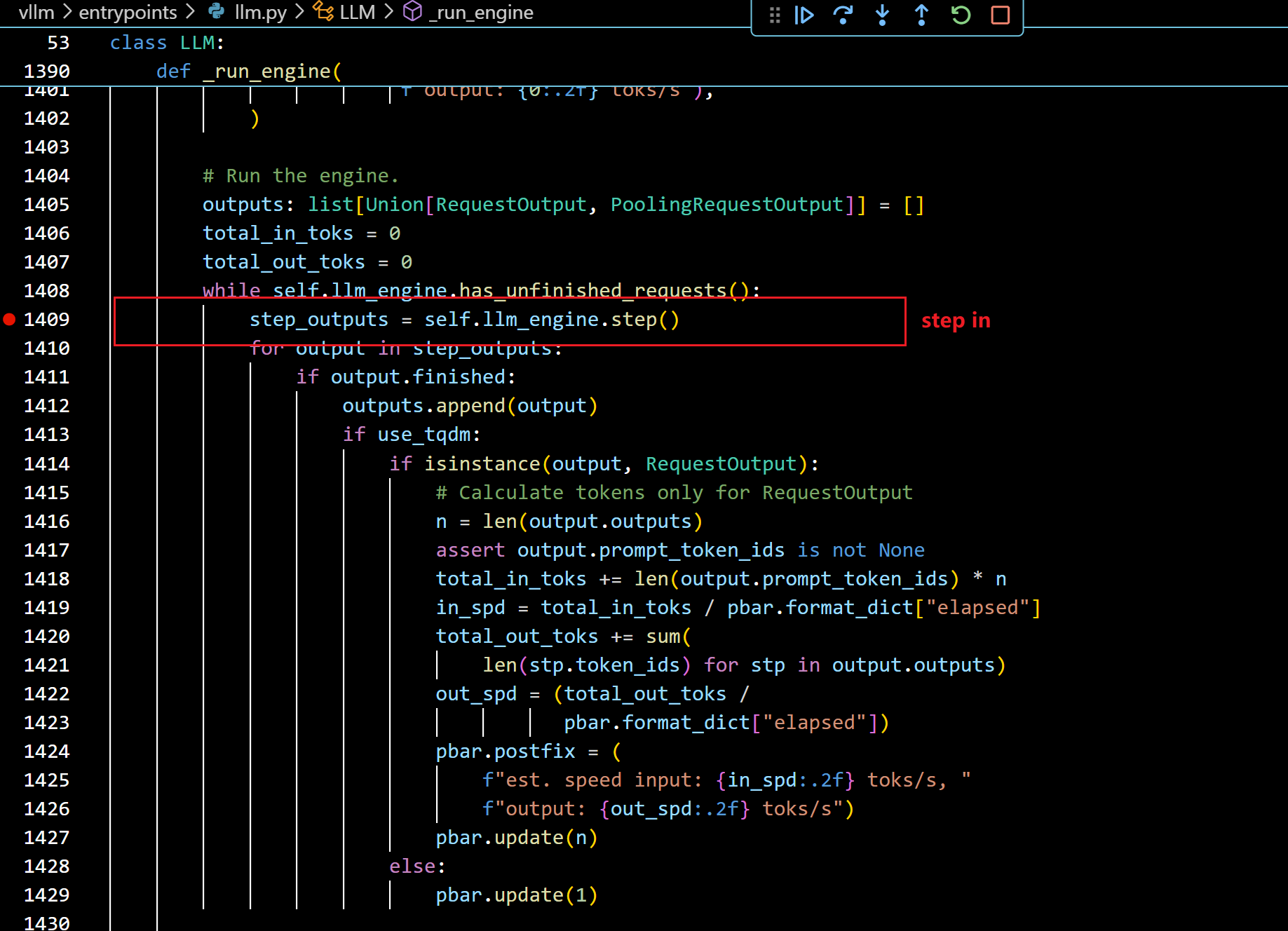
- 进入step之后,可以看到:
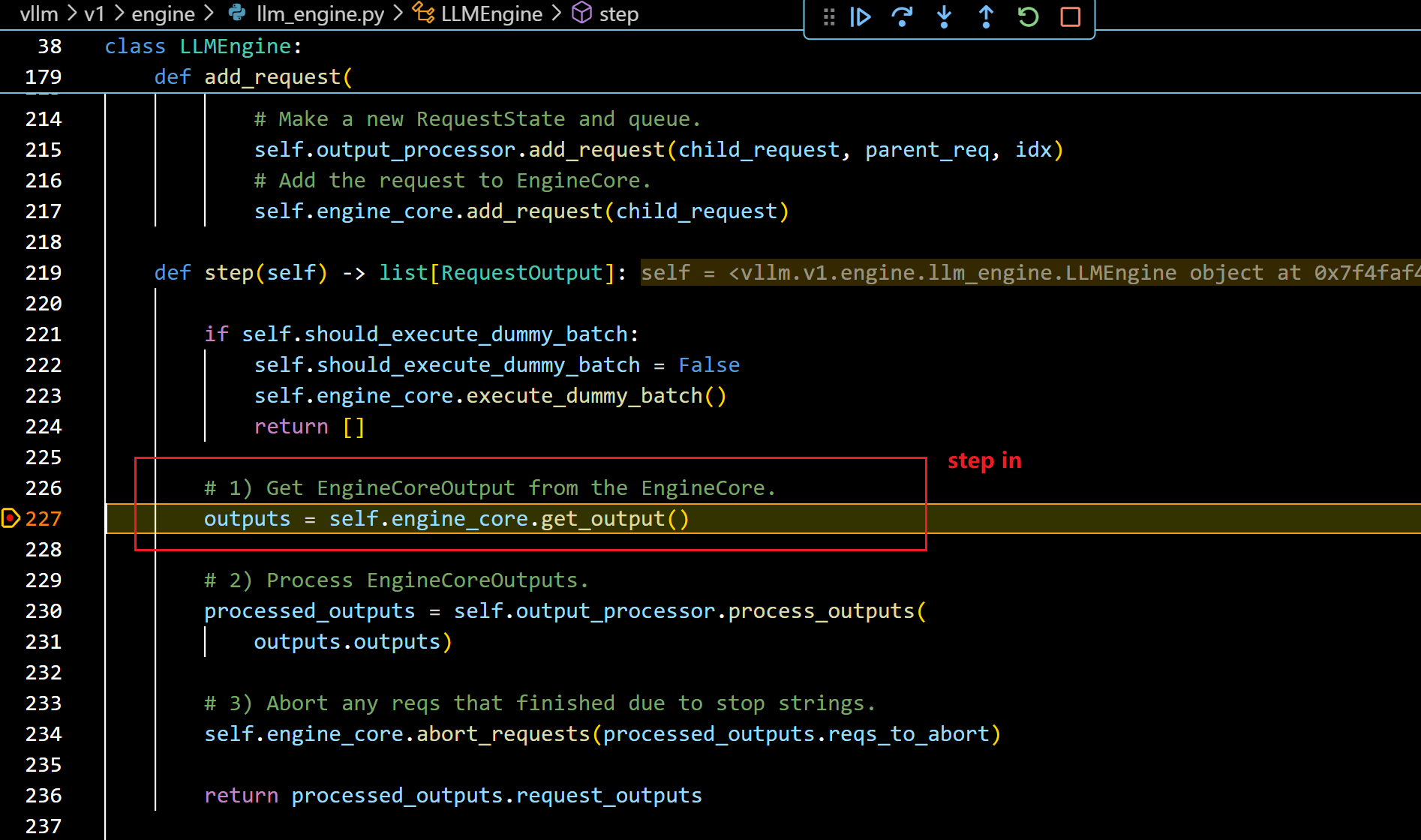
- 可以看到:

- 这个get_output是直接使用了SyncMPClient中的outputs_queue获取了,因为我们前面以前添加了request(可以自行debug),进程已经运行了推理。
- 然后进程process 0 会反复进行setp的操作,直到全部请求都推理完成:
- 推理结束:
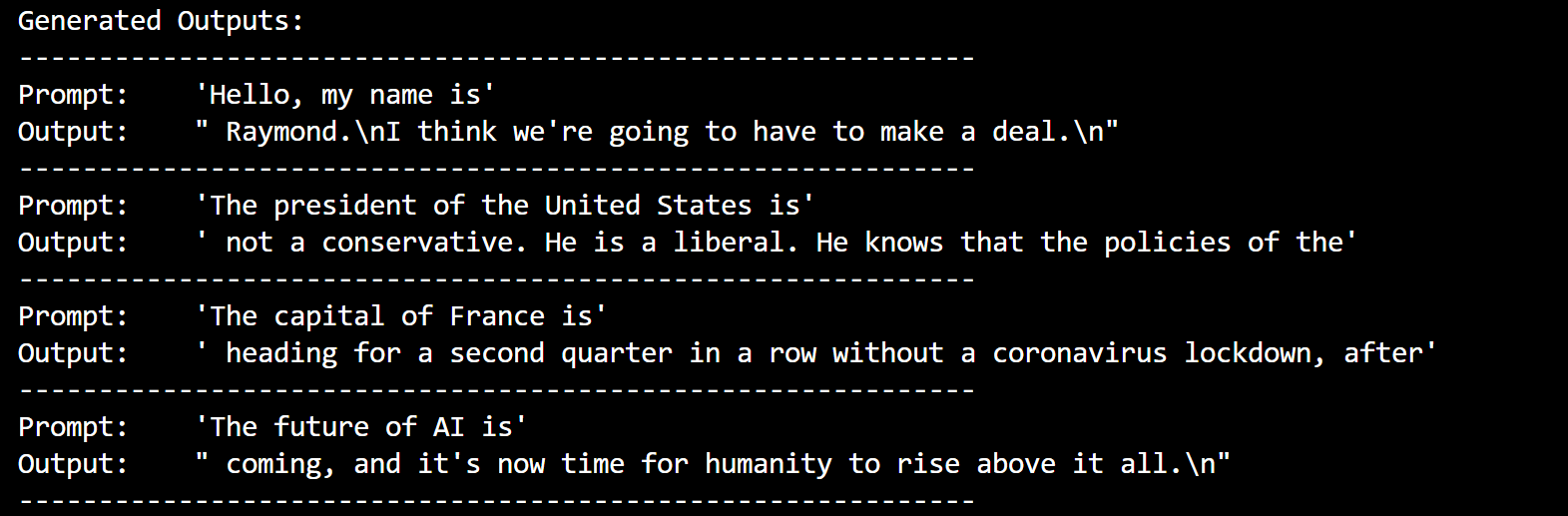
笔者已经尽量详细,但还是觉得写的不太好,多多包涵!