java 集合总结
文章目录
目录
文章目录
前言
一、泛型的作用
1.类型安全
2.通用性
这里再举个例子
二、泛型的实现
1.泛型类
2.泛型接口
3.泛型方法
4.T符号的起源(额外)
三、泛型擦除
四、泛型通配符
为什么用于读取?
为什么用于写入?
语法特点
?和T
总结
举例
五、泛型限制与注意事项
前言
集合(Collections) 是用于存储、管理和操作一组数据的容器,其核心作用是为开发者提供高效、灵活和标准化的数据管理方案
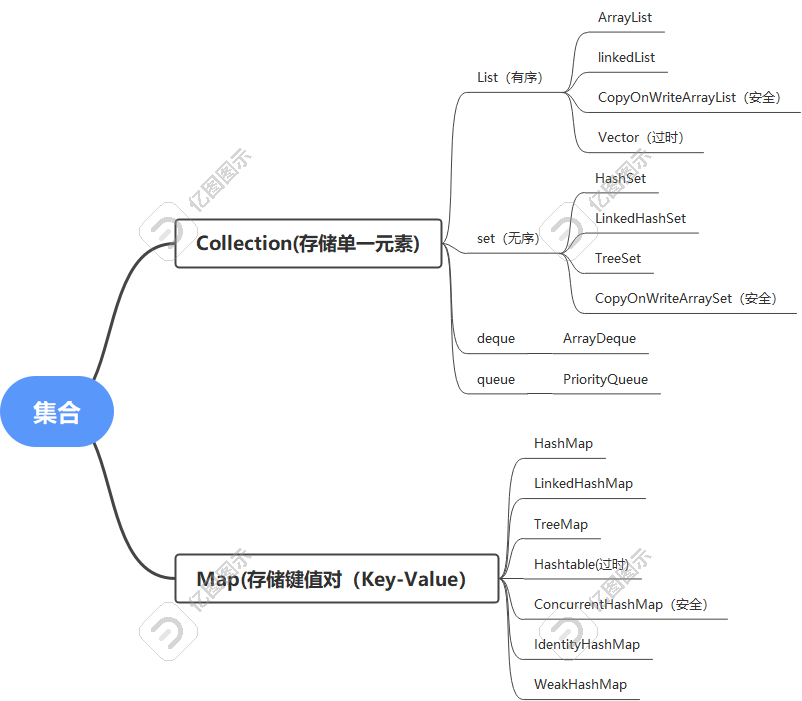
一、Collection
1.List
1.ArrayList
底层是数组,新增修改都是基于copy数组的形式,查询就是基于索引
详细请看从底层认识ArrayList
2.LinkedList
底层是以及静态内部类Node对象,通过前后指针指向不同节点,形成双向链表,查询数据需要从头或尾遍历链表,新增,修改,删除,也需要遍历到指定位置,后续直接改指针指向就行
详细请看LinkedList
3.CopyOnWriteArrayList(安全)
允许多线程读,不允许多线程同时写,底层就是在写的时候加了一个synchronized (lock) {} 锁代码块,保证线程安全,而读没加锁,其他的和ArrayList大同小异
4.Vector
过时了,直接加的方法锁,效率太低
| 实现类 | 底层结构 | 线程安全 | 特点 | 适用场景 |
|---|---|---|---|---|
| ArrayList | 动态数组 | 否 | 随机访问快(O(1)),增删中间元素慢(需移动元素,O(n)) | 频繁查询,少增删 |
| LinkedList | 双向链表 | 否 | 增删快(O(1)),随机访问慢(需遍历,O(n)) | 频繁头尾操作,需实现队列/栈 |
| CopyOnWriteArrayList | 动态数组 + 写时复制 | 是 | 读操作无锁,写操作复制新数组;读多写少性能高,写多时内存开销大 | 高并发读,极少写(如监听器) |
2.Set
1.HashSet
底层其实就是HashMap,存储的k,v值,直接调用HashMap中的方法。但是每次新增的时候v值是固定的,这就导致插入数组和链表时候相同k的数据会覆盖,导致值唯一
详细看HashSet
2.LinkedHashSet
底层是LinkedHashMap(看下面),和HashSet一样v固定,存的是k值
3.TreeSet
底层红黑树,自然有序,key值不重复
4.CopyOnWriteArraySet
基于CopyOnWriteArrayList,新增的时候循环判断是否存在数据
| 实现类 | 底层结构 | 线程安全 | 特点 | 适用场景 |
|---|---|---|---|---|
| HashSet | 基于 HashMap | 否 | 无序,快速插入、删除、查找(O(1)) | 去重且无需顺序 |
| LinkedHashSet | 链表 + HashMap | 否 | 维护插入顺序,性能略低于 HashSet | 需保持插入顺序的去重场景 |
| TreeSet | 红黑树 | 否 | 自然排序或自定义排序,查找/插入/删除 O(log n) | 需有序且去重的场景 |
| CopyOnWriteArraySet | 基于 CopyOnWriteArrayList | 是 | 读多写少性能好,写操作效率低 | 类似 CopyOnWriteArrayList |
| ConcurrentSkipListSet | 跳表(SkipList) | 是 | 有序,高并发下性能优于 TreeSet | 高并发有序集合 |
注意:set所谓的无序指的是实现的Set接口的默认实现(HashSet,TreeSet(自然有序)) ,而且无序是指的按插入顺序,自然List的有序也指的插入顺序(3,1,2)对应的查询顺序(3,1,2),而不是自然有序(1,2,3)
3.deque
继承自 Queue,支持两端操作(队尾,队首进行操作)
1.ArrayDeque
Queue接口的实现
2.ConcurrentLinkedDeque(安全)
没有复合操作,直接使用CAS来保证线程安全
4.queue
遵循FIFO(先进先出)原则的队列
1.PriorityQueue(支持有序)
元素按自然顺序或Comparator定义的顺序排序。
2.ConcurrentLinkedQueue(安全)
CAS来控制线程安全
二、Map
1.HashMap
底层是数据加链表(红黑树)的信息,无序,key不能重复,Value可重复
详情看HashMap
2.LinkedHashMap
底层就是HashMap,只不过多维护了一个双向链表结构(保证插入有序),简单来说每次新增的数据加入一个双向链表来维护顺序,不懂的看下面这篇文章
LinkedHashMap
3.Treemap
底层是红黑树,保证顺序(这里的顺序是自然顺序和key值相关),和LinkedHashMap顺序不同
详细看TreeMap
4.ConcureentHashMap(安全)
底层就是实现的HashMap,只不过加了sychronried锁,锁住了每一个桶(链表),数组不用锁,因为没有公共遍历处理,只有桶中可能会出现重复的key,会出现覆盖
5.ConcurrentSkipListMap
维护多层级的链表,是空间换时间的数据结构,链表构建时候层数生成随机,插入时候层数也随机,插入到生成层数及以下的层数中去,查询从高到低判断左右节点
| 实现类 | 底层结构 | 线程安全 | 特点 | 适用场景 |
|---|---|---|---|---|
| HashMap | 数组+链表/红黑树 | 否 | 快速查找(O(1)),链表过长转红黑树(O(log n)) | 通用键值存储,无需顺序 |
| LinkedHashMap | 链表 + HashMap | 否 | 维护插入顺序或访问顺序 | 需保留插入顺序(如 LRU 缓存) |
| TreeMap | 红黑树 | 否 | 按键自然排序或自定义排序,操作 O(log n) | 需有序键的场景 |
| Hashtable | 数组+链表 | 是 | 全表锁,性能差 | 遗留代码,不推荐使用 |
| ConcurrentHashMap | HashMap+CAS + synchronized | 是 | 高并发优化,锁粒度细 CAS + synchronized) | 高并发键值存储 |
| ConcurrentSkipListMap | 跳表 | 是 | 有序,高并发下性能优于 TreeMap | 高并发有序键值存储 |