【三十三周】文献阅读:OpenPose: 使用部分亲和场的实时多人2D姿态估计
目录
- 摘要
- Abstract
- OpenPose: 使用部分亲和场的实时多人2D姿态估计
- 研究背景
- 创新点
- 方法论
- 网络结构
- 损失函数
- 关键点连接
- 主要代码
- 实验结果
- 局限性
- 总结
摘要
OpenPose是一种实时多人2D姿态估计系统,能够从图像或视频中检测人体的关键点(如关节)并将这些关键点关联到不同的人。其核心创新在于引入了部分亲和场(Part Affinity Fields, PAFs),这是一种非参数化的表示方法,用于编码肢体的位置和方向信息。PAFs通过2D向量场表示肢体的连接关系,帮助系统在复杂的多人场景中正确关联关键点。OpenPose的工作流程分为以下几个步骤:首先,通过卷积神经网络(CNN)生成置信度图(Confidence Maps),表示每个身体部位的位置;接着,生成PAFs,表示肢体之间的连接关系;最后,通过贪心算法解析置信度图和PAFs,将关键点关联到不同的人。系统采用多阶段的CNN架构,逐步优化PAFs和置信度图,确保高精度和实时性能。
Abstract
OpenPose is a real-time multi-person 2D pose estimation system capable of detecting human keypoints (such as joints) from images or videos and associating these keypoints with different individuals. Its core innovation lies in the introduction of Part Affinity Fields (PAFs), a non-parametric representation method used to encode the position and orientation information of limbs. PAFs represent the connection relationships between body parts through 2D vector fields, aiding the system in accurately associating keypoints in complex multi-person scenarios. The workflow of OpenPose includes several steps: first, Confidence Maps are generated through a Convolutional Neural Network (CNN), indicating the location of each body part. Next, PAFs are generated to show the connections between limbs. Finally, a greedy algorithm parses the Confidence Maps and PAFs to associate keypoints with different individuals. The system employs a multi-stage CNN architecture to progressively refine PAFs and Confidence Maps, ensuring high accuracy and real-time performance.
OpenPose: 使用部分亲和场的实时多人2D姿态估计
Title: OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
Author: Cao, Z (Cao, Zhe) ; Hidalgo, G (Hidalgo, Gines) ; Simon, T (Simon, Tomas) ; Wei, SE (Wei, Shih-En); Sheikh, Y (Sheikh, Yaser)
Source: IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE
WOS:https://webofscience.clarivate.cn/wos/alldb/full-record/WOS:000597206900012
研究背景
目前对于实时多人姿态估计主要存在三个难点:
第一是每个图像可能包含未知数量的人,这些人可以出现在任何位置或比例。
第二是人与人之间的互动(如接触或遮挡)会引起复杂的空间干扰,使身体关键点部分之间的关联变得困难。
第三是运行时的复杂性往往会随着图像中的人数而增加。
对于姿态估计领域又分化成两种技术路线:
第一种是自顶向下的方法。这种方法是先用一个目标检测器检测到人物,然后再分别对单独的人物进行姿态估计。这种方法有一个显著的弊端,那就是如果人物检测不到那么就无法进行姿态估计。另一个弊端就是计算复杂度和人物数量相关,当图像中人物越多时消耗的时间就越多,难以进行实时应用。
第二种是自底向上的方法。这种方法首先检测图像中所有的人体关键点(例如肘部、膝盖、手腕等),然后将这些关键点分组以形成每个人的身体姿态。由于这种方法的计算复杂度不直接依赖于人数,因此它可以更高效地处理人群场景。但是这种方法目前的计算效率比较低,最终的图像解析需要耗费大量时间去做全局推理,因此没有应用到实时姿态估计领域。
创新点
在本篇论文中,研究者们正是采用了自底向上的方法来实现实时的姿态估计。
但是上一节提到自底向上的方法效率比较低,那么论文作者是如何实现实时姿态估计的呢?
We present the first bottom- up representation of association scores via Part Affinity Fields (PAFs), a set of 2D vector fields that encode the location and orientation of limbs over the image domain. We demonstrate that simultaneously inferring these bottom- up representations of detection and association encodes sufficient global context for a greedy parse to achieve high-quality results, at a fraction of the computational cost.
论文作者使用了一个叫做部分亲和场(Part Affinity Fields)的方法来编码图像中肢体位置和方向,节省了大量的计算资源,实现了实时的姿态估计。
方法论
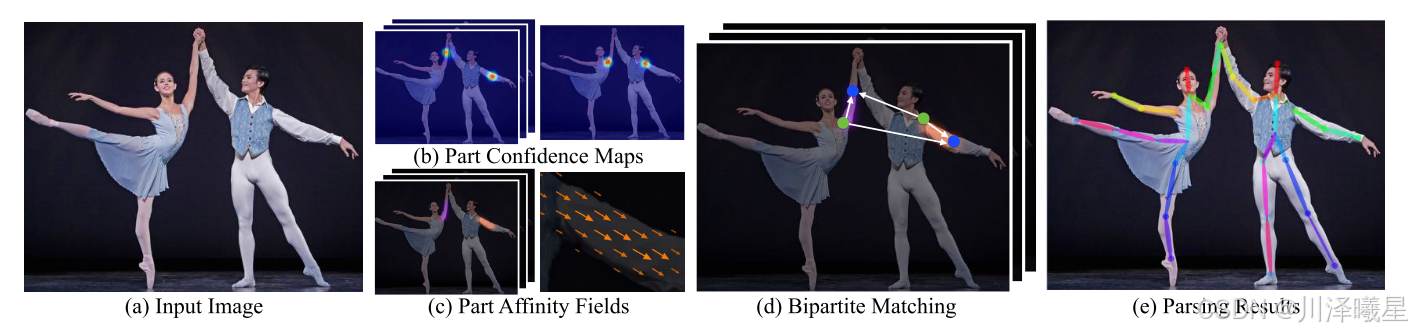
整体的工作流程如上图所示:
- 首先将整个图像输入到卷积神经网络中提取特征
- 分别提取人体关节点的热度图和PAF信息
- 将关键点进行二分匹配,选择概率最大的进行连接
- 全部连接生成图像中所有人的全身姿势

上图左侧展示的是连接右肘和手腕的肢体对应的部位亲和场,右侧表示PAF中每个像素的肢体位置和方向。
网络结构
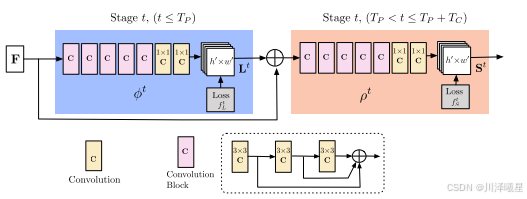
采用多阶段的卷积神经网络(CNN),逐步优化PAFs和关键点置信度图。网络通过迭代预测PAFs和置信度图,逐步细化预测结果。网络结构如上图所示,每个卷积块由三个连续的3x3卷积核组成,并且内部每一层的输出和最后一层的输出采用了残差连接。
在每个阶段,网络利用前一阶段的PAFs和原始图像特征,生成更精确的PAFs:
L t = ϕ t ( F , L t − 1 ) , ∀ 2 ≤ t ≤ T P \mathbf{L}^t = \phi^t(\mathbf{F}, \mathbf{L}^{t-1}), \quad \forall 2 \leq t \leq T_P Lt=ϕt(F,Lt−1),∀2≤t≤TP
- L t \mathbf{L}^t Lt :第 t 阶段的PAFs
- ϕ t \phi^t ϕt :第 t 阶段的CNN,用于生成PAFs
- F \mathbf{F} F :原始图像的特征图
- L t − 1 \mathbf{L}^{t-1} Lt−1 :第 t-1 阶段的PAFs
- T P T_P TP :PAFs的总阶段数
在PAFs的最后一个阶段,网络生成初始的置信度图:
S T P = ρ t ( F , L T P ) , ∀ t = T P \mathbf{S}^{T_P} = \rho^t(\mathbf{F}, \mathbf{L}^{T_P}), \quad \forall t = T_P STP=ρt(F,LTP),∀t=TP
- S T P \mathbf{S}^{T_P} STP:第 T P T_P TP 阶段的置信度图。
- ρ t \rho^t ρt:第 t t t 阶段的CNN,用于生成置信度图。
- F \mathbf{F} F:原始图像的特征图。
- L T P \mathbf{L}^{T_P} LTP:第 T P T_P TP 阶段的PAFs。
损失函数
损失函数由两部分组成:
PAFs的损失函数:
f
L
t
i
=
∑
c
=
1
C
∑
p
W
(
p
)
⋅
∣
∣
L
c
t
i
(
p
)
−
L
c
∗
(
p
)
∣
∣
2
2
f_{\mathbf{L}}^{t_i} = \sum_{c=1}^{C} \sum_{\mathbf{p}} \mathbf{W}(\mathbf{p}) \cdot ||\mathbf{L}_c^{t_i}(\mathbf{p}) - \mathbf{L}_c^*(\mathbf{p})||_2^2
fLti=c=1∑Cp∑W(p)⋅∣∣Lcti(p)−Lc∗(p)∣∣22
- f L t i f_{\mathbf{L}}^{t_i} fLti: 第 $ t_i $ 阶段的PAFs损失。
- L c t i ( p ) \mathbf{L}_c^{t_i}(\mathbf{p}) Lcti(p): 第 $ t_i $ 阶段的PAFs预测值。
- L c ∗ ( p ) \mathbf{L}_c^*(\mathbf{p}) Lc∗(p): 真实的PAFs值。
- W ( p ) \mathbf{W}(\mathbf{p}) W(p): 权重矩阵,用于处理未标注的区域。
置信度图的损失函数:
f
S
t
k
=
∑
j
=
1
J
∑
p
W
(
p
)
⋅
∣
∣
S
j
t
k
(
p
)
−
S
j
∗
(
p
)
∣
∣
2
2
f_{\mathbf{S}}^{t_k} = \sum_{j=1}^{J} \sum_{\mathbf{p}} \mathbf{W}(\mathbf{p}) \cdot ||\mathbf{S}_j^{t_k}(\mathbf{p}) - \mathbf{S}_j^*(\mathbf{p})||_2^2
fStk=j=1∑Jp∑W(p)⋅∣∣Sjtk(p)−Sj∗(p)∣∣22
- $ f_{\mathbf{S}}^{t_k} $: 第 $ t_k $ 阶段的置信度图损失。
- S j t k ( p ) \mathbf{S}_j^{t_k}(\mathbf{p}) Sjtk(p): 第 $ t_k $ 阶段的置信度图预测值。
- S j ∗ ( p ) \mathbf{S}_j^*(\mathbf{p}) Sj∗(p): 真实的置信度图值。
- W ( p ) \mathbf{W}(\mathbf{p}) W(p): 权重矩阵,用于处理未标注的区域。
关键点连接
在得到置信度图和PAFs后,系统需要通过解析算法将检测到的关键点关联到不同的人。通过计算PAF值与单位向量的点积,系统能够衡量两个关键点之间的关联强度。如果PAF值与单位向量的方向一致,则关联分数较高。
E = ∫ u = 0 u = 1 L c ( p ( u ) ) ⋅ d j 2 − d j 1 ∣ ∣ d j 2 − d j 1 ∣ ∣ 2 d u E = \int_{u=0}^{u=1} \mathbf{L}_c(\mathbf{p}(u)) \cdot \frac{\mathbf{d}_{j_2} - \mathbf{d}_{j_1}}{||\mathbf{d}_{j_2} - \mathbf{d}_{j_1}||_2} du E=∫u=0u=1Lc(p(u))⋅∣∣dj2−dj1∣∣2dj2−dj1du
- E E E: 表示两个关键点 d j 1 \mathbf{d}_{j_1} dj1 和 d j 2 \mathbf{d}_{j_2} dj2 之间的关联分数。
- L c ( p ( u ) ) \mathbf{L}_c(\mathbf{p}(u)) Lc(p(u)): 在位置 p ( u ) \mathbf{p}(u) p(u) 处的PAF值。
- p ( u ) \mathbf{p}(u) p(u): 插值位置,表示从 d j 1 \mathbf{d}_{j_1} dj1 到 d j 2 \mathbf{d}_{j_2} dj2 的线段上的点。
- d j 2 − d j 1 ∣ ∣ d j 2 − d j 1 ∣ ∣ 2 \frac{\mathbf{d}_{j_2} - \mathbf{d}_{j_1}}{||\mathbf{d}_{j_2} - \mathbf{d}_{j_1}||_2} ∣∣dj2−dj1∣∣2dj2−dj1: 单位向量,表示从 d j 1 \mathbf{d}_{j_1} dj1 到 d j 2 \mathbf{d}_{j_2} dj2 的方向。
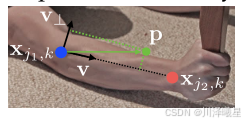
在初始的数据集中,PAF信息(Part Affinity Fields)是需要标注的,因为PAFs是训练OpenPose模型的关键组成部分。PAFs用于表示肢体的连接关系,编码了肢体的位置和方向信息。为了训练模型生成准确的PAFs,数据集中必须包含每个肢体的真实PAF信息。
如上图所示,从蓝点到橙点表示的是前臂的方向,在这之间按照一定的宽度画一个矩形空间代表肢体,矩形空间内都要标上PAF信息,矩形空间为0,如下式所示:
L c , k ∗ ( p ) = { v if p on limb c , k 0 otherwise . \mathbf{L}_{c,k}^*(\mathbf{p}) = \begin{cases} \mathbf{v} & \text{if } \mathbf{p} \text{ on limb } c, k \\ 0 & \text{otherwise}. \end{cases} Lc,k∗(p)={v0if p on limb c,kotherwise.
L c , k ∗ ( p ) \mathbf{L}_{c,k}^*(\mathbf{p}) Lc,k∗(p): 表示第k个人的第 c 个肢体在像素位置 p处的PAF值。
v \mathbf{v} v: 单位向量,表示肢体的方向,从肢体的一端指向另一端。
p \mathbf{p} p : 像素位置。
c , k c, k c,k: 第 k个人的第 c个肢体。
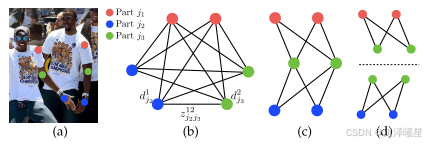
接下来再根据PAF得分来使用匈牙利算法进行二分图匹配即可。
主要代码
- bodypose_model类
class bodypose_model(nn.Module):
def __init__(self):
super(bodypose_model, self).__init__()
# 定义没有ReLU激活函数的层名列表
no_relu_layers = ['conv5_5_CPM_L1', 'conv5_5_CPM_L2', 'Mconv7_stage2_L1',\
'Mconv7_stage2_L2', 'Mconv7_stage3_L1', 'Mconv7_stage3_L2',\
'Mconv7_stage4_L1', 'Mconv7_stage4_L2', 'Mconv7_stage5_L1',\
'Mconv7_stage5_L2', 'Mconv7_stage6_L1', 'Mconv7_stage6_L1']
blocks = {} # 初始化一个空字典,用于存储不同阶段的网络块
# 定义初始阶段的网络结构
block0 = OrderedDict([
('conv1_1', [3, 64, 3, 1, 1]),
('conv1_2', [64, 64, 3, 1, 1]),
('pool1_stage1', [2, 2, 0]),
('conv2_1', [64, 128, 3, 1, 1]),
('conv2_2', [128, 128, 3, 1, 1]),
('pool2_stage1', [2, 2, 0]),
('conv3_1', [128, 256, 3, 1, 1]),
('conv3_2', [256, 256, 3, 1, 1]),
('conv3_3', [256, 256, 3, 1, 1]),
('conv3_4', [256, 256, 3, 1, 1]),
('pool3_stage1', [2, 2, 0]),
('conv4_1', [256, 512, 3, 1, 1]),
('conv4_2', [512, 512, 3, 1, 1]),
('conv4_3_CPM', [512, 256, 3, 1, 1]),
('conv4_4_CPM', [256, 128, 3, 1, 1])
])
# Stage 1
block1_1 = OrderedDict([ # Stage 1 L1部分的网络结构
('conv5_1_CPM_L1', [128, 128, 3, 1, 1]),
('conv5_2_CPM_L1', [128, 128, 3, 1, 1]),
('conv5_3_CPM_L1', [128, 128, 3, 1, 1]),
('conv5_4_CPM_L1', [128, 512, 1, 1, 0]),
('conv5_5_CPM_L1', [512, 38, 1, 1, 0])
])
block1_2 = OrderedDict([ # Stage 1 L2部分的网络结构
('conv5_1_CPM_L2', [128, 128, 3, 1, 1]),
('conv5_2_CPM_L2', [128, 128, 3, 1, 1]),
('conv5_3_CPM_L2', [128, 128, 3, 1, 1]),
('conv5_4_CPM_L2', [128, 512, 1, 1, 0]),
('conv5_5_CPM_L2', [512, 19, 1, 1, 0])
])
blocks['block1_1'] = block1_1 # 将Stage 1 L1部分加入blocks字典
blocks['block1_2'] = block1_2 # 将Stage 1 L2部分加入blocks字典
self.model0 = make_layers(block0, no_relu_layers) # 调用make_layers函数构建初始阶段网络
# Stages 2 - 6
for i in range(2, 7):
blocks['block%d_1' % i] = OrderedDict([ # Stage i L1部分
('Mconv1_stage%d_L1' % i, [185, 128, 7, 1, 3]),
('Mconv2_stage%d_L1' % i, [128, 128, 7, 1, 3]),
('Mconv3_stage%d_L1' % i, [128, 128, 7, 1, 3]),
('Mconv4_stage%d_L1' % i, [128, 128, 7, 1, 3]),
('Mconv5_stage%d_L1' % i, [128, 128, 7, 1, 3]),
('Mconv6_stage%d_L1' % i, [128, 128, 1, 1, 0]),
('Mconv7_stage%d_L1' % i, [128, 38, 1, 1, 0])
])
blocks['block%d_2' % i] = OrderedDict([ # Stage i L2部分
('Mconv1_stage%d_L2' % i, [185, 128, 7, 1, 3]),
('Mconv2_stage%d_L2' % i, [128, 128, 7, 1, 3]),
('Mconv3_stage%d_L2' % i, [128, 128, 7, 1, 3]),
('Mconv4_stage%d_L2' % i, [128, 128, 7, 1, 3]),
('Mconv5_stage%d_L2' % i, [128, 128, 7, 1, 3]),
('Mconv6_stage%d_L2' % i, [128, 128, 1, 1, 0]),
('Mconv7_stage%d_L2' % i, [128, 19, 1, 1, 0])
])
for k in blocks.keys():
blocks[k] = make_layers(blocks[k], no_relu_layers)
# 将各阶段网络赋值给相应的属性
self.model1_1 = blocks['block1_1']
self.model2_1 = blocks['block2_1']
self.model3_1 = blocks['block3_1']
self.model4_1 = blocks['block4_1']
self.model5_1 = blocks['block5_1']
self.model6_1 = blocks['block6_1']
self.model1_2 = blocks['block1_2']
self.model2_2 = blocks['block2_2']
self.model3_2 = blocks['block3_2']
self.model4_2 = blocks['block4_2']
self.model5_2 = blocks['block5_2']
self.model6_2 = blocks['block6_2']
def forward(self, x):
out1 = self.model0(x)
out1_1 = self.model1_1(out1)
out1_2 = self.model1_2(out1)
out2 = torch.cat([out1_1, out1_2, out1], 1) # 1代表沿着第二个维度进行拼接,即channel方向
out2_1 = self.model2_1(out2)
out2_2 = self.model2_2(out2)
out3 = torch.cat([out2_1, out2_2, out1], 1)
out3_1 = self.model3_1(out3)
out3_2 = self.model3_2(out3)
out4 = torch.cat([out3_1, out3_2, out1], 1)
out4_1 = self.model4_1(out4)
out4_2 = self.model4_2(out4)
out5 = torch.cat([out4_1, out4_2, out1], 1)
out5_1 = self.model5_1(out5)
out5_2 = self.model5_2(out5)
out6 = torch.cat([out5_1, out5_2, out1], 1)
out6_1 = self.model6_1(out6)
out6_2 = self.model6_2(out6)
return out6_1, out6_2
- Body类
class Body(object):
def __init__(self, model_path):
self.model = bodypose_model() # 实例化bodypose_model
if torch.cuda.is_available():
self.model = self.model.cuda()
# 加载预训练模型权重并适配到当前模型结构
model_dict = util.transfer(self.model, torch.load(model_path))
self.model.load_state_dict(model_dict)
self.model.eval()
def __call__(self, oriImg):
# scale_search = [0.5, 1.0, 1.5, 2.0]
scale_search = [0.5]
boxsize = 368
stride = 8
padValue = 128
thre1 = 0.1 # 关键点热图阈值
thre2 = 0.05 # PAF(部分亲和场)阈值
multiplier = [x * boxsize / oriImg.shape[0] for x in scale_search]
heatmap_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 19)) # 累加热图
paf_avg = np.zeros((oriImg.shape[0], oriImg.shape[1], 38)) # 累加PAF
for m in range(len(multiplier)):
# 根据multiplier列表中的比例调整图像大小
scale = multiplier[m]
# 对调整大小后的图像进行填充以适配模型输入要求,并获取填充信息
imageToTest = cv2.resize(oriImg, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_CUBIC)
imageToTest_padded, pad = util.padRightDownCorner(imageToTest, stride, padValue)
# 将图像数据转换为浮点型,并调整维度顺序,然后归一化到[-0.5, 0.5]区间
im = np.transpose(np.float32(imageToTest_padded[:, :, :, np.newaxis]), (3, 2, 0, 1)) / 256 - 0.5
im = np.ascontiguousarray(im)
# 将numpy数组转换为PyTorch张量,并根据情况转移到GPU
data = torch.from_numpy(im).float()
if torch.cuda.is_available():
data = data.cuda()
# 使用模型进行前向传播,不计算梯度
with torch.no_grad():
Mconv7_stage6_L1, Mconv7_stage6_L2 = self.model(data)
# 将输出结果转换回numpy数组,并从GPU(如果有)转移回CPU
Mconv7_stage6_L1 = Mconv7_stage6_L1.cpu().numpy()
Mconv7_stage6_L2 = Mconv7_stage6_L2.cpu().numpy()
# 提取并处理热图输出,包括尺寸调整和移除填充
heatmap = np.transpose(np.squeeze(Mconv7_stage6_L2), (1, 2, 0))
heatmap = cv2.resize(heatmap, (0, 0), fx=stride, fy=stride, interpolation=cv2.INTER_CUBIC)
heatmap = heatmap[:imageToTest_padded.shape[0] - pad[2], :imageToTest_padded.shape[1] - pad[3], :]
heatmap = cv2.resize(heatmap, (oriImg.shape[1], oriImg.shape[0]), interpolation=cv2.INTER_CUBIC)
# 提取并处理PAF(部分亲和场)输出,过程与热图相似
paf = np.transpose(np.squeeze(Mconv7_stage6_L1), (1, 2, 0))
paf = cv2.resize(paf, (0, 0), fx=stride, fy=stride, interpolation=cv2.INTER_CUBIC)
paf = paf[:imageToTest_padded.shape[0] - pad[2], :imageToTest_padded.shape[1] - pad[3], :]
paf = cv2.resize(paf, (oriImg.shape[1], oriImg.shape[0]), interpolation=cv2.INTER_CUBIC)
# 将当前尺度下的热图和PAF加权平均到累积的热图和PAF中
heatmap_avg += heatmap_avg + heatmap / len(multiplier)
paf_avg += + paf / len(multiplier)
# 寻找关键点
all_peaks = []
peak_counter = 0
for part in range(18): # 遍历人体的18个关键点
map_ori = heatmap_avg[:, :, part] # 获取当前关键点的热图
one_heatmap = gaussian_filter(map_ori, sigma=3) # 对热图应用高斯滤波以平滑数据
map_left = np.zeros(one_heatmap.shape)
map_left[1:, :] = one_heatmap[:-1, :]
map_right = np.zeros(one_heatmap.shape)
map_right[:-1, :] = one_heatmap[1:, :]
map_up = np.zeros(one_heatmap.shape)
map_up[:, 1:] = one_heatmap[:, :-1]
map_down = np.zeros(one_heatmap.shape)
map_down[:, :-1] = one_heatmap[:, 1:]
# 找到局部极大值(即峰值)
peaks_binary = np.logical_and.reduce(
(one_heatmap >= map_left, one_heatmap >= map_right, one_heatmap >= map_up, one_heatmap >= map_down, one_heatmap > thre1))
peaks = list(zip(np.nonzero(peaks_binary)[1], np.nonzero(peaks_binary)[0])) # note reverse
peaks_with_score = [x + (map_ori[x[1], x[0]],) for x in peaks]
peak_id = range(peak_counter, peak_counter + len(peaks))
peaks_with_score_and_id = [peaks_with_score[i] + (peak_id[i],) for i in range(len(peak_id))]
all_peaks.append(peaks_with_score_and_id)
peak_counter += len(peaks)
# 定义肢体序列和对应于中间关节的heatmap索引
limbSeq = [[2, 3], [2, 6], [3, 4], [4, 5], [6, 7], [7, 8], [2, 9], [9, 10], \
[10, 11], [2, 12], [12, 13], [13, 14], [2, 1], [1, 15], [15, 17], \
[1, 16], [16, 18], [3, 17], [6, 18]]
mapIdx = [[31, 32], [39, 40], [33, 34], [35, 36], [41, 42], [43, 44], [19, 20], [21, 22], \
[23, 24], [25, 26], [27, 28], [29, 30], [47, 48], [49, 50], [53, 54], [51, 52], \
[55, 56], [37, 38], [45, 46]]
connection_all = [] # 存储所有连接
special_k = [] # 存储特殊情况的索引
mid_num = 10 # 中间采样点数量
for k in range(len(mapIdx)):
score_mid = paf_avg[:, :, [x - 19 for x in mapIdx[k]]] # 获取中间关节的PAF
# 获取两个端点的所有候选位置
candA = all_peaks[limbSeq[k][0] - 1] # 计算候选数量
candB = all_peaks[limbSeq[k][1] - 1] # 当前肢体对应的端点编号
# 计算候选数量
nA = len(candA)
nB = len(candB)
# 当前肢体对应的端点编号
indexA, indexB = limbSeq[k]
if (nA != 0 and nB != 0):
connection_candidate = []
for i in range(nA):
for j in range(nB):
vec = np.subtract(candB[j][:2], candA[i][:2])
norm = math.sqrt(vec[0] * vec[0] + vec[1] * vec[1])
norm = max(0.001, norm)
vec = np.divide(vec, norm)
startend = list(zip(np.linspace(candA[i][0], candB[j][0], num=mid_num), \
np.linspace(candA[i][1], candB[j][1], num=mid_num)))
vec_x = np.array([score_mid[int(round(startend[I][1])), int(round(startend[I][0])), 0] \
for I in range(len(startend))])
vec_y = np.array([score_mid[int(round(startend[I][1])), int(round(startend[I][0])), 1] \
for I in range(len(startend))])
score_midpts = np.multiply(vec_x, vec[0]) + np.multiply(vec_y, vec[1])
score_with_dist_prior = sum(score_midpts) / len(score_midpts) + min(
0.5 * oriImg.shape[0] / norm - 1, 0)
criterion1 = len(np.nonzero(score_midpts > thre2)[0]) > 0.8 * len(score_midpts)
criterion2 = score_with_dist_prior > 0
# 满足条件则认为是有效连接
if criterion1 and criterion2:
connection_candidate.append(
[i, j, score_with_dist_prior, score_with_dist_prior + candA[i][2] + candB[j][2]])
connection_candidate = sorted(connection_candidate, key=lambda x: x[2], reverse=True) # 根据得分排序
connection = np.zeros((0, 5)) # 初始化连接矩阵
for c in range(len(connection_candidate)):
i, j, s = connection_candidate[c][0:3]
if (i not in connection[:, 3] and j not in connection[:, 4]):
connection = np.vstack([connection, [candA[i][3], candB[j][3], s, i, j]])
if (len(connection) >= min(nA, nB)):
break
connection_all.append(connection)
else:
special_k.append(k)
connection_all.append([])
# 初始化子集数组
subset = -1 * np.ones((0, 20))
candidate = np.array([item for sublist in all_peaks for item in sublist])
# 处理每一对肢体连接,构建最终的人体结构
for k in range(len(mapIdx)):
if k not in special_k:
partAs = connection_all[k][:, 0]
partBs = connection_all[k][:, 1]
indexA, indexB = np.array(limbSeq[k]) - 1
for i in range(len(connection_all[k])):
found = 0
subset_idx = [-1, -1]
for j in range(len(subset)):
if subset[j][indexA] == partAs[i] or subset[j][indexB] == partBs[i]:
subset_idx[found] = j
found += 1
if found == 1:
j = subset_idx[0]
if subset[j][indexB] != partBs[i]:
subset[j][indexB] = partBs[i]
subset[j][-1] += 1
subset[j][-2] += candidate[partBs[i].astype(int), 2] + connection_all[k][i][2]
elif found == 2:
j1, j2 = subset_idx
membership = ((subset[j1] >= 0).astype(int) + (subset[j2] >= 0).astype(int))[:-2]
if len(np.nonzero(membership == 2)[0]) == 0:
subset[j1][:-2] += (subset[j2][:-2] + 1)
subset[j1][-2:] += subset[j2][-2:]
subset[j1][-2] += connection_all[k][i][2]
subset = np.delete(subset, j2, 0)
else:
subset[j1][indexB] = partBs[i]
subset[j1][-1] += 1
subset[j1][-2] += candidate[partBs[i].astype(int), 2] + connection_all[k][i][2]
elif not found and k < 17:
row = -1 * np.ones(20)
row[indexA] = partAs[i]
row[indexB] = partBs[i]
row[-1] = 2
row[-2] = sum(candidate[connection_all[k][i, :2].astype(int), 2]) + connection_all[k][i][2]
subset = np.vstack([subset, row])
# 删除一些不完整或得分过低的子集
deleteIdx = []
for i in range(len(subset)):
if subset[i][-1] < 4 or subset[i][-2] / subset[i][-1] < 0.4:
deleteIdx.append(i)
subset = np.delete(subset, deleteIdx, axis=0)
return candidate, subset
实验结果
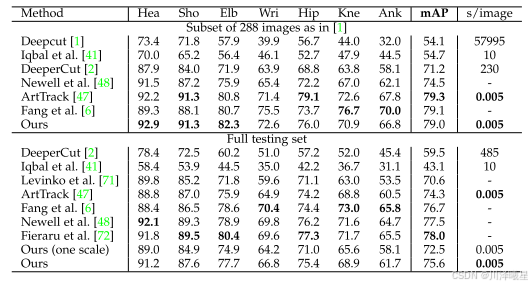
可以看到openpose在各种方法上有这最好的实时性能和相对好的mAP值,比最高的方法只差了2.4%。
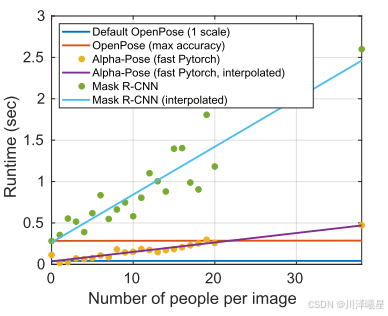
从上图可以看出openpose的多人性能非常优异,在人数增加的前提上运行时间基本上不发生变化。
局限性

- 罕见姿态:系统在处理非常规姿态(如倒立)时表现不佳,增加旋转数据增强可以部分缓解这一问题,但可能会降低整体精度。
- 遮挡问题:当人体关键点被遮挡时,系统容易出现漏检或定位误差。这在高度拥挤的场景中尤为明显,PAFs的重叠可能导致错误的关联。
- 误检:系统有时会将非人类物体(如动物或雕像)误检为人体关键点,增加负样本训练可能有助于减少此类错误。
总结
OpenPose 是一种用于实时多人2D姿态估计的算法,能够检测出图像或视频中人体的关键点位置,如肘部、膝盖和肩膀等。它特别强大之处在于可以同时处理多个人体的姿态估计,并且在不同的环境下都能保持较高的准确性和稳定性。首先,OpenPose 接受图片、视频帧或者其他形式的视觉输入作为处理对象。然后,它会使用卷积神经网络(CNN)对输入的每一个图像进行分析,以提取出与人体姿态相关的关键特征。基于提取到的特征,OpenPose 会为每个可能的身体关键点生成一个热图。这些热图代表了图像中不同位置是某个特定关键点的概率。再接下来生成部分亲和场(PAFs),这是一种描述图像中两个关键点是否属于同一个人的信息。通过PAFs,算法可以有效地将分散的关键点连接成完整的人体骨架。最后,根据之前步骤的结果,OpenPose 输出每个人在图像中的姿态估计结果,通常是以人体骨架的形式展示,其中包含了所有被检测到的关键点的位置信息。