二进制编码、定点数与浮点数
1. 二进制编码
1.1. 字符串的表示,从编码到数字
不仅数值可以用二进制表示,字符乃至更多的信息都能用二进制表示。最典型的例子就是字符串(Character String)。最早计算机只需要使用英文字符,加上数字和一些特殊符号,然后用 8 位的二进制,就能表示我们日常需要的所有字符了,这个就是我们常常说的ASCII 码(American Standard Code for Information Interchange,美国信息交换标准代码)。
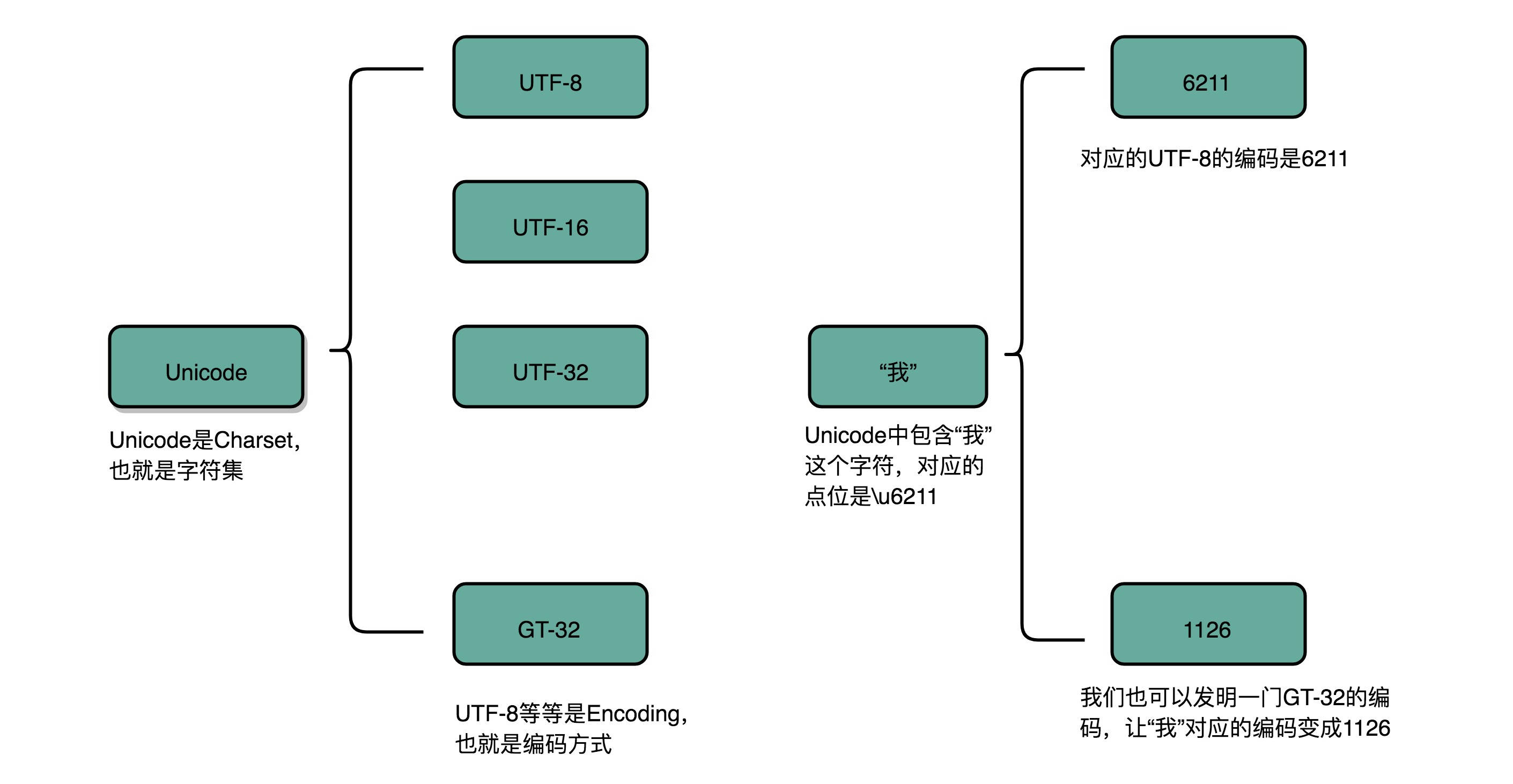
字符集,表示的可以是字符的一个集合。“第一版《新华字典》里面出现的所有汉字”,这是一个字符集。比如,我们日常说的 Unicode,其实就是一个字符集,包含了 150 种语言的 14 万个不同的字符。
而字符编码则是对于字符集里的这些字符,怎么一一用二进制表示出来的一个字典。我们上面说的 Unicode,就可以用 UTF-8、UTF-16,乃至 UTF-32 来进行编码,存储成二进制。
2. 浮点数和定点数
2.1. 浮点数的表示
单精度的 32 个比特可以分成三部分。
第一部分是一个符号位,用来表示是正数还是负数。我们一般用s来表示。在浮点数里,我们不像正数分符号数还是无符号数,所有的浮点数都是有符号的。
接下来是一个 8 个比特组成的指数位。我们一般用e来表示。8 个比特能够表示的整数空间,就是 0~255。我们在这里用 1~254 映射到 -126~127 这 254 个有正有负的数上。因为我们的浮点数,不仅仅想要表示很大的数,还希望能够表示很小的数,所以指数位也会有负数。
最后,是一个 23 个比特组成的有效数位。我们用f来表示。综合科学计数法,我们的浮点数就可以表示成下面这样:
(−1)s×1.f×2e
在这样的表示方式下,浮点数能够表示的数据范围一下子大了很多。正是因为这个数对应的小数点的位置是“浮动”的,它才被称为浮点数。随着指数位 e 的值的不同,小数点的位置也在变动。对应的, BCD 编码的实数,就是小数点固定在某一位的方式,我们也就把它称为定点数。
2.2. 浮点数的二进制转化
我们输入一个任意的十进制浮点数,背后都会对应一个二进制表示。比方说,我们输入了一个十进制浮点数 9.1。那么按照之前的讲解,在二进制里面,我们应该把它变成一个“符号位 s+ 指数位 e+ 有效位数 f”的组合。
2.3. 浮点数的加法和精度损失
先对齐、再计算。
回到浮点数的加法过程,其中指数位较小的数,需要在有效位进行右移,在右移的过程中,最右侧的有效位就被丢弃掉了。这会导致对应的指数位较小的数,在加法发生之前,就丢失精度。两个相加数的指数位差的越大,位移的位数越大,可能丢失的精度也就越大。
2.4. Kahan Summation 算法
虽然我们在计算浮点数的时候,常常可以容忍一定的精度损失,但是像上面那样,如果我们连续加 2000 万个 1,2000 万的数值都会被精度损失丢掉了,就会影响我们的计算结果。
一种叫作Kahan Summation的算法解决了这个问题。
public class KahanSummation {public static void main(String[] args) {float sum = 0.0f;float c = 0.0f;for (int i = 0; i < 20000000; i++) {float x = 1.0f;float y = x - c;float t = sum + y;c = (t-sum)-y;sum = t; }System.out.println("sum is " + sum); }
}这个算法的原理是,在每次的计算过程中,都用一次减法,把当前加法计算中损失的精度记录下来,然后在后面的循环中,把这个精度损失放在要加的小数上,再做一次运算。
这个方法在实际的数值计算中也是常用的,也是大量数据累加中,解决浮点数精度带来的“大数吃小数”问题的必备方案。