protobuf原理和使用
一、protobuf原理
1.协议概述
什么是协议:协议是一种约定,通过约定,不同的进程可以对一段数据产生相同的理解,从而相互协作,存在进程间通信的程序就一定需要协议。

2.判断消息的完整性-区分消息的边界
为了让对端知道如何结束消息分界,通常有以下几种做法:
1. 固定大小字节数拆分
按每个消息固定字节数来划分,例如每个消息 100 个字节,对端每接收 100 个字节,就当成一个消息来解析。
2. 特定符号分界
每个消息以特定的字符结尾(如 \r\n),当在字符流中读取到该字符时,则表明上一个消息到此为止。例如 Redis 协议(key-value 结构,如 get teacher\r\n),服务端读到 \r\n 就认定一个消息结束。
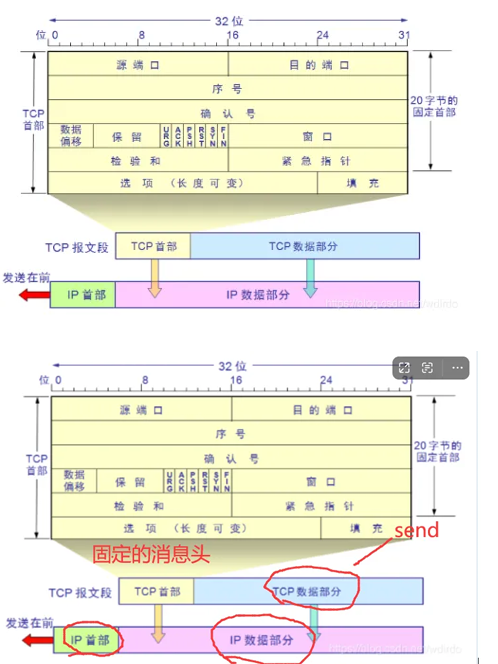
3. 固定消息头 + 消息体结构
消息头是固定字节长度的结构,其中包含一个特定字段来规定消息体的大小。接收消息时,先接收固定字节数的头部,解析出这个消息中消息体的长度,再按此长度接收消息体。这是目前各种网络应用用得最多的一种消息格式(header + body)。
4. 字符流宽度 + 消息总长度判断
在序列化后的 buffer 前面增加一个固定宽度的头部,其中有个字段存储消息总长度。接收时,先判断已收到的数据中是否包含结束符,收到结束符后解析消息头,得出这个消息的完整长度,再按此长度接收消息体。例如 HTTP 和 Redis 采用类似方式(需结合具体协议细节)。
这些方式的核心是让接收方能够明确识别消息的边界,避免因黏包、拆包等问题导致消息解析错误,确保通信双方对消息完整性的认知一致。
3.协议设计
3.1 协议设计范例
3.1.1 范例 1 - IM 即时通讯
即时通讯的协议设计如下:
| 字段 | 类型 | 长度(字节) | 说明 |
|---|---|---|---|
| length | unsigned int | 4 | 整个消息的长度,包括协议头 + BODY |
| version | unsigned short | 2 | 通信协议的版本号 |
| appid | unsigned short | 2 | 对外 SDK 提供服务时,用来识别不同的客户 |
| service_id | unsigned short | 2 | 对应命令的分组类,比如 login 和 msg 是不同分组 |
| command_id | unsigned short | 2 | 分组里面的子命令,比如 login 和 login response |
| seq_num | unsigned short | 2 | 消息序号 |
| reserve | unsigned short | 2 | 预留字节 |
| body | unsigned char[] | n | 具体的协议数据 |
3.1.2 范例 2 - 云平台节点服务器
| 字段 | 类型 | 长度(字节) | 说明 |
|---|---|---|---|
| STAG | unsigned short | 2 | 通信协议数据包的开始标志,如 0xff 0xfe |
| version | unsigned short | 2 | 通信协议的版本号,目前为 0x01 |
| checksum | unsigned char | 1 | 计算协议数据校验和,若为加密数据,则计算密文校验和。校验和计算范围:协议头 CheckSum 字段后数据,协议体全部数据 |
| type | unsigned char | 1 | 0 表示协议体是 json 格式,其它值未定义。设备心跳消息类型的值为 0xA0 |
| seqno | unsigned int | 4 | 通信数据报文的序列号,应答报文序列号必须与请求报文序列号相同 |
| Length | unsigned short | 4 | 报文内容长度,即从该字段后报文内容长度 |
| reserve | unsigned int | 4 | 预留字节,设备心跳消息类型的值为 devid |
| body | unsigned char[] | n | 数据 |
| 具体参考《云平台节点服务器设计说明书_v0.4.10.pdf》。 |
3.1.4 范例 4 - HTTP 协议
HTTP 协议的请求由请求行、请求头、空白行和请求体组成:
- 请求行:
[Method] [url] [Version] \r\n - 请求头:多个
[Key]: [Value] \r\n形式的参数。 - 空白行:
\r\n,表示请求头结束。 - 请求体(Body):实际数据。
不适合作为互联网后台协议的原因:
- HTTP 协议只是一个框架,没有指定包体的序列化方式,还需配合其他序列化方式(如 JSON)才能传递业务逻辑数据。
- HTTP 协议解析效率低,且相对复杂(并非协议本身简单,而是因其广泛使用让人熟悉)。
适用情况:
- 对公网用户开放 API,HTTP 协议的穿透性好。
- 效率要求没那么高的场景。
- 希望提供更多人熟悉的接口,如新浪微博、腾讯微博提供的开放接口。
3.1.5 范例 5 - Redis 协议
基本原理:先发送一个字符串表示参数个数,再逐个发送参数。每个参数发送时,先发送一个字符串表示参数的数据长度,再发送参数内容。
在 RESP 中,数据类型通过第一个字节判断:
- 单行(Simple String)回复:第一个字节是
+。 - 错误(Error)信息:第一个字节是
-。 - 整形数字(Integers):第一个字节是
:。 - 多行字符串(Bulk Strings):第一个字节是
$。 - 数组(Arrays):第一个字节是
*。
此外,RESP 可使用特殊变体表示 NULL 值。协议的不同部分始终以 \r\n(CRLF)结束。具体参考《Redis 协议规范 - 20221011.pdf》。
3.2 序列化方法

序列化和反序列化概念
- 序列化:把对象转换为字节序列的过程。
- 反序列化:把字节序列恢复为对象的过程。
什么情况下需要序列化
- 需将内存中的对象状态保存到文件或数据库时。
- 需通过套接字在网络上传送对象时。
常见的序列化方法
- TLV 编码及其变体:如 Protobuf(tag, length, value 的缩写)。
- 文本流编码:如 XML/JSON。
- 固定结构编码:协议约定传输字段类型和含义,无 tag 和 len,只有 value(如 TCP/IP)。
- 内存 dump:直接输出内存数据,反序列化时直接还原内存,不做序列化操作。
3.2.1 常见序列化方法(主流序列化协议)
- XML(可扩展标记语言):
- 通用且重量级的数据交换格式,以文本方式存储。
- JSON(JS 对象简谱):
- 通用且轻量级的数据交换格式,以文本结构存储。
- Protocol Buffer:
- Google 开发的独立、轻量级数据交换格式,以二进制结构存储。
| 类型 | XML | JSON | Protobuf |
|---|---|---|---|
| 通用性 | 通用 | 通用 | 通用(需编译器生成对应语言代码) |
| 数据长度 | 重量级 | 轻量级 | 轻量级 |
| 格式 | 文本格式 | 文本格式 | 二进制格式 |
范例:一个 Person 对象从客户端发送给服务器,包含以下字段:
- name:姓名(变长字段),如 “湖南长沙零声教育 darren”。
- age:年龄,如 80。
- languages:熟悉技能(普通数组,变长字段),如
[“C/C++”, “Java”, “python”, “go”, “js”]。 - phone:电话号码(嵌套对象),如
{“number”: “18570368134”, “type”: “home”}。 - books:对象数组(变长字段),每本书包含
name和price属性。 - vip:是否为 vip,如
true。 - address:地址,如 “yageguoji”。
文本格式(如 JSON)方便调试,二进制格式(如 Protobuf)则在效率和数据紧凑性上更有优势,不同序列化方式对这些字段的处理结构和效率各有差异。
3.2.2序列化结果数据对⽐
xml

3.2.3 序列化、反序列化速度对⽐ 测试10万次序列化
| 库 / 场景 | 序列化耗时(默认) | 序列化耗时(-O1) | 序列化后字节数 | 反序列化耗时(默认) | 反序列化耗时(-O1) |
|---|---|---|---|---|---|
| cJSON(C) | 488ms | 452ms | 297 | 284ms | 251ms |
| jsoncpp(C++) | 871ms | 709ms | 255 | 786ms | 709ms |
| rapidjson(C++) | 701ms | 113ms | 117 | 1288ms | 953ms |
| tinyxml2(XML) | - | - | - | 1781ms | - |
| protobuf | 241ms | 83ms | 239 | 190ms | 80ms |
说明:
- JSON 序列化后字节数差异与格式排列有关,例如:
{"name":"darren"}(紧凑格式) vs{\n"name": "darren"\n}(带换行缩进)。
- Protobuf 作为二进制协议,在序列化后字节数和耗时上均表现最优。
3.3 协议安全
1. XXTEA 加密算法(固定密钥)
- 简介:XXTEA 是 TEA 的改进版,属于分组密码算法,密钥长度为 128 位(4 个 32 位无符号整数),适合嵌入式系统或资源受限环境。
- 核心代码(C 语言):
#define DELTA 0x9e3779b9 #define MX (((z>>5^y<<2) + (y>>3^z<<4)) ^ ((sum^y) + (key[(p&3)^e] ^ z)))void btea(uint32_t *v, int n, uint32_t const key[4]) {uint32_t y, z, sum;unsigned p, rounds, e;if (n > 1) { // 加密rounds = 6 + 52/n;sum = 0;z = v[n-1];do {sum += DELTA;e = (sum >> 2) & 3;for (p=0; p<n-1; p++) {y = v[p+1];z = v[p] += MX;}y = v[0];z = v[n-1] += MX;} while (--rounds);} else if (n < -1) { // 解密n = -n;rounds = 6 + 52/n;sum = rounds*DELTA;y = v[0];do {e = (sum >> 2) & 3;for (p=n-1; p>0; p--) {z = v[p-1];y = v[p] -= MX;}z = v[n-1];y = v[0] -= MX;sum -= DELTA;} while (--rounds);} } - 使用示例:
uint32_t v[2] = {1, 2}; uint32_t key[4] = {2, 2, 3, 4}; btea(v, 2, key); // 加密 btea(v, -2, key); // 解密
4. Signal Protocol(端到端加密协议)
-
核心特性:
- 前向安全:即使某消息密钥泄露,无法解密历史消息。
- 后向安全:无法通过泄露的密钥预测未来消息密钥。
- 双棘轮算法:结合 KDF 链棘轮(生成消息密钥)和 DH 棘轮(保证密钥随机性)。
-
关键流程:
- X3DH 密钥协商:
- 双方各生成 3 对密钥:身份密钥(长期)、已签名预共享密钥(中期)、一次性预共享密钥(短期)。
- 通过 DH 协议计算初始密钥:
DH = DH(IPK-A, SPK-B) || DH(EPK-A, IPK-B) || DH(EPK-A, SPK-B) || DH(IPK-A, OPK-B) S = KDF(DH) // 衍生消息密钥
- 双棘轮算法:
- KDF 链棘轮:每次迭代生成新消息密钥,前半部分用于下一次迭代,后半部分用于加密消息。
- DH 棘轮:每次消息轮回后更新临时密钥对,确保盐值随机性,防止后向泄露。
- 群组聊天:
- 每个成员生成独立的 KDF 链密钥和签名密钥对。
- 消息加密后通过服务器转发,成员离开时需重新生成所有密钥并同步。
- X3DH 密钥协商:
-
应用场景:WhatsApp、Signal App 等实时通讯应用,确保通讯内容仅收发双方可解密。
3.4 数据压缩
- 适用场景:文本数据(如 JSON/XML)压缩,二进制数据(如图像、视频)压缩收益较低。
- 常用算法:
- deflate:结合 LZ77 和哈夫曼编码,常用于 HTTP 压缩(如 Nginx 默认支持)。
- gzip:基于 deflate,压缩率更高,适合文件压缩。
- LZW:适用于重复性高的文本(如日志),但存在专利限制。
- 实施建议:仅在带宽受限场景启用压缩,避免过度消耗 CPU 资源。
3.5 协议升级
- 版本号机制:
- 在协议头部添加
version字段(如 2 字节无符号整数),明确协议版本。 - 示例:
| 4字节 length | 2字节 version | 2字节 service_id | ... |
- 在协议头部添加
- 头部可扩展性:
- 在头部添加
extend_length字段,标识扩展头部长度,支持新增字段而不破坏旧协议。 - 结构:
固定头部(12字节) + 扩展头部(extend_length 字节) + 消息体 - 例:
固定头部:| magic(4) | version(2) | extend_len(2) | ... | 扩展头部:| new_field1(4) | new_field2(4) | ... |
- 在头部添加
4. Protobuf 的使用
Protocol Buffers(简称 Protobuf)是 Google 开发的语言中立、平台无关的高效序列化格式,广泛用于通信协议、数据存储等场景。其核心优势包括:
- 高效性:二进制格式,序列化后体积小、解析速度快。
- 强类型:通过
.proto文件定义数据结构,类型安全且易于维护。 - 扩展性:支持字段新增和旧版本兼容,无需重新部署系统。
4.1 Protobuf 协议的工作流程
- 定义数据结构:通过
.proto文件(IDL,接口描述语言)定义消息类型和字段。syntax = "proto3"; package example; message Person {string name = 1;int32 age = 2;repeated string emails = 3; } - 生成代码:使用
protoc编译器根据.proto文件生成对应语言的序列化 / 反序列化代码(如 C++ 的.pb.cc和.pb.h)。 - 序列化 / 反序列化:通过生成的代码对消息对象进行编码(写入文件或网络传输)和解码(读取解析)。
4.2 Protobuf 的编译安装(以 C++ 为例)
1. 下载与解压
- 官方仓库:https://github.com/protocolbuffers/protobuf
tar zxf protobuf-cpp-3.19.6.tar.gz
cd protobuf-3.19.6
2. 编译与安装
./configure # 配置编译选项
make # 编译(耗时较长,需耐心等待)
sudo make install # 安装到系统路径
sudo ldconfig # 更新动态链接库缓存
3. 验证安装
protoc --version # 应输出版本号(如 3.19.6)
4. 生成代码
-I:指定.proto文件所在路径(可多次指定,按顺序查找)。--cpp_out:指定生成的 C++ 代码输出路径。
5. 编译示例程序
g++ -std=c++11 -o my_app my_app.cc message.pb.cc -lprotobuf -lpthread -L/usr/local/lib
-lprotobuf:链接 Protobuf 库。-L/usr/local/lib:指定库文件路径(若安装在其他路径需调整)。
4.3 优化选项(option optimize_for)
.proto 文件可通过 option optimize_for 配置生成代码的优化级别(文件级选项):
| 选项 | 特点 | 适用场景 |
|---|---|---|
SPEED | 生成代码运行效率高,编译后体积较大(默认选项)。 | 高性能场景(如服务器端) |
CODE_SIZE | 生成代码体积小,运行效率较低。 | 资源受限场景(如嵌入式设备) |
LITE_RUNTIME | 兼顾效率和体积,但移除反射功能,仅需链接 libprotobuf-lite 库。 | 移动端或对体积敏感的场景 |
示例:
option optimize_for = LITE_RUNTIME; // 启用轻量级运行时
4.4 标量数值类型与编码规则
Protobuf 支持多种标量类型,不同类型在序列化时采用不同的编码方式,影响存储效率和性能。
.proto 类型 | C++ 类型 | 编码方式 | 适用场景 |
|---|---|---|---|
double | double | 定长(8 字节) | 浮点数值,对精度要求高的场景(如坐标、金额) |
float | float | 定长(4 字节) | 浮点数值,精度要求较低时(如概率、比例) |
int32 | int32 | 变长 | 非负数或小范围整数(若存在负数,优先使用 sint32) |
uint32 | uint32 | 变长 | 无符号整数 |
int64 | int64 | 变长 | 大范围整数(若存在负数,优先使用 sint64) |
sint32 | int32 | 变长(ZigZag) | 有符号整数(负数编码效率高于 int32) |
sint64 | int64 | 变长(ZigZag) | 大范围有符号整数 |
fixed32 | uint32 | 定长(4 字节) | 数值常大于 228 的无符号整数(如哈希值、版本号) |
fixed64 | uint64 | 定长(8 字节) | 数值常大于 256 的无符号整数(如时间戳、文件大小) |
bool | bool | 变长(0 或 1) | 布尔值 |
string | std::string | 变长(UTF-8) | 文本数据(如用户名、地址) |
bytes | std::string | 变长(二进制) | 任意字节数据(如图像、压缩数据) |
编码规则说明:
- 变长编码(Varint):适用于小数值,每个字节最高位为标志位(0 表示结束,1 表示继续)。例如,数值
1编码为0x01,数值300编码为0xAC 0x02。 - 定长编码:无论数值大小,固定占用字节数(如
fixed32始终占 4 字节),适合存储大数值或需要快速读取的场景。 - ZigZag 编码:将有符号整数映射为无符号数,避免负数在变长编码中占用更多字节(如
-1编码为0xFFFFFFFF,即0xFF 0xFF 0xFF 0xFF)。
4.5 反射机制(高级特性)
Protobuf 支持运行时反射,允许通过代码动态操作消息字段(如根据字段名读写值),适用于通用框架或插件系统。
核心类与接口
google::protobuf::Message:所有消息的基类,提供GetDescriptor()和GetReflection()接口获取元信息。google::protobuf::Descriptor:描述消息的结构(字段名、类型、标签等)。google::protobuf::Reflection:提供动态读写字段的方法(如GetInt32()、SetString())。
应用场景
- 通用日志系统:动态记录不同类型的消息字段。
- 网络传输:通过消息名动态解析接收到的数据包。
- 配置系统:根据配置文件动态生成消息对象。
注意:反射会增加运行时开销,且启用 LITE_RUNTIME 优化时反射功能不可用。
5 Protobuf 编码原理
Protobuf 采用高效的二进制编码,核心目标是减少数据存储空间并提升解析速度。以下是其核心编码原理的详细解析:
5.1 Varints 编码(变长整型)
核心思想
- 动态分配字节:根据数值大小动态分配字节数,小数值占用少字节,大数值占用多字节。
- Base128 编码:每个字节的最高位(MSB)为标志位,剩余 7 位存储数据:
- 标志位为 1:后续还有字节。
- 标志位为 0:当前字节是最后一个字节。
- 小端序存储:低字节在前,高字节在后。
编码示例
-
正数示例:数字 1
- 二进制:
00000001(仅 1 字节,标志位为 0)。 - 编码结果:
0x01。
- 二进制:
-
较大数示例:数字 666
- 十进制转二进制:
666 = 256×2 + 154 = 00000010 10011010(8 位)。 - 按 7 位拆分:
10011010(低 7 位)、0000001(高 1 位补前导 0)。 - 标志位补位:
10011010(标志位 1,后续有字节)、00000010(标志位 0,最后一个字节)。 - 编码结果(十六进制):
0xAA 0x02。
- 十进制转二进制:
-
大数示例:0xFFFFFFFF(4 字节整数)
- 二进制:32 位全 1,按 7 位拆分需 5 字节(32/7≈4.57,向上取整)。
- 编码结果:5 字节,每个字节标志位均为 1(前 4 字节),最后一字节标志位为 0。
优缺点与适用场景
- 优点:小数值(≤28bit)存储效率极高,节省空间。
- 缺点:大数值(>28bit)可能比固定长度编码更占空间(如 32bit 整数需 5 字节 vs. fixed32 的 4 字节)。
- 适用场景:非负数、小整数(如枚举值、计数器)。
5.2 Zigzag 编码(负数优化)
问题背景
- 负数在 Varints 中的低效性:
- int32 类型的负数(如 -5)在 Protobuf 中会被视为无符号数,高字节全为 1,导致 Varints 编码需 10 字节。
- 示例:-5 的补码为
0xFFFFFFFF...FB,编码后为0xFB 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0x01(10 字节)。
解决方案:Zigzag 映射
- 核心思想:将负数映射为正数,使高位全为 0,再使用 Varints 编码。
- 正向变换(编码):
// 32位:n << 1 ^ (n >> 31) // 64位:n << 1 ^ (n >> 63) sint32 n = -5; uint32 encoded = (n << 1) ^ (n >> 31); // n >> 31 对负数为 0xFFFFFFFF(32个1)- 例:-5 → 编码后为
0xA(二进制1010),Varints 编码仅需 1 字节。
- 例:-5 → 编码后为
- 逆向变换(解码):
// 32位:(n >> 1) ^ -(n & 1) int32 decoded = (encoded >> 1) ^ (-(encoded & 1));
效果对比
| 类型 | 数值 | 编码后字节数 | 说明 |
|---|---|---|---|
| int32 | -5 | 10 字节 | 直接 Varints 编码 |
| sint32 | -5 | 2 字节 | Zigzag + Varints 编码 |
适用场景
- 有符号整数(尤其是负数),如温度差值、账户余额变动等。
- 推荐使用
sint32/sint64替代int32/int64存储负数。
5.3 固定长度编码(Fixed32/Fixed64)
原理
- 定长存储:无论数值大小,固定占用 4 字节(fixed32/sfixed32/float)或 8 字节(fixed64/sfixed64/double)。
- 适用场景:
- 大数值(>28bit 的无符号数,如哈希值、时间戳)。
- 需快速读取的场景(如索引字段)。
对比 Varints
| 场景 | Varints(int32) | fixed32 |
|---|---|---|
| 数值 ≤ 28bit | 1-4 字节(高效) | 4 字节(低效) |
| 数值 > 28bit 且为正 | 5 字节 | 4 字节(高效) |
| 负数 | 10 字节 | 不适用 |
5.4 长度分隔类型(Length-Delimited)
原理
- TLV 结构:
- T(Type=2):标识字段类型为长度分隔。
- L(Length):4 字节变长整数,标识值(V)的字节数。
- V(Value):具体数据(如字符串、字节数组、嵌套消息)。
- 示例:字符串
"hello"(UTF-8 编码,长度 5)- 编码:
0xA(Type=2,Length=5) +"hello"的字节数据。
- 编码:
适用场景
- 变长数据类型:
string、bytes、嵌套消息(message)、打包的重复字段(packed repeated)。
5.5 编码类型总结
| 类型 | Protobuf 类型 | 编码方式 | 适用场景 |
|---|---|---|---|
| Varints | int32/uint32/int64/uint64/bool/enum | Base128 变长 | 小整数、非负数、枚举值 |
| Zigzag | sint32/sint64 | Zigzag + Varints | 有符号整数(尤其是负数) |
| 固定 32 | fixed32/sfixed32/float | 4 字节定长 | 大整数(>28bit)、浮点数 |
| 固定 64 | fixed64/sfixed64/double | 8 字节定长 | 极大整数(>56bit)、双精度浮点数 |
| 长度分隔 | string/bytes/message/repeated | TLV(Type=2) | 变长字符串、二进制数据、嵌套消息 |
5.6 编码选择建议
- 优先使用 Varints:对于非负数、小整数(如用户 ID、计数器)。
- 负数用 sint32/sint64:避免 int32/int64 对负数的低效编码。
- 大整数用 fixed32/fixed64:如时间戳(秒级时间戳用 fixed32 仅需 4 字节)。
- 字符串 / 嵌套消息用长度分隔:确保数据边界清晰,支持动态长度。
二、protobuf语法详解
1. 定义消息类型基础
1.1 语法声明
- 语法版本:proto3 语法需在文件首行声明
syntax = "proto3";,否则默认使用 proto2。- 示例:
syntax = "proto3"; message SearchRequest {string query = 1;int32 page_number = 2;int32 result_per_page = 3; }1.2 字段组成
- 字段结构:
类型 字段名 = 标识号;
- 类型:标量类型(如
string、int32)或自定义消息类型。- 标识号:唯一整数,用于二进制编码,不可修改。范围:1~536,870,911,禁止使用 19000~19999(预留段)。
2. 字段类型与规则
2.1 标量类型映射
.proto 类型 C++ 类型 Java 类型 说明 doubledoubledouble64 位浮点数 int32int32int变长编码,负数效率低,建议用 sint32stringstringStringUTF-8 或 ASCII 编码文本 bytesstringByteString任意二进制数据 2.2 字段规则
- singular:0 或 1 个值(默认规则,不可显式声明)。
- repeated:0 或多个值,顺序保留,标量类型默认启用
packed压缩。repeated int32 scores = 4; // 可重复字段3. 枚举类型(Enum)
3.1 定义与规则
- 语法:
message SearchRequest {enum Corpus {UNIVERSAL = 0; // 必须以0开头(默认值)WEB = 1;IMAGES = 2;}Corpus corpus = 4; // 使用枚举字段 }- 注意:
- 枚举值需唯一,首值必须为 0(作为默认值)。
- 允许别名(
allow_alias = true),但需显式声明。3.2 兼容性
- 未识别的枚举值在反序列化时保留,不同语言处理方式不同(如 C++ 存储为整数,Java 通过特殊类型表示)。
4. 消息定义进阶
4.1 嵌套类型
- 语法:在消息内部定义其他消息类型。
message SearchResponse {message Result { // 嵌套消息string url = 1;string title = 2;}repeated Result results = 1; // 外部使用:ParentType.NestedType }4.2 Any 类型(动态消息)
- 用途:无需预先定义即可存储任意消息类型,需导入
google/protobuf/any.proto。import "google/protobuf/any.proto"; message ErrorStatus {repeated google.protobuf.Any details = 2; // 存储任意消息 }- 实现:通过 URL 标识类型(如
type.googleapis.com/packagename.messagename),支持动态打包 / 解包。5. 数据结构与特殊字段
5.1 Oneof(互斥字段)
- 用途:确保同一时间只有一个字段被设置,节省内存。
message SampleMessage {oneof test_oneof {string name = 4;SubMessage sub_message = 9; // 设置其中一个会清除另一个} }- 注意:不支持
repeated,反射 API 可用,需避免内存泄漏(如 C++ 中需注意指针管理)。5.2 Map(键值对)
- 语法:
map<string, Project> projects = 3; // 键为string,值为自定义消息- 特性:
- 序列化顺序不确定,文本格式按键排序。
- 重复键以最后一个为准,兼容旧版本(视为
repeated MapFieldEntry)。6. 版本兼容性与更新规则
6.1 安全更新操作
- 允许操作:
- 添加新字段(旧版本解析时忽略,默认值处理)。
- 删除字段(标记为
deprecated,保留标识号)。- 兼容类型转换(如
int32与uint32、bool与int32)。6.2 禁止操作
- 修改已有字段的标识号。
- 混用
sint32与其他整数类型(不兼容)。- 删除
repeated字段并替换为非repeated字段。7. 代码生成与语言特性
7.1 生成文件结构
- C++:生成
.h和.cc,每个消息对应一个类。- Java:生成
.java和Builder类,支持流式构建。- Python:生成模块,通过描述符动态创建类。
- Go:生成
.pb.go,支持结构体和方法绑定。7.2 优化选项(
optimize_for)
- SPEED:默认,生成高性能代码(序列化 / 解析最快)。
- CODE_SIZE:代码体积小,适用于大量消息定义的场景。
- LITE_RUNTIME:轻量级运行时,不含反射功能,适合移动端。
option optimize_for = LITE_RUNTIME; // 启用轻量级模式8. 高级特性与其他
8.1 包声明(
package)
- 用途:避免命名冲突,影响生成代码的命名空间 / 包名。
package foo.bar; // C++对应命名空间foo::bar,Java对应包com.foo.bar(需配合java_package)8.2 服务定义(RPC 支持)
- 语法:定义 RPC 服务接口,配合 gRPC 等框架生成代码。
service SearchService {rpc Search(SearchRequest) returns(SearchResponse); // 定义远程方法 }8.3 JSON 映射
- 规则:proto3 支持自动 JSON 编码 / 解码,字段名映射为驼峰式(如
page_number→pageNumber)。
bytes→Base64 字符串,enum→枚举名,map→JSON 对象。9. 选项(Options)与保留字段
9.1 常用选项
- 文件选项:
java_package:指定 Java 包名。cc_enable_arenas:启用 C++ 内存池优化。- 字段选项:
deprecated=true:标记字段废弃,生成代码中添加警告。9.2 保留字段(
reserved)
- 用途:防止字段标识号或名称被重用,避免版本冲突。
message Foo {reserved 2, 15, 9 to 11; // 保留标识号reserved "foo", "bar"; // 保留字段名(影响JSON序列化) }
三、具体使用案例
1. 定义
.proto文件(user.proto)syntax = "proto3";package demo; // 包名,影响生成的命名空间// 定义用户消息类型 message User {string name = 1; // 姓名(字符串)int32 age = 2; // 年龄(整数)string email = 3; // 邮箱(字符串) }2. 生成 C++ 代码
安装 Protobuf 编译器(protoc)
# Ubuntu/Debian sudo apt-get install protobuf-compiler libprotobuf-dev# 验证安装 protoc --version # 应输出版本号(如 3.19.6)生成代码
protoc --cpp_out=. user.proto # 生成 user.pb.h 和 user.pb.cc3. C++ 代码实现(main.cpp)
#include <iostream> #include "user.pb.h" // 包含生成的头文件using namespace std; using namespace demo; // 使用定义的包名// 序列化消息到文件 bool SerializeToFile(const User& user, const string& filename) {fstream output(filename, ios::out | ios::binary);if (!user.SerializeToOstream(&output)) {cerr << "Failed to serialize User." << endl;return false;}cout << "Serialized data to " << filename << endl;return true; }// 从文件反序列化消息 bool ParseFromFile(User& user, const string& filename) {fstream input(filename, ios::in | ios::binary);if (!user.ParseFromOstream(&input)) {cerr << "Failed to parse User from file." << endl;return false;}cout << "Parsed data from " << filename << endl;return true; }int main() {// 创建 User 对象并设置字段User user;user.set_name("Alice");user.set_age(30);user.set_email("alice@example.com");// 序列化到文件SerializeToFile(user, "user.bin");// 反序列化从文件User parsed_user;if (ParseFromFile(parsed_user, "user.bin")) {// 验证字段值cout << "Parsed Name: " << parsed_user.name() << endl;cout << "Parsed Age: " << parsed_user.age() << endl;cout << "Parsed Email: " << parsed_user.email() << endl;}return 0; }4. 编译与运行
编译命令
g++ -std=c++11 main.cpp user.pb.cc -lprotobuf -o protobuf_demo
-lprotobuf:链接 Protobuf 库。user.pb.cc:生成的实现文件。运行结果
./protobuf_demo输出:
Serialized data to user.bin Parsed data from user.bin Parsed Name: Alice Parsed Age: 30 Parsed Email: alice@example.com5. 代码解析
关键步骤说明
消息定义:
.proto文件中声明User消息,包含三个字段(name、age、- 每个字段有唯一标识号(
1、2、3),用于二进制编码。代码生成:
protoc编译器根据.proto生成user.pb.h和user.pb.cc,包含消息类的定义和序列化 / 反序列化方法。序列化:
SerializeToOstream:将User对象序列化为二进制流,写入文件。- Protobuf 使用高效的二进制格式(如 Varints 编码整数,长度分隔字符串)。
反序列化:
ParseFromOstream:从文件读取二进制数据,解析为User对象。- 自动处理字段的类型转换和默认值(如未设置的字段使用默认值)。
字段访问:
- 通过生成的访问器(如
set_name、name())操作字段,类型安全且高效。6. 扩展说明
- 嵌套消息:若需定义复杂结构,可在
.proto中嵌套消息:message Address {string city = 1;string street = 2; } message User {string name = 1;Address address = 2; // 嵌套消息字段 }- 枚举类型:用于限制字段取值范围:
enum Gender {GENDER_UNKNOWN = 0;GENDER_MALE = 1;GENDER_FEMALE = 2; } message User {Gender gender = 4; // 使用枚举字段 }- 重复字段:处理数组或列表:
message User {repeated string hobbies = 5; // 可重复字段(列表) }
0voice · GitHub