如何处理 collation 导致的索引失效 | OceanBase SQL调优实践
OceanBase 的社区论坛中常有关于性能调优方面的问题。为了方便更多用户能掌握相关的调优技能,将论坛中遇到的相关问题记录下来并进行总结和分享。期待我们能够一起学习,共同成长!
基础背景知识
在聊这个调优问题之前,需要先简单介绍几个和数据库相关的基础知识,就是 charset(字符集)和 collation(字符排序规则或者叫比较规则)的概念,以及 leading 和 use_nl 这两种常见 hint。已经了解的同学可以直接跳过这段内容。
charset
简单来说,charset 会定义字符如何被编码和存储。例如
- 当 charset 为 utf-8 时,大写字母 "A" 会被编码为 1 个字节:0100 0001(也就是十六进制的 0x41);
- 当 charset 为 utf-16 时,大写字母 "A" 被编码为 2 个字节:0000 0100 0000 0001(也就是十六进制 0x0041)。
不同的字符集支持存储的字符种类和范围也有所不同,例如 utf-8 字符集可以存储 Unicode 字符,而 latin1 字符集只能存储西欧语言字符。
collation
collation 是 charset 的一个属性,用来定义字符的比较和排序方式。例如当 charset 被设置为 utf8mb4 时,可选的 collation 就会有 utf8mb4_general_ci、utf8mb4_bin、utf8mb4_unicode_ci 等等。
- utf8mb4_general_ci:不区分大小写的通用排序规则(ci 是 case insensitive 的意思,即不区分大小写);
- utf8mb4_bin:基于二进制比较,区分大小写的排序规则;
- utf8mb4_unicode_ci:基于 Unicode 的,不区分大小写的排序规则。
- utf8 下还有很多针对各种不同语言的排序规则,例如根据汉语拼音排序的 utf8mb4_zh_pinyin_ci 等等。
charset 和 collation 是一对多的关系,一种 collation 属于且仅属于一种 charset。例如定义一个列为 c3 varchar(200) COLLATE utf8mb4_bin 时,这个列的 charset 就会自动被设置为 utf8mb4。
常用 Hint
与其他数据库的行为相比,OceanBase 数据库优化器是动态规划的,已经考虑了所有可能的最优路径。Hint 主要作用是让用户能够显式指定优化器的行为,并按照 Hint 执行 SQL 查询。
这里只简单介绍两个最常用的 Hint,一个叫 leading,一个叫 USE_NL:
- LEADING Hint 可以指定表的联接顺序。语法是:
/*+ LEADING(table_name_list)*/。在 table_name_list 中可以使用()表示内部各表的联接优先级,指定复杂的联接顺序,比 ordered 有更大的灵活性。示例如下:
-- 注意:为确保按照用户指定的顺序进行联接,LEADING Hint 的检查比较严格:
-- 如果发现 Hint 指定的 table_name 不存在,LEADING Hint 不会生效。
-- 如果发现 Hint 中存在重复表,LEADING Hint 也不会生效。EXPLAIN BASIC SELECT /*+LEADING(d c b a)*/ * FROM t1 a, t1 b, t1 c, t1 d;
+------------------------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------------------------+
| ========================================= |
| |ID|OPERATOR |NAME| |
| ----------------------------------------- |
| |0 |NESTED-LOOP JOIN CARTESIAN | | |
| |1 |├─NESTED-LOOP JOIN CARTESIAN | | |
| |2 |│ ├─NESTED-LOOP JOIN CARTESIAN | | |
| |3 |│ │ ├─TABLE FULL SCAN |d | |
| |4 |│ │ └─MATERIAL | | |
| |5 |│ │ └─TABLE FULL SCAN |c | |
| |6 |│ └─MATERIAL | | |
| |7 |│ └─TABLE FULL SCAN |b | |
| |8 |└─MATERIAL | | |
| |9 | └─TABLE FULL SCAN |a | |
| ========================================= |
+------------------------------------------------------------------------------------------------------+EXPLAIN BASIC SELECT /*+LEADING((d c) (b a))*/ * FROM t1 a, t1 b, t1 c, t1 d;
+------------------------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------------------------+
| ========================================= |
| |ID|OPERATOR |NAME| |
| ----------------------------------------- |
| |0 |NESTED-LOOP JOIN CARTESIAN | | |
| |1 |├─NESTED-LOOP JOIN CARTESIAN | | |
| |2 |│ ├─TABLE FULL SCAN |d | |
| |3 |│ └─MATERIAL | | |
| |4 |│ └─TABLE FULL SCAN |c | |
| |5 |└─MATERIAL | | |
| |6 | └─NESTED-LOOP JOIN CARTESIAN | | |
| |7 | ├─TABLE FULL SCAN |b | |
| |8 | └─MATERIAL | | |
| |9 | └─TABLE FULL SCAN |a | |
| ========================================= |
+------------------------------------------------------------------------------------------------------+EXPLAIN BASIC SELECT /*+LEADING((d c b) a))*/ * FROM t1 a, t1 b, t1 c, t1 d;
+------------------------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------------------------+
| ========================================= |
| |ID|OPERATOR |NAME| |
| ----------------------------------------- |
| |0 |NESTED-LOOP JOIN CARTESIAN | | |
| |1 |├─NESTED-LOOP JOIN CARTESIAN | | |
| |2 |│ ├─NESTED-LOOP JOIN CARTESIAN | | |
| |3 |│ │ ├─TABLE FULL SCAN |d | |
| |4 |│ │ └─MATERIAL | | |
| |5 |│ │ └─TABLE FULL SCAN |c | |
| |6 |│ └─MATERIAL | | |
| |7 |│ └─TABLE FULL SCAN |b | |
| |8 |└─MATERIAL | | |
| |9 | └─TABLE FULL SCAN |a | |
| ========================================= |
+------------------------------------------------------------------------------------------------------+- 在 USE_NL 中指定的表如果是 Join 的右表,在 Join 的时候会使用 Nested Loop Join 算法,语法是:
/*+ USE_NL(table_name_list)*/。示例如下:
CREATE TABLE t0(c1 INT, c2 INT, c3 INT);CREATE TABLE t1(c1 INT, c2 INT, c3 INT);CREATE TABLE t2(c1 INT, c2 INT, c3 INT);-- 如果想让 join 的顺序是 t0 join t1,join 为 nest loop join,则应该这样写 hint:
EXPLAIN BASIC SELECT /*+ LEADING(t0 t1) USE_NL(t1) */ * FROM t0, t1 WHERE t0.c1 = t1.c1;
+--------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------+
| ============================= |
| |ID|OPERATOR |NAME| |
| ----------------------------- |
| |0 |NESTED-LOOP JOIN | | |
| |1 |├─TABLE FULL SCAN |t0 | |
| |2 |└─MATERIAL | | |
| |3 | └─TABLE FULL SCAN|t1 | |
| ============================= |
+--------------------------------------------------------------------------------------------+-- 如果想让 join 的顺序是 t0 join (t1 join t2),且想让最外层的 join 为 nest loop join,则应该这样写 hint:
EXPLAIN BASIC SELECT /*+ LEADING(t0 (t1 t2)) USE_NL((t1 t2)) */ * FROM t0, t1, t2 WHERE t0.c1 = t1.c1 AND t0.c1 = t2.c1;
+-----------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------------------------------------------------------------+
| =============================== |
| |ID|OPERATOR |NAME| |
| ------------------------------- |
| |0 |NESTED-LOOP JOIN | | |
| |1 |├─TABLE FULL SCAN |t0 | |
| |2 |└─MATERIAL | | |
| |3 | └─HASH JOIN | | |
| |4 | ├─TABLE FULL SCAN|t1 | |
| |5 | └─TABLE FULL SCAN|t2 | |
| =============================== |
+-----------------------------------------------------------------------------------------------------------------------+
注意
USE_NL、USE_HASH、USE_MERGE 这三个 hint 往往会配合 LEADING 这个 hint 一起使用。因为当 join 的右表匹配table_name_list时,才会按照 hint 语义生成计划。
前面这句话理解起来可能不是那么直观,接下来,我们来举一个最简单的小例子。假设用户希望对一条 SQL:SELECT * FROM t1, t2 WHERE t1.c1 = t2.c1;中t1 join t2对应计划中的 join 计算方式进行干预。
原本的计划空间有六种,分别是:
• t1 nest loop join t2
• t1 hash join t2
• t1 merge join t2
• t2 nest loop join t1
• t2 hash join t1
• t2 merge join t1
如果加了 hint:/*+ USE_NL(t1)*/,则计划空间减少为四种,分别是:
• t1 nest loop join t2
• t1 hash join t2
• t1 merge join t2
• t2 nest loop join t1
因为计划空间中,只有当t1为 join 的右表时,才会按照 hint 生成t2 nest loop join t1的计划;当t1为 join 的左表时,则不受这个 hint 的影响。
如果加了hint:/*+ LEADING(t2 t1) USE_NL(t1)*/,计划空间就只有确定的一种:t2 nest loop join t1
问题描述
铺垫了这么久,终于可以描述下这个前两天遇到的比较有意思的问题了!下面为方便大家理解,会对问题进行一些简化(原问题链接在这里)。问题大致是说有两张表 t1 和 t2:
- t1 表的 c3 列是 varchar,charset 是 utf8mb4,collation 是 utf8mb4_bin;
- t2 表的 c3 列也是 varchar, charset 也是 utf8mb4,但 collation 是 charset 默认的 collation utf8mb4_general_ci。
create table t1(c1 int primary key,c2 int unique key,c3 varchar(200) COLLATE utf8mb4_bin) DEFAULT CHARSET = utf8mb4;create table t2(c1 int primary key,c2 int,c3 varchar(200),key idx(c3)) DEFAULT CHARSET = utf8mb4;然后需要对两张表的 c3 列进行 join,但 join 之后发现没能利用上 t2 表的索引 idx。加/*+leading(t1 t2) use_nl(t2)*/ 这个 hint 是为了还原用户描述的计划,含义是强制让这个 join 是 nest loop join,并且连接顺序是 t1 join t2(即 t2 是 join 的右表)。
explain
select /*+leading(t1 t2) use_nl(t2)*/ * from t1 join t2 on t1.c3 = t2.c3where t1.c2 = 123;
+--------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------+
| ===================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------------- |
| |0 |NESTED-LOOP JOIN | |1 |11 | |
| |1 |├─TABLE RANGE SCAN |t1(c2)|1 |7 | |
| |2 |└─MATERIAL | |1 |5 | |
| |3 | └─TABLE FULL SCAN|t2 |1 |4 | |
| ===================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2], [t1.c3], [t2.c1], [t2.c2], [t2.c3]), filter(nil), rowset=16 |
| conds([t1.c3 = cast(t2.c3, VARCHAR(1048576))]), nl_params_(nil), use_batch=false |
| 1 - output([t1.c1], [t1.c3], [t1.c2]), filter(nil), rowset=16 |
| access([t1.c1], [t1.c3], [t1.c2]), partitions(p0) |
| is_index_back=true, is_global_index=false, |
| range_key([t1.c2], [t1.shadow_pk_0]), range(123,MIN ; 123,MAX), |
| range_cond([t1.c2 = 123]) |
| 2 - output([t2.c1], [t2.c2], [t2.c3]), filter(nil), rowset=16 |
| 3 - output([t2.c1], [t2.c3], [t2.c2]), filter(nil), rowset=16 |
| access([t2.c1], [t2.c3], [t2.c2]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t2.c1]), range(MIN ; MAX)always true |
+--------------------------------------------------------------------------------------------+大家可以看到,在执行 nest loop join 的过程中,左表 t1 每拿出一行数据后,t2 表无法利用 idx 这个索引快速定位这一行数据,而是需要进行全表扫(TABLE FULL SCAN),导致 SQL 执行效率很低。
问题分析
两个表的 c3 列都是 varchar 类型,charset 也相同,那为啥走不上索引?
这个问题猛一看确实有点儿奇怪。但仔细想想也能解释的通,就是因为这个 collation 搞的鬼!例如向两张表里各插入相同的四行数据 A、a、B、b,那么由于 collation 不同,就会导致排序结果不同:
-- t1 表认为:A < B < a < b
obclient [test]> select c3 from t1 order by c3;
+------+
| c3 |
+------+
| A |
| B |
| a |
| b |
+------+
4 rows in set (0.002 sec)-- t2 表认为:A <= a < B <= b
obclient [test]> select c3 from t2 order by c3;
+------+
| c3 |
+------+
| A |
| a |
| B |
| b |
+------+
4 rows in set (0.001 sec)那么 t2 表上的索引 idx 上的数据就会是 A、a、B、b 这个顺序。如果拿着 t1 表的 B 值去 t2 表的索引 idx 上进行探测,就会先和 idx 上的 A 值比较,发现 B > A,那么就需要继续比较 idx 上的下一个值 a,按照 t1 表 B 值的 collation,就会发现 B < a,那就没必要继续探测了,直接返回 t2 表中没有 B 值。
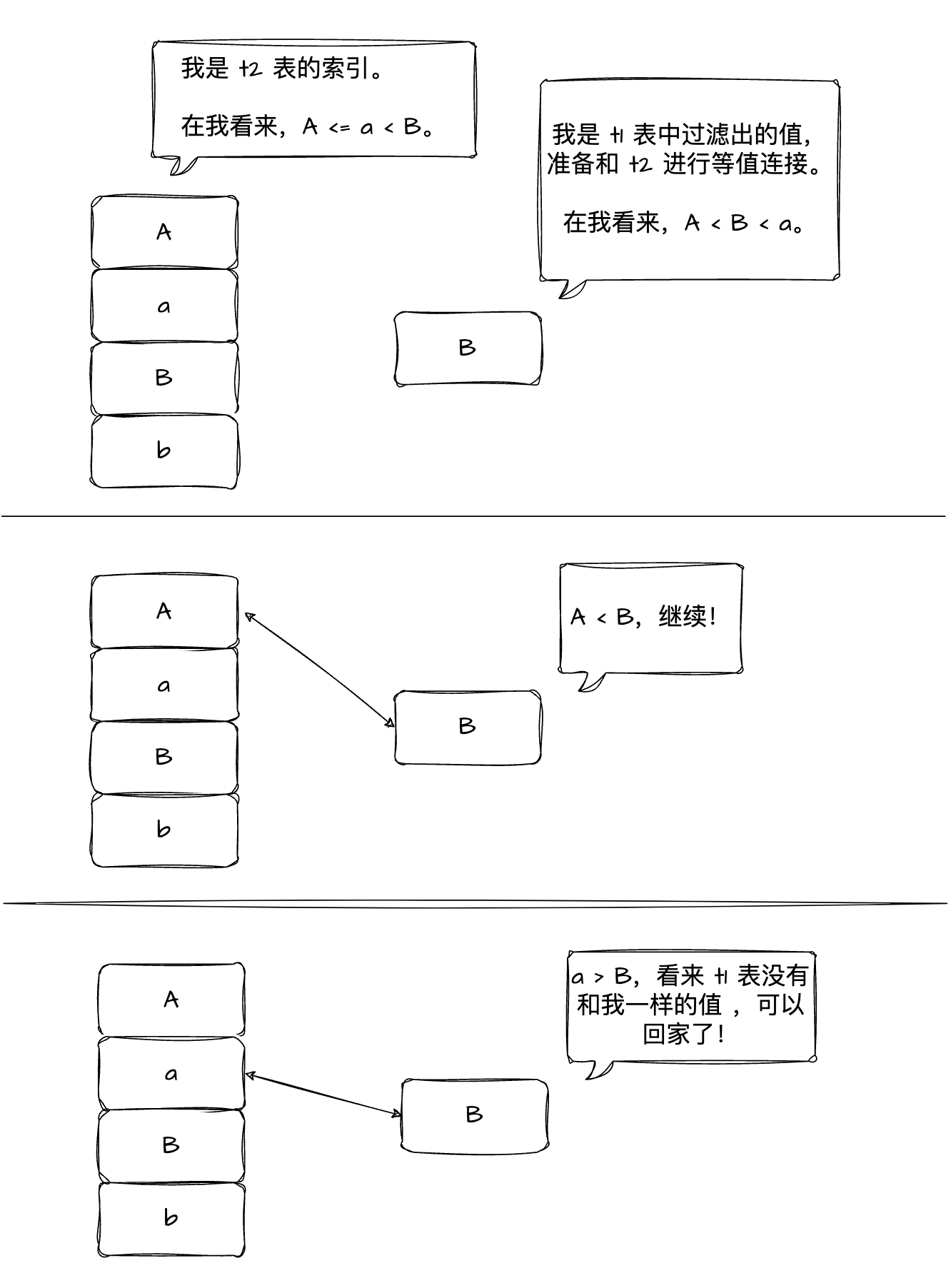
这样 join 之后的结果显然是错误的!所以数据库不会利用 t2 表索引的有序性快速定位 t1 表中的数据,只能对 t2 进行全表扫。
问题解决
方法一
SQL 调优专家絮语老哥给了个解决方案:把 join 条件里的 t1.c3 改成 convert(t1.c3 using utf8mb4)。
这样就会在进行 join 之前,把从 t1 过滤出来的值的 collation 转成 utf8mb4 默认的 collation utf8mb4_general_ci,统一了 join 双方的排序规则,这样就可以利用上索引了。
explainselect /*+leading(t1 t2) use_nl(t2)*/ * from t1 join t2 on convert(t1.c3 using utf8mb4) = t2.c3where t1.c2 = 123;
+--------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------+
| ================================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------------------------- |
| |0 |NESTED-LOOP JOIN | |4 |36 | |
| |1 |├─TABLE RANGE SCAN |t1(c2) |1 |7 | |
| |2 |└─DISTRIBUTED TABLE RANGE SCAN|t2(idx)|4 |29 | |
| ================================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2], [t1.c3], [t2.c1], [t2.c2], [t2.c3]), filter(nil), rowset=16 |
| conds(nil), nl_params_([t1.c3(:0)]), use_batch=true |
| 1 - output([t1.c1], [t1.c3], [t1.c2]), filter(nil), rowset=16 |
| access([t1.c1], [t1.c3], [t1.c2]), partitions(p0) |
| is_index_back=true, is_global_index=false, |
| range_key([t1.c2], [t1.shadow_pk_0]), range(123,MIN ; 123,MAX), |
| range_cond([t1.c2 = 123]) |
| 2 - output([t2.c1], [t2.c3], [t2.c2]), filter(nil), rowset=16 |
| access([GROUP_ID], [t2.c1], [t2.c3], [t2.c2]), partitions(p0) |
| is_index_back=true, is_global_index=false, |
| range_key([t2.c3], [t2.c1]), range(MIN ; MAX), |
| range_cond([convert(cast(:0, VARCHAR(1048576)), 'utf8mb4') = t2.c3]) |
+--------------------------------------------------------------------------------------------+计划里也可以看到,之前 t2 表的 table full scan 变成了 table range scan,终于用上了 idx 这个索引!用户的问题也得到了解决~
方法二
上面这种方法一并不是通用的方法。OceanBase 的 convert 只能转 charset,然后附带把 collation 转成对应 charset 默认的 collation。碰巧 utf8mb4 的默认 collation 是 general_ci,直接把 collation 给转成想要的了。万一想转的 collation 不是对应 charset 默认的 collation,用方法一就不成了!
最好的方法是把 join 条件中的 t1.c3 改成 t1.c3 collate utf8mb4_general_ci,这样就可以随心所欲地转换成你真正想要的 collation 了。
explainselect /*+leading(t1 t2) use_nl(t2)*/ * from t1 join t2 on t1.c3 collate utf8mb4_general_ci = t2.c3where t1.c2 = 123
+--------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------+
| ================================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------------------------- |
| |0 |NESTED-LOOP JOIN | |4 |36 | |
| |1 |├─TABLE RANGE SCAN |t1(c2) |1 |7 | |
| |2 |└─DISTRIBUTED TABLE RANGE SCAN|t2(idx)|4 |29 | |
| ================================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2], [t1.c3], [t2.c1], [t2.c2], [t2.c3]), filter(nil), rowset=16 |
| conds(nil), nl_params_([t1.c3(:0)]), use_batch=true |
| 1 - output([t1.c1], [t1.c3], [t1.c2]), filter(nil), rowset=16 |
| access([t1.c1], [t1.c3], [t1.c2]), partitions(p0) |
| is_index_back=true, is_global_index=false, |
| range_key([t1.c2], [t1.shadow_pk_0]), range(123,MIN ; 123,MAX), |
| range_cond([t1.c2 = 123]) |
| 2 - output([t2.c1], [t2.c3], [t2.c2]), filter(nil), rowset=16 |
| access([GROUP_ID], [t2.c1], [t2.c3], [t2.c2]), partitions(p0) |
| is_index_back=true, is_global_index=false, |
| range_key([t2.c3], [t2.c1]), range(MIN ; MAX), |
| range_cond([convert(cast(:0, VARCHAR(1048576)), 'utf8mb4') = t2.c3]) |
+--------------------------------------------------------------------------------------------+What's more?
推荐使用论坛小助手
在OceanBase社区中,可以直接 @论坛小助手 机器人问问题,对于本文的问题,目测效果还不错,提出了好几种可行的方案(还包括了絮语老哥的那种)。与义说其实直接在问答帖下艾特他就可以,不用多余问他什么,他会自己去爬楼看问题。

推荐阅读
《DBA 入门教程 —— 诊断和调优 —— 阅读和管理 OceanBase 数据库 SQL 执行计划》