【综述】视频目标分割VOS
目录
- 1、Associating Objects with Transformers for Video Object Segmentation
- 1)背景知识
- 2)研究方法
- 3)实验结果
- 4)结论
- 2、Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
- 1)背景知识
- 2)研究方法
- 3)实验结果
- 4)关键结论
- 3、Recurrent Dynamic Embedding for Video Object Segmentation
- 1)背景知识
- 2)研究方法
- 3)实验结果
- 4)关键结论
- 4、XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
- 1)背景知识
- 2)研究方法
- 3)实验结果
- 4)关键结论
- 5、Decoupling Features in Hierarchical Propagation for Video Object Segmentation
- 1)背景知识
- 2)研究方法
- 双分支传播
- 门控传播模块(GPM)
- 3)实验结果
- 4)关键结论
- 6、Tracking Anything with Decoupled Video Segmentation
- 背景知识
- 研究方法
- 双向传播
- 时序传播模块
- 实验结果
- 关键结论
- 7、Putting the Object Back into Video Object Segmentation
- 1)背景知识与研究动机
- 2)研究方法
- 3)实验
- 关键数值结果
- 4)结论
1、Associating Objects with Transformers for Video Object Segmentation
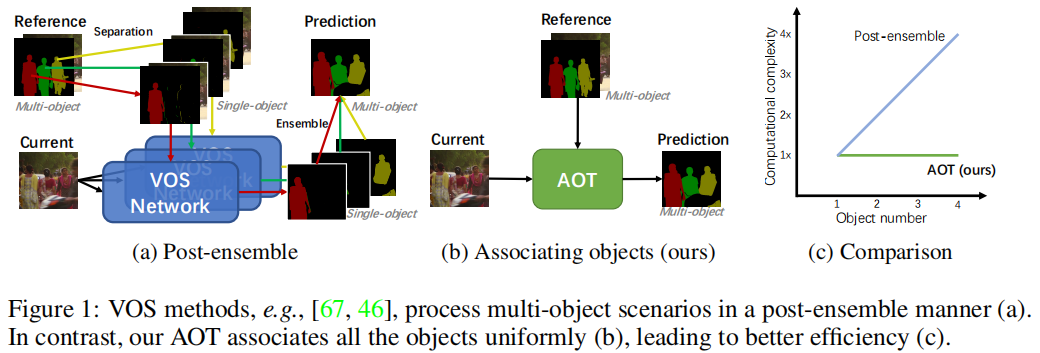
这篇文章提出了一种名为“Associating Objects with Transformers (AOT)”的新方法,用于解决半监督视频目标分割(VOS)任务中的多目标场景问题。AOT通过将多个目标统一嵌入到同一个高维嵌入空间中,实现了多目标的匹配和解码,显著提高了效率,并在多个基准测试中取得了优异的性能。
1)背景知识
视频目标分割(VOS)是视频理解中的一个基础任务,其目标是根据视频序列中第一帧提供的目标掩码,跟踪并分割整个视频中的目标。半监督VOS是其中的主要任务类型。尽管已有方法取得了显著进展,但它们大多针对单个目标进行解码,导致在多目标场景下需要独立匹配每个目标,并将单目标预测组合成多目标分割,这种后处理方式效率低下,尤其是在计算资源有限的情况下。
2)研究方法
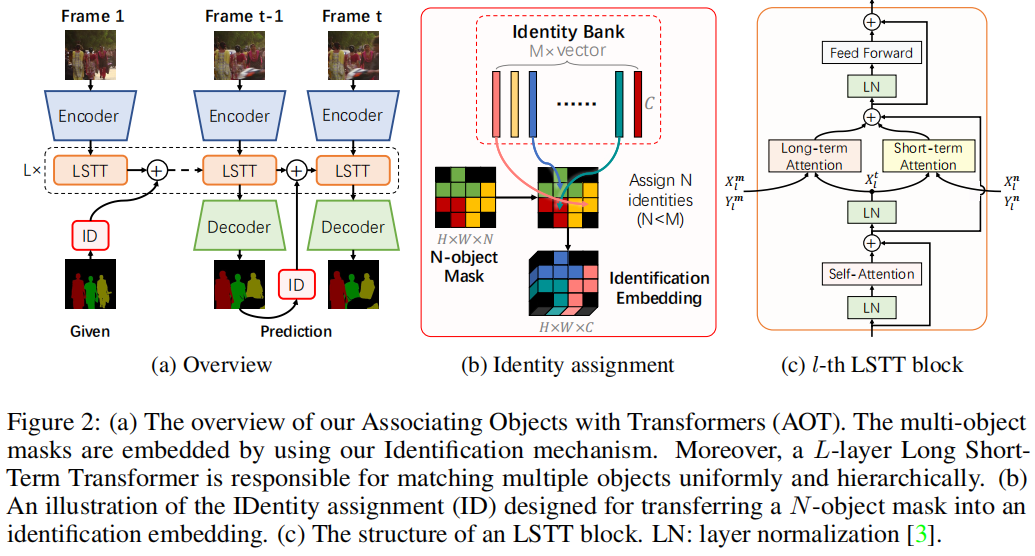
AOT的核心在于提出了一个识别机制,将多个目标嵌入到同一个特征空间中,从而可以同时处理多个目标的匹配和分割解码,效率与处理单个目标相当。具体来说,AOT包含以下几个关键部分:
-
识别机制:通过为每个目标分配一个唯一的身份标识,并将这些目标嵌入到同一个特征空间中,网络可以学习目标之间的关联。这种机制允许直接从聚合的特征中解码多目标分割。
-
长短期变换器(LSTT):为了充分建模多目标关联,设计了LSTT模块,用于构建层次化的匹配和传播。LSTT模块结合了长期注意力(匹配第一帧的嵌入)和短期注意力(匹配附近几帧的嵌入),以更有效地关联多个目标。
-
网络架构:AOT使用轻量级的MobileNet-V2作为骨干网络,并设计了不同复杂度的变体,包括AOT-Tiny、AOT-Small、AOT-Base和AOT-Large,以满足不同的效率和性能需求。
3)实验结果
实验部分,作者在YouTube-VOS、DAVIS 2017和DAVIS 2016这三个流行的基准数据集上验证了AOT的性能。结果显示:
- YouTube-VOS:AOT在验证集2018和2019的分割性能(J&F指标)上均优于所有现有方法,例如AOT-L达到了83.8%和83.7%,而之前的最佳方法CFBI+为82.8%和81.8%。同时,AOT在多目标运行时效率上也显著优于其他方法,例如AOT-T在保持实时性能(41.0 FPS)的同时,性能优于CFBI+。
- DAVIS 2017:AOT在验证集和测试集上均取得了最佳性能,例如R50-AOT-L在验证集上达到了84.9%,在测试集上达到了79.6%,并且保持了较高的运行效率(18.0 FPS)。
- DAVIS 2016:尽管AOT主要针对多目标VOS,但在单目标场景下也取得了新的最佳性能,例如R50-AOT-L达到了91.1%,并且运行效率是现有方法的两倍。
此外,文章还提供了与其他最新实时方法(如SAT和GC)的比较,AOT在保持实时性能的同时,显著优于这些方法。
4)结论
AOT通过其创新的识别机制和LSTT模块,在多目标视频目标分割任务中实现了效率和性能的双重提升。该方法不仅在多个基准测试中取得了优异的性能,还保持了较高的运行效率,使其在实际应用中具有很大的潜力。此外,AOT的架构设计允许通过调整LSTT模块的数量来灵活平衡性能和速度,为未来的研究和应用提供了更多的可能性。
2、Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
这篇文章提出了一种名为“Space-Time Correspondence Network (STCN)”的新型视频目标分割(VOS)方法,旨在通过改进时空对应关系建模来提高效率和性能。STCN通过直接在帧之间建立对应关系,避免了为每个目标重新编码掩码特征,从而实现了一个高效且鲁棒的框架。该方法在DAVIS和YouTubeVOS数据集上取得了新的最高性能,并且运行速度超过20 FPS,显著优于现有方法。
1)背景知识
视频目标分割(VOS)任务的目标是在视频序列中标记和分割目标实例。本文关注半监督设置,即第一帧的分割掩码已知,算法需要推断剩余帧的分割掩码。与视频目标跟踪不同,VOS需要详细的目标掩码,而不仅仅是简单的边界框。一个高性能的算法应该能够在部分或完全遮挡、外观变化和目标变形的情况下,将目标从背景或其他干扰因素中区分出来。
2)研究方法
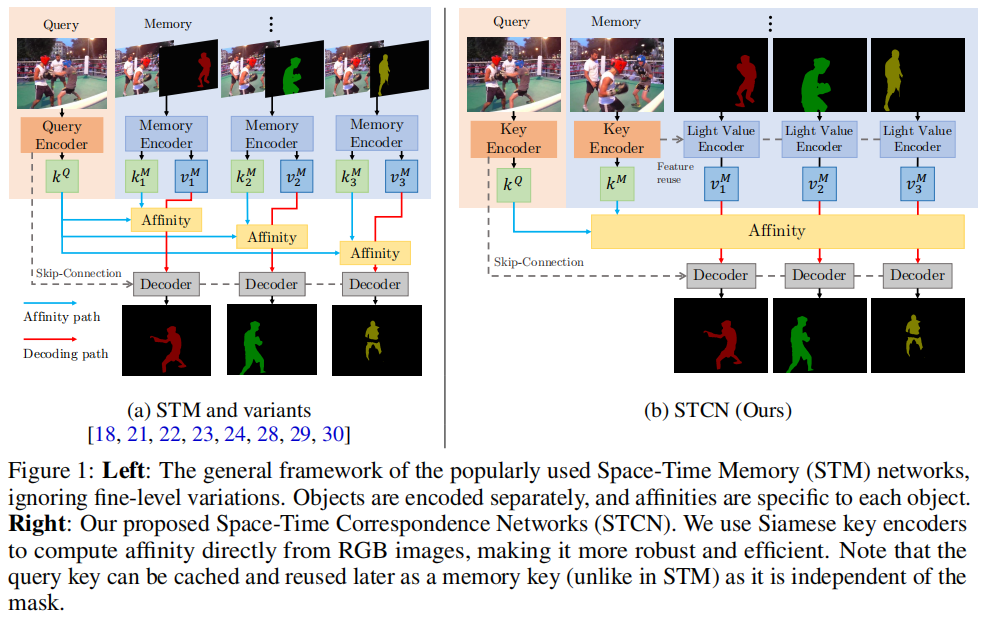

STCN的核心思想是直接在帧之间建立对应关系,而不是为视频中的每个目标构建特定的内存库和亲和力。这种方法不仅更高效,而且更鲁棒,因为模型被迫学习所有目标之间的关系,而不仅仅是标记的目标。STCN通过以下关键步骤实现:
-
特征提取:STCN使用ResNet50作为键编码器(仅输入图像)和ResNet18作为值编码器(输入图像和掩码)。键特征(和结果亲和力)可以独立于掩码提取,每个帧只计算一次,并且在内存和查询之间是对称的。这种设计允许在不引入掩码作为干扰的情况下,在视频帧之间建立对应关系。
-
记忆读取和解码:给定T个记忆帧和一个查询帧,STCN计算记忆键和查询键之间的亲和力矩阵,并使用softmax归一化。然后,通过加权和的方式从记忆特征中聚合查询帧的特征,这些特征随后被传递到解码器以生成掩码。
-
记忆管理:STCN在记忆管理上进行了优化,避免了使用临时记忆帧,因为这会导致记忆键与查询帧过于相似,从而导致漂移。这种修改减少了对值编码器的调用次数,显著提高了速度。
-
亲和力计算:STCN提出了使用负平方欧几里得距离代替点积来计算亲和力。这种改变确保了每个记忆节点都有机会显著贡献(给定正确的查询),从而提高了性能、鲁棒性和内存使用效率。
3)实验结果
STCN在DAVIS 2017和YouTubeVOS 2018验证集上进行了广泛的实验,并与其他方法进行了比较。结果显示:
- DAVIS 2017:STCN在验证集上取得了85.4%的J&F分数,超过了之前最好的方法MiVOS(83.3%)和STM(81.8%),并且运行速度为20.2 FPS,显著快于STM(10.2 FPS)。
- YouTubeVOS 2018:STCN在验证集上取得了83.0%的G分数,超过了之前的最高成绩82.7%,并且在多目标场景下运行速度超过20 FPS。
此外,STCN在DAVIS 2016和YouTubeVOS 2019验证集上也取得了优异的成绩,并在DAVIS交互式赛道上展示了其性能。
4)关键结论
STCN通过直接帧到帧的对应关系和改进的亲和力计算方法,提供了一种简单、高效且强大的视频目标分割解决方案。它不仅在性能上超越了现有的最先进方法,而且在运行速度上也具有显著优势。STCN的提出为未来视频目标分割的研究提供了一个新的高效基线。
尽管STCN在多个基准测试中取得了优异的性能,但它在处理具有相似外观且相隔较远的目标时可能会出现错误分割的情况。这是因为STCN目前没有考虑时间一致性线索,例如光流或局部匹配。作者认为,STCN的框架足够简单,可以很容易地扩展以包含时间一致性考虑,从而实现进一步的改进。
3、Recurrent Dynamic Embedding for Video Object Segmentation
这篇文章提出了一种名为“Recurrent Dynamic Embedding (RDE)”的新型视频目标分割(VOS)方法,旨在解决基于时空记忆(STM)的VOS网络在处理长视频时面临的内存需求不断增加和噪声积累的问题。RDE通过引入循环动态嵌入和时空聚合模块(SAM),构建了一个固定大小的记忆库,并通过无偏指导损失和自校正策略来提高模型的鲁棒性和准确性。该方法在多个基准数据集上取得了优异的性能,并在合成长视频中展示了其有效性。
1)背景知识
视频目标分割(VOS)是视频理解中的一个基础任务,特别是在半监督设置中,给定第一帧的实例标注,算法需要分割出其他帧中的实例。现有的基于STM的VOS网络通过不断增加记忆库的大小来提高性能,但这种方法存在两个主要问题:一是硬件难以承受不断增加的内存需求;二是存储大量信息会引入噪声,不利于从记忆库中读取最重要的信息。
2)研究方法

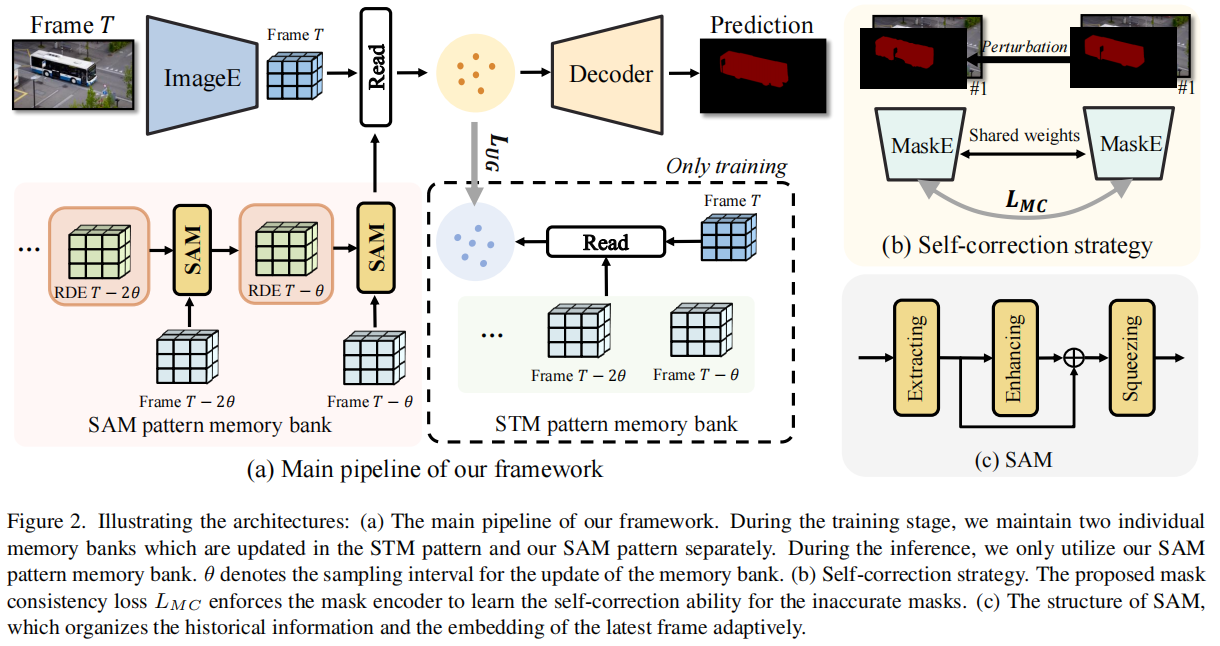
为了解决上述问题,文章提出了RDE方法,其核心是构建一个固定大小的记忆库。具体来说,RDE通过以下三个关键部分实现:
-
循环动态嵌入(RDE):RDE通过SAM生成和更新,利用历史信息的线索和最新帧的嵌入来提供更丰富的表示。RDE的更新过程包括三个部分:提取、增强和压缩。提取部分负责组织历史RDE和最新帧嵌入之间的时空关系;增强部分通过空洞空间金字塔池化(ASPP)强化这种关系;压缩部分则通过卷积操作压缩增强后的特征。
-
时空聚合模块(SAM):SAM负责生成和更新RDE,通过组织历史信息和最新帧的嵌入来适应性地更新记忆库。SAM包括提取、增强和压缩三个部分,分别负责组织时空关系、强化关系和压缩信息。
-
无偏指导损失(Unbiased Guidance Loss):为了避免SAM在长视频中由于循环使用而导致的误差累积,文章提出了一种无偏指导损失。这种损失通过比较SAM模式记忆库和STM模式记忆库的分布来控制SAM的更新过程,使其在训练阶段更加稳定。
-
自校正策略(Self-correction Strategy):考虑到记忆库中掩码的质量会影响查询帧的分割性能,文章设计了一种自校正策略,通过模拟不同质量的掩码并约束这些掩码的嵌入与真实掩码的嵌入接近,从而在训练阶段学习自校正能力。
3)实验结果
文章在DAVIS 2017、DAVIS 2016和YouTube-VOS 2019等多个基准数据集上进行了广泛的实验。实验结果表明,RDE方法在性能和速度上都取得了最佳的权衡:
- DAVIS 2017验证集:RDE方法达到了86.1%的J&F分数,比STCN高出0.7%,并且速度更快(27 FPS对比20.2 FPS)。
- DAVIS 2017测试集:RDE方法在测试集上也表现出色,J&F分数为78.9%。
- DAVIS 2016验证集:RDE方法达到了91.6%的J&F分数,速度为35 FPS,比STCN快40%。
- YouTube-VOS 2019验证集:尽管RDE方法没有超过STCN,但它仍然超过了其他最先进的方法,无论是否使用BL30K数据集进行训练。
此外,文章还通过合成长视频实验验证了RDE方法在处理长视频时的有效性。实验结果表明,随着合成长视频长度的增加,RDE方法的性能和速度几乎不受影响,而STCN的性能和速度明显下降。
4)关键结论
文章提出的RDE方法通过构建固定大小的记忆库,有效地解决了STM方法在处理长视频时面临的内存需求和噪声积累问题。通过SAM模块和无偏指导损失,RDE方法在训练阶段更加稳定,并且能够自适应地更新记忆库。自校正策略进一步提高了模型对记忆库中掩码质量的鲁棒性。实验结果表明,RDE方法在多个基准数据集上都取得了优异的性能,并且在处理长视频时表现出色。
4、XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
这篇文章介绍了一种名为 XMem 的新型视频目标分割(VOS)架构,专门针对长视频设计,灵感来源于 Atkinson-Shiffrin 记忆模型。XMem 通过引入多种独立但深度连接的特征记忆库,解决了传统 VOS 方法在处理长视频时面临的内存需求和性能衰减问题。该方法在长视频数据集上大幅超越了现有技术,并在短视频数据集上与现有技术持平。
1)背景知识

视频目标分割(VOS)任务的目标是在给定视频中标记和分割出特定的目标对象。在半监督设置中,用户提供了第一帧的标注,算法需要尽可能准确地分割出其他帧中的目标对象,同时尽量实现实时在线处理,并在处理长视频时保持较小的内存占用。现有的 VOS 方法大多使用单一类型的特征记忆库来存储目标对象的深度网络表示,但对于超过一分钟的长视频,单一记忆库模型会将内存消耗和准确性紧密联系在一起,限制了模型的扩展性。
2)研究方法

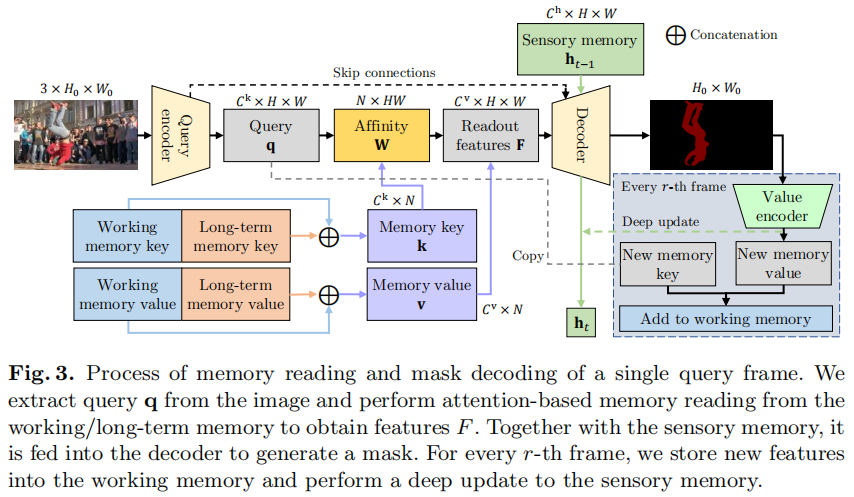
XMem 的核心在于模仿 Atkinson-Shiffrin 记忆模型,引入了三种特征记忆库:
- 感觉记忆(Sensory Memory):快速更新,提供时间平滑性,但不适合长期预测,因为存在表示漂移问题。
- 工作记忆(Working Memory):从历史帧的子集中聚合而来,不随时间漂移,用于短期预测。
- 长期记忆(Long-term Memory):紧凑且持久,通过记忆强化算法将工作记忆中的元素整合到长期记忆中,避免内存爆炸并最小化长期预测的性能衰减。
XMem 的关键创新点包括:
- 记忆强化算法(Memory Potentiation Algorithm):通过聚合更丰富的信息到长期记忆的原型中,防止由于子采样导致的混叠现象。
- 记忆阅读机制(Memory Reading Mechanism):结合工作记忆和长期记忆,通过注意力机制提取查询帧所需的特征。
- 自适应更新策略(Adaptive Update Strategy):根据视频内容动态调整记忆库的更新频率,确保在不同场景下都能保持高效的性能。
3)实验结果
XMem 在多个基准数据集上进行了广泛的实验,包括长视频数据集和短视频数据集。实验结果表明,XMem 在长视频数据集上大幅超越了现有技术,同时在短视频数据集上与现有技术持平。具体结果如下:
- 长视频数据集(Long-time Video Dataset):XMem 在长视频数据集上取得了显著的性能提升,例如在 3× 变体上,XMem 的 J&F 分数为 90.0%,而其他方法如 STCN 的分数为 84.6%,性能衰减仅为 0.2%,而 STCN 的衰减为 -2.7%。
- 短视频数据集(DAVIS 和 YouTube-VOS):XMem 在 DAVIS 2017 验证集上达到了 86.2% 的 J&F 分数,在 YouTube-VOS 2018 验证集上达到了 85.7% 的 G 分数,与现有技术持平,同时在处理长视频时保持了较低的内存占用。
4)关键结论
XMem 通过引入多种特征记忆库和记忆强化算法,有效地解决了传统 VOS 方法在处理长视频时面临的内存需求和性能衰减问题。XMem 不仅在长视频数据集上取得了显著的性能提升,还在短视频数据集上与现有技术持平,展示了其在不同场景下的广泛适用性。此外,XMem 的内存占用低,适合在资源受限的设备上运行,例如移动设备。
尽管 XMem 在处理长视频时表现出色,但在目标对象移动过快或存在严重运动模糊的情况下,即使是更新速度最快的感官记忆也无法跟上目标对象的变化,导致分割失败。作者认为,使用具有更大感受野的感官记忆可以解决这一问题。
5、Decoupling Features in Hierarchical Propagation for Video Object Segmentation
这篇文章提出了一种名为 Decoupling Features in Hierarchical Propagation (DeAOT) 的新型视频目标分割(VOS)方法,旨在解决现有基于层次传播的VOS方法(如AOT)在传播过程中因增加目标特定信息而导致目标无关视觉信息丢失的问题。DeAOT通过解耦目标无关和目标特定的特征传播,并引入高效的门控传播模块(Gated Propagation Module, GPM),显著提高了VOS的性能和效率。
1)背景知识
视频目标分割(VOS)是视频理解中的一个基础任务,目标是在给定视频中标记和分割出特定的目标对象。半监督VOS要求算法在给定某些帧的标注掩码后,能够将这些掩码信息传播到整个视频序列中。近年来,基于注意力机制的VOS方法取得了显著进展,其中AOT通过引入基于Transformer的层次传播机制,实现了从过去帧到当前帧的信息传播,并将当前帧的特征从目标无关(object-agnostic)转换为目标特定(object-specific)。
2)研究方法
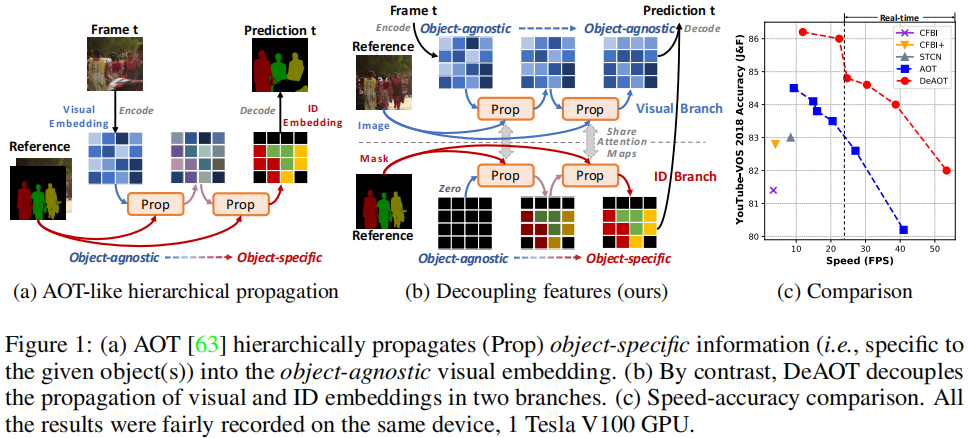
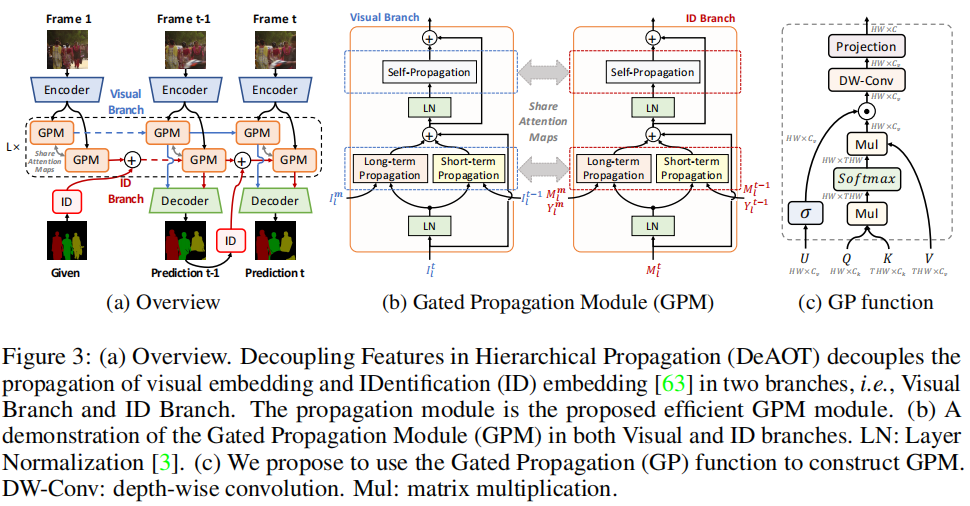
DeAOT的核心思想是将目标无关和目标特定的特征传播解耦到两个独立的分支中,即视觉分支(Visual Branch)和ID分支(ID Branch)。视觉分支负责匹配对象、收集过去的视觉信息并细化对象特征;ID分支则利用视觉分支计算的注意力图(attention maps)将ID嵌入从过去帧传播到当前帧。这种双分支结构避免了在深层传播层中丢失目标无关的视觉信息,从而有助于学习更鲁棒的视觉嵌入。
双分支传播
- 视觉分支:通过计算注意力图在视觉嵌入上进行对象匹配,并传播过去的视觉信息。
- ID分支:利用视觉分支的注意力图将ID嵌入从过去帧传播到当前帧。
门控传播模块(GPM)
为了提高效率,DeAOT提出了一种基于单头注意力的GPM模块,用于构建层次传播。GPM包括长时传播、短时传播和自传播三种类型的传播过程,每种传播过程都使用了门控传播函数(GP function)。
3)实验结果
DeAOT在多个基准数据集上进行了广泛的实验,包括YouTube-VOS、DAVIS 2017、DAVIS 2016和VOT 2020。实验结果表明,DeAOT在准确性和运行速度上均优于现有的AOT方法。
- YouTube-VOS:DeAOT在2018和2019年的验证集上分别达到了86.0%和85.9%的J&F分数,运行速度为22.4fps,显著优于AOT的84.1%和14.9fps。
- DAVIS 2017:DeAOT在验证集和测试集上分别达到了85.2%和80.7%的J&F分数,运行速度为27fps,优于AOT的83.8%和18.7fps。
- DAVIS 2016:DeAOT达到了92.3%的J&F分数,运行速度为27fps,优于AOT的91.1%和18.0fps。
- VOT 2020:DeAOT在EAO分数上达到了0.622,显著优于现有的跟踪方法。
4)关键结论
DeAOT通过解耦目标无关和目标特定的特征传播,避免了在深层传播层中丢失视觉信息,从而提高了VOS的性能。此外,DeAOT提出的GPM模块在保持高效的同时,进一步提升了性能。DeAOT在多个基准数据集上取得了新的最高性能,并在运行速度上优于现有方法。
尽管DeAOT在多个基准数据集上取得了优异的性能,但在处理具有严重遮挡的多个高度相似目标时,DeAOT仍然可能失败。这表明在复杂场景下,进一步改进特征传播和目标匹配机制仍然是一个挑战。
6、Tracking Anything with Decoupled Video Segmentation
这篇文章提出了一种名为 DEVA(Decoupled Video Segmentation Approach)的新型视频分割方法,旨在通过解耦图像级分割和时序传播来实现对任意目标的跟踪和分割。DEVA通过结合任务特定的图像级分割模型和通用的时序传播模型,有效减少了对大规模视频训练数据的依赖,并在多个视频分割任务中取得了优异的性能。
背景知识
视频分割是计算机视觉中的一个基础任务,对于视频理解至关重要。传统的端到端视频分割方法需要在标注好的视频数据集上进行训练,这在大规模词汇表或开放世界设置中变得不切实际,因为标注成本高昂且难以扩展。DEVA通过解耦图像级分割和时序传播,利用更便宜的图像级模型和通用的时序传播模型,减少了对大规模视频训练数据的需求。

研究方法
DEVA的核心思想是将视频分割任务分解为两个独立但相互协作的模块:图像级分割模块和时序传播模块。图像级分割模块负责提供特定任务的分割假设,而时序传播模块则负责在视频序列中传播这些分割假设,生成连贯的分割结果。
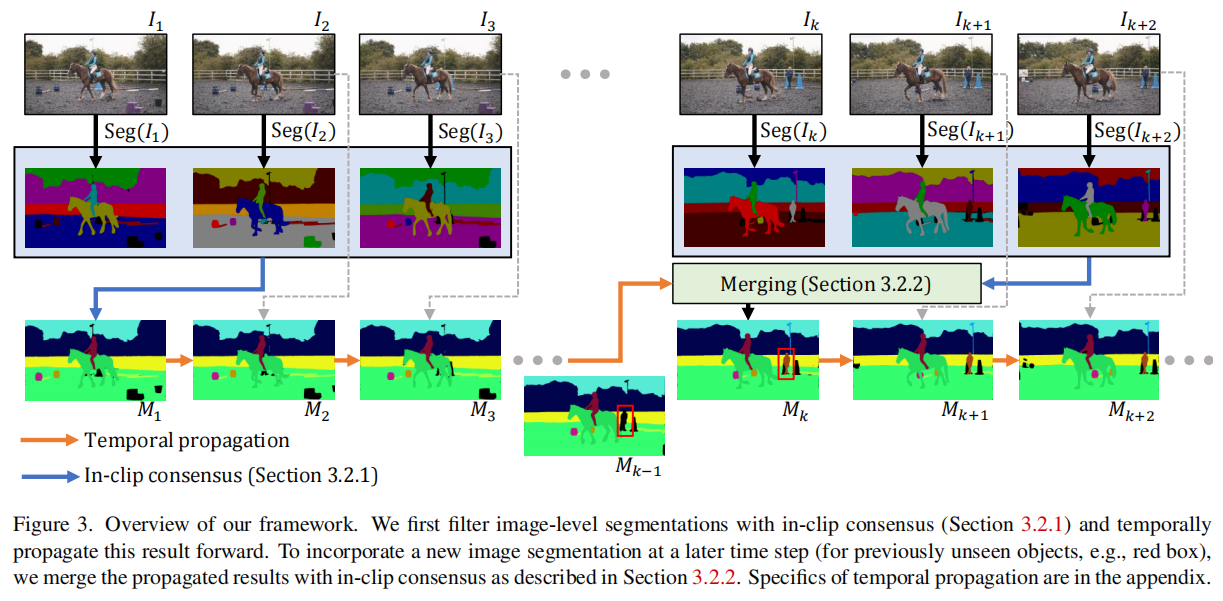

双向传播
DEVA提出了一种双向传播算法,用于在(半)在线设置中融合不同帧的分割假设。具体来说,DEVA通过以下步骤实现:
- In-clip Consensus(剪辑内共识):通过查看未来几帧的分割结果,DEVA在当前帧上达成共识,从而减少单帧分割的噪声。
- Temporal Propagation(时序传播):将经过剪辑内共识处理后的分割结果传播到后续帧。
- Merging Propagation and Consensus(传播和共识的融合):将传播得到的分割结果与新的图像分割结果合并,以处理新出现的对象。
时序传播模块
DEVA的时序传播模块基于XMem模型,该模型通过维护一个内部特征记忆来实现高效的视频对象分割。DEVA对XMem进行了几项改进,包括增加感知记忆的通道数、使用加法而不是连接来融合记忆读出结果,以及引入辅助损失来监督感知记忆。
实验结果
DEVA在多个基准数据集上进行了广泛的实验,包括大规模视频全景分割(VIPSeg)、开放世界视频分割(BURST)、引用视频分割(Ref-YouTubeVOS 和 Ref-DAVIS)以及无监督视频对象分割(DAVIS-16 和 DAVIS-17)。实验结果表明,DEVA在这些任务中均取得了优异的性能。
- 大规模视频全景分割(VIPSeg):DEVA在VIPSeg验证集上取得了42.1%的VPQ分数,显著优于现有的端到端方法。
- 开放世界视频分割(BURST):DEVA在BURST数据集上取得了69.9%的OWTA分数,优于现有的跟踪方法。
- 引用视频分割:DEVA在Ref-YouTubeVOS和Ref-DAVIS数据集上分别取得了66.0%和66.3%的J&F分数,优于现有的方法。
- 无监督视频对象分割:DEVA在DAVIS-16和DAVIS-17数据集上分别取得了88.9%和73.4%的J&F分数,表现出色。
关键结论
DEVA通过解耦图像级分割和时序传播,有效地减少了对大规模视频训练数据的依赖,并在多个视频分割任务中取得了优异的性能。这种方法特别适合于大规模词汇表或开放世界设置,其中视频数据和标注成本高昂且难以获取。DEVA的双向传播算法和改进的时序传播模块是其实现高性能的关键。
尽管DEVA在多个任务中表现出色,但它也有一些限制。首先,由于时序传播模块是任务无关的,它无法自行检测新对象,这可能导致新对象的检测延迟。其次,在数据充足的情况下,端到端方法仍然优于DEVA,但DEVA在大规模词汇表或开放世界设置中更具潜力。
7、Putting the Object Back into Video Object Segmentation
这篇文章介绍了一种名为Cutie的视频目标分割(Video Object Segmentation, VOS)网络,它通过对象级别的记忆读取来提高在复杂场景下的分割性能。Cutie的核心创新在于其对象级别的记忆读取机制,通过对象查询和对象变换器(object transformer)实现,能够有效地将对象从记忆中重新引入到查询帧中,从而在具有挑战性的数据集上取得了显著的性能提升。
1)背景知识与研究动机
视频目标分割(VOS)任务要求在给定第一帧注释的情况下,跟踪并分割视频中的目标对象。近年来,基于记忆的VOS方法通过从过去的分割帧中计算记忆表示,并在新查询帧中读取这些记忆来实现分割。然而,这些方法主要依赖于像素级别的匹配,容易受到干扰,尤其是在存在干扰物的情况下,导致性能下降。为了解决这一问题,Cutie提出了一种对象级别的记忆读取方法,通过对象查询和对象变换器来整合像素特征,从而在复杂场景下实现更鲁棒的分割性能。

2)研究方法
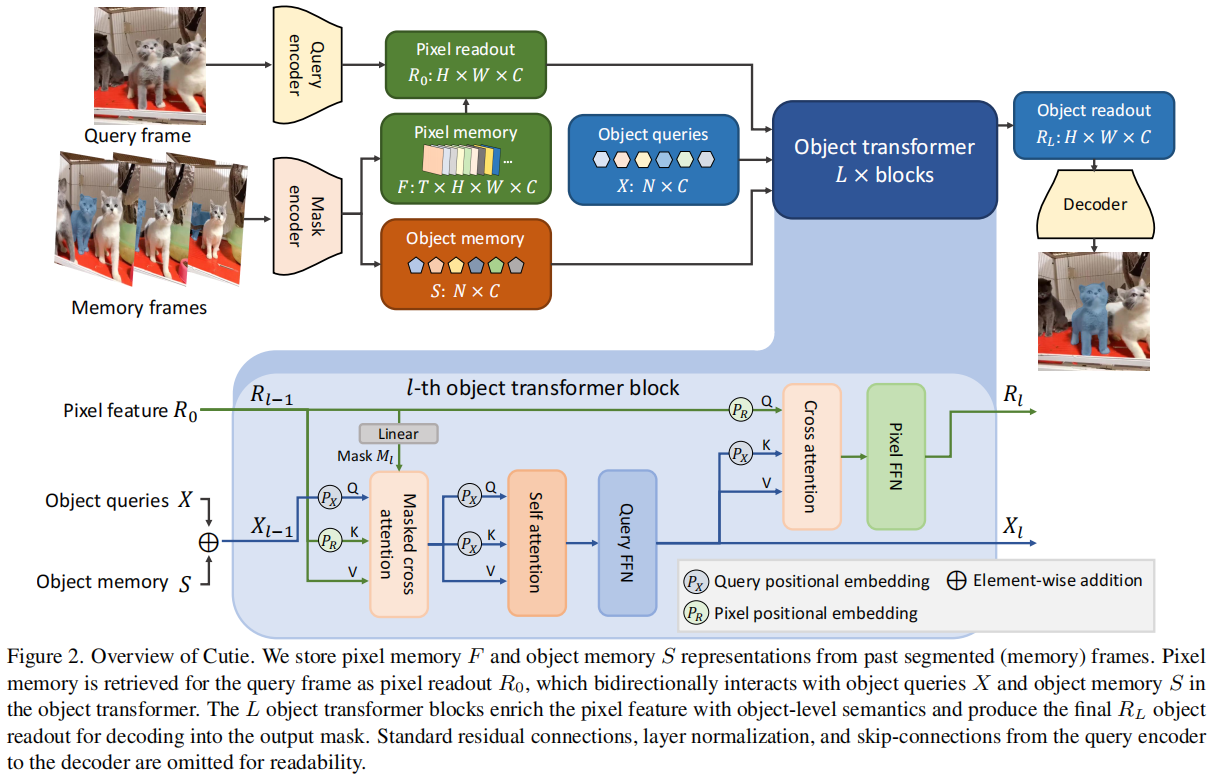
Cutie的核心是对象级别的记忆读取机制,它通过以下三个主要部分实现:
- 对象变换器(Object Transformer):Cutie使用一组对象查询(object queries)与从像素记忆中读取的特征进行交互。这些对象查询作为目标对象的高级摘要,而高分辨率特征图则用于精确分割。对象变换器通过迭代的方式将对象查询与像素特征结合起来,从而在保持全局对象信息的同时,也保留了高分辨率的像素特征。
- 前景-背景掩码注意力(Foreground-Background Masked Attention):为了清晰地分离前景和背景的语义,Cutie扩展了掩码注意力机制,使得部分对象查询只关注前景,而其余的则只关注背景。这种分离有助于在存在干扰物的情况下保持分割的准确性。
- 紧凑对象记忆(Compact Object Memory):Cutie引入了一个紧凑的对象记忆来总结目标对象的特征,这些特征在查询时被检索为目标特定的对象级表示,从而增强了对象查询的表示能力。
3)实验
实验部分评估了Cutie在多个标准基准测试上的性能,包括DAVIS 2017、YouTubeVOS和具有挑战性的MOSE数据集。结果显示,Cutie在MOSE数据集上相较于XMem和DeAOT等方法有显著的性能提升,同时在DAVIS和YouTubeVOS数据集上也保持了竞争力,无论是在准确性还是效率上。
关键数值结果
- 在MOSE数据集上,Cutie相比于XMem提升了8.7 J&F,同时保持了类似的运行时间。
- 在DAVIS-2017和YouTubeVOS数据集上,Cutie-base模型的J&F分数分别为67.9和87.7,表现出色。
- 在长视频评估中,Cutie在BURST数据集上的表现也优于其他方法,例如Cutie-base在长视频上的HOTA分数为61.8%,优于XMem的57.9%。
4)结论
Cutie通过其对象级别的记忆读取机制,在复杂场景下的视频目标分割任务中取得了显著的性能提升。它有效地整合了自顶向下的对象级信息和自底向上的像素级特征,使得在存在干扰物和遮挡的情况下也能保持鲁棒的分割性能。此外,Cutie的设计允许它在实时应用中保持高效率。
尽管Cutie在许多情况下表现出色,但在高度相似的对象靠近或相互遮挡时,它可能会失败。这种情况下,像素记忆和对象记忆可能无法提供足够的区分特征供对象变换器操作。