【Qwen开源】WorldPM: 扩展人类偏好建模
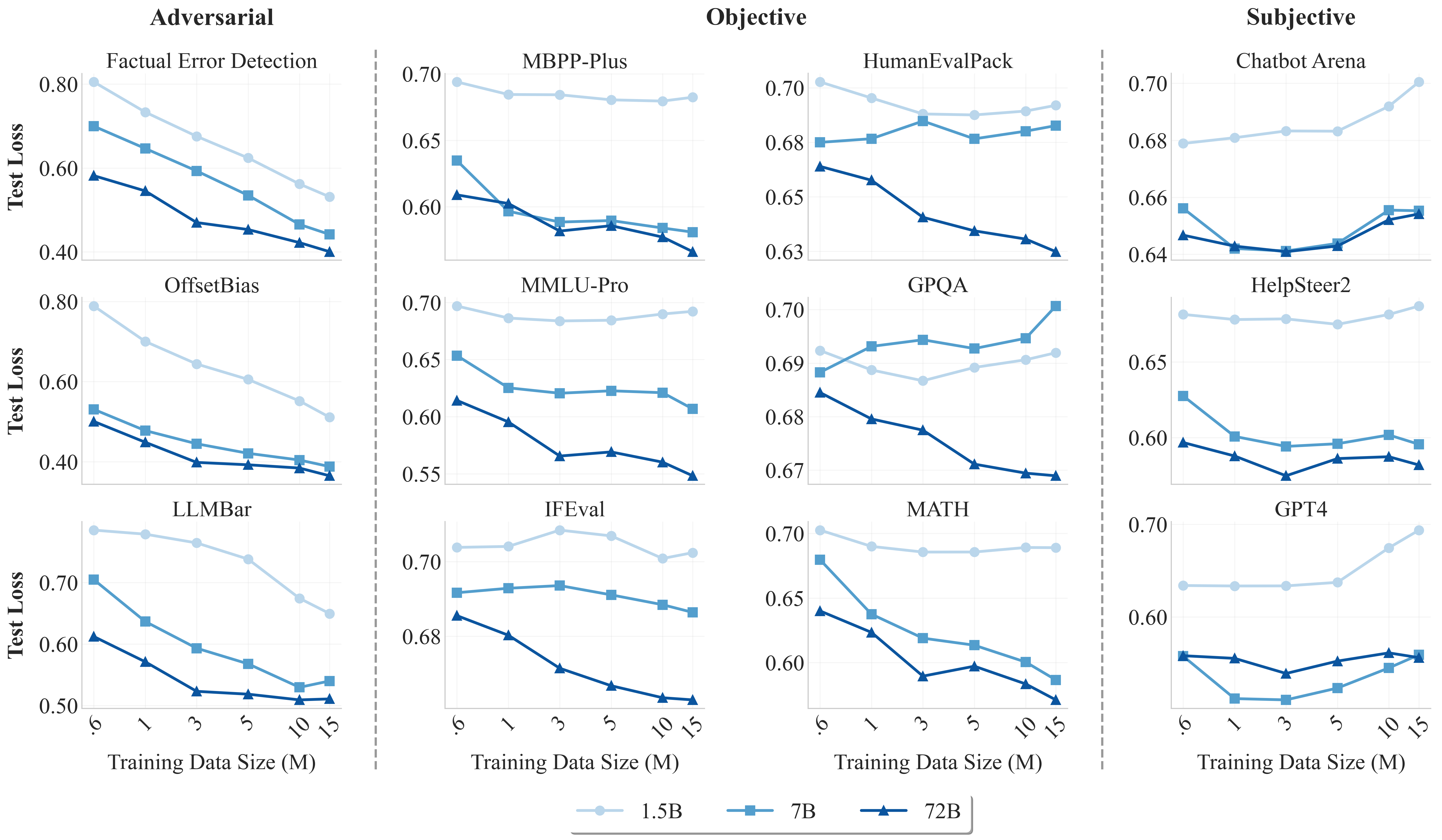
受语言建模中的缩放定律启发,该定律展示了测试损失如何随着模型和数据集的规模呈幂律关系扩展,我们发现类似的定律也存在于偏好建模中。我们提出了世界偏好建模(WorldPM)来强调这种扩展潜力,其中世界偏好体现了人类偏好的统一表示。在本文中,我们从涵盖多样化用户社区的公共论坛中收集了偏好数据,并使用从1.5B到72B参数的模型在15M规模的数据上进行了广泛的训练。我们观察到不同评估指标之间的显著模式:(1)对抗性指标(识别欺骗性特征的能力)随着训练数据和基础模型规模的增加而持续扩展;(2)客观指标(具有明确答案的客观知识)在更大的语言模型中表现出涌现行为,突显了WorldPM的可扩展性潜力;(3)主观指标(来自有限数量人类或AI的主观偏好)并未显示出扩展趋势。进一步的实验验证了WorldPM作为偏好微调基础的有效性。通过在7个基准测试中的20个子任务上进行评估,我们发现WorldPM广泛提高了不同规模(7K、100K和800K样本)人类偏好数据集的泛化性能,在许多关键子任务上性能提升超过5%。将WorldPM集成到我们的内部RLHF管道中,我们观察到在内部和公共评估集上均有显著改进,内部评估中的显著提升为4%到8%。
🔍 关键发现
- 在对抗性评估中,测试损失呈现出幂律下降,表明模型在识别故意错误的回答以及那些写得好但不相关或不完整的回答方面的能力有所增强。
- 客观指标揭示了一种新兴现象,即更大的模型在更多基准测试中表现出测试损失的幂律下降。WorldPM 代表了一项具有挑战性的任务,它需要更大的模型来引发对客观知识的偏好,这表明其具有进一步发展的巨大潜力。
- 主观评估没有显示出明显的扩展趋势。我们从风格偏好的角度分析了潜在原因。虽然 WorldPM 在扩展过程中变得更加风格中立,但一些主观评估表现出风格偏好,导致评估性能较低。
🤔 深入探讨:理解偏好建模中的扩展
为什么主观领域无法扩展
在我们的偏好建模扩展实验中,我们观察到客观领域有明显的扩展趋势,但在主观领域却没有。我们将此归因于主观评估的多维性——评估结果本质上是多个维度的平均值。这导致在某些维度上出现正向扩展,而在其他维度上出现负向扩展,从而在整体上表现出缺乏扩展的现象。值得注意的是,正如我们在论文中解释的那样,对于某些表面层次的维度(如风格),WorldPM克服了这些偏差,导致评估分数显著降低。
为什么偏好建模是可扩展的
💡 关键见解
偏好建模的可扩展性可能看起来违反直觉,主要有两个方面的担忧:
-
任务视角:偏好建模似乎过于简单,只有二元信号(指示哪个响应更受青睐),导致监督稀疏。
-
数据视角:人类论坛数据看起来嘈杂,似乎难以扩展。
解决担忧
关于稀疏监督:考虑为什么下一个词预测能成功建模语言——为了准确预测下一个词(例如,有90%的概率),语言模型必须理解全面的语言规则。同样,为了成功预测90%的偏好数据集标签,模型必须学习足够普遍的人类偏好表示。
关于噪声数据:噪声指的是标签或监督信号中的明显随机性。然而,由于论坛数据代表了真实的人类注释,它本身就包含其自身的合理性。即使个体的人类智能无法辨别模式,强大的语言模型也能发现潜在的结构。
关键结论
神经网络的可扩展性可能既不依赖于密集的监督信号,也不依赖于精确的监督信号。只要监督信号是合理且具有挑战性的,扩展就是可能的——尽管密集和精确的信号会加速收敛。
🎯 模型使用
基础模型与微调变体
WorldPM 通过大规模训练在统一偏好表示学习方面取得了突破。虽然我们的实验展示了在各种偏好场景下的强大泛化能力,但我们建议进行任务特定的微调以获得最佳性能。
基础模型
- 🌟 WorldPM-72B
微调版本
每个模型都在不同规模的人类偏好数据集上进行了微调:
| Model | Dataset | Training Scale |
|---|---|---|
| WorldPM-72B-HelpSteer2 | HelpSteer2 | 7K |
| WorldPM-72B-UltraFeedback | UltraFeedback | 100K |
| WorldPM-72B-RLHFLow | RLHFLow | 800K |
💡 推荐
基础 WorldPM-72B 模型是进行自定义微调的绝佳起点。我们的实验证实,与从头开始训练相比,从 WorldPM 开始能带来更好的性能。
🚀 Quick Start
安装最新的transformers
from transformers import AutoModel, AutoTokenizer, AutoConfigmodel_name = 'Qwen/WorldPM-72B'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
config = AutoConfig.from_pretrained(model_name,trust_remote_code=True )
model = AutoModel.from_pretrained(model_name, config = config, device_map = "auto", trust_remote_code=True,
).eval()def get_score(model, tokenizer, conversation):con_str = tokenizer.apply_chat_template(conversation, tokenize=False, add_generation_prompt=False)input_ids = tokenizer.encode(con_str, return_tensors="pt", add_special_tokens=False)outputs = model(input_ids=input_ids.to(model.device))score = outputs[0].cpu().item()return scoremessages = [[{'role': 'system', 'content': ""},{'role': 'user', 'content': "Tips for better sleep?"},{'role': 'assistant', 'content': "Three key tips for better sleep:\n1. Set a consistent bedtime and wake-up schedule\n2. Avoid screens 1 hour before bed\n3. Keep your bedroom cool and dark\n\nStart with these habits and you should notice improvement within a week."}],[{'role': 'system', 'content': ""},{'role': 'user', 'content': "Tips for better sleep?"},{'role': 'assistant', 'content': "just try sleeping earlier or take some pills if u cant sleep lol. maybe watch tv until u get tired idk"}]
]score = [get_score(model, tokenizer=tokenizer, conversation=message) for message in messages]print(score) #[0.6298332214355469, -1.6425328254699707] for WorldPM-72B