常用算法/机理模型演示平台搭建(一)
算法/机理模型演示平台搭建
- 一、算法列表(app/algorithms)
- 二、行业机理模型 (app/models)
- 三、如何使用
本项目旨在为初学者提供 35种 常用算法和 9种 行业机理模型的简单Python实现或概念说明。每个算法都有其独特的应用场景,从数据预测、质量检测、过程控制到结构分析和优化问题,以及系统仿真。
希望通过这些简单的示例,帮助你初步了解这些算法的基本原理和潜在应用。
最终能够实现:
-
算法服务器部署(FastApi)
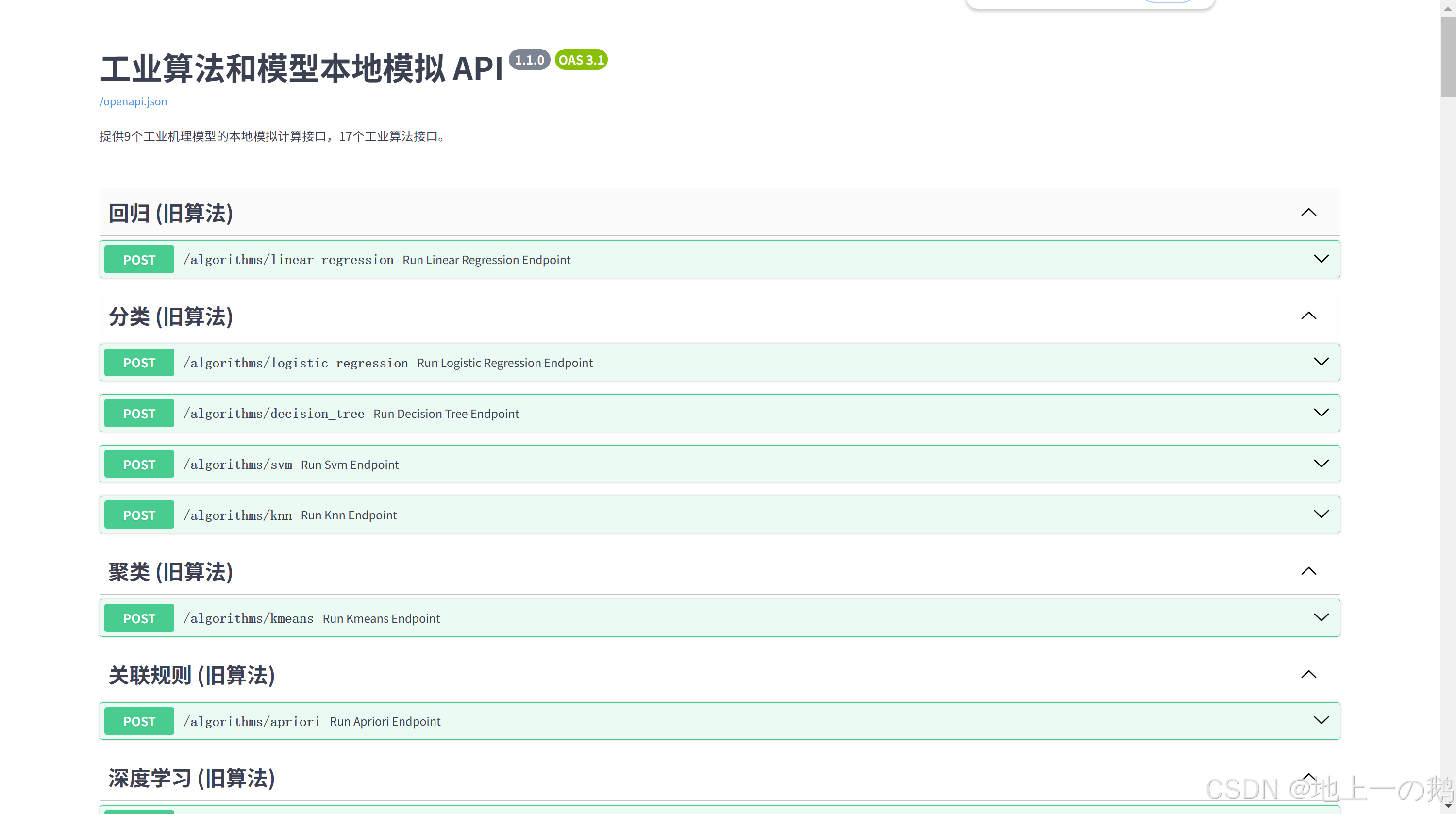
-
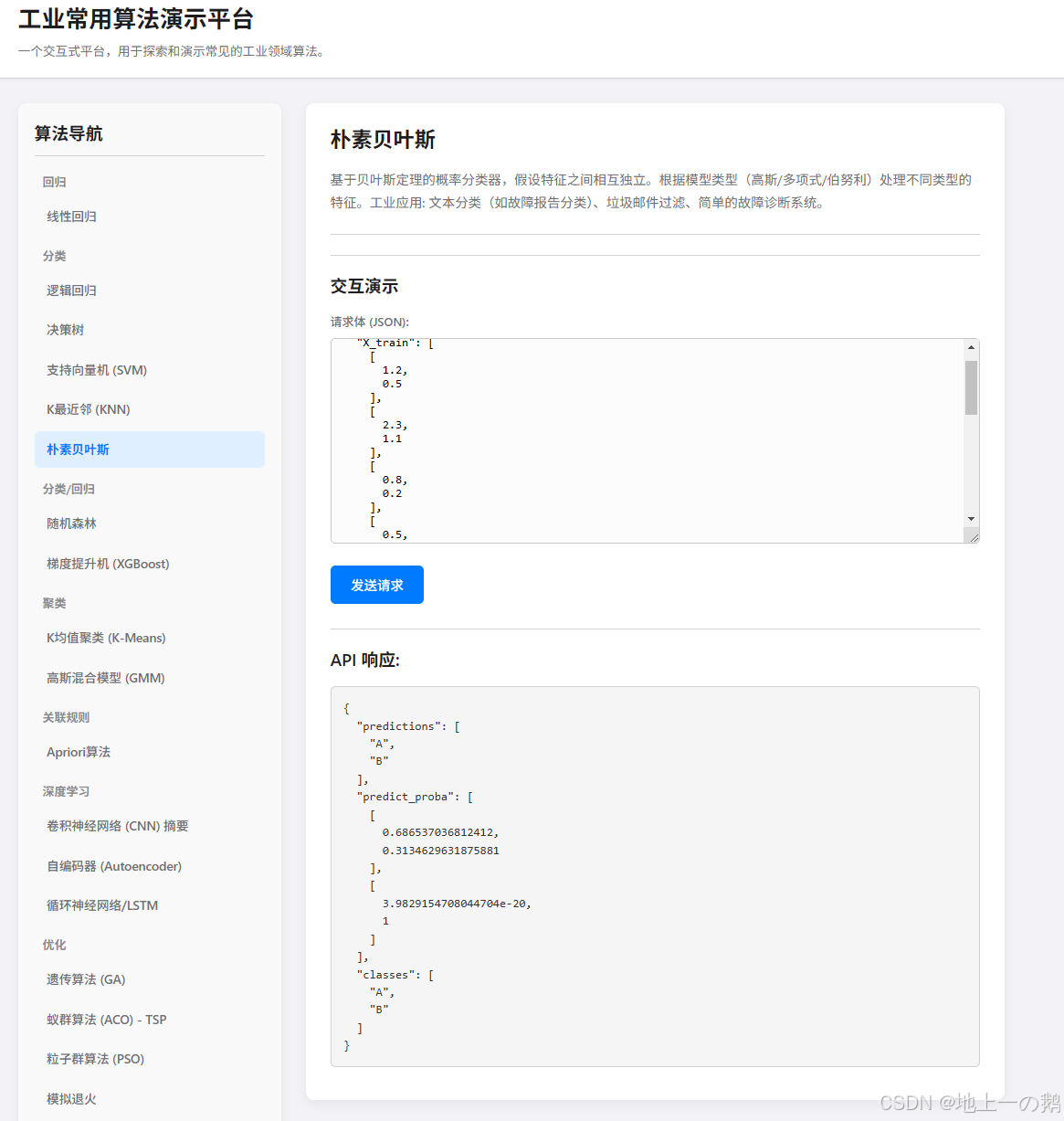
算法演示平台搭建
-
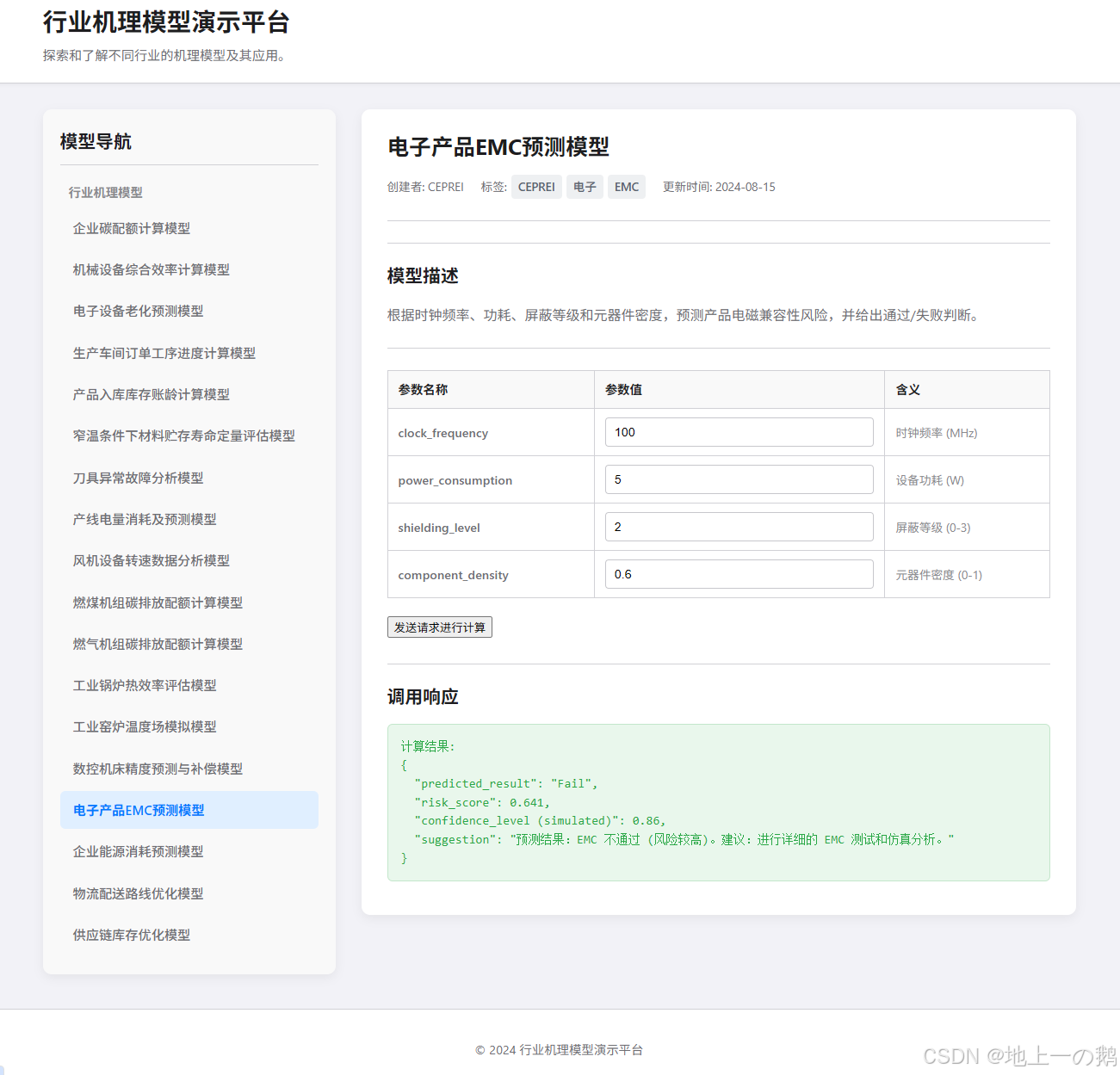
行业机理模型演示平台搭建
一、算法列表(app/algorithms)
-
线性回归 (Linear Regression) (
linear_regression.py)- 简介: 通过找到数据点之间的最佳拟合直线(或超平面)来进行预测。
- 应用: 需求预测、设备性能预测、成本估算等。
-
逻辑回归 (Logistic Regression) (
logistic_regression.py)- 简介: 用于处理分类问题,预测一个事件发生的概率(例如,是/否,合格/不合格)。
- 应用: 故障诊断(预测设备是否会故障)、质量检测(判断产品是否合格)、客户流失预测。
-
决策树 (Decision Tree) (
decision_tree.py)- 简介: 通过一系列"是/否"问题来对数据进行分类或预测,形成一个树状结构。
- 应用: 生产决策(选择最佳工艺路线)、故障原因分析、质量控制规则制定。
-
支持向量机 (SVM) (
svm.py)- 简介: 找到一个最佳的边界(超平面)来区分不同的数据类别,特别擅长处理复杂和高维数据。
- 应用: 预测性维护(基于传感器数据预测故障)、工业图像识别(零件识别、缺陷检测)、过程状态监控。
-
K最近邻 (KNN) (
knn.py)- 简介: 通过查找与新数据点最相似(最近)的K个已知数据点,来判断新数据点的类别或数值。
- 应用: 产品质量分类、设备状态识别、异常检测。
-
K均值聚类 (K-Means) (
kmeans.py)- 简介: 将数据自动分成K个簇(组),使得同一个簇内的数据尽可能相似,不同簇的数据尽可能不同。
- 应用: 生产数据分析(识别不同生产模式)、客户分群、设备工况聚类。
-
Apriori算法 (
apriori.py)- 简介: 用于发现数据项之间的有趣关联规则(例如,“购买A的顾客通常也会购买B”)。
- 应用: 生产流程优化(发现工序间的关联)、物料关联分析、设备故障关联模式挖掘。
-
卷积神经网络 (CNN) (
cnn.py)- 简介: 深度学习的一种,特别擅长处理图像数据,能自动学习图像的特征。
- 应用: 工业视觉检测(产品外观缺陷、尺寸测量)、机器人视觉导航、人脸识别门禁。
- 注意:
cnn.py文件提供的是概念性代码框架,运行可能需要安装深度学习库(如TensorFlow)。 API 提供获取模型摘要的功能。
-
有限元分析 (FEA) (
fea.py)- 简介: 将复杂的物理结构分解成许多小单元,通过计算每个单元的行为来模拟整体结构的力学响应。
- 应用: 结构强度分析、热力学分析、流体动力学模拟等。
- 注意:
fea.py文件提供的是概念性说明,API 提供获取说明文本的功能。
-
网格剖分 (Meshing) (
meshing.py)- 简介: 将复杂的几何模型划分成适合数值模拟的网格的过程。
- 应用: 有限元分析前处理、计算流体力学(CFD)模拟、CAD。
- 注意:
meshing.py文件提供的是概念性说明,API 提供获取说明文本的功能。
-
遗传算法 (Genetic Algorithm) (
genetic_algorithm.py)- 简介: 模拟生物进化来搜索复杂问题的最优解或近似最优解。
- 应用: 生产调度优化、物流路径规划、工艺参数优化。
-
蚁群算法 (Ant Colony Optimization, ACO) (
aco.py)- 简介: 模拟蚂蚁觅食行为解决组合优化问题。
- 应用: 旅行商问题(TSP)、车辆路径规划(VRP)、任务分配。
-
粒子群算法 (Particle Swarm Optimization, PSO) (
pso.py)- 简介: 模拟鸟群觅食行为进行优化计算。
- 应用: 函数优化、参数辨识、控制策略优化。
-
插值算法 (Interpolation) (
interpolation.py)- 简介: 根据已知离散数据点,估计在这些点之间的未知点的值。
- 应用: 数据平滑与拟合、曲线/曲面生成、信号恢复。
-
PID 控制器 (PID Controller) (
pid_controller.py)- 简介: 根据设定值与测量值之间的误差,通过比例、积分、微分计算来调整控制输出。
- 应用: 温度控制、压力控制、流量控制、液位控制、电机速度控制等几乎所有自动化控制回路。
- 注意: API 计算单步输出,状态(如积分累积)需调用方管理。
-
卡尔曼滤波器 (Kalman Filter) (
kalman_filter.py)- 简介: 在存在噪声的情况下,对动态系统的状态进行最优估计,结合预测和测量进行更新。
- 应用: 传感器数据融合、目标跟踪(如机器人导航)、状态估计、过程监控。
- 注意: API 实现简化的 1D 线性滤波器单步更新,状态(估计值和协方差)需调用方管理。
-
快速傅里叶变换 (FFT) (
fft_analysis.py)- 简介: 将时域信号转换到频域,分析信号包含的频率成分及其强度。
- 应用: 设备振动分析(故障诊断)、状态监测、噪声分析、信号去噪、电力系统谐波分析。
-
朴素贝叶斯 (Naive Bayes) (
naive_bayes.py)- 简介: 基于贝叶斯定理的概率分类器,假设特征之间相互独立。
- 应用: 文本分类(如故障报告分类)、垃圾邮件过滤、简单的故障诊断系统。
-
随机森林 (Random Forest) (
random_forest.py)- 简介: 集成学习方法,通过构建多个决策树并集成它们的预测结果来提高准确性和减少过拟合。
- 应用: 故障预测、产品质量分类、需求预测、参数优化。
-
梯度提升机 (Gradient Boosting) (
gradient_boosting.py)- 简介: 通过迭代地构建弱学习器(通常是决策树)并将它们组合成一个强学习器的集成方法。
- 工业应用: 预测性维护、能耗预测、产品质量控制、异常检测。
-
主成分分析 (PCA) (
pca.py)- 简介: 一种无监督学习的降维技术,通过找到高维数据中的主要变化方向来减少数据维度。
- 应用: 多传感器数据降维、特征提取、数据可视化、噪声消除。
-
奇异值分解 (SVD) (
svd.py)- 简介: 一种矩阵分解技术,将矩阵分解为三个矩阵的乘积,广泛用于降维和数据压缩。
- 应用: 图像压缩、推荐系统、噪声过滤、潜在语义分析。
-
自编码器 (Autoencoder) (
autoencoder.py)- 简介: 一种神经网络架构,学习将输入压缩到低维表示,然后重构回原始输入,用于数据压缩和特征学习。
- 应用: 异常检测、噪声消除、传感器数据压缩、故障特征提取。
- 注意: 需要 TensorFlow 或其他深度学习库。
-
循环神经网络/长短期记忆网络 (RNN/LSTM) (
rnn_lstm.py)- 简介: 处理序列数据的神经网络,RNN有短期记忆能力,LSTM改进了长期依赖问题。
- 应用: 时间序列预测、设备状态监测、自然语言处理、预测性维护。
- 注意: 需要 TensorFlow 或其他深度学习库。
-
强化学习 (Reinforcement Learning) (
reinforcement_learning.py)- 简介: 通过与环境交互来学习最优行为策略的机器学习范式,基于奖励和惩罚机制。
- 应用: 自动化控制策略、生产调度优化、机器人导航、能源管理。
- 注意: 当前实现提供Q-Learning的概念说明。
-
异常检测 (Anomaly Detection) (
anomaly_detection.py)- 简介: 使用孤立森林算法识别数据中的异常点或模式,不需要已标记的训练数据。
- 应用: 设备故障检测、产品质量监控、网络安全监测、传感器数据异常识别。
-
模糊逻辑 (Fuzzy Logic) (
fuzzy_logic.py)- 简介: 基于"模糊集合"理论的逻辑系统,处理介于"真"与"假"之间的"部分真实"概念。
- 应用: 复杂工艺控制(如窑炉控制)、智能家电控制、模式识别、决策支持系统。
- 注意: 当前实现提供概念说明。
-
蒙特卡洛模拟 (Monte Carlo Simulation) (
monte_carlo.py)- 简介: 使用随机抽样和统计分析来估计复杂系统的行为和结果分布。
- 应用: 风险评估、可靠性分析、项目进度估计、金融预测、库存优化。
-
模拟退火 (Simulated Annealing) (
simulated_annealing.py)- 简介: 受冶金退火过程启发的随机优化算法,通过控制"温度"参数搜索全局最优解。
- 应用: 作业调度、物流路径规划、布局优化、电路设计。
-
贝叶斯优化 (Bayesian Optimization) (
bayesian_optimization.py)- 简介: 用于优化昂贵黑箱函数的全局优化方法,通过概率模型指导搜索过程。
- 应用: 超参数调优、实验设计、复杂工艺参数优化、传感器网络布局。
- 注意: 当前实现提供概念说明。
-
高斯混合模型 (GMM) (
gmm.py)- 简介: 假设数据由多个高斯分布组合而成的概率模型,用于概率聚类和密度估计。
- 应用: 复杂数据聚类、异常检测、语音识别、图像分割。
-
时间序列分析 (ARIMA) (
arima.py)- 简介: 自回归积分移动平均模型,用于分析和预测时间序列数据。
- 应用: 需求预测、库存规划、能源消耗预测、设备性能趋势分析。
- 注意: 需要 statsmodels 库。
-
离散事件模拟 (DES) (
discrete_event_simulation.py)- 简介: 模拟系统中事件在离散时间点发生的过程,分析系统性能。
- 应用: 生产线效率分析、物流中心吞吐量模拟、呼叫中心排队优化、医院资源调度。
- 注意: API 实现为概念性简化模拟。
-
基于主体的建模 (ABM) (
agent_based_modeling.py)- 简介: 模拟大量自主主体(Agent)的微观行为及其相互作用,观察系统宏观层面的涌现现象。
- 应用: 供应链韧性分析、工厂工人行为模拟、市场扩散模型、交通流仿真。
- 注意: API 实现为概念性简化模拟。
-
系统动力学 (SD) (
system_dynamics.py)- 简介: 使用存量、流量和反馈回路来模拟复杂系统随时间变化的动态行为。
- 应用: 长期战略规划、市场动态分析、资源管理策略评估、环境影响建模。
- 注意: API 实现为概念性简化模拟。
二、行业机理模型 (app/models)
app/models 目录包含用于定义 FastAPI 端点请求体和响应体的数据模型 (Pydantic 模型)。这些模型确保了 API 接收和返回的数据结构是正确的。
inventory_optimization.py: 库存优化相关的数据模型。logistics_route.py: 物流路线规划相关的数据模型。energy_consumption.py: 能耗预测相关的数据模型。emc_prediction.py: 电磁兼容性 (EMC) 预测相关的数据模型。cnc_accuracy.py: CNC 机床精度相关的数据模型。kiln_temperature.py: 窑炉温度控制或预测相关的数据模型。boiler_efficiency.py: 锅炉效率相关的数据模型。carbon_quota_gas.py: 燃气相关的碳配额计算模型。carbon_quota_coal.py: 燃煤相关的碳配额计算模型。
这些模型定义了各个 API 端点所需输入数据的字段、类型和验证规则,以及 API 响应数据的结构。
三、如何使用
每个 .py 文件包含对应算法的简单实现或说明。阅读代码中的注释可以帮助你理解算法的基本步骤。
注意: 某些算法(如CNN、样条插值、FFT)可能需要安装额外的Python库(tensorflow, scipy, numpy)才能通过 API 使用其全部功能。请确保 requirements.txt 中包含这些依赖,并在构建 Docker 镜像时成功安装。
1. 构建 Docker 镜像:
在包含 Dockerfile 的项目根目录下,运行以下命令构建镜像:
docker build -t industrial-algorithms-api .
2. 运行 Docker 容器:
构建成功后,运行以下命令启动容器:
docker run -d --name industrial-algo-container -p 8000:8000 industrial-algorithms-api
-d: 在后台运行容器。--name industrial-algo-container: 为容器指定一个名称。-p 8000:8000: 将主机的 8000 端口映射到容器的 8000 端口。
3. 访问 API 文档:
容器运行后,在浏览器中访问 http://localhost:8000/docs (或 http://<你的Docker主机IP>:8000/docs,如果 Docker 不在本地运行)。
你将看到由 FastAPI 自动生成的交互式 API 文档 (Swagger UI),其中列出了所有可用的算法端点、所需的输入参数(请求体)和预期的输出格式(响应体)。
4. 调用 API :
你可以使用 API 文档页面直接发送请求来测试各个算法,或者使用 curl、Postman 或其他编程语言(如 Python 的 requests 库)向以下端点发送 POST 或 GET 请求:
/algorithms/linear_regression(POST)/algorithms/logistic_regression(POST)/algorithms/decision_tree(POST)/algorithms/svm(POST)/algorithms/knn(POST)/algorithms/kmeans(POST)/algorithms/apriori(POST)/algorithms/cnn_summary(POST) - 获取 CNN 模型摘要/algorithms/fea_explanation(GET) - 获取 FEA 说明/algorithms/meshing_explanation(GET) - 获取 Meshing 说明/algorithms/genetic_algorithm(POST)/algorithms/aco_tsp(POST)/algorithms/pso(POST)/algorithms/interpolation(POST)/algorithms/pid_control(POST)/algorithms/kalman_filter(POST)/algorithms/fft_analysis(POST)/algorithms/naive_bayes(POST) - 新增/algorithms/random_forest(POST) - 新增/algorithms/gradient_boosting(POST) - 新增/algorithms/pca(POST) - 新增/algorithms/svd(POST) - 新增/algorithms/autoencoder(POST) - 新增/algorithms/rnn_lstm(POST) - 新增/algorithms/reinforcement_learning_concept(GET) - 新增/algorithms/anomaly_detection(POST) - 新增/algorithms/fuzzy_logic_concept(GET) - 新增/algorithms/monte_carlo(POST) - 新增/algorithms/simulated_annealing(POST) - 新增/algorithms/bayesian_optimization_concept(GET) - 新增/algorithms/gmm(POST) - 新增/algorithms/arima(POST) - 新增/algorithms/discrete_event_simulation(POST) - 新增/algorithms/agent_based_modeling(POST) - 新增/algorithms/system_dynamics(POST) - 新增
请求体示例:
下面是每个 POST 端点所需请求体的示例 JSON 数据。
请注意,对于 genetic_algorithm 和 pso,API 目前使用固定的示例函数进行优化,请求体主要用于调整算法参数。
对于新增的模拟算法 (DES, ABM, SD),API 实现也是概念性的简化模拟。
-
/algorithms/linear_regression{"x_train": [1, 2, 3, 4, 5],"y_train": [2, 4, 5, 4, 5],"x_predict": [6, 7, 8],"learning_rate": 0.01,"epochs": 1000 } -
/algorithms/logistic_regression{"x_train": [1, 2, 3, 6, 7, 8],"y_train": [0, 0, 0, 1, 1, 1],"x_predict": [4, 5],"learning_rate": 0.05,"epochs": 2000,"threshold": 0.5 } -
/algorithms/decision_tree{"X_train": [[1, 1],[1, 0],[0, 1],[0, 0],[1, 1],[0, 1]],"y_train": [1, 1, 0, 0, 1, 0],"X_predict": [[1, 0],[0, 0]],"max_depth": 2 } -
/algorithms/svm{"X_train": [[1, 2], [2, 3], [3, 3],[6, 5], [7, 8], [8, 6]],"y_train": [1, 1, 1, -1, -1, -1],"X_predict": [[2, 2],[7, 7]],"learning_rate": 0.001,"epochs": 5000,"lambda_param": 0.01 } -
/algorithms/knn{"X_train": [[30, 0.5], [35, 0.6], [40, 0.7],[50, 1.0], [55, 1.1], [60, 1.2],[70, 1.5], [75, 1.6], [80, 1.8]],"y_train": [0, 0, 0, 1, 1, 1, 2, 2, 2],"X_predict": [[45, 0.9],[65, 1.4]],"k": 3 } -
/algorithms/kmeans{"X": [[1, 1], [1, 2], [2, 1], [2, 2],[8, 8], [8, 9], [9, 8], [9, 9],[1, 8], [9, 1]],"k": 2,"max_iters": 100,"tol": 0.0001,"random_state": 42 } -
/algorithms/apriori{"dataset": [["部件A", "部件B", "部件E"],["部件B", "部件D"],["部件B", "部件C"],["部件A", "部件B", "部件D"],["部件A", "部件C"],["部件B", "部件C"],["部件A", "部件C"],["部件A", "部件B", "部件C", "部件E"],["部件A", "部件B", "部件C"]],"min_support": 0.2,"min_confidence": 0.6 } -
/algorithms/cnn_summary{"input_shape": [64, 64, 3],"num_classes": 5 } -
/algorithms/genetic_algorithm{"pop_size": 100,"gene_length": 22,"bounds": [-2.0, 2.0],"crossover_rate": 0.85,"mutation_rate": 0.02,"n_generations": 150,"random_state": 123 } -
/algorithms/aco_tsp{"city_coords": [[0, 0],[1, 5],[3, 1],[6, 4],[8, 2]],"num_ants": 20,"num_iterations": 150,"alpha": 1.0,"beta": 2.5,"rho": 0.6,"q": 100,"random_state": 456 } -
/algorithms/pso{"dimensions": 2,"num_particles": 40,"max_iterations": 100,"w": 0.7,"c1": 1.8,"c2": 1.8,"bounds": [-5.0, 5.0],"random_state": 789 } -
/algorithms/interpolation{"x_known": [0, 1, 2, 3, 4, 5],"y_known": [15, 18, 22, 19, 17, 20],"x_target": [1.5, 2.5, 3.5],"method": "cubic_spline" }method可以是 “linear”, “lagrange”, 或 “cubic_spline”.x_target也可以是单个数值,例如2.5.
-
/algorithms/pid_control(新增){"setpoint": 100.0,"measurement": 95.5,"prev_error": 5.0,"integral_sum": 12.3,"kp": 0.8,"ki": 0.1,"kd": 0.05,"dt": 0.1,"integral_min": -50.0,"integral_max": 50.0 } -
/algorithms/kalman_filter(新增){"x_hat_prev": 25.5,"P_prev": 1.0,"measurement": 26.1,"process_noise_variance": 0.01,"measurement_noise_variance": 0.1 } -
/algorithms/fft_analysis(新增){"signal": [0.5, 0.7, 0.5, 0.2, -0.1, -0.3, -0.2, 0.1, 0.5, 0.7, 0.5, 0.2, -0.1, -0.3, -0.2, 0.1],"sampling_rate": 100.0 } -
/algorithms/naive_bayes(新增){"X_train": [[1.2, 0.5], [2.3, 1.1], [0.8, 0.2], [0.5, 1.5], [3.2, 0.8]],"y_train": ["A", "B", "A", "B", "B"],"X_predict": [[1.0, 0.7], [2.8, 0.9]],"model_type": "gaussian" }model_type可以是 “gaussian”(适用于连续特征), “multinomial”(适用于离散计数,如词频),或 “bernoulli”(适用于二元/布尔特征)。
-
/algorithms/random_forest(新增){"X_train": [[1.2, 0.5, 2.1], [2.3, 1.1, 0.8], [0.8, 0.2, 1.5], [0.5, 1.5, 0.9], [3.2, 0.8, 2.2]],"y_train": [1, 2, 1, 2, 2],"X_predict": [[1.0, 0.7, 1.8], [2.8, 0.9, 1.2]],"task_type": "classification","n_estimators": 100,"max_depth": 5,"test_size": 0.2 }task_type可以是 “classification”(分类)或 “regression”(回归)。
-
/algorithms/gradient_boosting(新增){"X_train": [[1.2, 0.5, 2.1], [2.3, 1.1, 0.8], [0.8, 0.2, 1.5], [0.5, 1.5, 0.9], [3.2, 0.8, 2.2], [2.8, 1.2, 0.5]],"y_train": [10.5, 12.8, 9.7, 11.2, 13.5, 12.1],"X_predict": [[1.0, 0.7, 1.8], [2.8, 0.9, 1.2]],"objective": "reg:squarederror","n_estimators": 100,"learning_rate": 0.1,"max_depth": 3,"test_size": 0.2 }objective可以是 “reg:squarederror”(回归), “binary:logistic”(二分类),或 “multi:softmax”(多分类)。
-
/algorithms/pca(新增){"X": [[1.2, 0.5, 2.1, 1.8], [2.3, 1.1, 0.8, 2.3], [0.8, 0.2, 1.5, 1.1], [0.5, 1.5, 0.9, 0.7], [3.2, 0.8, 2.2, 2.5]],"n_components": 2 } -
/algorithms/svd(新增){"X": [[1.2, 0.5, 2.1], [2.3, 1.1, 0.8], [0.8, 0.2, 1.5], [0.5, 1.5, 0.9]],"n_components": 2,"full_matrices": false } -
/algorithms/autoencoder(新增){"X": [[1.2, 0.5, 2.1, 1.8, 0.3], [2.3, 1.1, 0.8, 2.3, 1.2], [0.8, 0.2, 1.5, 1.1, 0.9], [0.5, 1.5, 0.9, 0.7, 1.8]],"encoding_dim": 2,"epochs": 50,"batch_size": 2,"validation_split": 0.0 } -
/algorithms/rnn_lstm(新增){"time_series": [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120],"look_back": 3,"model_type": "lstm","units": 4,"epochs": 100,"batch_size": 1,"n_forecast_steps": 5 }model_type可以是 “rnn” 或 “lstm”。
-
/algorithms/anomaly_detection(新增){"X": [[1.2, 0.5], [2.3, 1.1], [0.8, 0.2], [0.5, 1.5], [3.2, 0.8], [15.0, 20.0], [2.5, 1.2]],"n_estimators": 100,"contamination": "auto","random_state": 42 }contamination可以是 “auto” 或一个介于 (0, 0.5] 的浮点数,表示预期的异常样本比例。
-
/algorithms/monte_carlo(新增){"num_simulations": 1000,"simulation_type": "investment_projection","params": {"initial_amount": 10000, "years": 10, "avg_return_rate": 0.07, "volatility": 0.15},"percentiles": [5, 25, 50, 75, 95],"return_all_results": false }simulation_type可以是 “dice_roll” 或 “investment_projection”。
-
/algorithms/simulated_annealing(新增){"problem_type": "rastrigin","initial_temperature": 100.0,"cooling_rate": 0.95,"max_iterations": 1000,"min_temperature": 0.001,"dimensions": 2,"bounds": [-5.0, 5.0],"return_history": true }problem_type可以是 “rastrigin”(连续优化)或 “tsp”(旅行商问题,组合优化)。- 对于 “tsp” 问题,需提供
city_coords参数而不是dimensions和bounds。
-
/algorithms/gmm(新增){"X": [[1.2, 0.5], [2.3, 1.1], [0.8, 0.2], [8.5, 9.5], [9.2, 8.8], [7.8, 9.1]],"n_components": 2,"max_iterations": 100,"tol": 1e-4,"random_state": 42,"return_responsibilities": false } -
/algorithms/arima(新增){"time_series": [100, 120, 140, 150, 145, 160, 170, 180, 175, 190, 210, 230],"order": [5, 1, 0],"n_forecast_steps": 5,"confidence_level": 0.95 }order是 ARIMA 模型的 (p, d, q) 阶数。
-
/algorithms/discrete_event_simulation(新增){"num_servers": 2,"arrival_rate": 1.5,"avg_service_time": 1.0,"simulation_time": 200.0,"random_seed": 42 } -
/algorithms/agent_based_modeling(新增){"num_agents": 150,"grid_size": 25,"num_steps": 100,"interaction_rule": "seek_neighbor","params": {},"random_seed": 123 } -
/algorithms/system_dynamics(新增){"initial_stock": 50.0,"inflow_rate": 5.0,"outflow_factor": 0.1,"feedback_factor": -0.02,"simulation_steps": 100,"dt": 0.5 }
响应体示例 (K-Means):
{"centroids": [[1.5, 1.5],[8.5, 8.5]// ... (实际中心点会根据运行结果变化)],"labels": [0, 0, 0, 0, 1, 1, 1, 1, 0, 1 // (实际标签会根据运行结果变化)],"converged": true
}
请参考 /docs 页面获取每个端点的详细请求和响应格式。
重要说明:
- CNN 摘要端点需要 Docker 镜像中已安装 TensorFlow。
- 样条插值需要 Docker 镜像中已安装 SciPy。
- 对于优化算法(GA, ACO, PSO),API 目前使用预定义的示例目标函数。如果需要优化不同的函数,需要修改代码。
- 由于部分算法(如 K-Means, GA, ACO, PSO)包含随机性,即使使用相同的输入,每次调用的结果也可能略有不同,除非指定了
random_state参数。 - PID 和 Kalman Filter API 计算的是单步结果,若要模拟动态过程,调用方需要维护和传递状态信息(如
prev_error,integral_sum,x_hat_prev,P_prev)。