研读论文《Attention Is All You Need》(7)
原文 14
3.2 Attention
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
翻译
注意力函数可以被描述为将查询和一组键值对映射到输出的过程,其中查询、键、值和输出均为向量。输出的计算方式为值的加权和,而每个值对应的权重由查询与相应键的兼容性函数计算得出。
重点句子解析
- An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors.
【解析】
句子的结构是:主句+非限制性定语从句。主句采用了被动语态,其主干是:An attention function can be described as mapping A to B。其中,A代表a query and a set of key-value pairs,其中的a query和a set of key-value pairs是由and连接的两个并列名词短语;a set of(一组,一套) 和key-value都修饰pairs;B代表an output。be described as表示:被描述为,mapping A to B表示:把A映射到B。主句后边是where引导的非限制性定语从句,其中,where可以理解为“在此情况下”,指代前文描述的映射过程。从句属于“主系表”结构,其中的the query, keys, values, and output 是由逗号和and连接的四个并列名词,共同做主语。
【参考翻译】
注意力函数可以被描述为将查询和一组键值对映射到输出的过程,其中查询、键、值和输出均为向量。
- The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
【解析】
句子的结构是:主句+非限制性定语从句。主句是一个较为简单的被动句,其中,is computed as的字面意思是“被计算为”,也可以活译为“计算方式为”;a weighted sum表示“加权和”;介词短语of the values做后置定语,意为:这些值的。where引导定语从句,并且在从句中做状语,可以理解为:在前边所述的计算过程中;从句的主干是:the weight is computed by a compatibility function. 意思是说:权重通过兼容性函数来计算。原句中的过去分词短语assigned to each value做后置定语,修饰the weight,字面意思是:被赋予每个值的;介词短语of the query with the corresponding key做后置定语,修饰function。其中的另一个介词with表示前后两者有关联,可以译为“与…”。
【参考翻译】
输出的计算方式为值的加权和,其中,每个值对应的权重由查询与相应键的兼容性函数计算得出。
原文 15
3.2.1 Scaled Dot-Product Attention
We call our particular attention “Scaled Dot-Product Attention” (Figure 2). The input consists of queries and keys of dimension d k d_k dk , and values of dimension d v d_v dv. We compute the dot products of the query with all keys, divide each by d k \sqrt{d_k} dk, and apply a softmax function to obtain the weights on the values.
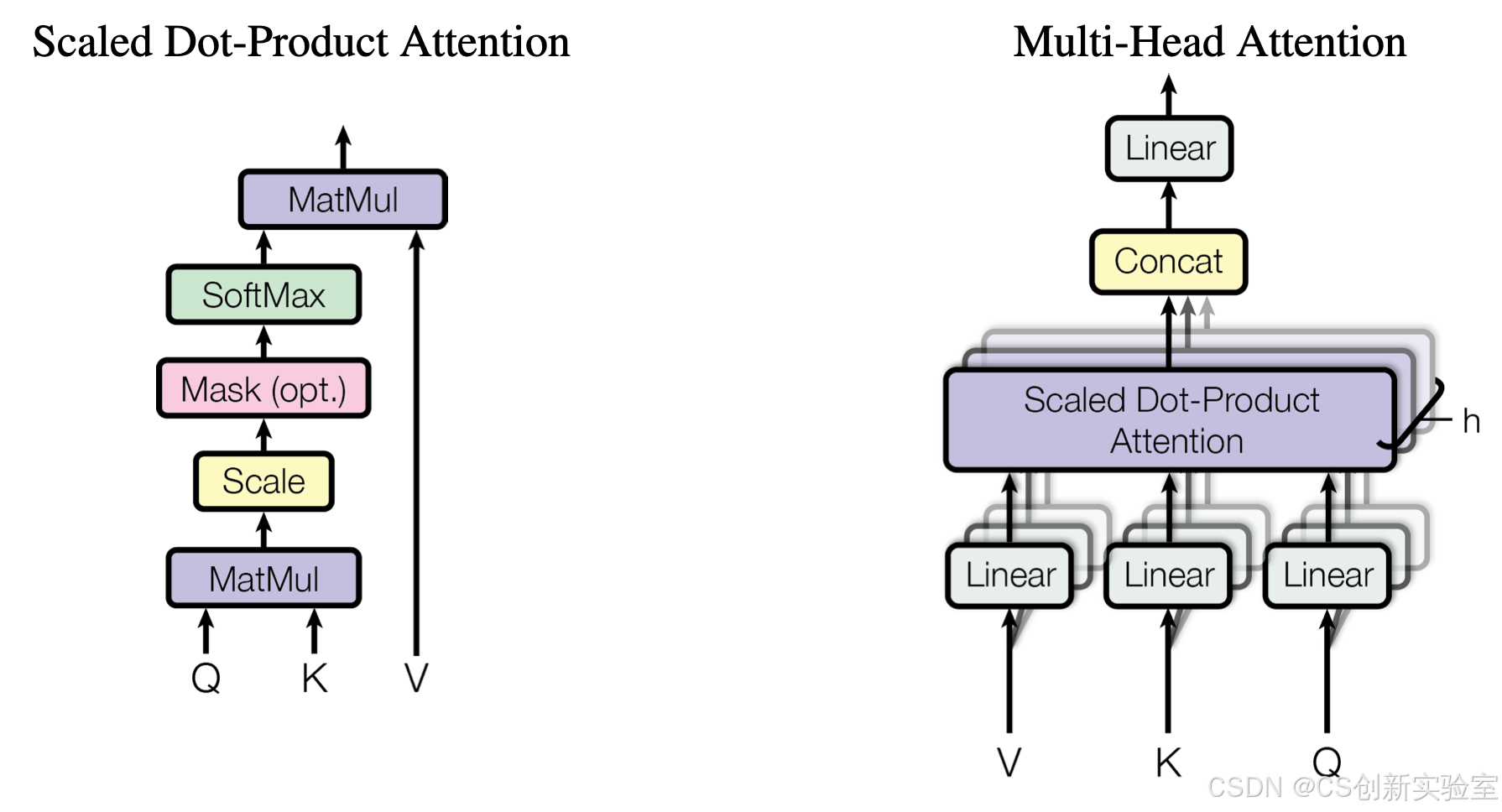
Figure 2: (left) Scaled Dot-Product Attention. (right) Multi-Head Attention consists of several attention layers running in parallel.
图2:(左)缩放点积注意力;(右)多头注意力机制由多个并行运行的注意力层组成。
翻译
3.2.1 缩放点积注意力
我们将这种特定的注意力称为"缩放点积注意力"(图2)。输入包含维度为 d k d_k dk 的查询(queries)和键(keys),以及维度为 d v d_v dv 的值(values)。我们首先计算查询与所有键的点积,然后将每个点积结果除以 d k \sqrt{d_k} dk ,最后应用softmax 函数得到值的权重分布。
重点句子解析
- We call our particular attention “Scaled Dot-Product Attention” .
【解析】
这个句子的结构是“主语+谓语+宾语+宾补”。谓语动词call后边的our particular attention是宾语,"Scaled Dot-Product Attention"是宾语补足语(简称宾补),对宾语进行补充说明。我们可以把宾语our particular attention看作A,把宾补Scaled Dot-Product Attention看作B,从而把整个句子简化为:We call A B(我们把A称为B)。
【参考翻译】
我们将这种特定的注意力称为“缩放点积注意力”。
- The input consists of queries and keys of dimension d k d_k dk, and values of dimension d v d_v dv.
【解析】
这个一个“主谓宾”结构的简单句,只不过用作谓语的动词短语consists of(包含;由……组成) 后边有两个宾语,一个是queries and keys of dimension dk,另一个是values of dimension dv。如果我们把第一个宾语queries and keys of dimension dk看作A,把第二个宾语values of dimension dv看作B,就可以把整个句子简化为:The input consists of A and B(输入包含A和B)。再来看queries and keys of dimension dk,这里的of dimension dk是后置定语,修饰前边的并列名词queries and keys;在values of dimension dv中也有一个介词短语of dimension dv充当后置定语。
【参考翻译】
输入包含维度为 d k d_k dk 的查询和键,以及维度为 d v d_v dv 的值。
- We compute the dot products of the query with all keys, divide each by d k \sqrt{d_k} dk, and apply a softmax function to obtain the weights on the values.
解析:
句子的主语“We”后边跟了三个并列的动宾结构,可以简化为:We compute the dot products, divide each, and apply a softmax function. 原句中的介词短语of the query with all keys是后置定语,其中的另一个介词with体现了the query 和all keys之间的关联;介词短语by d k \sqrt{d_k} dk是后置定语。结尾处的不定式短语 to obtain the weights on the values做目的状语,其中on the values是介词短语充当后置定语,修饰the weights。
【参考翻译】
我们首先计算查询与所有键的点积,然后将每个点积结果除以 d k \sqrt{d_k} dk,最后应用softmax函数得到值的权重分布。
原文 16
In practice, we compute the attention function on a set of queries simultaneously, packed together into a matrix Q Q Q. The keys and values are also packed together into matrices K K K and V V V . We compute the matrix of outputs as:
Attention ( Q , K , V ) = s o f t m a x ( Q K T d k ) V (1) \text{Attention}(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\tag{1} Attention(Q,K,V)=softmax(dkQKT)V(1)
The two most commonly used attention functions are additive attention, and dot-product (multi-plicative) attention. Dot-product attention is identical to our algorithm, except for the scaling factor of 1 d k \frac{1}{\sqrt{d_k}} dk1 . Additive attention computes the compatibility function using a feed-forward network with a single hidden layer. While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.
翻译
在实际操作中,我们会同时对一组查询进行注意力函数的计算,这些查询被一起打包成矩阵 Q Q Q。同样,键和值也分别被一起打包成矩阵 K K K 和 V V V。我们对输出的矩阵按以下公式计算:
Attention ( Q , K , V ) = s o f t m a x ( Q K T d k ) V (1) \text{Attention}(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\tag{1} Attention(Q,K,V)=softmax(dkQKT)V(1)
最常用的两种注意力函数是加性注意力和点积(乘法)注意力。点积注意力与我们的算法相同,只是有一个缩放因子 1 d k \frac{1}{\sqrt{d_k}} dk1 的差别。加性注意力使用含有单个隐藏层的前馈网络计算兼容性函数。虽然二者理论复杂度相似,但实践中点积注意力速度更快且空间利用率更高,因其可通过高度优化的矩阵乘法代码实现。