BERT 核心技术全解析:Transformer 双向编码与掩码语言建模的底层逻辑
一、引言:从 BERT 到生成式 AI 的进化之路
科学的突破从来不是孤立的奇迹,而是人类知识长河中无数基石的累积。 当我们惊叹于 ChatGPT、Google Bard 等大型语言模型(LLM)在生成式 AI 领域的惊人表现时,不能不回溯到 2018 年 ——Google 研究人员推出的 BERT,正是这场革命的起点。作为首批现代 LLM 之一,BERT 凭借 Transformer 架构的创新,重新定义了自然语言处理(NLP)的可能性,为后续的技术飞跃奠定了坚实基础。本文将深入解析 BERT 的架构、工作原理、实际应用及局限性,揭示其如何为 AI 时代的语言技术铺就道路。
二、BERT 的诞生:Transformer 架构的破局
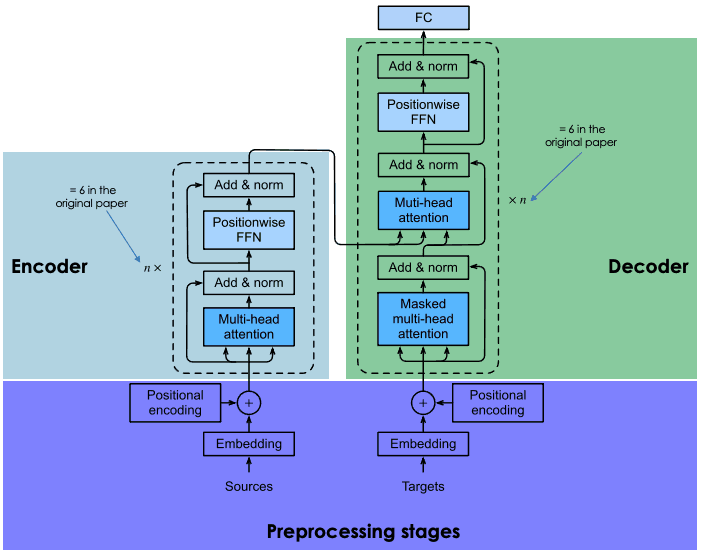
2.1 什么是 BERT?
BERT(Bidirectional Encoder Representations from Transformers)是 Google 于 2018 年开源的预训练语言模型,其核心是Transformer 架构—— 这一由 Google 在 2017 年论文《注意力就是你所需要的一切》中提出的创新神经架构,彻底改变了 NLP 的游戏规则。
在Transformer之前,递归神经网络(RNN)和卷积神经网络(CNN)是 NLP 的主流,但它们受限于单向预测(仅依赖前文或后文)和顺序计算(无法并行处理),难以捕捉复杂的语言上下文。BERT 通过双向编码和自注意力机制,让模型能够同时分析句子中单词的前后关系,显著提升了语言理解的准确性。
2.2 架构解析:Base 与 Large 的差异
BERT 推出时包含两个版本:
- BERT-Base:12 层 Transformer 编码器,12 头注意力机制,1.1 亿参数,适用于轻量级任务。
- BERT-Large:24 层 Transformer 编码器,16 头注意力机制,3.4 亿参数,在复杂任务中表现更优。
两者的核心区别在于层数和参数规模,后者通过更深的网络和更多注意力头,捕捉更精细的语义关联,在问答、文本分类等任务中精度更高。
三、BERT 的工作原理:双向学习与预训练策略
3.1 核心机制:掩码语言建模(MLM)
BERT 实现双向学习的关键是掩码语言建模(MLM):在训练时随机掩盖句子中 15% 的单词,迫使模型通过上下文双向推理被掩盖的词汇。例如:
原句:The quick brown fox jumps over the lazy dog.
掩码后:The quick [MASK] fox jumps over the [MASK] dog.
模型需结合前后文预测 “brown” 和 “lazy”,这种机制让模型深度理解词汇间的依赖关系,提升上下文感知能力。
3.2 预训练与微调:两步走的高效策略
- 预训练阶段:
BERT 在 Wikipedia(25 亿单词)和 BooksCorpus(8 亿单词)上进行了 4 天的训练,利用 Google 自研的 TPU(张量处理单元)加速计算。预训练的目标是学习通用语言表示,不针对特定任务。- 微调阶段:
开发人员可基于预训练模型,使用领域特定数据调整模型头部参数,适配具体任务(如情感分析、问答系统)。这种 “预训练 + 微调” 模式极大降低了开发成本,使 BERT 成为 NLP 任务的通用底座。
四、BERT 的应用场景:从实验室到现实世界

4.1 NLP 任务的全能选手
BERT 在以下领域展现了突破性性能:
- 问答系统:如 SQuAD 数据集上,BERT-Large 的准确率超过人类水平,能精准定位问题答案。
- 情感分析:分析电影评论时,可准确判断情感倾向(如 “这部电影特效震撼,但剧情拖沓”→中性偏负面)。
- 命名实体识别(NER):识别文本中的人名、地名、机构名,如从 “苹果公司成立于 1976 年” 中提取 “苹果公司”(组织实体)。
- 多语言翻译:基于跨语言预训练,BERT 可处理 70 余种语言,助力 Google 搜索的多语言优化。
4.2 现实案例:Google 搜索的 BERT 赋能
2020 年,Google 宣布将 BERT 集成到搜索算法中,提升 70 余种语言的搜索质量。例如,用户搜索 “如何缓解颈部疼痛” 时,BERT 会分析 “缓解”“颈部”“疼痛” 的上下文关联,优先展示包含拉伸建议、医学解释的内容,而非简单关键词匹配的结果。这一改进使搜索结果更符合用户意图,推动了搜索引擎从 “关键词匹配” 向 “语义理解” 的跨越。
4.3 代码案例:使用 BERT 进行情感分析
场景说明
分析用户对某产品的评论情感倾向(正面 / 负面),基于预训练的 BERT 模型进行微调。
代码实现
# 导入所需库
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
import torch
from datasets import load_dataset, DatasetDict# 加载预训练模型和分词器(以英文情感分析为例)
model_name = "bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2) # 2分类任务(正面/负面)# 加载示例数据集(IMDB影评数据集)
dataset = load_dataset("imdb")
# 转换为Hugging Face DatasetDict格式
dataset = DatasetDict({"train": dataset["train"].shuffle(seed=42).select(range(1000)), # 取前1000条训练数据"test": dataset["test"].shuffle(seed=42).select(range(100)), # 取前100条测试数据
})# 数据预处理函数:分词并截断/填充到固定长度
def preprocess_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=128)# 对数据集应用预处理
tokenized_datasets = dataset.map(preprocess_function, batched=True)# 定义训练参数
training_args = TrainingArguments(output_dir="./bert-sentiment-analysis", # 输出目录num_train_epochs=3, # 训练轮次per_device_train_batch_size=16, # 训练批次大小per_device_eval_batch_size=16, # 评估批次大小warmup_steps=500, # 学习率热身步数weight_decay=0.01, # 权重衰减logging_dir="./logs", # 日志目录evaluation_strategy="epoch", # 每轮评估一次save_strategy="epoch", # 每轮保存模型load_best_model_at_end=True, # 加载最优模型
)# 初始化Trainer
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["test"],
)# 训练模型
trainer.train()# 示例预测:分析一条影评的情感
example_review = "This movie was absolutely fantastic! The acting and plot were incredible."
inputs = tokenizer(example_review, padding=True, truncation=True, max_length=128, return_tensors="pt")
with torch.no_grad():outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=1).item()print(f"影评情感预测:{'正面' if predictions == 1 else '负面'}")
五、BERT 的进化:开源生态与变体创新
5.1 开源驱动的技术迭代
BERT 的开源特性催生了庞大的变体家族,以下是代表性改进:
- RoBERTa(Meta):使用 10 倍于 BERT 的训练数据(160GB 文本),采用动态掩码技术(同一单词在不同训练批次中随机掩码),提升模型鲁棒性,在 GLUE 基准测试中超越原版 BERT。
- DistilBERT(Hugging Face):通过知识蒸馏压缩模型,参数减少 40%,推理速度提升 60%,适用于移动端和嵌入式设备,如聊天机器人的实时响应。
- ALBERT:引入参数共享和跨层参数缩减技术,在保持性能的同时降低内存占用,适合资源受限的场景。
5.2 领域定制:微调模型的多样性
基于 BERT 的微调模型已覆盖多个垂直领域:
- BERT-base-Chinese:针对中文分词和语法特点优化,用于中文情感分析、新闻分类。
- BERT-base-NER:专注于命名实体识别,在医疗记录、法律文书中提取关键实体。
- BERT-Patent:在 1 亿 + 专利文献上训练,支持专利检索和技术趋势分析。
5.3 代码案例:使用 DistilBERT 进行快速推理
场景说明
在资源受限的设备(如手机 APP)上实现实时文本分类,使用轻量化模型 DistilBERT 提升推理速度。
代码实现
# 导入轻量化模型和分词器
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
import torch# 加载DistilBERT模型(参数比BERT减少40%)
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = DistilBertTokenizer.from_pretrained(model_name)
model = DistilBertForSequenceClassification.from_pretrained(model_name)# 示例文本:餐厅评价
text = "The food was delicious, but the service was slow and staff were unfriendly."# 预处理与推理
inputs = tokenizer(text, padding=True, truncation=True, return_tensors="pt")
with torch.no_grad():outputs = model(**inputs)
probabilities = torch.nn.functional.softmax(outputs.logits, dim=1).tolist()[0]# 输出结果(0=负面,1=正面)
print(f"文本:{text}")
print(f"负面概率:{probabilities[0]:.2%},正面概率:{probabilities[1]:.2%}")
六、BERT 的局限性与未来挑战
6.1 当前短板
- 计算资源需求高:尽管 DistilBERT 等变体轻量化,但从头训练 BERT 仍需大量 TPU/GPU 资源,中小企业难以负担。
- 缺乏实时学习能力:预训练模型无法动态更新知识,例如无法识别 2023 年后出现的新词 “生成式 AI”。
- 潜在偏见与幻觉:训练数据若包含偏见(如性别、种族刻板印象),模型可能生成有害内容;且无 RLHF(人类反馈强化学习)机制,易产生事实性错误(如 “巴黎是德国首都”)。
6.2 进化方向
- 与生成式模型结合:如将 BERT 的编码器与 GPT 的解码器结合,提升长文本生成的逻辑性。
- 联邦学习与隐私保护:在医疗等敏感领域,通过联邦学习在本地数据上微调,避免隐私泄露。
- 多模态扩展:融合图像、语音数据,开发 “视觉 - 语言” 联合模型,如 Google 的 Flan-T5。
6.3 代码案例:使用 BERT 进行多语言命名实体识别
场景说明
识别法语文本中的人名、地名、机构名,使用预训练的多语言 BERT 模型(bert-base-multilingual-cased)。
代码实现
# 加载多语言模型(支持50+语言)
from transformers import AutoTokenizer, AutoModelForTokenClassificationmodel_name = "bert-base-multilingual-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name, num_labels=18) # 18类NER标签# 法语示例文本
text = "Barack Obama a visité Paris en 2017 avec son épouse Michelle Obama."# 分词与预测
inputs = tokenizer(text, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=2)# 解析预测结果(映射标签到实体类型)
labels = ["O", "B-PER", "I-PER", "B-LOC", "I-LOC", "B-ORG", "I-ORG", ...] # 完整标签列表需参考模型文档
tokenized_input = tokenizer.tokenize(text)for token, label_id in zip(tokenized_input, predictions[0].tolist()):print(f"Token: {token.ljust(10)} Label: {labels[label_id]}")
七、结论:BERT 的遗产与 AI 的未来
从 Google 搜索的底层技术到开源社区的创新基石,BERT 证明了预训练模型在 NLP 中的革命性价值。 尽管新一代 LLM(如 LLaMA 2、ChatGPT)已在生成能力上超越 BERT,但其 “双向编码 + 预训练微调” 的框架依然是现代 AI 的核心范式。正如牛顿所言:“我看得更远,是因为站在巨人的肩膀上。 ”BERT 正是这样一位巨人,它不仅开启了 LLM 的时代,更教会我们:技术的突破,从来都是集体智慧的结晶。