从零启动 Elasticsearch
elastic 有弹力的
ElaticSearch (ES)是一个基于 Lucene 的分布式全文检索引擎。可以做到近乎实时地存储、检索数据,并且本身具有良好的扩展性,可以扩展到上百台服务器,处理PB级别(1 Petabyte = 1024TB)的数据。
ES 常用于日志分析、全文搜索、安全智能、业务分析和运维智能等场景。
文章目录
- 使用
- 原理
- Lucene
- ELK Stack
- 原理
- 索引
使用
可用 docker 部署 elasticsearch 程序,默认有安全检测不好连接,生产环境可以见下面命令绕过连接启动:
访问测试:
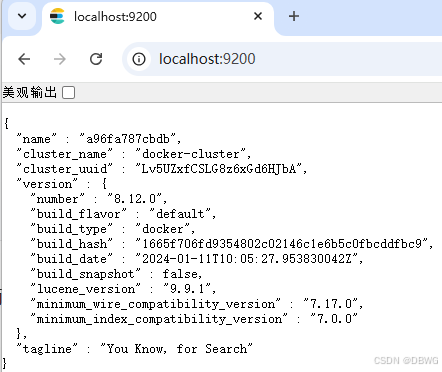
也可以用 curl http://localhost:9200 来测试
相关docker命令:
-- 关闭 Elasticsearch 安全认证(仅测试环境) (没有应该会下载,注意版本)
docker run -d -p 9200:9200 -p 9300:9300 `-e "discovery.type=single-node" `-e "xpack.security.enabled=false" `--name elasticsearch docker.elastic.co/elasticsearch/elasticsearch:8.12.0-- 之后直接 start 启动即可:
docker start elasticsearch
docker stop elasticsearch
docker rm elasticsearchdocker ps -a # 查看所有容器(包括停止的)
docker logs elasticsearch
写java时:
springbootframe 管理的 elasticsearch 只需配置即可使用:
- ElasticsearchRepository已经提供了基础的 CRUD 操作
这里交互方法也只需声明继承的接口: - 自定义方法则能通过命名规则来扩展更多查询功能——也不需要实现,Spring Data 框架能够依据方法名称自动生成对应的实现。
package org.example.searchservice.repository;import org.example.common.dto.Question;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;import java.util.List;@Repository
public interface QuestionEsRepository extends ElasticsearchRepository<Question, String> {// 标题或内容模糊搜索(自动解析成 bool should)List<Question> findByTitleContainingOrContentContaining(String title, String content);// 根据标签精确匹配(List<String> 是 keyword 类型)List<Question> findByTagsIn(List<String> tags);
}//你不需要手动实现插入方法,ElasticsearchRepository 已经帮你准备好了常用的 CRUD 方法,包括插入。
// 🧩 一、插入数据的方式
//ElasticsearchRepository 继承了 CrudRepository,所以它自动拥有以下方法:
//
//方法 作用
//save(T entity) 插入或更新单条数据
//saveAll(Iterable<T> entities) 批量插入或更新
//findById(ID id) 根据 ID 查询
//deleteById(ID id) 根据 ID 删除
//findAll() 查询所有
//count() 统计数量
检索:(需先把要检索的插入ES,如上的save方法)
原理
Lucene
Lucene 是一个全文检索引擎工具包 。
它是一款 纯Java的全文检索引擎工具包,提供了完整的查询引擎和索引引擎,主要用于实现全文搜索功能。
Lucene 主要是基于倒排索引的文本检索,通过创建并建立索引器(IndexWriter)来读取需要建立全文索引的文本内容 —— 即读入一堆文本文件并将其转换为易于搜索的数据结构
ElasticSearch 是基于 Lucene 做了封装和增强,通过简单的 RESTful API 来隐藏 Lucene 的复杂性。
ELK Stack
ES与Logstash、Beats和Kibana等工具协同工作,共同提供数据收集、存储、分析、可视化和监控等功能,组成 ELK 。
- Logstash:数据收集与处理 管道工具(采集日志数据、过滤清洗)
- Beats:轻量级的数据采集器(日志或指标)
- Kibana:可视化工具
工作流程:[ 日志 / 数据 ]↓Beats(轻量上报器)↓Logstash(采集 + 清洗)↓
Elasticsearch(存储 + 查询)↓Kibana(可视化)原理
索引
ES 中存储数据的基本单元,并且用于搜索和分析数据。