No More Adam: 新型优化器SGD_SaI

一.核心思想和创新点
2024年12月提出的SGD-SaI算法(Stochastic Gradient Descent with Scaling at Initialization)本质上是一种在训练初始阶段对不同参数块(parameter block)基于**梯度信噪比(g-SNR, Gradient Signal-to-Noise Ratio)进行局部学习率缩放的SGDM变体。**代码开源:https://github.com/AnonymousAlethiometer/SGD_SaI/
通过在训练初始化阶段针对参数分组进行一次性学习率缩放(基于g-SNR)即可实现与自适应方法类似的性能,完全不依赖于动态二阶动量,不仅保留了SGDM的高效性和简洁性,还显著提升了大模型训练的资源利用率和稳定性。这为未来深度学习模型的高效训练,特别是大规模Transformer的可扩展性提供了一条全新路径。
1.质疑自适应梯度方法的必要性
作者质疑了当前深度学习中广泛应用的自适应梯度优化器(如Adam及其变体)的必要性,认为其主要优势(即根据梯度历史动态调整每个参数的学习率以应对训练初期的梯度噪声、稀疏和不同参数组间的学习率不均衡)可以通过更简单、更高效的方法实现。
2.提出SGD-SaI优化器
作者提出了一种基于动量的随机梯度下降优化器改进版——SGD-SaI(Stochastic Gradient Descent with Scaling at Initialization),其核心做法是在训练初始阶段,利用梯度信噪比(g-SNR),对不同参数分组的学习率进行一次性分组缩放,而非每步动态自适应。这种方法完全摒弃了存储和更新每个参数的二阶动量(即方差估计),极大减少了优化器的内存开销和计算复杂度。
3.梯度信噪比(g-SNR)引导的分组缩放
g-SNR度量了参数块的梯度范数与方差之比,可以稳定反映各参数块在不同训练阶段的梯度特性。实验表明g-SNR在参数块内具有时间上的稳定性(即初始化时刻的分布基本决定整个训练过程),据此对参数分组的学习率进行归一化缩放,有效平衡了参数块间的训练进度。
4.广泛的适用性和实证优势
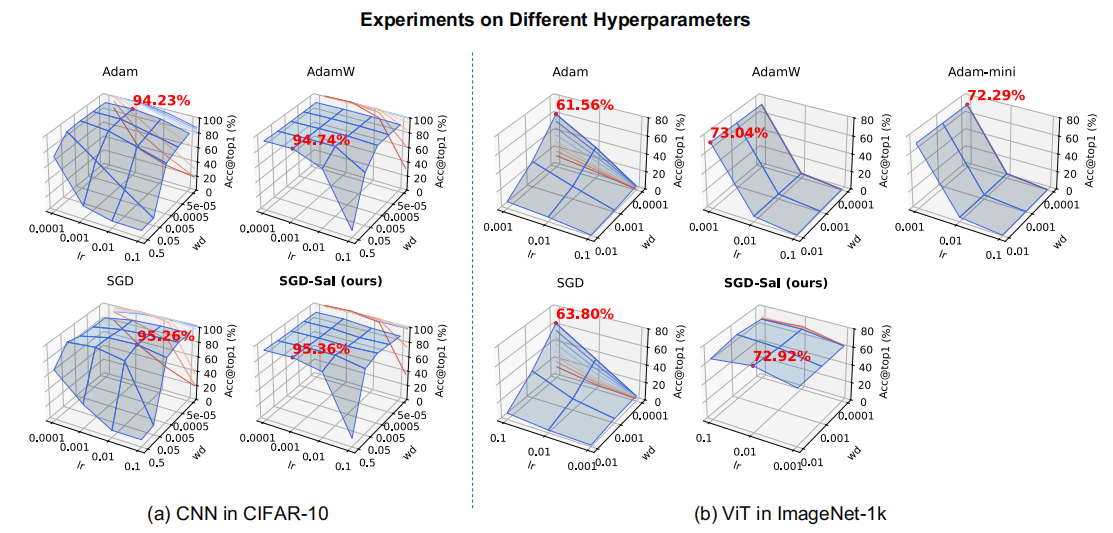
SGD-SaI方法不仅在传统卷积神经网络(CNN)任务上表现良好,在Transformer、ViT、GPT-2等参数分布高度异质的大模型任务中,也能够实现与主流自适应方法(AdamW、Adam-mini等)相当甚至更优的性能,同时具备更好的超参数鲁棒性和极低的内存占用,显著提升了大模型训练的可扩展性与资源利用效率。
5.实验验证
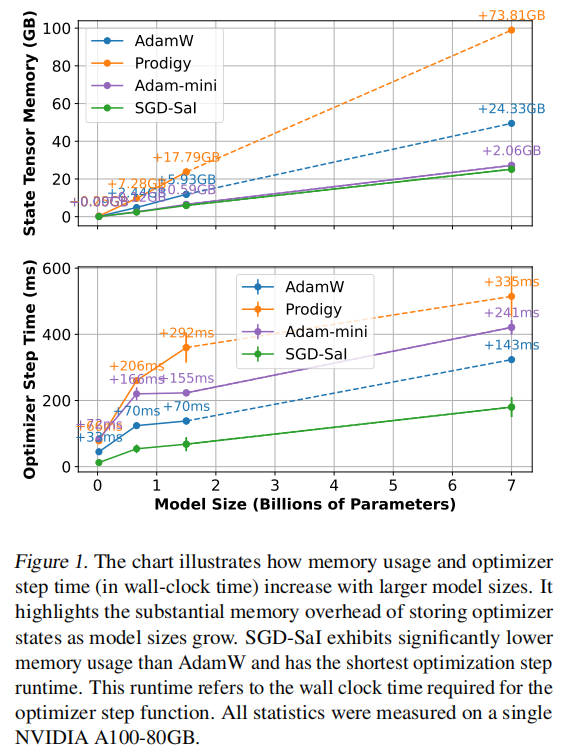
在大规模语言模型、视觉Transformer、LoRA微调、扩散模型微调以及CNN等多类任务上的实验证明,SGD-SaI在准确率、收敛稳定性、内存效率、训练速度等方面均表现优异,尤其是在Transformer类任务中,解决了传统SGD难以收敛的问题,并可节省高达50%甚至75%的优化器状态内存,显著降低了训练门槛。
二.算法流程
1.参数分块(Parameter Grouping)
神经网络的所有参数 θ \theta θ 按照网络结构分为 B B B 个参数块(如不同层、不同类型参数等),记为 θ ( i ) \theta^{(i)} θ(i)( i = 1 , 2 , . . . , B i=1,2,...,B i=1,2,...,B)。
2.计算每个参数块的梯度信噪比(g-SNR)
对于每个参数块 i i i,在第一次训练迭代时计算:
-
梯度范数:
G n o r m ( i ) = ∑ j = 1 d i ( g j ( i ) ) 2 G_{\mathrm{norm}}^{(i)}=\sqrt{\sum_{j=1}^{d_i}(g_j^{(i)})^2} Gnorm(i)=∑j=1di(gj(i))2
其中 g j ( i ) g_j^{(i)} gj(i)是第 i i i 个参数块第 j j j个参数的梯度, d i d_i di 是该参数块参数数量。
- 梯度均值:
g ˉ ( i ) = 1 d i ∑ j = 1 d i g j ( i ) \bar{g}^{(i)}=\frac{1}{d_i}\sum_{j=1}^{d_i}g_j^{(i)} gˉ(i)=di1∑j=1digj(i)
- 梯度方差:
G v a r ( i ) = 1 d i ∑ j = 1 d i ( g j ( i ) − g ˉ ( i ) ) 2 G_\mathrm{var}^{(i)}=\frac{1}{d_i}\sum_{j=1}^{d_i}(g_j^{(i)}-\bar{g}^{(i)})^2 Gvar(i)=di1∑j=1di(gj(i)−gˉ(i))2
- g-SNR定义:
G s n r ( i ) = G n o r m ( i ) G v a r ( i ) + ϵ G_{\mathrm{snr}}^{(i)}=\frac{G_{\mathrm{norm}}^{(i)}}{\sqrt{G_{\mathrm{var}}^{(i)}+\epsilon}} Gsnr(i)=Gvar(i)+ϵGnorm(i)
其中 ϵ \epsilon ϵ 是防止分母为零的小常数。
3. 归一化g-SNR得到缩放因子
对所有参数块的 G snr ( i ) G_{\text{snr}}^{(i)} Gsnr(i)做最大值归一化:
G ~ s n r ( i ) = G s n r ( i ) max k G s n r ( k ) \tilde{G}_\mathrm{snr}^{(i)}=\frac{G_\mathrm{snr}^{(i)}}{\max_kG_\mathrm{snr}^{(k)}} G~snr(i)=maxkGsnr(k)Gsnr(i)
这样归一化后的值在0到1之间。
4. 局部学习率缩放
对于每个参数块,设全局基础学习率为 η \eta η,则每个参数块的实际学习率为:
η ( i ) = G ~ s n r ( i ) ⋅ η \eta^{(i)}=\tilde{G}_{\mathrm{snr}}^{(i)}\cdot\eta η(i)=G~snr(i)⋅η
5.训练过程
- 动量项采用传统SGDM:
m t ( i ) = μ m t − 1 ( i ) + ( 1 − μ ) g t ( i ) m_t^{(i)}=\mu m_{t-1}^{(i)}+(1-\mu)g_t^{(i)} mt(i)=μmt−1(i)+(1−μ)gt(i)
- 权重更新(以decoupled weight decay为例):
θ t ( i ) = θ t − 1 ( i ) − λ η θ t − 1 ( i ) − η ( i ) m t ( i ) \theta_t^{(i)}=\theta_{t-1}^{(i)}-\lambda\eta\theta_{t-1}^{(i)}-\eta^{(i)}m_t^{(i)} θt(i)=θt−1(i)−ληθt−1(i)−η(i)mt(i)
其中 λ \lambda λ为权重衰减系数。
补充解释一下Decoupled weight decay(解耦权重衰减):
是一种针对权重衰减(weight decay)正则化项的优化策略,最早由Loshchilov和Hutter在AdamW优化器中系统提出。 其核心思想是将权重衰减正则项与梯度更新过程解耦,从而更好地控制正则化效果,提升模型泛化能力,避免对自适应梯度的干扰。
在SGD及其变体(如Adam)中,L2正则化通常被实现为在每次参数更新时,将权重衰减项( λ θ \lambda \theta λθ)加入到梯度中:
g ′ = g + λ θ g^{\prime}=g+\lambda\theta g′=g+λθ
其中, g g g 是损失函数关于参数的梯度, λ \lambda λ 是权重衰减系数, θ \theta θ是参数。
然后按照普通优化器的参数更新公式进行迭代: θ t + 1 = θ t − η g ′ \theta_{t+1}=\theta_t-\eta g^{\prime} θt+1=θt−ηg′
这种方式实际上把权重衰减项当做损失函数梯度的一部分来处理。
解耦策略下,权重衰减项不再与梯度混合计算,而是在参数更新时直接对参数进行衰减,其更新公式为:
θ t + 1 = θ t − η g − η λ θ t \theta_{t+1}=\theta_t-\eta g-\eta\lambda\theta_t θt+1=θt−ηg−ηλθt
也可以拆分为两步:
1.正常的梯度下降更新: θ t + 1 / 2 = θ t − η g \theta_{t+1/2}=\theta_t-\eta g θt+1/2=θt−ηg
2.单独进行权重衰减: θ t + 1 = θ t + 1 / 2 − η λ θ t \theta_{t+1}=\theta_{t+1/2}-\eta\lambda\theta_t θt+1=θt+1/2−ηλθt
这样做的好处是,权重衰减只针对参数本身进行缩减,而不会受梯度自适应调整的影响,能更精确地施加正则化,从而提升模型泛化效果。
SGD-SaI算法采用了decoupled weight decay,即先计算梯度用于g-SNR,再单独对参数进行衰减,这样能够保证g-SNR反映真实的梯度稀疏性和噪声特征,而不会被权重衰减项混淆,从而提升分组学习率缩放的有效性
值得强调的是:整个训练过程中每个参数块的缩放因子 G ~ snr ( i ) \tilde{G}_{\text{snr}}^{(i)} G~snr(i)只在初始化阶段计算一次,后续训练保持不变,极大降低了内存和计算开销。
三.代码解释
核心代码是sgd_sai.py,这里完整注释如下
import torch
from torch.optim.optimizer import Optimizer # PyTorch优化器基类class SGD_sai(Optimizer): # 定义SGD_sai优化器类,继承自PyTorch优化器r"""该优化器实现了论文"SGD-SaI: Stochastic Gradient Descent with Scaling at Initialization"的核心算法思想。支持标准SGD参数设置及momentum、weight_decay等常用优化选项。"""def __init__(self, params, lr=1e-2, momentum=0.9, eps=1e-8, weight_decay=0, maximize=False):# 构造函数,初始化优化器的各项参数和默认设置defaults = dict(lr=lr, momentum=momentum, eps=eps, weight_decay=weight_decay, maximize=maximize)super(SGD_sai, self).__init__(params, defaults) # 调用父类初始化self.gsnr_initialized = False # 标志变量,指示g-SNR缩放因子是否已完成初始化@torch.no_grad()def step(self, closure=None):"""执行一次优化器更新。包括g-SNR的初始化、动量累计、权重衰减和参数更新。"""loss = Noneif closure is not None:with torch.enable_grad():loss = closure() # 支持自定义loss回调(如二阶梯度)# 如果还没有初始化g-SNR缩放因子,则进行一次初始化if not self.gsnr_initialized:gsnr_list = [] # 用于存储每个参数组的g-SNRfor group in self.param_groups:for p in group['params']:if p.grad is None: # 跳过无梯度参数continuegrad = p.grad.data # 获取梯度grad_norm = grad.norm() # 计算L2范数grad_var = grad.var() # 计算方差eps = group['eps'] # 取数值稳定用小常数gsnr = grad_norm / (grad_var.sqrt() + eps) # 计算g-SNRgsnr_list.append(gsnr) # 存入列表# 将所有g-SNR按最大值归一化max_gsnr = torch.max(torch.stack(gsnr_list))norm_gsnr_list = [x / max_gsnr for x in gsnr_list]# 保存每个参数的g-SNR缩放因子idx = 0for group in self.param_groups:for p in group['params']:if p.grad is None:continuep.gsnr_scale = norm_gsnr_list[idx] # 动态添加属性idx += 1self.gsnr_initialized = True # 完成g-SNR初始化return loss # 初始化阶段不做参数更新# 正式参数更新过程for group in self.param_groups:lr = group['lr'] # 获取全局学习率momentum = group['momentum'] # 获取动量系数weight_decay = group['weight_decay'] # 获取权重衰减系数maximize = group['maximize'] # 是否最大化目标for p in group['params']:if p.grad is None:continuegrad = p.grad.dataif maximize:grad = -grad # 支持最大化模式# 解耦式权重衰减:对参数本身做缩放,不叠加到梯度if weight_decay != 0:p.data.add_(p.data, alpha=-lr * weight_decay)# 获取g-SNR缩放因子scale = getattr(p, 'gsnr_scale', 1.0)# 获取或初始化动量param_state = self.state[p]if 'momentum_buffer' not in param_state:buf = param_state['momentum_buffer'] = torch.clone(grad).detach()else:buf = param_state['momentum_buffer']buf.mul_(momentum).add_(grad, alpha=1 - momentum)# 参数更新:带g-SNR缩放的动量SGDp.data.add_(buf, alpha=-lr * scale)return loss # 返回损失值以便监控
代码中有几点重点说明:
(1)g-SNR初始化:
- 仅在第一次调用
step()时触发,遍历所有参数,依据当前梯度分布计算g-SNR,并最大归一化。 - 利用动态属性
p.gsnr_scale将每个参数的缩放因子缓存下来,后续训练反复使用。
(2)动量与权重衰减:
- 动量缓存采用PyTorch标准做法(
momentum_buffer)。 - 权重衰减采用解耦式,即直接对参数做缩放操作,避免正则项混入梯度统计,理论上等同于AdamW等现代优化器。
(3)参数更新:
- 更新公式为:基础学习率 × g-SNR缩放 × 动量项,精确实现论文中的“初始化缩放,分组局部自适应学习率”思想。
- 若未初始化g-SNR则直接跳过参数更新。
(4)max/min目标灵活性:
maximize选项用于兼容极大极小化目标。
四.使用优化器
安装:
pip install sgd-sai
使用:
from sgd_sai import SGD_sai# 初始化优化器
optimizer = SGD_sai(model.parameters(), lr=lr, momentum=0.9, eps=1e-08, weight_decay=weight_decay)for _ in range(steps):pred = model(input_ids)loss = loss_fn(pred, labels)loss.backward()optimizer.step()optimizer.zero_grad(set_to_none=True)
在每个训练step前调用
optimizer.zero_grad(),是为了清空所有参数的.grad属性,以避免梯度累积。否则多次反向传播会让梯度不断相加,导致梯度异常。当
set_to_none=False(默认值)时,会将每个参数的.grad置为与原来形状相同的全零张量当
set_to_none=True时,则会直接把.grad设为 None
set_to_none=True通常更高效,节省了将张量置零的时间与显存开销,特别适合大模型或分布式训练,且官方推荐优先使用。只要后续所有反向传播都能正确地重新分配
.grad,则功能完全等价。某些情况下(比如自定义梯度操作),如果你的代码假设
.grad一定存在且是全零tensor,才建议用默认方式。