网络编程中的直接内存与零拷贝
本篇文章会介绍 JDK 与 Linux 网络编程中的直接内存与零拷贝的相关知识,最后还会介绍一下 Linux 系统与 JDK 对网络通信的实现。
1、直接内存
所有的网络通信和应用程序中(任何语言),每个 TCP Socket 的内核中都有一个发送缓冲区(SO_SNDBUF)和一个接收缓冲区(SO_RECVBUF):
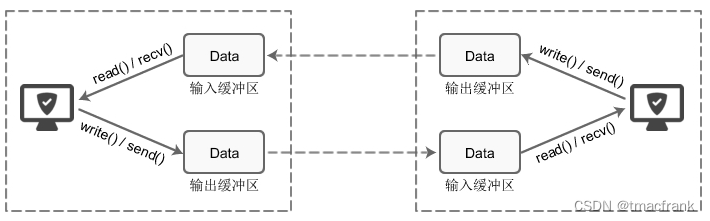
应用程序调用 write() 会使内核复制应用程序缓冲区中所有的数据到 Socket 的发送缓冲区,如果后者放不下并且该 Socket 是阻塞式的,应用程序会被投入睡眠。write() 直到应用程序缓冲区的所有数据都复制到 Socket 的发送缓冲区后才会返回,此时可以继续向应用程序缓冲区写入数据,但不表示对端的 TCP 或应用程序已经接收到数据:
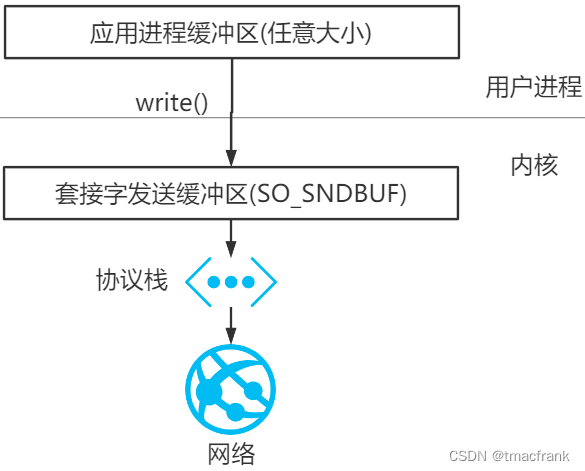
Java 也遵从这种规则。只不过因为堆、GC 等特性影响,会有一些特殊操作,即使用直接内存(或称堆外内存),下面来阐述原因:
- 前面说过,要发送的数据会从应用程序的缓冲区被内核拷贝到 Socket 内核的发送缓冲区中。这中间必定有调用 Native 方法将 Java 对象地址通过 JNI 传递给底层 C 库的过程
- 如果该 Java 对象存在堆中,受 GC 影响该对象可能会在堆中移动,就有可能出现该对象地址在传递给底层前后不同的情况,原地址失效底层就拿不到原本的对象。因此会要求调用 Native 方法之前一定要将数据存在堆外内存,JDK 对此的解决方案是将堆中的数据拷贝到堆外的 DirectBuffer 中
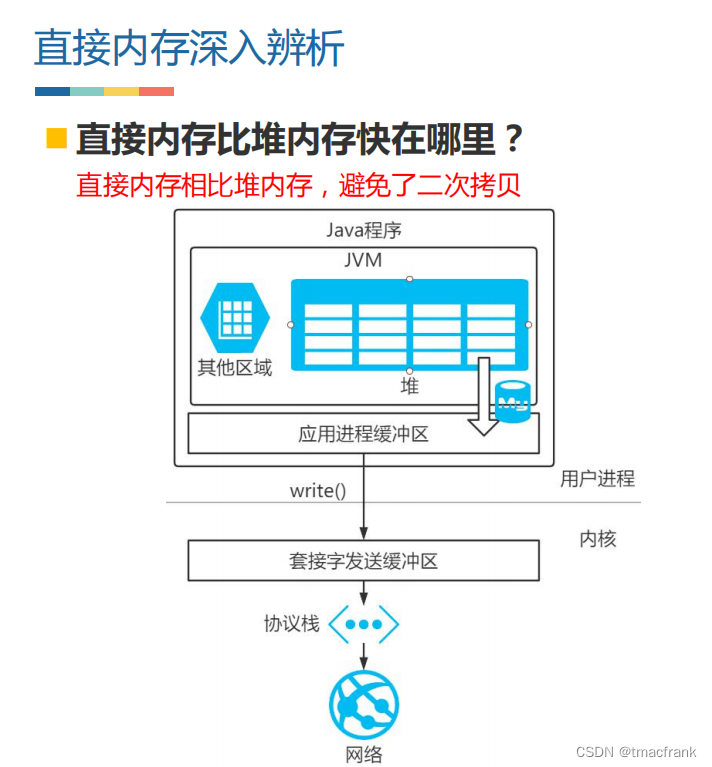
- 也可以直接使用 DirectBuffer 而不再通过堆,这样可以省去把数据由堆拷贝到 DirectBuffer 的一次拷贝,使用直接内存当然就会快一点
- 直接内存不受新生代的 Minor GC 影响,只有执行老年代的 Full GC 时才会顺便回收直接内存,整理内存的压力也比将数据放到堆上小
使用堆外内存的好处是减少了 GC(会暂停其他工作)工作、加快了复制速度(相比于堆少了一次数据拷贝);缺点是如果堆外发生内存泄漏难以排查、不适合存很复杂的对象(适合简单对象或扁平化对象)。
2、零拷贝
指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。
零拷贝并不是说不需要拷贝,只是说减少冗余的、不必要的(尤其是需要 CPU 干预的)拷贝:
- 零拷贝技术可以减少数据拷贝和共享总线操作的次数,消除传输数据在存储器之间不必要的中间拷贝次数,从而有效地提高数据传输效率
- 零拷贝技术减少了用户进程地址空间和内核地址空间之间因为上下文切换而带来的开销
2.1 Linux 的 IO 机制与 DMA
早期用户进程需要读取磁盘数据时都需要 CPU 中断并参与,这样 CPU 的效率低,因为每次 IO 请求都要中断 CPU 带来 CPU 的上下文切换,为了解决这个问题出现了 DMA(Direct Memory Access)。
DMA 不需要依赖 CPU 大量的中断负载就可以与不同速度的硬件装置进行沟通。DMA 控制器接管了数据读写请求,减少了 CPU 的负担,使得 CPU 可以高效工作。现代硬盘基本都支持 DMA,实际的 IO 读取涉及两个过程(都是阻塞的):
- DMA 等待数据准备好,把磁盘数据读取到操作系统内核缓冲区
- 用户进程,将内核缓冲区的数据 copy 到用户空间
DMA 是物理硬件,也算是一种芯片,磁盘、网卡、键盘等都有自己的 DMA。早期 CPU 会参与 IO 工作,读取磁盘上的数据拷贝到内存当中,由于 IO 读写速度相比于 CPU 的处理速度是很慢的,所以这就相当于浪费了 CPU 的宝贵时间,于是产生了 DMA 设备,在有 IO 需求时,CPU 给 DMA发指令让其读取磁盘数据,DMA 读取后会将数据拷贝到内存中,再通知 CPU 数据拷贝完成,然后 CPU 再用内存中的数据做接下来的操作。这就将 CPU 从低速的 IO 读取工作中解放出来,专心做高速计算。
2.2 传统数据传送机制
以读取文件再用 Socket 发送出去这个过程为例,伪代码如下:
buffer = File.read()
Socket.send(buffer)
这个过程的示意图如下:
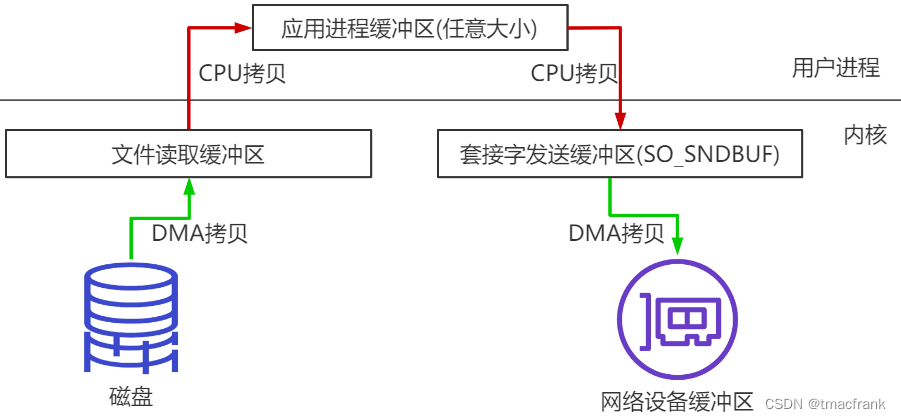
数据要经过四次拷贝:
- 将磁盘中的文件拷贝到操作系统内核缓冲区
- 将内核缓冲区数据拷贝到应用程序缓冲区
- 将应用程序缓冲区中的数据拷贝到位于操作系统内核缓冲区中的 Socket 网络发送缓冲区
- 将 Socket 缓冲区中的数据拷贝到网卡,由网卡进行网络传输
其中 2、3 两次(即图中红线的两次 CPU 拷贝)是“不必要的拷贝”,对于发送网络数据而言属于额外开销,可以优化掉。
此外,read 和 send 都属于系统调用,每次调用都牵涉两次上下文切换,总共就是四次上下文切换:
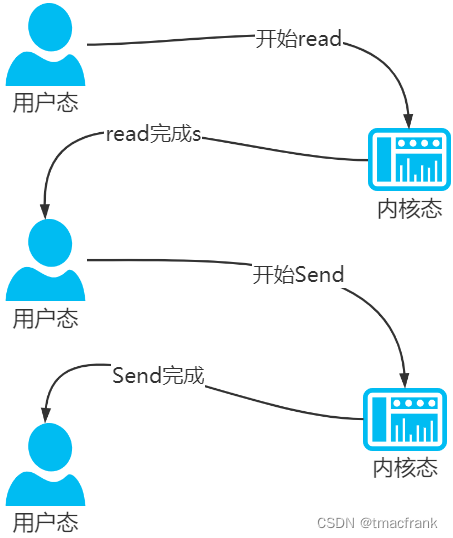
2.3 Linux 常见的零拷贝
零拷贝的目的就是减少不必要的拷贝,需要 OS 支持(需要 kernel 暴露 api)。
mmap 内存映射
将硬盘与应用程序缓冲区进行映射(建立一一对应关系),由于 mmap() 将文件直接映射到用户空间,读取文件时就可以根据该映射关系将文件从硬盘拷贝到用户空间:
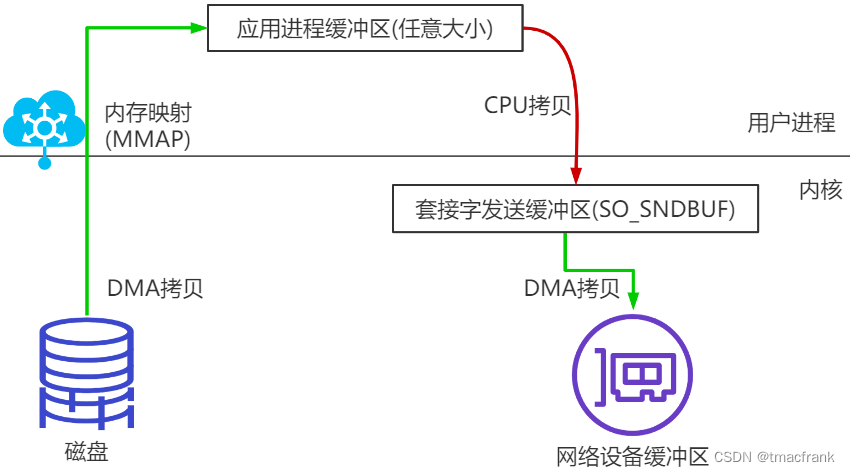
这样仍有 3 次拷贝,4 次上下文切换。
sendfile
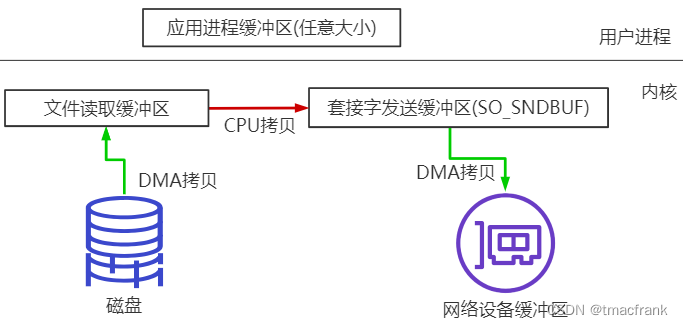
sendfile 需要 3 次拷贝,2 次上下文切换:
- 3 次拷贝如上图所示,当然如果硬件支持的话,红线的 CPU 拷贝是可以省略的。具体做法是文件读取缓冲区将文件的起始位置和长度的描述符传入 Socket 缓冲区,然后 DMA 会根据这个数据从文件读取缓冲区中直接将文件读取到网络设备缓冲区,这样就只需要 2 次拷贝了
- 用户调用 sendfile 这一个系统调用,仅需两次上下文切换
splice
Linux 在 2.6.17 开始支持的系统调用,使用管道直接将内核缓冲区的数据转换为其他数据 buffer。在 Socket 网络通信的情况下,就是文件读取缓冲区与 SO_SNDBUF 建立 pipe 管道(实际上是管道两侧的缓冲区共用一块物理内存)。这样在无需硬件支持的情况下就省去了 CPU 拷贝:
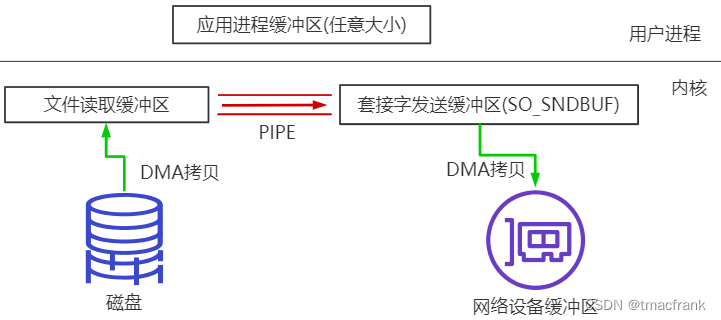
splice 也是需要 2 次拷贝,2 次上下文切换。
总结
零拷贝说法的来源最早出现于 sendfile 系统调用,这是真正操作系统意义上的零拷贝(也称狭义零拷贝)。
但是由于由 OS 内核提供的操作系统意义上的零拷贝发展到现在种类并不是很多,因此随着发展,零拷贝的概念延伸到了,减少不必要的数据拷贝都算作零拷贝的范畴。
3、Linux 和 JDK 对网络通信的实现
3.1 Linux 网络 IO 模型
同步与异步,阻塞与非阻塞
同步与异步关注的是调用方是否主动获取结果:
- 同步:调用方主动等待结果返回
- 异步:调用方不用主动等待结果返回,而是通过状态通知、回调函数等手段获取结果
阻塞与非阻塞关注的是调用方在等待结果返回之前的状态:
- 阻塞:结果返回前,当前线程被挂起不做任何事
- 非阻塞:结果返回前,线程可以做其他事情,不会被挂起
二者有四种组合:
- 同步阻塞:编程中最常见的模型,等待结果并且等待期间不做任何事,效率很低
- 同步非阻塞:可以抽象为轮询模式,等待结果期间会做其他事情,但是会时不时地询问是否已经返回结果
- 异步阻塞:用的很少,有点像在线程池中 submit 后马上 Future.get(),此时线程其实还是挂起的
- 异步非阻塞:常用模型是回调函数
Linux 下的五种 IO 模型
五种 IO 模型,前四种是同步的,最后一种是异步的:
- 阻塞 IO:调用 IO 函数,会经过系统调用进入内核。应用程序会被阻塞,直到数据被准备好,从内核空间拷贝到用户空间后,IO 函数返回,阻塞才被解除。BIO 中的 bind()、connect()、accept() 都是阻塞方法
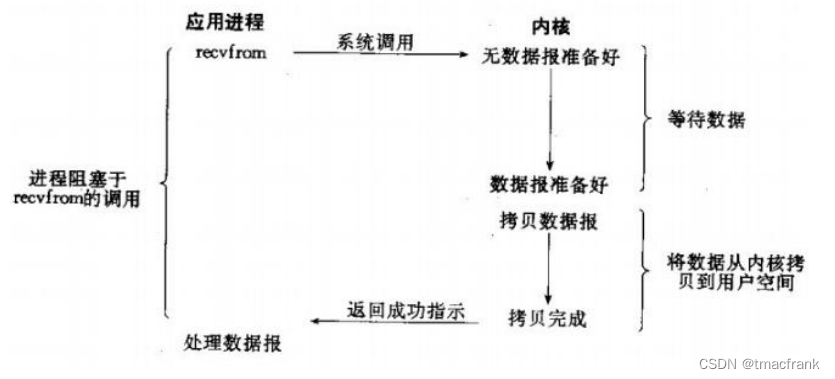
- 非阻塞 IO:IO 操作无法完成时,不将进程睡眠,而是返回一个错误。这样应用就需要不断测试数据是否已经准备好,如果没有就继续测试直到数据准备好为止。这种不断测试会大量占用 CPU 时间,因此该模型绝对不被推荐
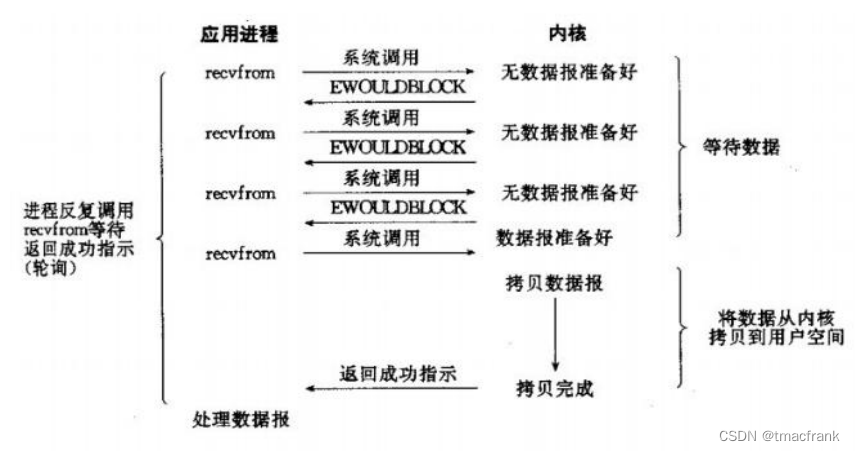
- IO 复用(select、poll、epoll):本质上也是阻塞的,只不过将阻塞拆开为 select(或 epoll)和 recvfrom 两个系统调用,前者在有读写事件到来时返回,后者在数据从内核拷贝到用户空间后返回。也就是对一个 IO 端口进行两次系统调用,返回两次结果,这比阻塞 IO 并没有什么优势,甚至相同条件下处理单个连接的效率还要比 BIO 低,但是胜在能同时对多个 IO 端口进行监听
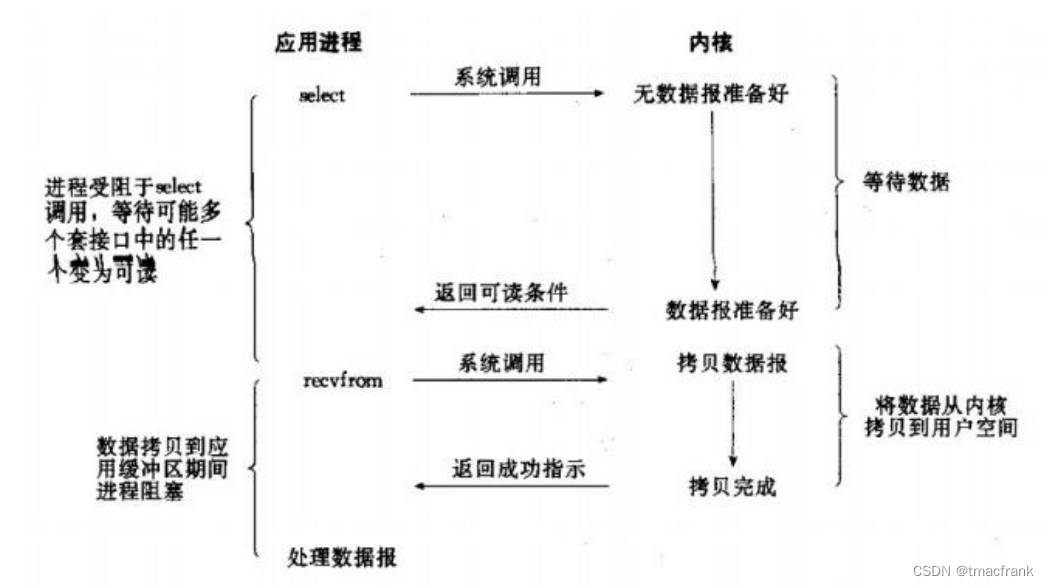
- 信号驱动 IO:应用进程向内核注册一个信号处理函数然后继续执行其他内容不会阻塞,当数据到来时,内核发出信号,通过信号处理程序告诉应用进程数据来了,这时应用程序才调用 recvfrom 进入阻塞式获取数据的过程。整个过程有两次调用和两次返回

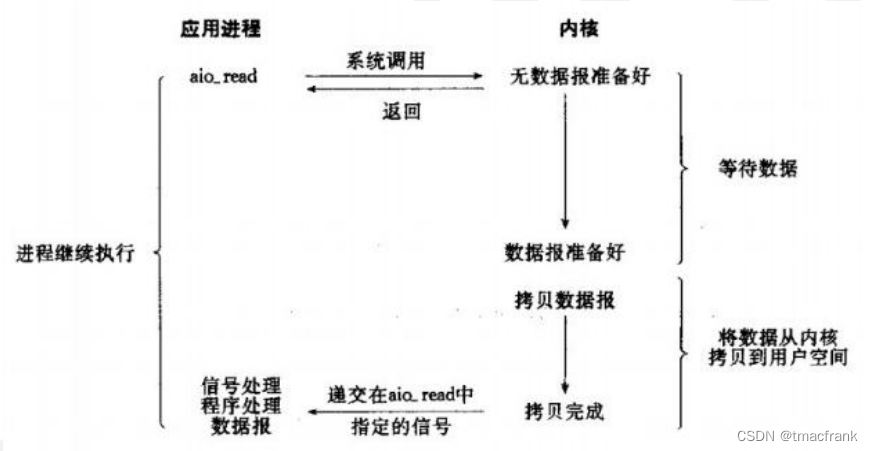
- 异步 IO:当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者的输入输出操作(Linux 下的 AIO 是假的异步,是用 IO 多路复用实现的)
3.2 JDK 对网络通信的实现
JDK 实际上就是对 Linux 的 IO 通信模型进行了一个包装,因此我们先了解 Linux 的通信实现。
Linux 下的阻塞网络编程
Linux 下与 JDK 实现网络通信的一个最大不同是,在服务端,Linux 用的是 socket 而 JDK 用的 ServerSocket,实际上就是 JDK 在 socket 基础上做了一层封装。此外,Linux 下需要通过 listen() 侦听端口,这个大概也被 ServerSocket 封装了。
从 Linux 代码结构看网络通信
分层:应用 API 层、协议层、接口层,应用发送数据是由上至下,接收数据是由下至上,并且接收时还涉及到由网络设备产生的硬中断。
中断、上半部、下半部
内核和设备驱动是通过中断的方式来处理的。所谓中断,可以理解为当设备上有数据到达的时候,会给 CPU 的相关引脚上触发一个电压变化,以通知 CPU 来处理数据。
网卡把数据写入内存后会向 CPU 发出一个中断信号,由操作系统执行网卡中断程序去处理数据。由于网络操作复杂且耗时,如果在中断函数中完成所有处理,会使得中断处理函数(优先级过高)过度占据 CPU,使得 CPU 无法响应其他设备(如鼠标键盘),因此 Linux 将中断处理函数分为上半部和下半部。
上半部只进行最简单的工作,快速处理然后释放 CPU,这样 CPU 就可以让其他中断进来。下半部则慢慢从容的处理绝大部分工作。自 2.4 以后内核采用下半部是软中断,即给内存中的一个变量的二进制赋值以通知中断处理程序;而硬中断则是通过给 CPU 物理引脚施加电压变化。
JDK 的 BIO 实现分析
Socket 和 ServerSocket 内部的 SocketImpl 才是真正实现网络通信的组件(使用了门面模式),这与 Linux 下 CS 两端都使用 socket 是吻合的。
Linux 下的 IO 复用编程
select,poll,epoll 都是 IO 多路复用的机制。所谓 IO 多路复用就是指一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但 select,poll,epoll 本质上都是同步 I/O,他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步 I/O 则无需自己负责进行读写,异步 I/O 的实现会负责把数据从内核拷贝到用户空间。
select 提供了一个函数:
// readfds 读事件 fd 集合,writefds 写事件 fd 集合,exceptfds 异常事件 fd 集合
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
所有的操作系统都支持 select 机制,Linux 下能监控的最大文件描述符数量为 1024,超过该数量性能会急剧下滑。
poll 也提供了一个函数,将 select() 参数中的三个描述符合为一个:
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
fds 也是不能超过 1024 个,否则性能会急剧下降(因为是轮询 Socket 通道获取事件,数量多了自然性能就下降了)。
epoll 有三个函数,也就是三个系统调用:
// 创建 epoll 的文件描述符,类似于 JDK NIO 的 Selector.open()
int epoll_create(int size);
// 注册、增加、删除、修改关注的事件,类似于 JDK NIO 的 ServerChannel.register()
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// 等待,看是否有事件发生,类似于 JDK NIO 的 Selector.select()
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
实际上 JDK 的 NIO 就是对 Linux epoll 的包装。