RNope:结合 RoPE 和 NoPE 的长文本建模架构
TL;DR
- 2025 年 Cohere 提出的一种高效且强大的长上下文建模架构——RNope-SWA。通过系统分析注意力模式、位置编码机制与训练策略,该架构不仅在长上下文任务上取得了当前最优的表现,还在短上下文任务和训练/推理效率方面实现了良好平衡。
Paper name
Rope to Nope and Back Again: A New Hybrid Attention Strategy
Paper Reading Note
Paper URL:
- https://arxiv.org/pdf/2501.18795
Introduction
背景
- 现有的基于 RoPE 的方法在处理进一步扩展的上下文长度时表现出一定的性能局限。
- Query-Key Normalization(QK-Norm)被提出用于改善训练稳定性,该方法在计算注意力前对查询-键向量在头维度上进行归一化处理。虽然 QK-Norm 缓解了训练过程中的数值不稳定性并被广泛采用,但它可能削弱模型的长上下文建模能力。
- “无位置嵌入”(NoPE)的提出,认为移除显式的位置嵌入、仅依赖因果掩码带来的隐式位置信息,反而可能提升长上下文的表现。
本文方案
- 首先分析不同注意力机制(包括 NoPE 和 QK-Norm)在训练至 7500 亿 token 后的注意力模式及其对长上下文性能的影响
- 提出了一种结合 RoPE 和 NoPE 的新架构——RNoPE 。该架构不仅在长上下文任务上超越了传统的基于 RoPE 的 Transformer 模型,同时在较短上下文需求的基准测试中也表现出具有竞争力的性能。
Methods
实验配置
-
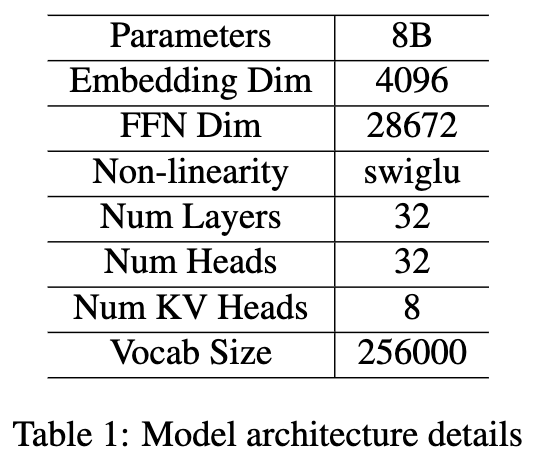
模型架构,参数总量为80亿(包括词嵌入参数)
-
模型训练分为两个阶段:预训练阶段和监督微调(SFT)阶段。
- 在进行长上下文评估时,SFT阶段是必要的,因为它可以降低长上下文任务中的方差,并使仅通过预训练无法显现的长上下文能力得以展现
-
测试的三种模型变体如下:
- RoPE 模型 :该变体使用旋转位置嵌入(Rotary Position Embedding, RoPE)来编码位置信息。在预训练阶段,RoPE 参数 θ 设置为10,000;在随后的SFT阶段,θ 被提升至200万,以适应更长的上下文长度。该变体作为基线模型,其架构与大多数现有模型相似。
- QK-Norm 模型 :在执行RoPE中的角度旋转之前,对查询向量和键向量分别应用层归一化(Layer Normalization)。除归一化操作外,其他超参数(包括θ值和训练方法)均与RoPE变体保持一致。
- NoPE 模型 :已有研究表明,不使用位置嵌入(NoPE)的Transformer变体在长上下文任务中仍可有效运行。然而,这些模型在训练序列长度内的困惑度(perplexity)和下游任务表现通常较差。在我们的研究中,NoPE变体未使用QK-Norm,其余训练方法与上述两种变体相同。
评估与注意力分析
- RoPE 和 QK-Norm 变体在标准基准上的表现相当,而 NoPE 变体则相对落后,这与先前研究结果一致
- 在长上下文评估中,QK-Norm 表现最差,尽管它在其他能力上表现尚可
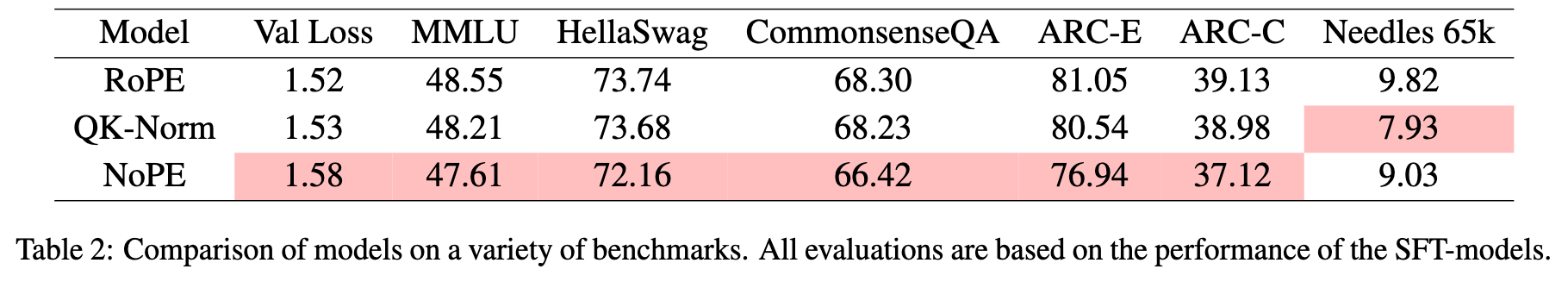
注意力模式分析
- 为了探究不同架构的影响,对各模型内部的注意力模式进行了分析
- 继续使用 NIAH 任务,将上下文划分为四个部分
- 前10个token(begin)
- 针句token(needle)
- 一般上下文token(context)
- 问题/补全token(qc)
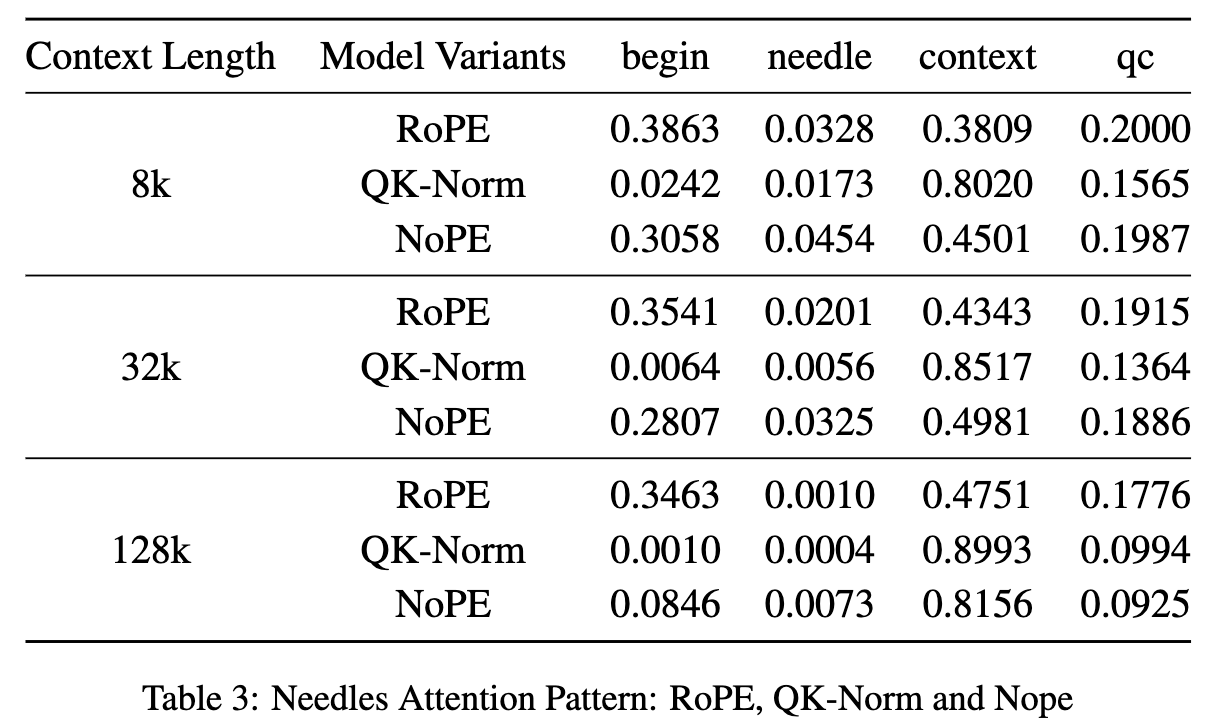
- 对于每个模型,我们首先计算“qc”查询token与所有四个段落的键token之间的注意力分数。注意力分数在每个段内进行求和,然后在所有注意力头和层之间进行聚合,以获得每个段的平均注意力分数。这些分数进一步在多个样本上按序列长度(8000、32000、128000 token)进行平均。我们称这一指标为“注意力质量”(attention mass),结果见表3。
- 随着序列长度增加,所有变体在“针”token上的注意力质量都在下降,表明相关信息的检索难度随上下文增长而增大。
- 在同一上下文长度下,NoPE 变体对“针”的注意力质量最高,其次是 RoPE,而 QK-Norm 最低。
- QK-Norm 在 “开头token” 上的注意力质量极低,而在“噪声上下文”上的注意力质量较高,这与其在 NIAH 任务中相对较差的表现一致。QK-Norm 中的归一化操作削弱了 Query 与 Key 向量点积中的幅度信息,导致注意力 logit 更接近且分布更平坦。
混合模型(Hybrid Model)
提出了一种结合 RoPE 和 NoPE 的新架构——RNoPE,以融合两种方法的优势。将两者结合有望在保持长上下文能力的同时提升整体性能。
- NoPE 能够通过向量相似性实现高效的信息检索
- RoPE 则能够显式建模位置信息和“最近性偏置”(recency bias)
实现方式:在模型中交替使用 NoPE 层和 RoPE 层:在一个层中应用 NoPE,在下一层中应用 RoPE
RNoPE 训练与评估
- 预训练阶段 RoPE 参数 θ 统一设为 10,000。随后我们进行多轮微调,分别尝试了不同的 θ 值:10,000、100,000、200万和400万,以评估不同配置下的模型表现。
- 将该变体称为 RNoPE 变体 ,并根据 SFT 阶段使用的 θ 值分别命名为:
- RNoPE-10k(θ = 10,000)
- RNoPE-100k(θ = 100,000)
- RNoPE-2M(θ = 2,000,000)
- RNoPE-4M(θ = 4,000,000)
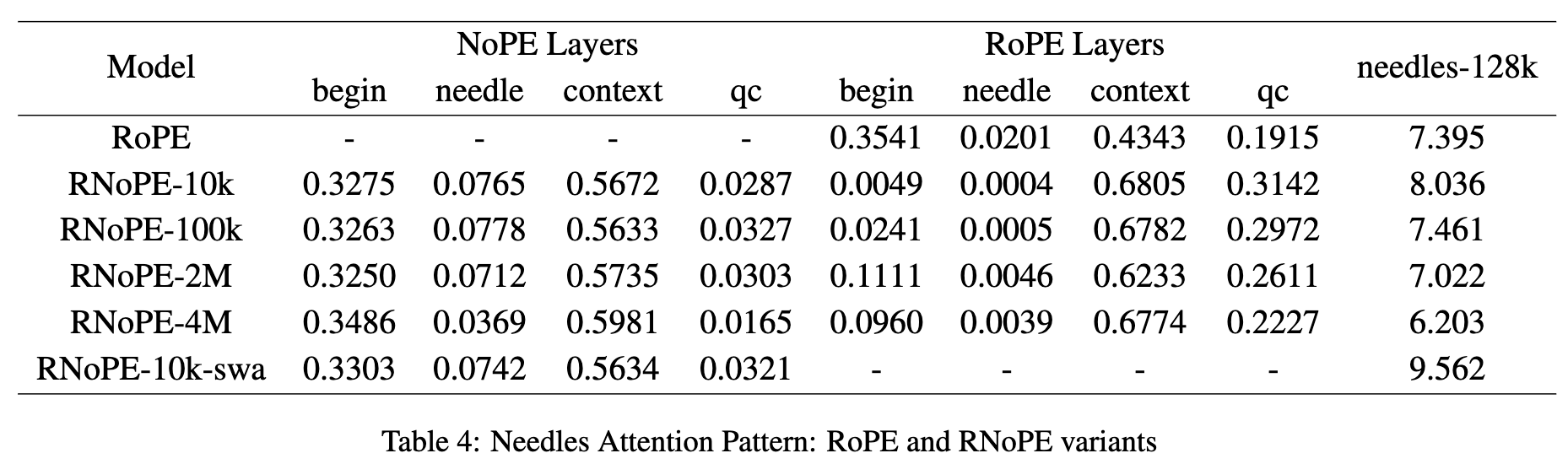
在序列长度为 128,000 的 NIAH 任务上报告针句得分,并计算各变体的注意力质量(attention mass),结果见表4。注意力质量分别对所有 RoPE 层和 NoPE 层进行聚合。
- 随着 SFT 阶段 RoPE 参数 θ 的增加,模型的长上下文能力反而下降。这与之前纯 RoPE 模型中的观察相矛盾:在那些模型中,更大的 θ 值通常有助于提升长上下文性能,并扩展注意力机制的有效感受野
- NoPE 层的表现
- 表现出强大的信息检索能力,表现为在针句 token 上注意力质量显著增强
- 在开头 token 上出现明显的 attention sink 现象
- 相较于纯 RoPE 或纯 NoPE 模型,其 recency bias 更弱
- RoPE 层的表现
- 检索能力极弱,针句和开头 token 的注意力质量都很低。
- 几乎没有 attention sink 现象。
- 却展现出比纯 RoPE 模型更强的 recency bias。
- 不同 θ 值的影响 :
- 随着 θ 增大,RoPE 层的 recency bias 减弱,表现为对 qc token 的注意力质量下降。
- 这与已有研究一致:增大 θ 会扩展注意力机制的有效感受野,使注意力分布更平坦
- RoPE 层感受野的扩大引入了噪声,干扰了后续 NoPE 层进行相似度计算和信息检索的能力,最终导致针句得分下降。
【结论】
- NoPE 与 RoPE 层的组合具有协同优势 :
- NoPE 层擅长全局信息检索;
- RoPE 层则因具备 recency bias 而适合处理局部上下文信息。
改进方案:RNoPE-10k-swa
基于上述洞察,我们提出了一个新的变体:RNoPE-10k-swa ,其中 “swa” 表示滑动窗口注意力(Sliding Window Attention)。
-
具体做法是:
- 对 RoPE 层设置硬性的注意力窗口大小(设为 8,192),从而限制其有效注意力范围;
- 同时保留 NoPE 层的全注意力机制,用于长上下文信息检索;
- 其他训练参数与 RNoPE-10k 保持一致,包括 θ 值不变。
-
变体取得了显著改进:
- 在 128,000 token 长度下的 NIAH 得分达到 9.562 ,明显优于基线模型和原始 RNoPE-10k;
- NoPE 层展现出结构清晰的注意力模式,表明其具备强大的长上下文检索能力。
模型架构
- 在 Command R+ 架构 (Cohere For AI, 2024)的基础上进行了以下关键架构设计选择:
- 移除 QK-Norm 组件 :由于其注意力模式不佳,严重影响长上下文性能,因此我们决定不再使用 Query-Key Normalization。
- 引入全注意力范围的 NoPE 层 :通过在部分层中使用无位置嵌入(NoPE)机制,增强模型对长距离信息的检索能力。
- 对 RoPE 层应用滑动窗口机制 :设置 RoPE 层的滑动窗口大小为 4,096,利用 RoPE 固有的“最近性偏置”(recency bias),提升模型在中短上下文范围内的表现。
- 全注意力层与滑动窗口层交错比例为 1:3
Experiments
标准基准任务
-
RNope-SWA 在长上下文任务上显著优于基线模型,同时在短上下文任务中也保持竞争力 ,实现了效率与性能之间的良好平衡。
- 在 MMLU 上提升 +2.0%,在 GSM8k 上提升 +1.8%;

- 在 MMLU 上提升 +2.0%,在 GSM8k 上提升 +1.8%;
-
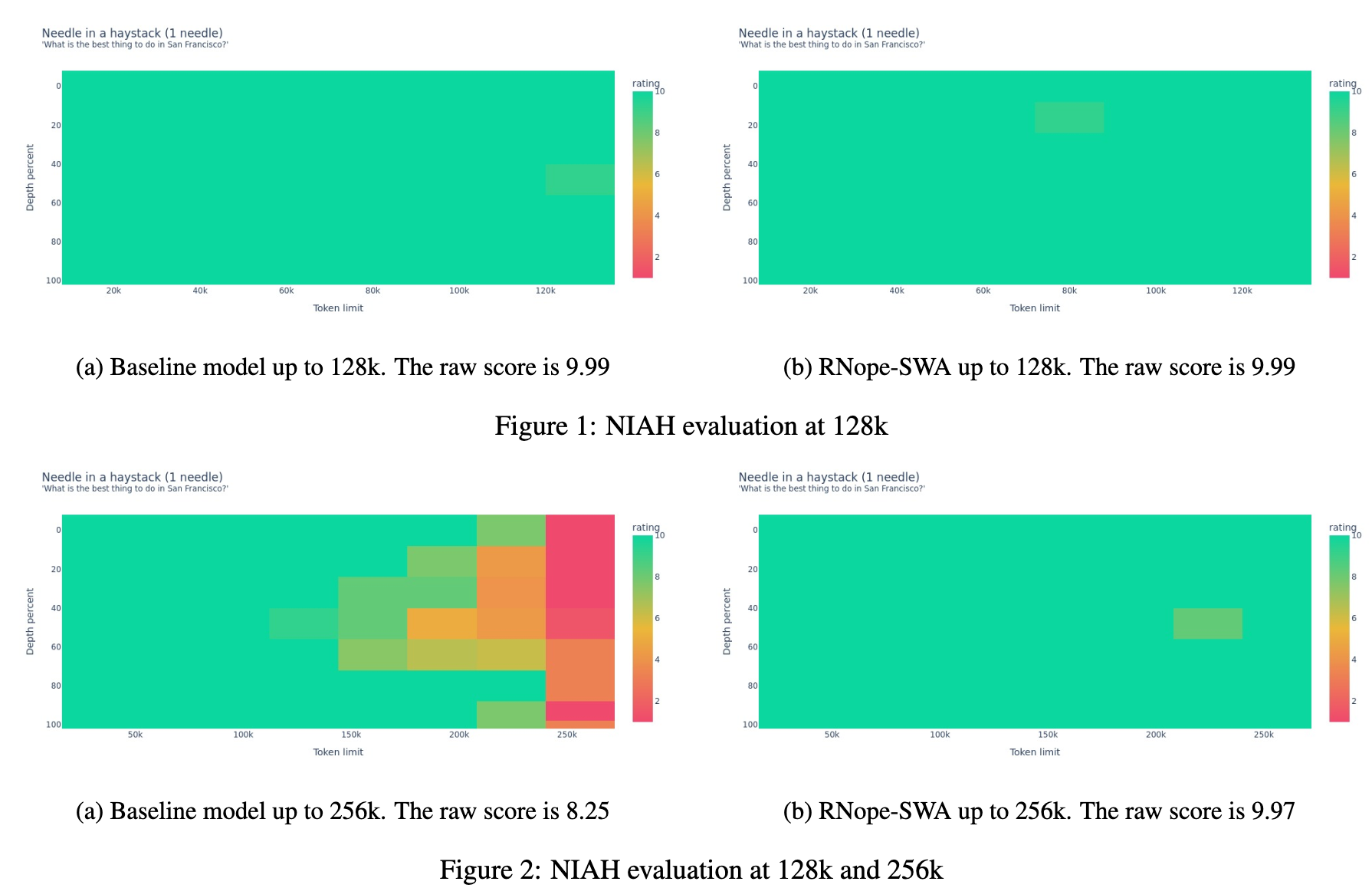
长文本下的检索能力, NIAH 任务(Needles-in-a-Haystack)
- 虽然两个模型在训练见过的上下文长度内都能接近满分,但 RNope-SWA 具有更强的外推能力
- 在 256k 上下文长度下,RNope-SWA 几乎没有性能下降,而 Baseline 即使使用了 θ=8,000,000 的 RoPE 参数,也表现出显著的性能退化
Ruler 基准任务(检索与问答)
Ruler 是比 NIAH 更具挑战性的任务集合,包含多查询/键/值设置、长上下文问答等;
- Baseline 在超过 64k 的上下文长度后性能急剧下降
- 在 8k 到 256k 的变化中:
- 检索任务得分从 96.6 降至 57.1(下降约 41%)
- 问答任务得分从 53.5 降至 30.0(下降约 44%)
- 在 8k 到 256k 的变化中:
- 而 RNope-SWA 分别仅下降 22.1% 和 23.4% ,表现更稳定。

训练与推理效率分析
- 训练阶段:
- 设滑动窗口大小为 S,完整上下文长度为 L;
- 75% 的层现在使用 O(SL) 复杂度计算,而非传统 O(L²);
- 使用 Flash Attention 和序列并行技术(sequence-parallel):
- 在 64k 上下文长度下,训练吞吐量提升约 50%;
- 在 128k 上下文长度下,提升近 2 倍。
- 推理阶段:
- 理论上,KV 缓存最多可节省 75%;
- 实测结果:
- 使用 132k 输入 token、96 输出 token 时,端到端延迟降低约 44%;
- 使用 990k 输入 token、8 输出 token 时,延迟降低近 70%;
Conclusion
- 提出了 RNope-SWA ,一种结合 NoPE 与 RoPE 的混合注意力架构,通过交错使用全注意力与滑动窗口机制,在保持高性能的同时大幅提升训练与推理效率。