Qwen3技术报告解读
https://github.com/QwenLM/Qwen3/blob/main/Qwen3_Technical_Report.pdf
节前放模型,大晚上的发技术报告。通义,真有你的~
文章目录
- 预训练
- 后训练
- Long-CoT Cold Start
- Reasoning RL
- Thinking Mode Fusion
- General RL
- Strong-to-Weak Distillation
- 模型结构

先看下摘要里提到的几个亮点:
-
包括Dense和Moe模型,参数量横跨0.6B到235B。
Dense包括:Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B。
Moe包括:- Qwen3-235B-A22B,235B 总参数和 22B 激活参数的大型MoE模型。
- Qwen3-30B-A3B,30B 总参数和 3B 激活参数的小型MoE模型。
-
把thinking和non-thinking模式集成在一个模型中。并且,只需要在提示词中就能进行两个模式的切换。
-
多语言支持,从29种到119种。
在Qwen3发布的当天,笔者就赶紧在自己的任务上尝试了新发布的模型,就我的任务而言相比Qwen-2.5来说还是有比较明显的提升的。终于等到技术报告发布了,赶紧来看看~
目录:
- 预训练
- 后训练
- Long-CoT Cold Start
- Reasoning RL
- Thinking Mode Fusion
- General RL
- 模型结构
预训练
在更大规模的数据上进行了预训练,语言扩充到了119种,token数达到了36万亿!Qwen2.5则只有18万亿个。
怎么扩充到这么大规模的预训练数据?
- 多模态的方案。使用微调后的Qwen2.5-VL提取PDF中的文本。
- 合成数据。使用Qwen2.5-Math和Qwen2.5-Coder合成数学、代码领域的数据。
为了提高数据的质量和多样性,开发了一个多语言的数据标注系统。使用该系统对训练数据集进行了详细的标注,覆盖了多个维度,包括教育价值、领域、主题和安全性等。这些标注信息会被用于过滤和组合数据。
预训练分成三个阶段:
- General Stage,S1。
模型在 30 万亿个 token 上进行预训练,上下文长度为 4K token。为模型提供了基本的语言技能和通用知识。 - Reasoning Stage,S2。
通过增加知识密集型数据(如 STEM、编程和推理任务)的比例来增强模型的推理能力,随后模型又在额外的 5 万亿个 token 上进行了预训练。 - Long Context Stage,最后阶段。
使用高质量的长上下文数据将上下文长度扩展到 32K token,确保模型能够有效地处理更长的输入。这一阶段的数据种,75%的样本长度在16k-32k,25%在4k-16k。
后训练
四阶段的后训练流程,以对齐人类偏好和下游任务。
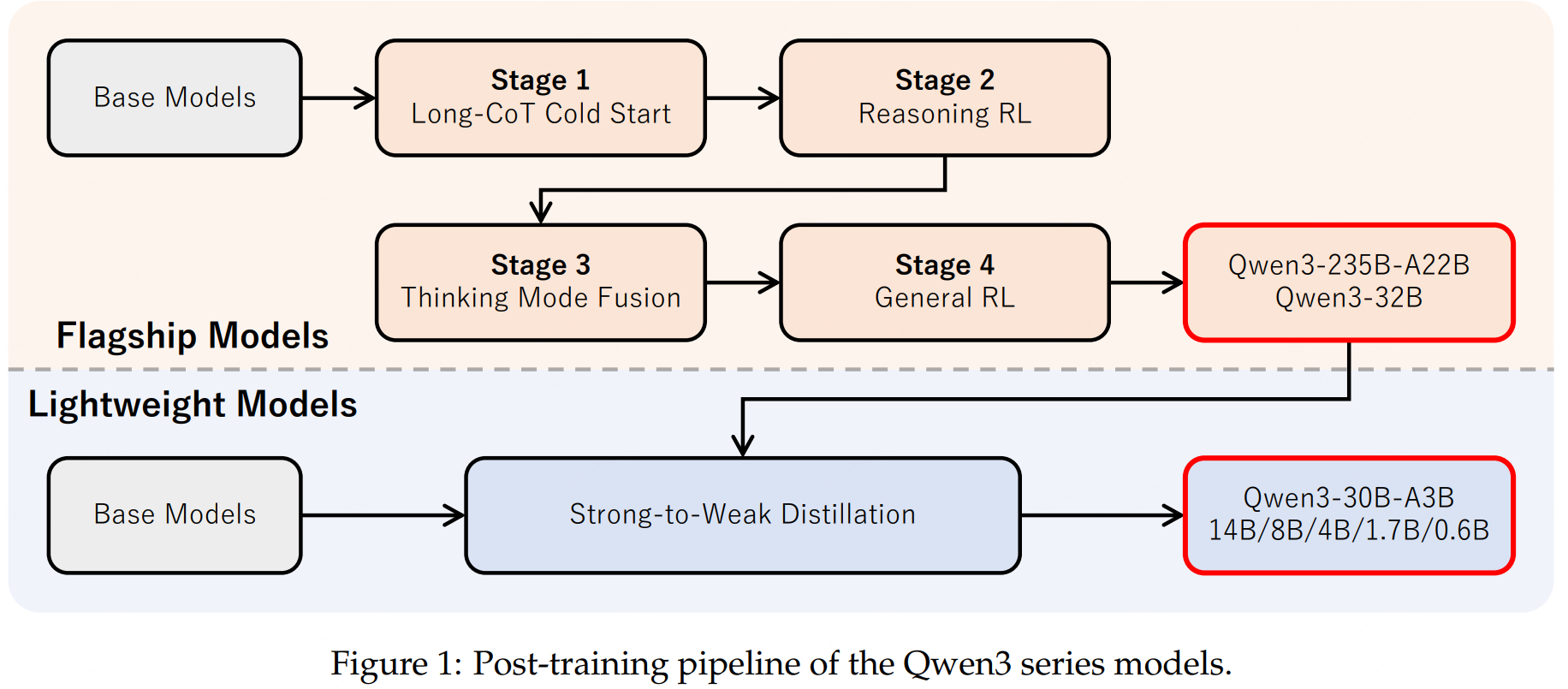
- Long-CoT Cold Start,长思维链冷启动。
使用多样的的长思维链数据进行微调,涵盖了数学、代码、逻辑推理和 STEM 问题等多种任务和领域,在为模型配备基本的推理能力。 - 长思维链强化学习。
大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力。 - 思维模式融合。
在一份包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中。通过一个token(/no_think)来进行模式的切换。 - 通用强化学习。
在包括指令遵循、格式遵循和 Agent 能力等在内的 20 多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力并纠正不良行为。
另外,可以看到,Qwen3-235B-A22B和Qwen3-32B是按照上面四阶段的后训练流程训的,其他模型则是在这两个的基础上蒸馏出来的。看看每个阶段的一些重点。
Long-CoT Cold Start
使用的数据,包括数学、代码、逻辑推理和STEM,数据集里的每个问答样本都有参考答案、代码样本都配备测试样例。
数据怎么怎么构造的?严格的两阶段的过滤过程:query过滤和response过滤。
-
query过滤。
- 使用Qwen2.5-72B-Instruct识别并过滤那些难以验证的query,例如包含多个子问题或通用文本生成的query。
- 此外,还过滤了Qwen2.5-72B-Instruct无需cot就能正确回答的问题,以确保数据集中只包含需要深度推理的问题。
- 并且使用Qwen2.5-72B-Instruct标注了每个query的领域,以确保数据领域的均衡。
-
response过滤。
- query过滤后,使用QwQ-32B为每个query生成多个候选响应。
- 对于QwQ-32B无法生成正确解决方案的查询,由人工标注员评估响应的准确性。进一步的筛选标准包括移除最终答案错误、重复过多、明显猜测、思考与总结内容不一致、语言混用或风格突变、以及可能与验证集项目过于相似的响应。
Reasoning RL
这一阶段的数据必须满足的要求:
- 在上一阶段没有使用过。
- 对于冷启动模型是可以学习的。
- 要有挑战性。
- 覆盖广泛的子领域。
最终收集了3995(才这么点数据?🤔)个query-verfier pair进行GRPO训练。
在训练策略上,通过控制模型的熵(即模型输出的不确定性)来平衡探索和利用。熵的增加或保持稳定对于维持稳定的训练过程至关重要。
Thinking Mode Fusion
这一阶段的目标是实现对推理行为的管理和控制,即think和no-think的切换,通过SFT实现,并且设计了chat template融合两种模式。
SFT数据怎么构建的?
为了确保上一步得到的模型的性能不被SFT影响,thinking的数据是使用第一阶段的query在第二阶段的模型上做拒绝采样得到的。non-thinking的数据则是精心筛选(具体怎么做的没有细说)的涵盖大量任务的数据,例如代码、数学、指令跟随、多语言任务、创意写作、问答和角色扮演等。对于non-thinking的数据,通过自动生成的checklist来评估响应的质量。
两类数据的模板:
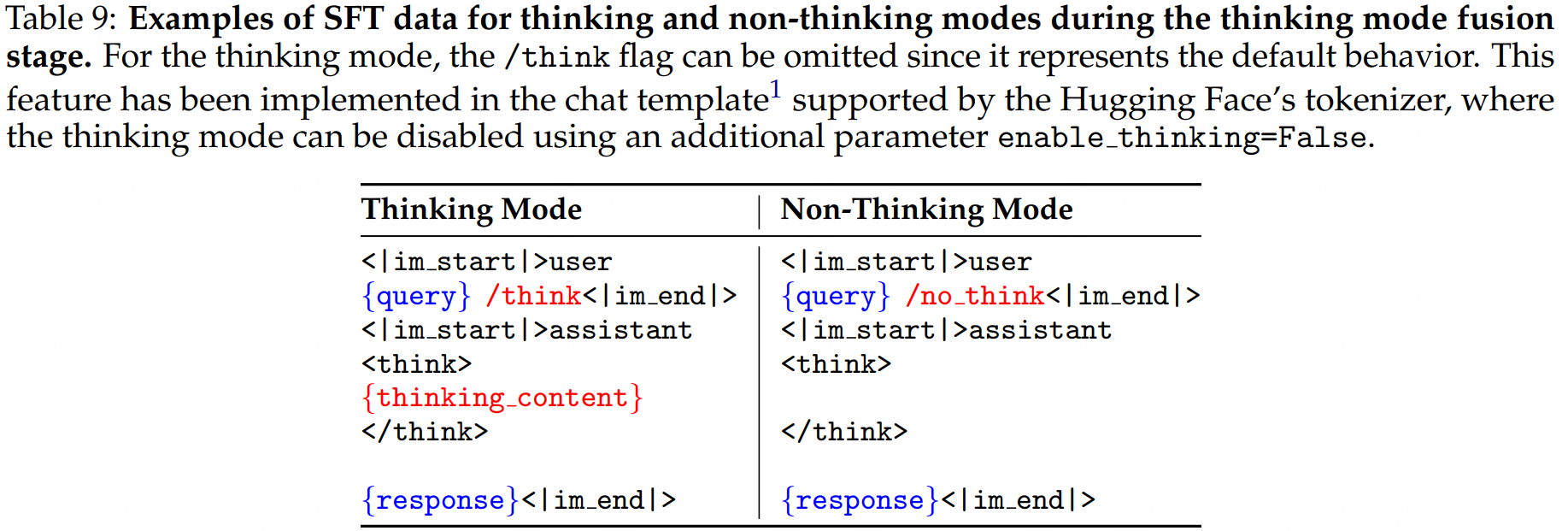
默认情况下是开启think模式的,为此还在训练数据中添加了一些不包含/think的带思考过程的样本。
此外,还通过训练实现了模型生成时自动进行预算控制(Thinking Budget)。一种具体的情况——不完整的思考过程下也能正常回答问题。在推理时,用户可以指定一个budget,当模型的思考过程达到了指定的阈值时,则手动停止思考过程,并插入停止思考的指令,让模型直接开始回答问题。

General RL
重点在奖励的设计上,覆盖了20种不同的任务。一共有三种类型的奖励:
- Rule-based Reward。
- Model-based Reward with Reference Answer。用Qwen2.5-72B-Instruct对模型的回答和参考答案进行打分。
- Model-based Reward without Reference Answer。对于没有标准答案的样本,利用偏好数据训练了一个打分模型对模型回答打分作为标量奖励。
特别的,这一阶段训练了模型的Agent的能力,在RL的Rollout时,允许模型和外部环境进行多轮的交互。
Strong-to-Weak Distillation
前面的这四个阶段使用来训Qwen3-235B-A22B和Qwen3-32B的,其余的小模型都是在这个阶段蒸馏得到的。蒸馏时有两个阶段:
-
Off-policy Distillation。
使用强模型(Qwen3-32B或Qwen3-235B-A22B)在思考模式和非思考模式下的生成,将这些输出作为弱模型的训练目标。 -
On-policy Distillation。
在思考和非思考模式下,从弱模型中采样,通过最小化弱模型和强模型输出之间的KL散度对弱模型进行微调。
感觉论文种讲的不是很清楚。
模型结构
Dense模型与Qwen2.5的模型结构类似,包括使用了GQA、SwiGLU、RoPE、RMSNorm和pre-normalization。不同之处:去除了QKV-bias、引入了QK-Norm。MoE模型的基础架构和Qwen3 Dense是一样的。
Dense和MoE的模型架构如下所示: