《k-means 散点图可视化》实验报告
一,实验目的
本次实验旨在通过Python编程实现k - means算法的散点图可视化。学习者将编写代码,深入理解聚类分析基本原理与k - means算法实现流程,掌握数据聚类及可视化方法,以直观展示聚类结果。
二,实验原理
- k-means 算法原理
k-means 算法是一种常用的无监督学习算法,用于将数据集划分为 k 个不同的簇。其基本原理是:首先随机选择 k 个点作为初始聚类中心,然后将数据集中的每个点分配到距离其最近的聚类中心所在的簇,接着重新计算每个簇的中心(即均值),并重复上述分配和更新中心的过程,直到聚类中心不再发生显著变化或达到最大迭代次数。
k-means 算法的目标是最小化簇内误差平方和(SSE,Sum of Squared Errors),也称为惯性(inertia),计算公式为:

1)算法概述:k - means 算法是一种无监督学习算法,目标是将数据集划分成 k 个簇。
2)初始化:随机挑选 k 个点作为初始聚类中心,初始点的选择会对算法收敛速度和最终聚类结果产生影响。
3)分配数据点:采用常用的欧几里得距离作为距离度量,计算数据集中每个点到 k 个聚类中心的距离,把各点划分至距离最近的聚类中心所在簇。
4)更新聚类中心:针对每个簇,计算簇内所有数据点的均值,并用该均值更新对应簇的聚类中心。
5)迭代优化:不断重复 “分配数据点” 和 “更新聚类中心” 这两个步骤,直到聚类中心的变化小于特定阈值,或者达到预先设定的最大迭代次数。
6)目标函数:算法以最小化簇内误差平方和(SSE,即惯性)为目标,计算公式为SSE=∑i=1k∑x∈Ci∥x−μi∥2 。通过持续迭代使 SSE 不断减小,促使同一簇内的数据点紧密聚集,达成有效聚类。
2.k-means聚类的应用场景
K-means聚类广泛应用于数据分析、模式识别、图像分割等领域。例如客户分群、文本分类、图像压缩等。
3.K-means聚类的优缺点
优点:实现简单、计算高效、适用于大型数据集。
缺点:对初始值敏感,可能收敛到局部最优解,需要事先确定簇个数K。
4.算法实现流程
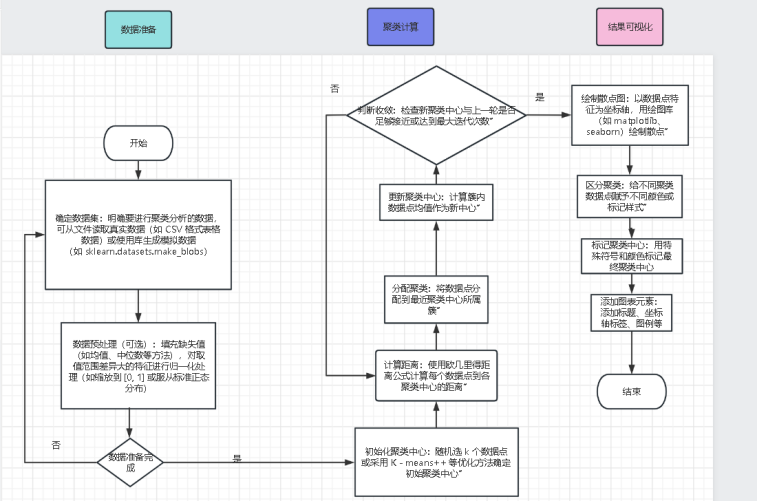
K - means散点图可视化流程图涵盖数据准备、聚类计算、结果可视化三阶段。数据准备时,先明确数据集来源,可选真实文件数据或模拟生成数据,若数据有缺失值或特征取值差异大,需进行预处理。聚类计算先初始化聚类中心,可随机选或用优化方法;接着进入迭代,算距离、分配聚类、更新中心并判断收敛,不满足则继续迭代。结果可视化阶段,先以特征为轴绘制散点图,再用不同颜色区分聚类,标记聚类中心,添加标题、标签、图例等图表元素,最终完成K - means散点图可视化流程。
5.数据可视化方法
散点图是呈现二维数据分布的高效手段,在k-means聚类里,可借助散点图将不同簇的数据点以不同颜色呈现,同时标注每个簇的中心位置,以此直观展现聚类结果。 此外,为确定最优聚类数量k,可运用手肘法绘制不同k值对应的SSE曲线,选取曲线拐点处的k值作为最佳聚类数量。
三、实验环境
编程语言:Python
主要库:numpy用于数值计算,matplotlib用于数据可视化。
运行平台:window10
四,实验步骤
1.库导入:
导入numpy库用于数值计算,matplotlib.pyplot用于数据可视化。

2.数据生成:使用numpy库的随机数生成函数,从三个不同均值的二维正态分布中生成数据点,并将它们堆叠在一起,形成一个包含 300 个二维数据点的数据集X。

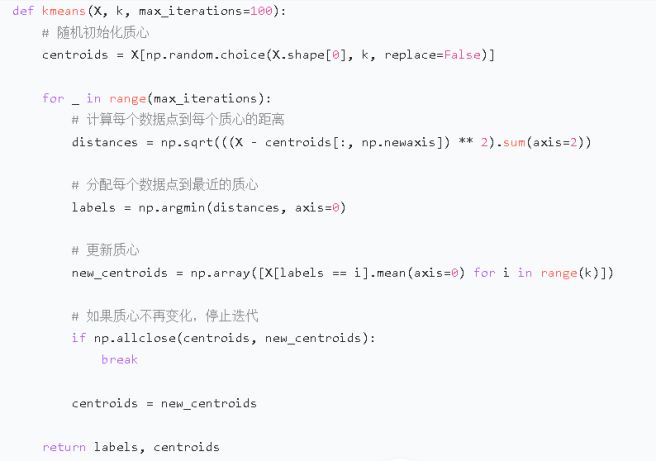
3.K - means 聚类:定义kmeans函数实现 K - means 算法。在函数内,首先随机初始化k个质心,然后通过多次迭代,不断更新数据点的聚类分配以及质心位置,直到质心不再显著变化或达到最大迭代次数。
4.结果可视化:调用kmeans函数对生成的数据集X进行聚类,得到聚类标签和最终质心。使用matplotlib库绘制散点图,将不同聚类的数据点用不同颜色表示,聚类中心用特殊标记(红色叉号)表示,同时添加标题和坐标轴标签以展示聚类结果。

五,实验结果
从可视化的散点图中可以清晰地看到,数据点被成功划分到了 3 个不同的聚类中,不同颜色的点代表不同的聚类,红色叉号准确标识出了各个聚类的中心位置。这表明 K - means 算法在该示例数据集上能够有效地进行聚类操作,直观地展示了聚类效果。

六,实验总结
通过本次实验,成功实现了 K - means 聚类算法并将其结果进行可视化展示。在实验过程中,对 K - means 算法的原理有了更深入的理解,掌握了使用 Python 相关库进行数据处理、聚类分析和可视化的方法。同时也发现,K - means 算法对初始质心的选择较为敏感,不同的初始质心可能导致不同的聚类结果。在未来的研究中,可以进一步探索更优化的初始质心选择方法,以及将该算法应用于更复杂的实际数据集,以提高对聚类算法的应用能力。
import numpy as np
import matplotlib.pyplot as pltdef kmeans(X, k, max_iterations=100):# 随机初始化质心centroids = X[np.random.choice(X.shape[0], k, replace=False)]for _ in range(max_iterations):# 计算每个数据点到每个质心的距离distances = np.sqrt(((X - centroids[:, np.newaxis]) ** 2).sum(axis=2))# 分配每个数据点到最近的质心labels = np.argmin(distances, axis=0)# 更新质心new_centroids = np.array([X[labels == i].mean(axis=0) for i in range(k)])# 如果质心不再变化,停止迭代if np.allclose(centroids, new_centroids):breakcentroids = new_centroidsreturn labels, centroids# 生成一些示例数据
np.random.seed(42)
X = np.vstack([np.random.normal([0, 0], 1, (100, 2)),np.random.normal([5, 5], 1, (100, 2)),np.random.normal([10, 0], 1, (100, 2))
])# 运行 K-means 算法
k = 3
labels, centroids = kmeans(X, k)# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.scatter(centroids[:, 0], centroids[:, 1], marker='X', s=200, c='red')
plt.title('K-means Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()