Python - 爬虫;Scrapy框架之items,Pipeline管道持久化存储(二)
阅读本文前先参考
https://blog.csdn.net/MinggeQingchun/article/details/145904572
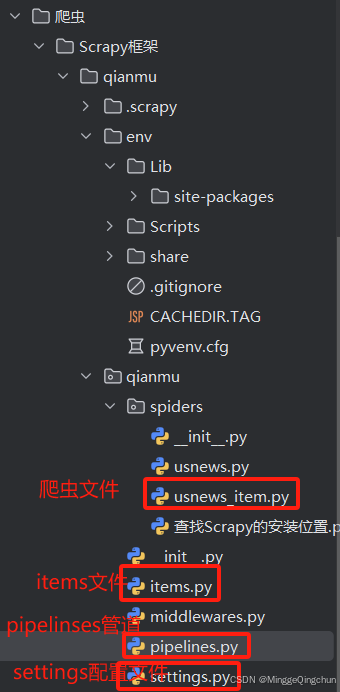
1、基于管道的持久化存储,主要依靠scrapy框架的item.py和pipelines.py文件
item.py:数据结构模板文件,定义数据属性
pipelines.py:管道文件,接收数据(item),进行持久化操作
2、爬虫文件、items文件、pipelines文件三者关系:
(1)首先,spider 爬取了数据,过滤后 写入到items中
(item是scrapy中,连结spider和pipeline的桥梁,即items是 定义数据结构 )
(2)其次,再通过yield返回爬取数据给核心引擎并 交付给pipeline
(3)最后,pipeline通过 调用items获取数据,再 写入指定文件或通过数据库连接存入数据库3、整个流程:
(1)爬虫文件爬取到数据后,把数据赋给item对象
(2)使用yield关键字将item对象提交给pipelines管道
(3)在管道文件中的process_item方法接收item对象,然后把item对象存储
(4)在setting中开启管道
官网文档:Item Pipeline — Scrapy 2.12.0 documentation
以爬虫迁木网 专注留学DIY-只做精细内容-迁木网 为例
1、 items文件(定义数据结构)定义数据属性,在item.py文件中编写数据的属性
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapy'''
迁木网大学信息的字段
类似Java中的Model
'''
class QianmuUniversityItem(scrapy.Item):# define the fields for your item here like:name = scrapy.Field()runk = scrapy.Field()country = scrapy.Field()state = scrapy.Field()city = scrapy.Field()undergraduate_num = scrapy.Field()postgraduate_num = scrapy.Field()website = scrapy.Field()
2、爬虫文件(爬取数据),项目.spider爬虫程序
import scrapyfrom 爬虫.Scrapy框架.qianmu.qianmu.items import QianmuUniversityItem'''
settings.py中有一个HTTPCACHE_ENABLED配置
# 启用HTTP请求缓存,下次请求同一URL时不再发送远程请求
HTTPCACHE_ENABLED = True
'''class UsnewsSpider(scrapy.Spider):name = "usnews"# 允许爬虫的URL必须在此字段内;genspider时可以指定;如qianmu.com意味www.qianmu.com和http.qianmu.org下的链接都可以爬取allowed_domains = ["www.qianmu.org"]# 爬虫的入口地址,可以多个start_urls = ["http://www.qianmu.org/2023USNEWS%E4%B8%96%E7%95%8C%E5%A4%A7%E5%AD%A6%E6%8E%92%E5%90%8D"]# 框架请求start_urls成功后,会调用parse方法def parse(self, response):# 提取链接,并释放links = response.xpath('//div[@id="content"]//tr[position()>1]/td/a/@href').extract()for link in links:if not link.startswith('http://www.qianmu.org'):link = 'http://www.qianmu.org/%s' % link# 请求成功以后,异步调用callback函数yield response.follow(link, self.parse_university)def parse_university(self, response):# 去除空格等特殊字符response = response.replace(body=response.text.replace('\t','').replace('\r\n', ''))item = QianmuUniversityItem()data = {}item['name'] = response.xpath('//div[@id="wikiContent"]/h1/text()').extract_first()# data['name'] = response.xpath('//div[@id="wikiContent"]/h1/text()')[0]table = response.xpath('//div[@id="wikiContent"]//div[@class="infobox"]/table')if not table:return Nonetable = table[0]keys = table.xpath('.//td[1]/p/text()').extract()cols = table.xpath('.//td[2]')# 当我们确定解析的数据只有1个结果时,可以使用extract_first()函数values = [' '.join(col.xpath('.//text()').extract()) for col in cols]if len(keys) == len(values):data.update(zip(keys, values))item['runk'] = data.get('排名')item['country'] = data.get('国家')item['state'] = data.get('州省')item['city'] = data.get('城市')item['undergraduate_num']= data.get('本科生人数')item['postgraduate_num']= data.get('研究生人数')item['website'] = data.get('网址')# yield出去的数据会被Scrapy框架接收,进行下一步处理;如果没有任何处理,则会打印到控制台yield item此时运行爬虫文件,可以看到数据格式输出如下

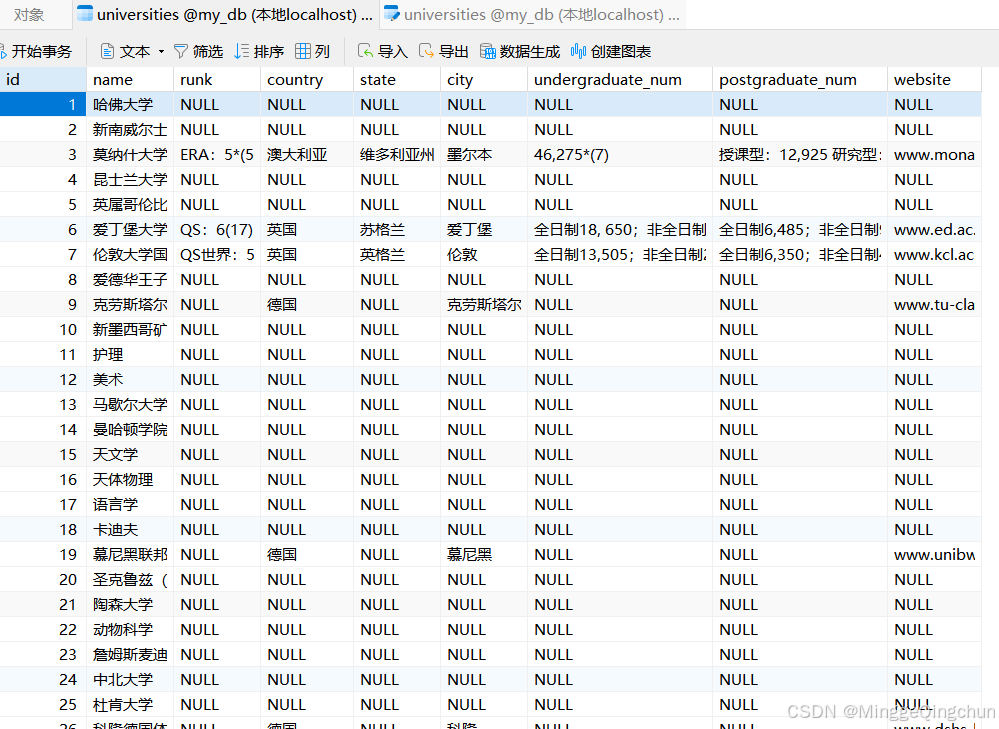
3、Pipelines文件(保存数据); pipelines.py文件代码的实现,也就是真正的存储过程
(1)MySQL存储
建一个大学表【universities】
CREATE TABLE `universities` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(256) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '学校名称',
`rank` varchar(128) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '学校排名',
`country` varchar(128) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '国家',
`state` varchar(128) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '州省',
`city` varchar(128) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '城市',
`undergraduate_num` varchar(128) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '本科生人数',
`postgraduate_num` varchar(128) COLLATE utf8mb4_unicode_ci DEFAULT NULL COMMENT '研究生人数',
`website` text COMMENT '网站地址',
PRIMARY KEY (`id`)
)ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='大学信息表'# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import redis
# useful for handling different item types with a single interface
from itemadapter import ItemAdapterimport pymysql
from redis import Redis
from scrapy.exceptions import DropItemfrom 爬虫.抓取网页数据.urllib_test import value'''
开启settings配置文件中ITEM_PIPELINES
在Scrapy框架中,ITEM_PIPELINES配置项用于定义数据处理的顺序。来指定哪些管道(pipelines)将被启用以及它们的执行顺序。
每个管道都是一个元组(tuple),包含两个元素:管道的路径和它的优先级(整数)。优先级越高,管道执行的越早。自定义的优先级设置为300以上
ITEM_PIPELINES = {"qianmu.pipelines.MysqlPipeline": 300,
}
'''
class MysqlPipeline(object):def open_spider(self,spider):self.conn = pymysql.connect(host='localhost',port=3306,user='root',password='ming1992',database='my_db',charset='utf8')self.cursor = self.conn.cursor()def close_spider(self,spider):self.cursor.close()self.conn.close()def process_item(self, item, spider):# keys = item.keys()# values = [item[k] for k in keys]# MySQL 不接受 None 作为值,应该将其转换为 NULL 或者跳过这些字段# 处理None值:如果某些字段允许为NULL,可以在过滤时保留这些字段,并将None映射为NULL# 过滤掉值为 None 的字段,或者将 None 转换为 NULLprint('处理前:',item.items())filtered_item = {k: ('NULL' if v is None else v) for k, v in item.items()}print('处理后:', filtered_item)keys, values = zip(*filtered_item.items())print(f'处理keys:{keys};values:{values}')sql = "insert into {} ({}) values ({})".format('universities',','.join(keys),','.join(['%s'] * len(values)))print('执行SQL语句', sql)try:self.cursor.execute(sql, values)self.conn.commit()except pymysql.MySQLError as e:print(f"Error inserting data into MySQL: {e}")print('SQL语句',self.cursor._last_executed)return item
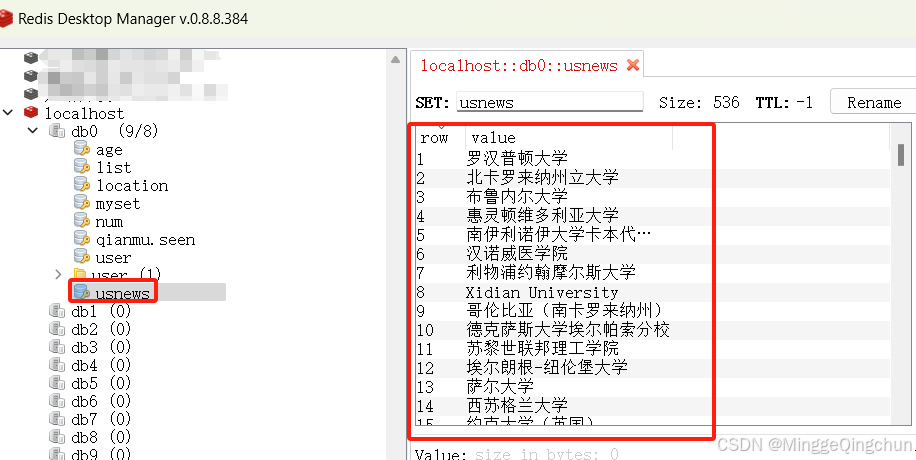
(2)Redis中存储
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import redis
# useful for handling different item types with a single interface
from itemadapter import ItemAdapterimport pymysql
from redis import Redis
from scrapy.exceptions import DropItemfrom 爬虫.抓取网页数据.urllib_test import value'''
开启settings配置文件中ITEM_PIPELINES
在Scrapy框架中,ITEM_PIPELINES配置项用于定义数据处理的顺序。来指定哪些管道(pipelines)将被启用以及它们的执行顺序。
每个管道都是一个元组(tuple),包含两个元素:管道的路径和它的优先级(整数)。优先级越高,管道执行的越早。自定义的优先级设置为300以上
ITEM_PIPELINES = {"qianmu.pipelines.MysqlPipeline": 300,
}
'''
class RedisPipeline(object):def open_spider(self,spider):self.redisPool = redis.ConnectionPool(host='localhost',port=6379,decode_responses=True)self.redis = redis.Redis(connection_pool=self.redisPool)def close_spider(self,spider):self.redis.close()self.redisPool.close()def process_item(self, item, spider):if self.redis.sadd(spider.name,item['name']):return itemreturn DropItemclass MysqlPipeline(object):def open_spider(self,spider):self.conn = pymysql.connect(host='localhost',port=3306,user='root',password='ming1992',database='my_db',charset='utf8')self.cursor = self.conn.cursor()def close_spider(self,spider):self.cursor.close()self.conn.close()def process_item(self, item, spider):# keys = item.keys()# values = [item[k] for k in keys]# MySQL 不接受 None 作为值,应该将其转换为 NULL 或者跳过这些字段# 处理None值:如果某些字段允许为NULL,可以在过滤时保留这些字段,并将None映射为NULL# 过滤掉值为 None 的字段,或者将 None 转换为 NULLprint('处理前:',item.items())filtered_item = {k: ('NULL' if v is None else v) for k, v in item.items()}print('处理后:', filtered_item)keys, values = zip(*filtered_item.items())print(f'处理keys:{keys};values:{values}')sql = "insert into {} ({}) values ({})".format('universities',','.join(keys),','.join(['%s'] * len(values)))print('执行SQL语句', sql)try:self.cursor.execute(sql, values)self.conn.commit()except pymysql.MySQLError as e:print(f"Error inserting data into MySQL: {e}")print('SQL语句',self.cursor._last_executed)return item
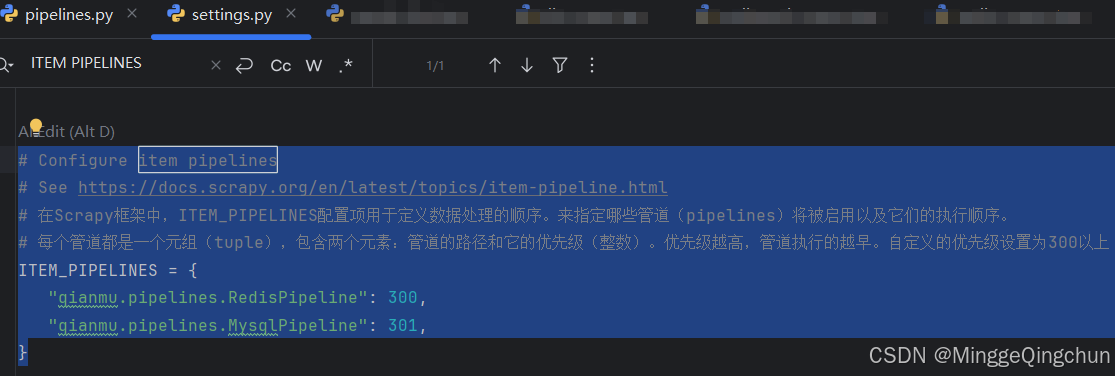
4、setting配置
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# 在Scrapy框架中,ITEM_PIPELINES配置项用于定义数据处理的顺序。来指定哪些管道(pipelines)将被启用以及它们的执行顺序。
# 每个管道都是一个元组(tuple),包含两个元素:管道的路径和它的优先级(整数)。优先级越高,管道执行的越早。自定义的优先级设置为300以上
ITEM_PIPELINES = {"qianmu.pipelines.RedisPipeline": 300,"qianmu.pipelines.MysqlPipeline": 301,
}