阿里开源通义万相 Wan2.1-VACE,开启视频创作新时代
0.前言
阿里巴巴于2025年5月14日正式开源了其最新的AI视频生成与编辑模型——通义万相Wan2.1-VACE。这一模型是业界功能最全面的视频生成与编辑工具,能够同时支持多种视频生成和编辑任务,包括文生视频、图像参考视频生成、视频重绘、局部编辑、背景延展以及视频时长延展等全系列基础生成和编辑能力。


下面详细给大家介绍一下它的技术和能力亮点。
1.核心技术与能力亮点
-
全面可控的生成能力****全面可控的生成能力
通义万相2.1-VACE 支持对视频生成进行细粒度控制,可基于多种控制信号生成内容,包括:-
人体姿态光流
-
结构保留
-
空间运动
-
色彩渲染
同时,它还支持基于主体和背景参考的视频生成。
-
-
强大的局部与全局编辑能力
- 局部编辑:可指定视频中的局部区域进行元素替换、添加或删除。
- 时间轴编辑:给定任意视频片段,可通过首尾帧补全生成完整视频。
- 空间扩展:支持视频扩展生成,典型应用包括视频背景替换 —— 在保持主体不变的前提下,根据文本提示更换背景。

-
多形态信息输入
为解决专业创作者面临的 “仅用文本提示难以精准控制元素一致性、布局、运动和姿态” 的局限,One2.1V 在 2.1 模型基础上进一步升级,成为集成文本、图像、视频、掩码和控制信号的统一视频编辑模型:- 图像输入:支持参考图像(物体相关)或视频帧输入。
- 视频输入:可通过擦除部分内容、局部编辑或扩展等操作实现视频重生成。
- 掩码输入:用户可通过 0/1 二进制信号指定编辑区域。
- 控制信号输入:支持深度图、光流布局、灰度图、线稿和姿态等信号。

-
统一的模型架构
其核心技术突破在于采用单一模型处理传统需要多个 “专业模型” 的任务,这得益于动态输入模块和继承自 2.1 模型的强大视频生成能力。这意味着,图像参考(元素一致性)、视频重创作(姿态迁移、运动 / 结构控制、色彩重渲染)、局部编辑(主体重塑 / 移除、背景 / 时长扩展)等功能均可通过 通义万相2.1-VACE实现。视频条件单元 VCU
通义万相团队深入分析和总结了文生视频、参考图生视频、视频生视频,基于局部区域的视频生视频4大类视频生成和编辑任务的输入形态,提出了一个更加灵活统一的输入范式:视频条件单元 VCU
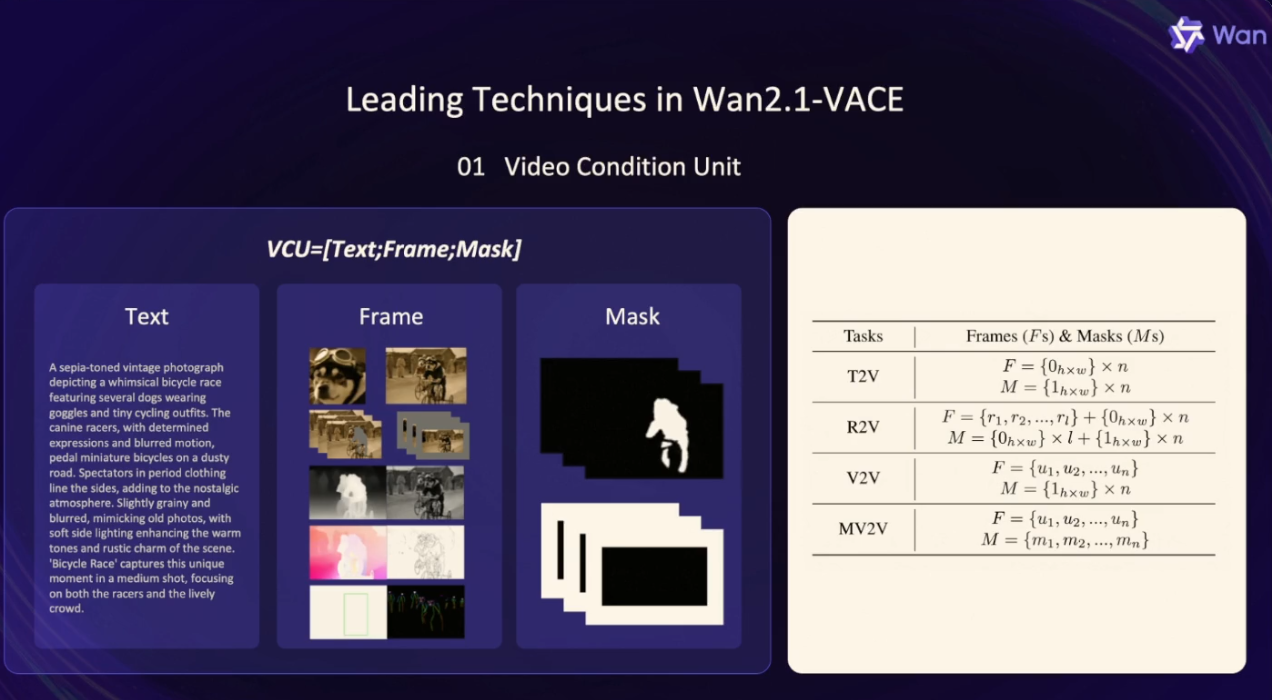
多模态输入的token序列化FINE-TUNING
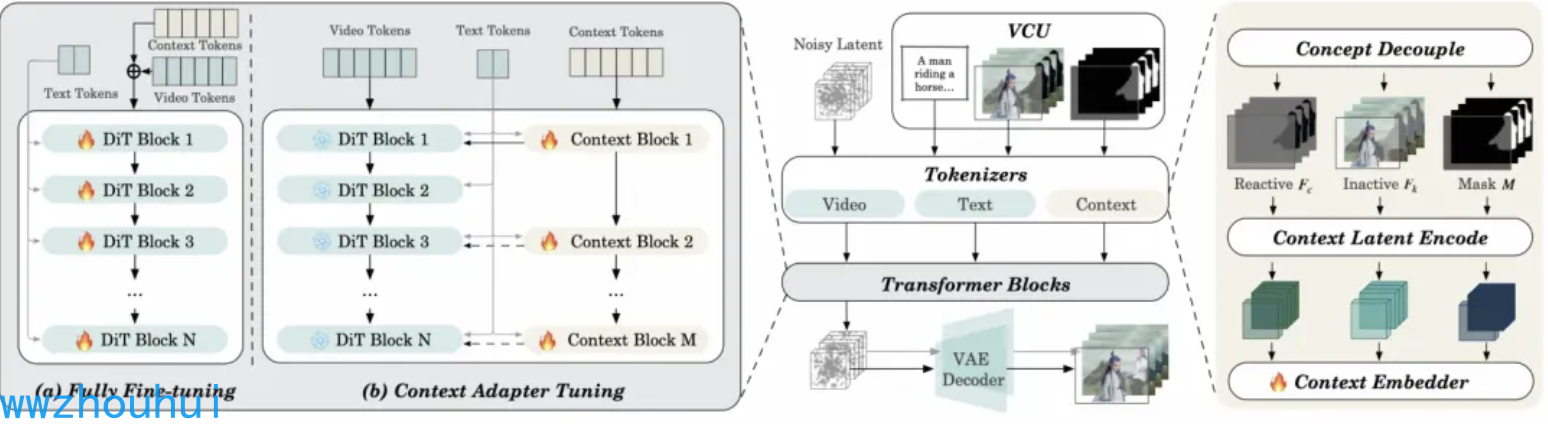
在多模态输入处理中,token 序列化是 Wan2.1 视频扩散 Transformer 架构精准解析输入信息的关键环节,而 VACE 成功攻克了这一难题。其处理流程可分为概念解耦、编码转换与特征融合三个核心步骤。
在概念解耦阶段,VACE 针对 VCU 输入的 Frame 序列,创新性地将图像元素按性质拆分。对于需保留原始视觉信息的 RGB 像素,以及承载控制指令等需重新生成的像素内容,分别构建可变帧序列与不变帧序列,为后续处理奠定基础。
进入编码转换环节,三类序列分别经历专属编码路径。可变帧序列与不变帧序列借助 VAE(变分自编码器),转化为与 DiT 模型噪声维度匹配、通道数为 16 的隐空间表征;mask 序列则通过变形与采样技术,编码为时空维度统一、通道数达 64 的特征向量,实现不同模态数据的规范化表达。
最终的特征融合步骤,VACE 将 Frame 序列与 mask 序列的隐空间特征深度整合,并通过可训练参数模块,精准映射为适配 DiT 模型的 token 序列,成功搭建起多模态输入与 Transformer 架构之间的高效信息桥梁。
-
无缝的任务组合能力
统一模型的一大优势是天然支持自由组合各种基础功能,无需为每种独特功能单独训练新模型。典型组合场景包括:- 结合图像参考与主体重塑,实现视频物体替换。
- 结合运动控制与帧参考,控制静态图像的姿态。
- 结合图像参考、帧参考、背景扩展与时长扩展,将静态风景图转化为横版视频,并可添加参考图像中的元素。

上面给大家展示了模型的能力, 效果到底如何呢?下面手把手带大家在魔搭社区部署和搭建,我们感受一下把。
2.模型部署
模型社区启动资源
登录魔搭社区https://modelscope.cn/
搜索模型 通义万相2.1-VACE-1.3B
我们点击右上角nodebook快速开发- 使用魔搭平台提供的免费实例
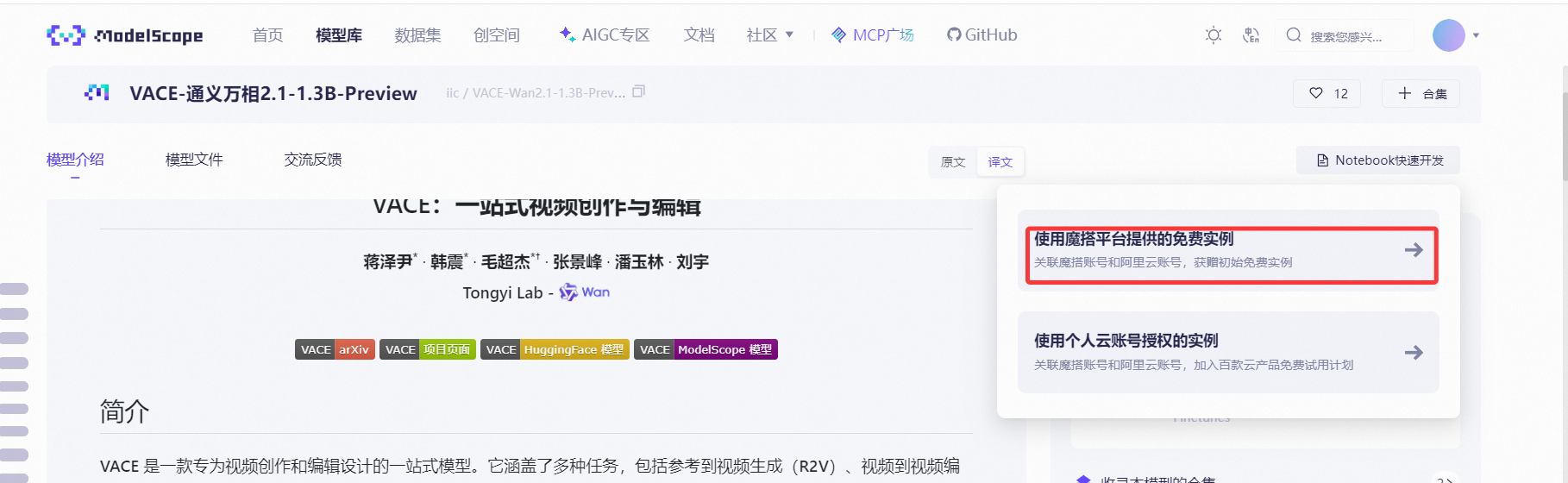
这里我们选择PAI-DSW,选择GPU环境,点击启动按钮等待服务器分配资源
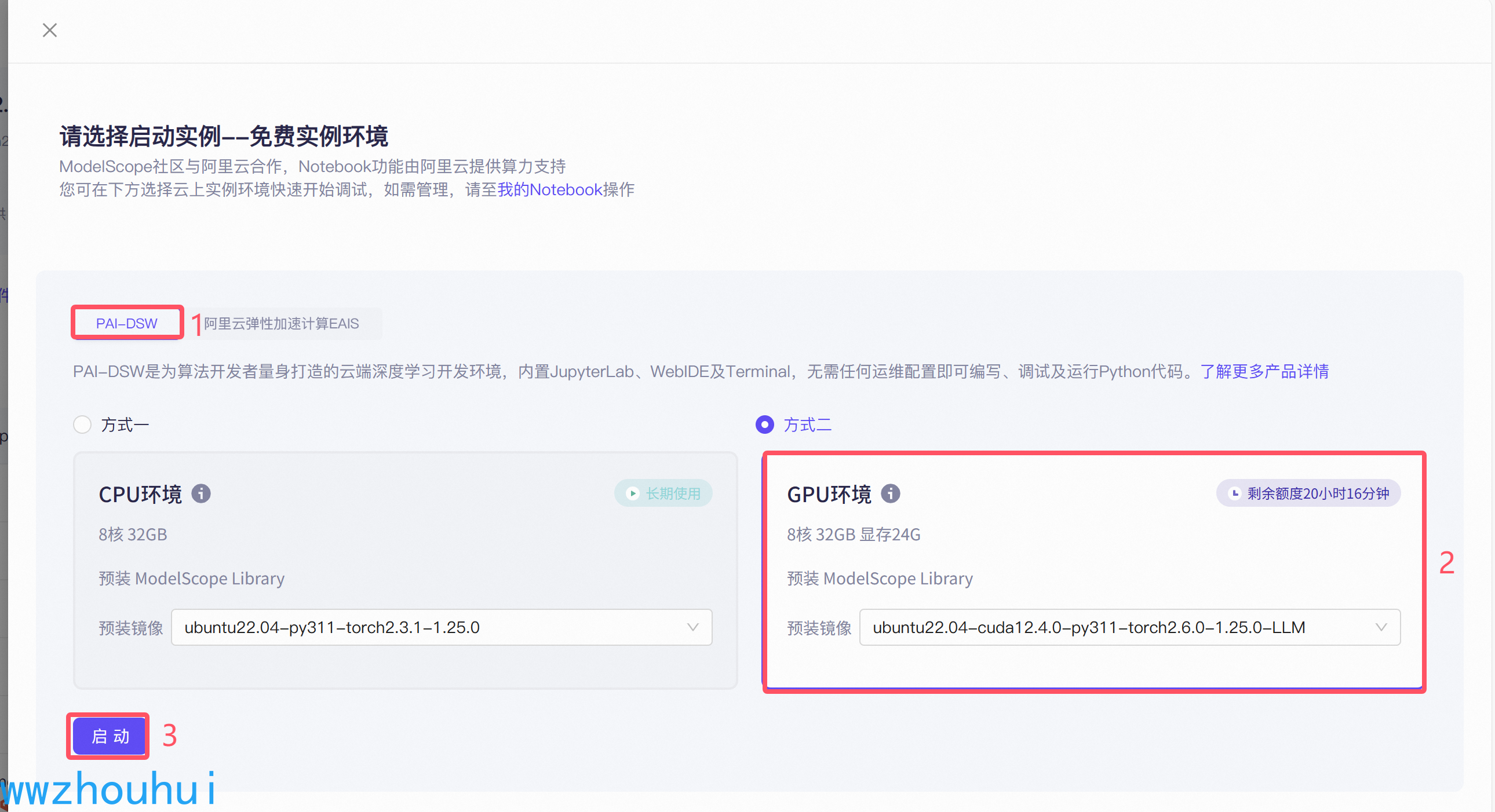
启动按钮点击后,我们稍等几分钟
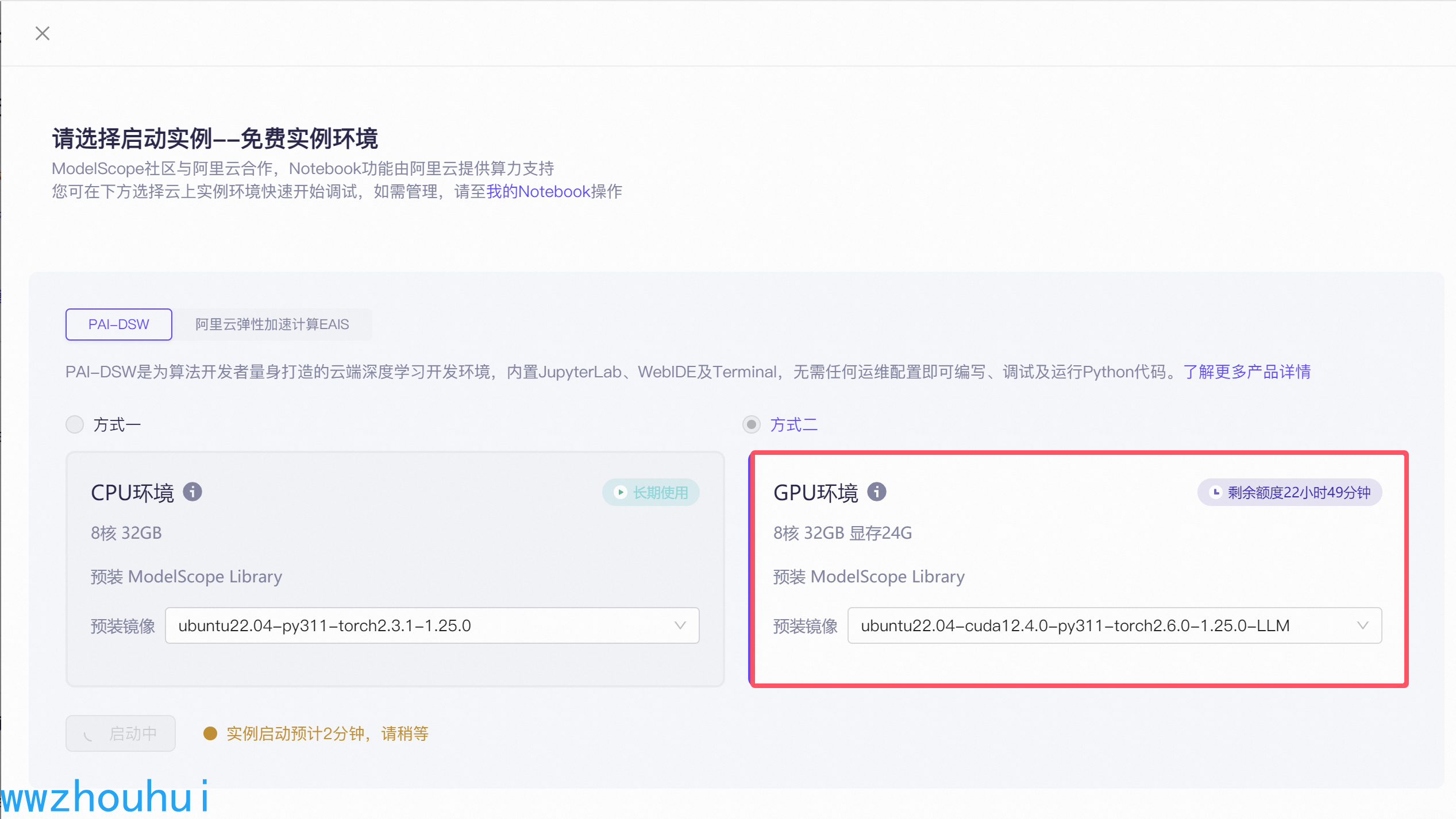
启动完成后我们点击查看nodebook进入调试界面
模型下载
我们进入nodebook调试界面看到下面的界面
接下来我们需要把模型权重下载下来。
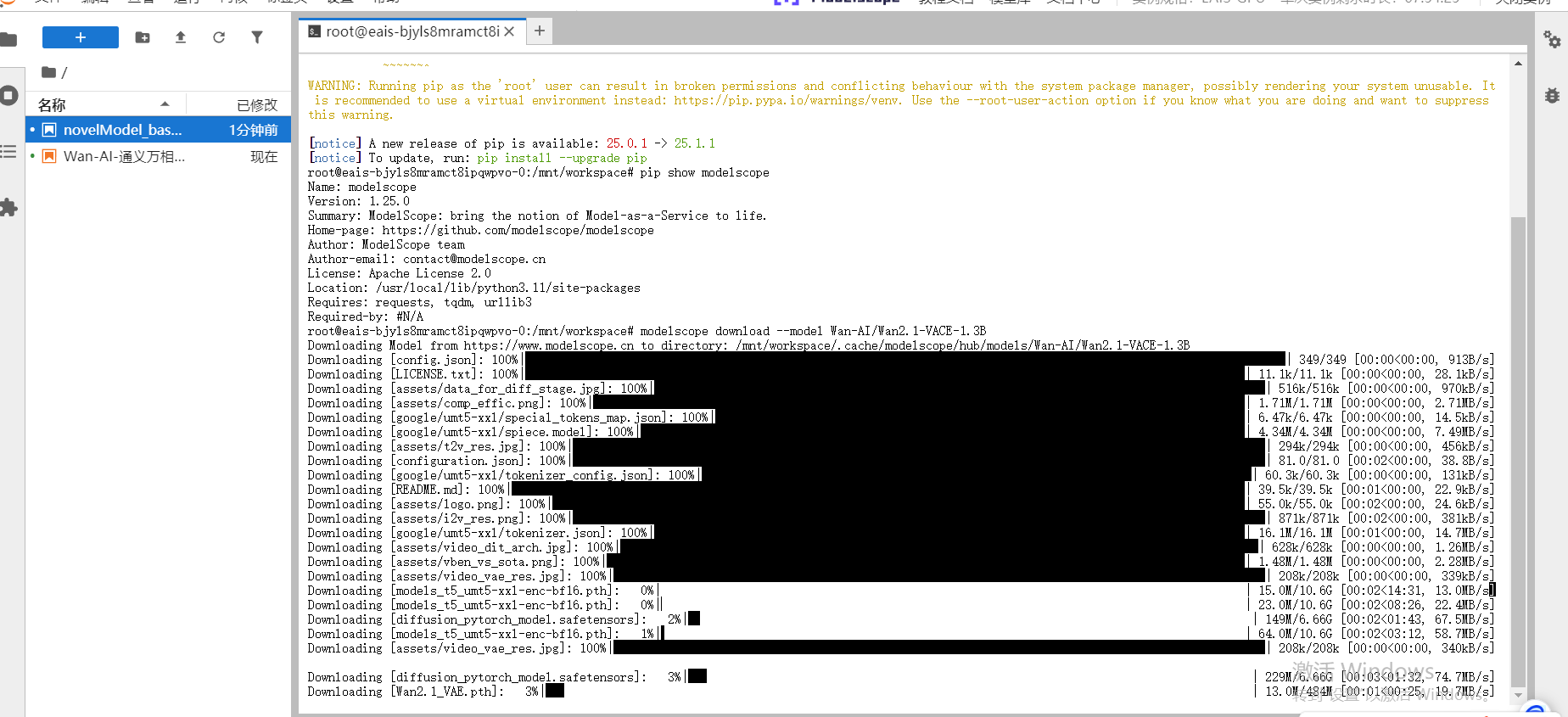
我们打开一个终端命令
在shell窗口中,我们输入下面命令下载模型权重
pip install modelscope
modelscope download --model Wan-AI/Wan2.1-VACE-1.3B --local_dir /mnt/workspace/Wan2.1-VACE-1.3B
模型推理
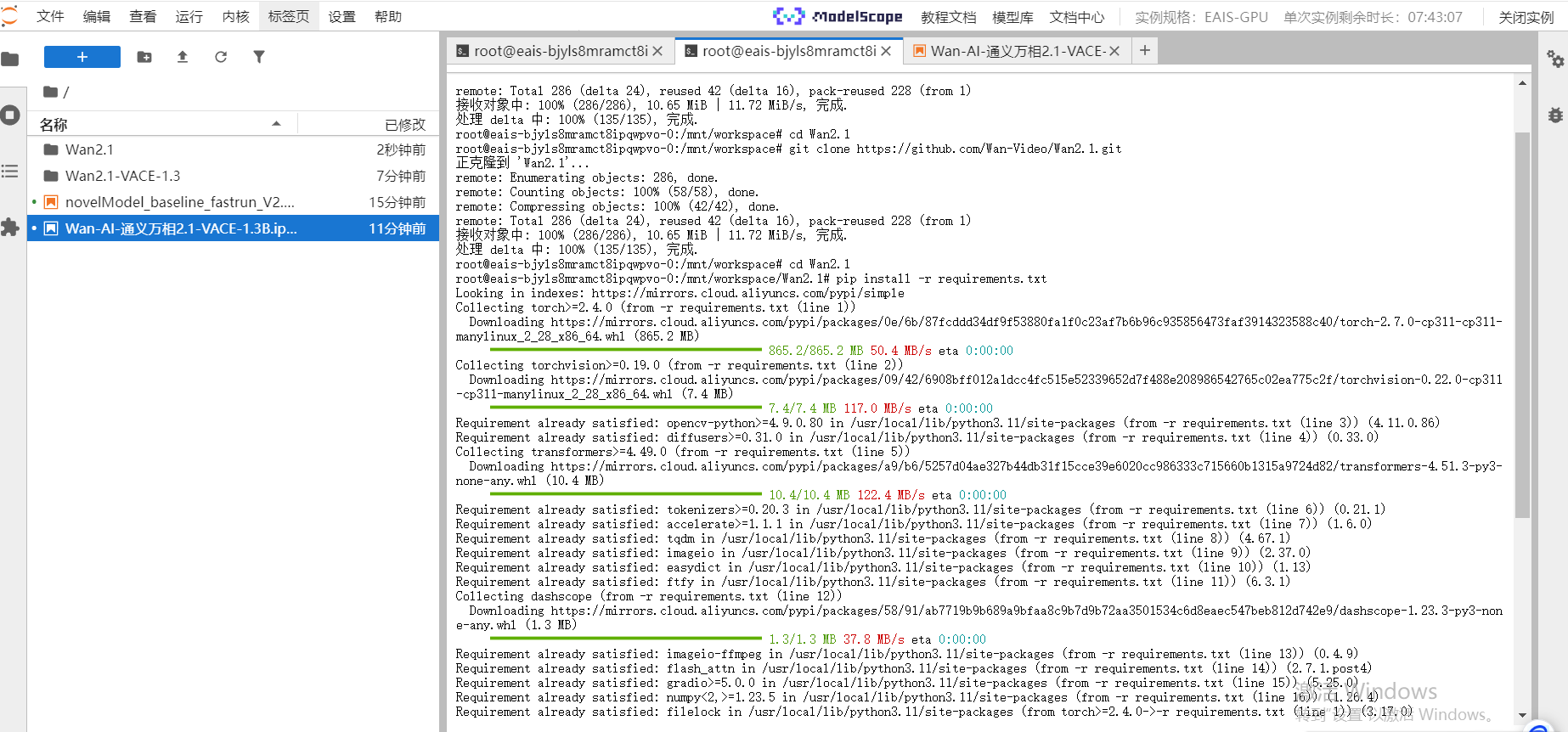
接下来我们在github上下载模型推理代码,我们在shell窗口输入如下命令
git clone https://ghfast.top/https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1

接下来我们安装一下模型推理依赖
pip install -r requirements.txt
pip install torch==2.5.1 torchvision==0.20.1 --index-url https://download.pytorch.org/whl/cu124
看到上面的画面我们就完成推理代码python依赖包的安装。
检查一下torch
pip show torch
cli inference
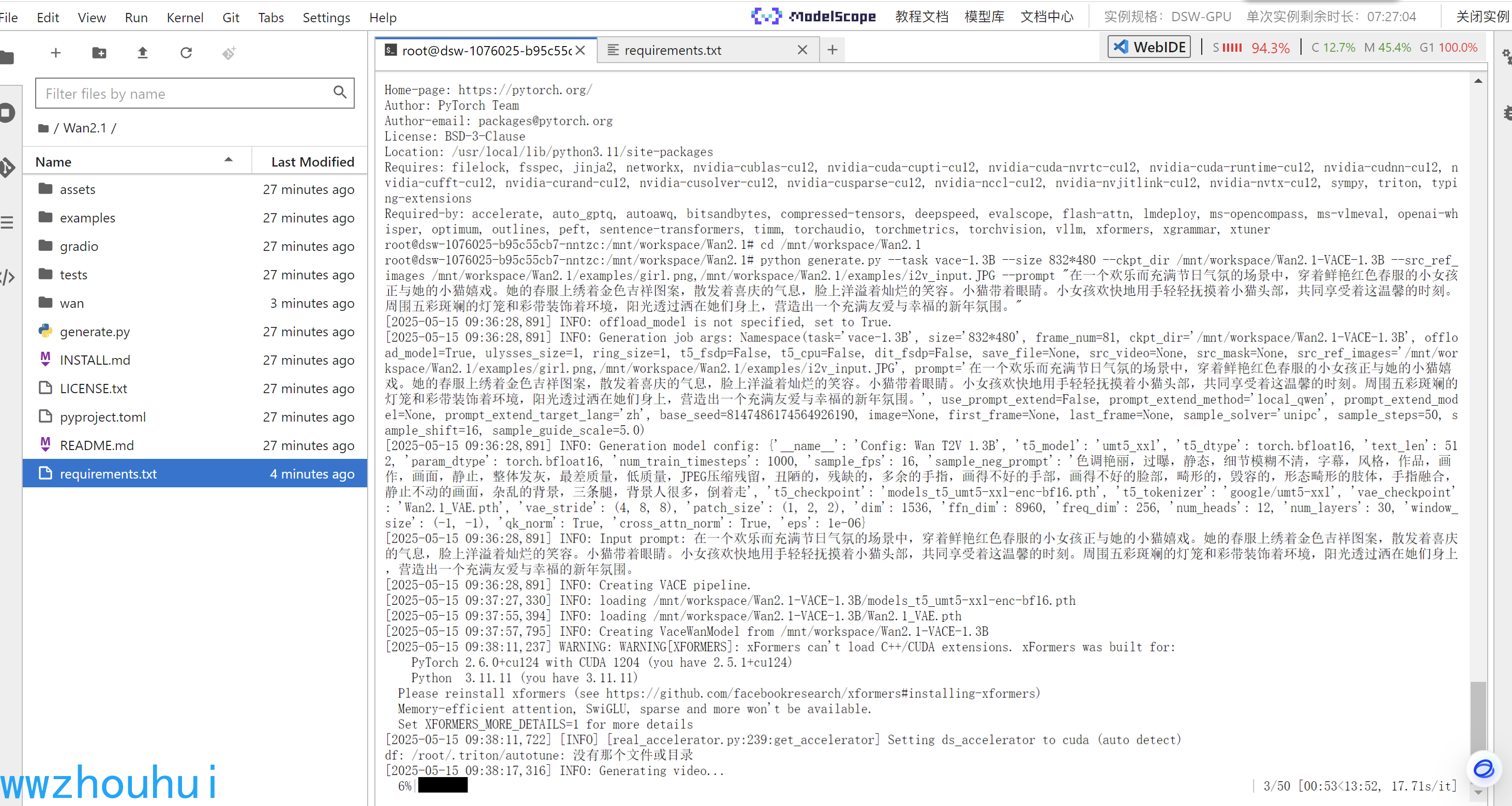
接下来来我们使用cli 命令行测试验证一下模型是否能够推理成功
cd /mnt/workspace/Wan2.1
python generate.py --task vace-1.3B --size 832*480 --ckpt_dir /mnt/workspace/Wan2.1-VACE-1.3B --src_ref_images /mnt/workspace/Wan2.1/examples/girl.png,/mnt/workspace/Wan2.1/examples/i2v_input.JPG --prompt "在一个欢乐而充满节日气氛的场景中,穿着鲜艳红色春服的小女孩正与她的小猫嬉戏。她的春服上绣着金色吉祥图案,散发着喜庆的气息,脸上洋溢着灿烂的笑容。小猫带着眼睛。小女孩欢快地用手轻轻抚摸着小猫头部,共同享受着这温馨的时刻。周围五彩斑斓的灯笼和彩带装饰着环境,阳光透过洒在她们身上,营造出一个充满友爱与幸福的新年氛围。"
程序运行加载模型,第一次运行会比较慢一点。
推理结束
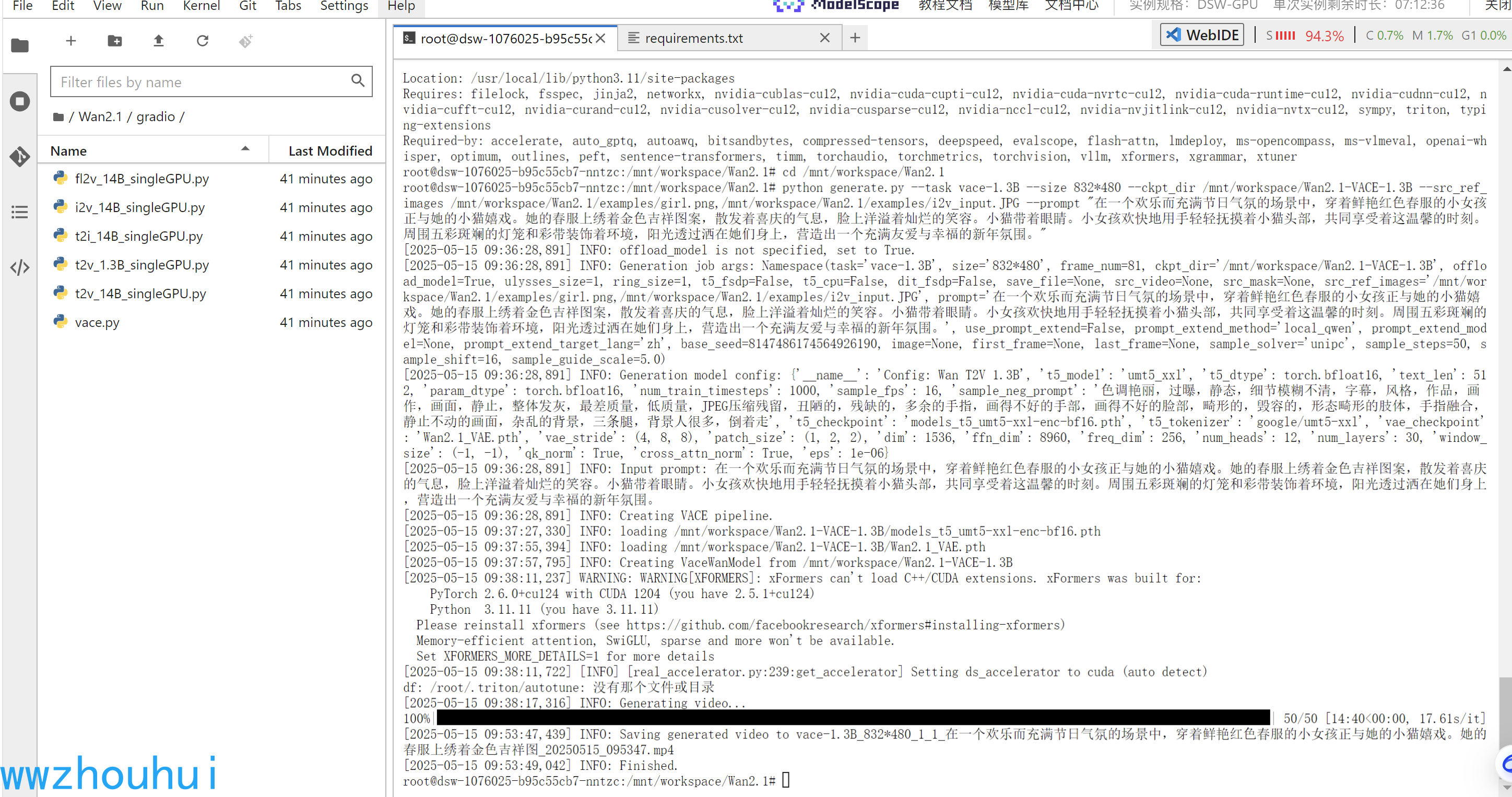
完成推理后我们看一下视频生成的效果

手有点脱离身体,不过确实把小女孩和猫合成在一个视频里面,哈哈。
gradio inference
接下来我们使用gradio web页面的方式实现模型推理
cd /mnt/workspace/Wan2.1
python gradio/vace.py --ckpt_dir /mnt/workspace/Wan2.1-VACE-1.3B
页面启动完成
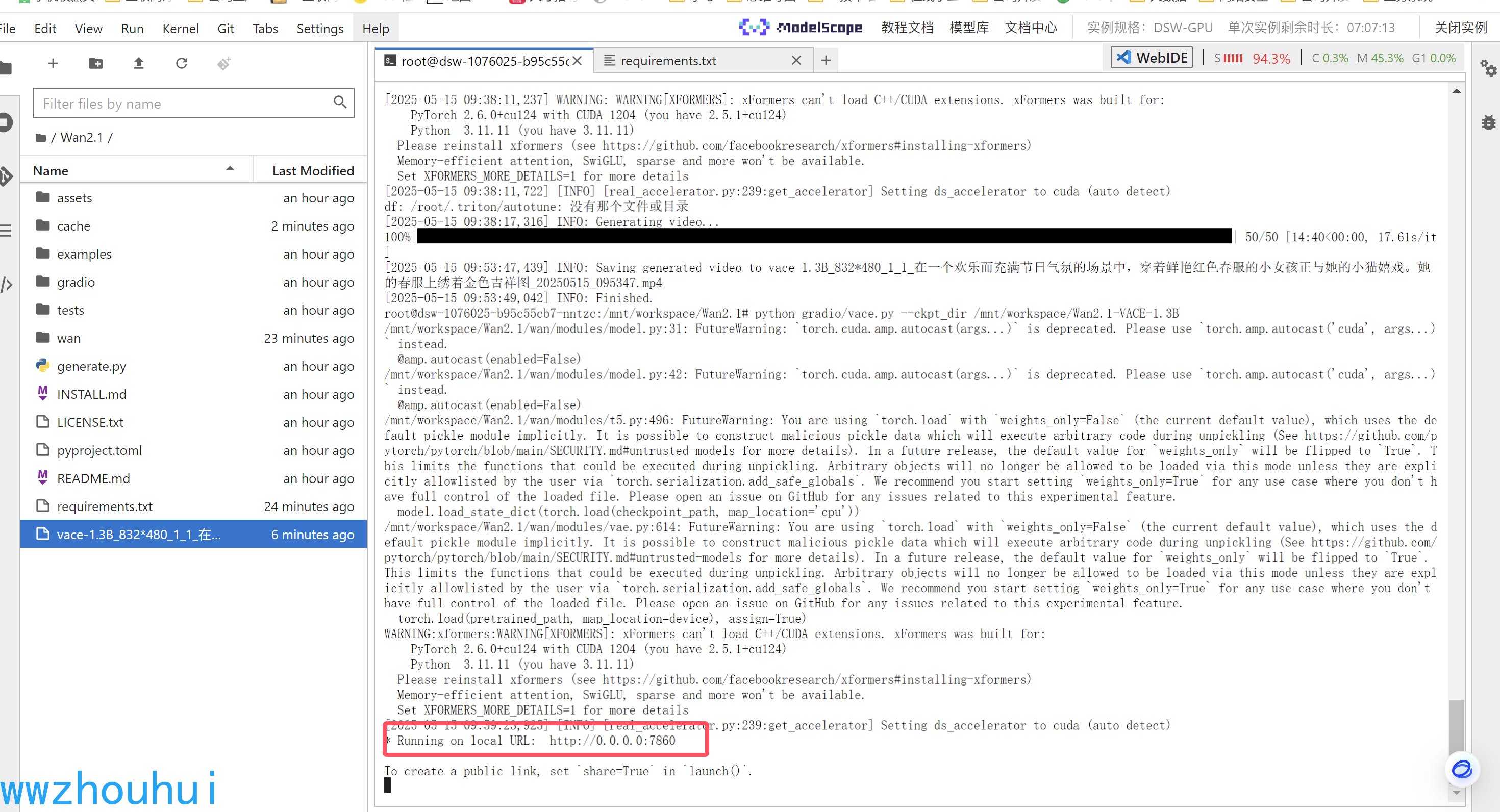
页面打开(我们借用官方的提供的gradio,页面有点丑)
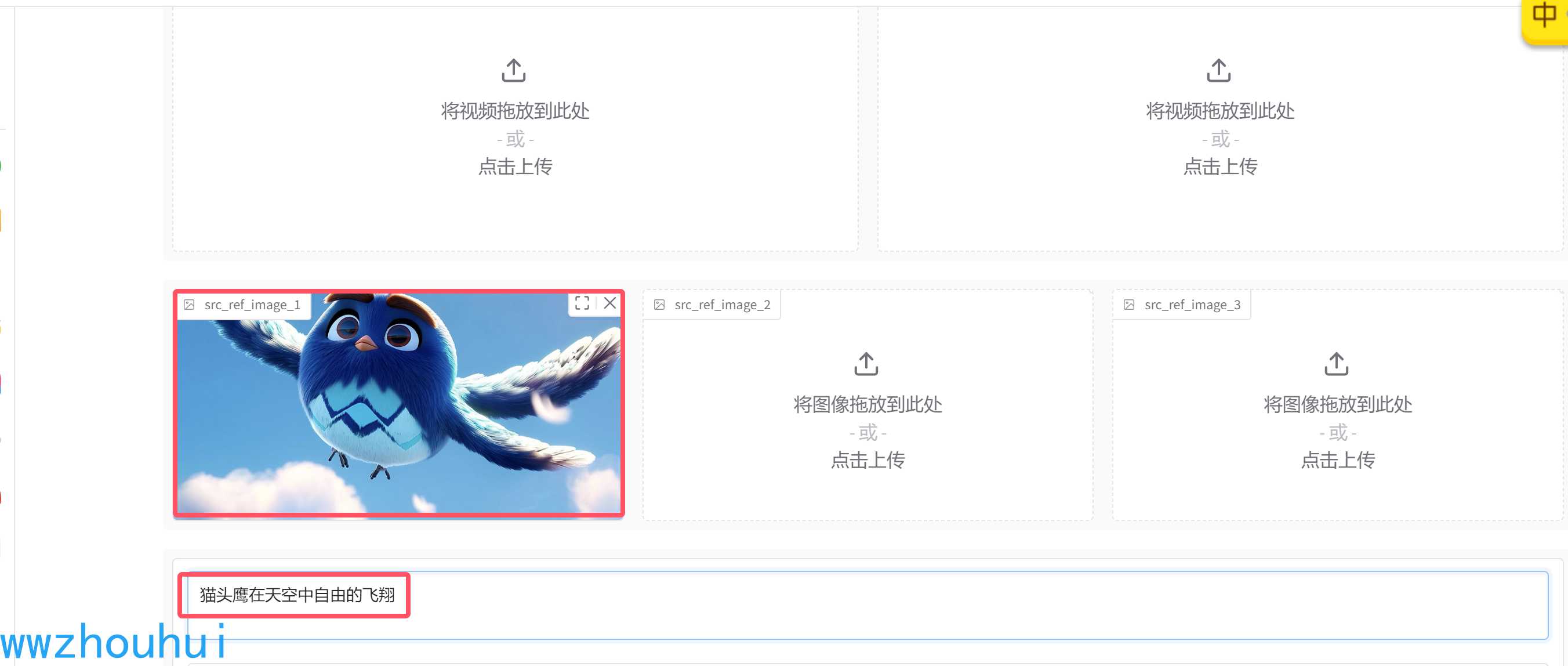
先测试一个简单,上传一个猫头鹰飞翔的图片 ,图片的长设置832 宽度设置480
猫头鹰在天空中自由的飞翔
生成的效果
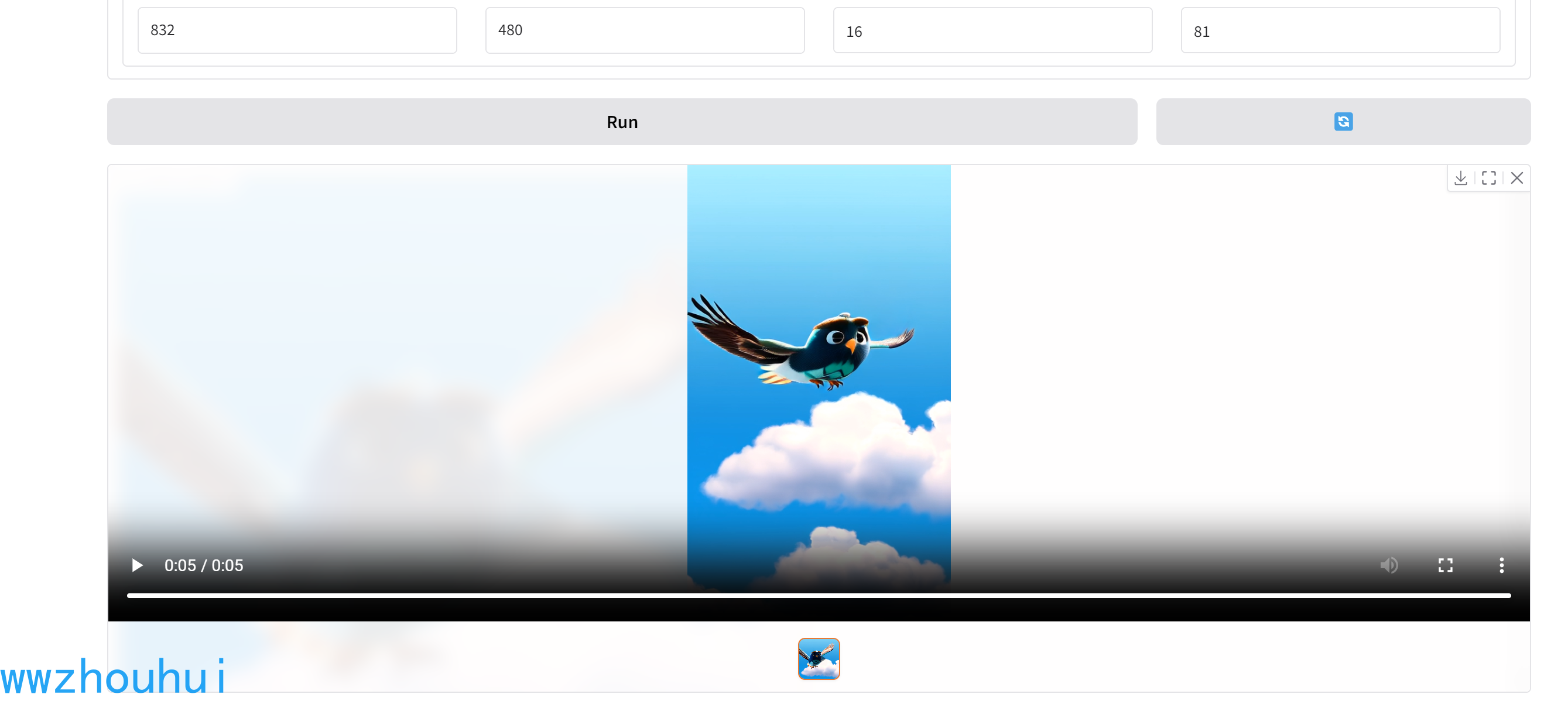
以上我们用2种方式实现了基于Wan2.1-VACE模型的推理。从提供的DEMO和模型的代码里面来看有不少好玩的东西。由于我这里用了魔搭社区免费GPU算力,实现的推理效果可能和官方宣传有点差异。但是我测试下来总体还可以,由于时间关系也没有做详细的测试。
3.总结:
今天主要带大家了解了阿里巴巴于 2025 年 5 月 14 日开源的 AI 视频生成与编辑模型 —— 通义万相 Wan2.1-VACE,并详细介绍了其部署和推理过程。该模型具有全面可控的生成能力、强大的局部与全局编辑能力、多形态信息输入、统一的模型架构以及无缝的任务组合能力等亮点,是业界功能最全面的视频生成与编辑工具。由于时间关系,本次测试未进行详细的对比和评估。不过,从模型的功能和提供的 DEMO 来看,通义万相 Wan2.1-VACE 具有很大的应用潜力,能够为视频生成和编辑领域带来新的可能性。感兴趣的小伙伴可以按照本文步骤去尝试,探索该模型更多的应用场景。今天的分享就到这里结束了,我们下一篇文章见。
#WanVACE