兼顾长、短视频任务的无人机具身理解!AirVista-II:面向动态场景语义理解的无人机具身智能体系统

- 作者:Fei Lin 1 ^{1} 1, Yonglin Tian 2 ^{2} 2, Tengchao Zhang 1 ^{1} 1, Jun Huang 1 ^{1} 1, Sangtian Guan 1 ^{1} 1, and Fei-Yue Wang 2 , 1 ^{2,1} 2,1
- 单位: 1 ^{1} 1澳门科技大学创新工程学院工程科学系, 2 ^{2} 2中科院自动化研究所复杂系统管理与控制国家重点实验室
- 论文标题:AirVista-II: An Agentic System for Embodied UAVs Toward Dynamic Scene Semantic Understanding
- 论文链接:https://arxiv.org/pdf/2504.09583
主要贡献
- 提出AirVista-II系统:这是一个端到端的代理系统,用于使无人机(UAV)从被动的数据采集平台向主动的语义交互范式转变,实现了无人机在动态场景中的通用语义理解和推理。
- 设计自适应关键帧提取策略:针对长视频场景,提出了一种结合运动感知采样、聚类分析和模型引导选择的自适应关键帧提取策略。该策略能够有效地捕捉语义显著的帧,增强无人机对复杂动态场景的理解能力。
- 在多个公共航拍视频数据集上验证:在零样本(zero-shot)设置下,展示了系统在多样化无人机动态场景中的高准确性和描述质量,证明了其在实际应用中的潜力。
研究背景
- 无人机在动态环境中的重要性:
- 无人机在物流运输、灾难响应等动态环境中扮演着越来越重要的角色。
- 然而,目前的任务通常依赖于人类操作员监控航拍视频并做出决策,这种人机协作模式在效率和适应性方面存在显著限制。
- 语义理解任务的需求:
- 为了实现更高效的自主操作,无人机需要具备语义理解能力,不仅作为数据采集平台,还要能够进行环境的语义建模和自然语言交互,从而根据感知信息生成对人类操作指令的高级语义响应。
- 现有方法的局限性:
- 近年来,以大型语言模型(LLM)为代表的基础模型(FM)在具身智能领域展现了强大的自主性和领域适应性。
- 然而,现有方法通常缺乏显式的任务规划机制,导致响应可控性不稳定。此外,由于缺乏外部工具调用能力和协调多模块框架,在处理结构复杂和开放性任务时泛化能力有限。
研究方法
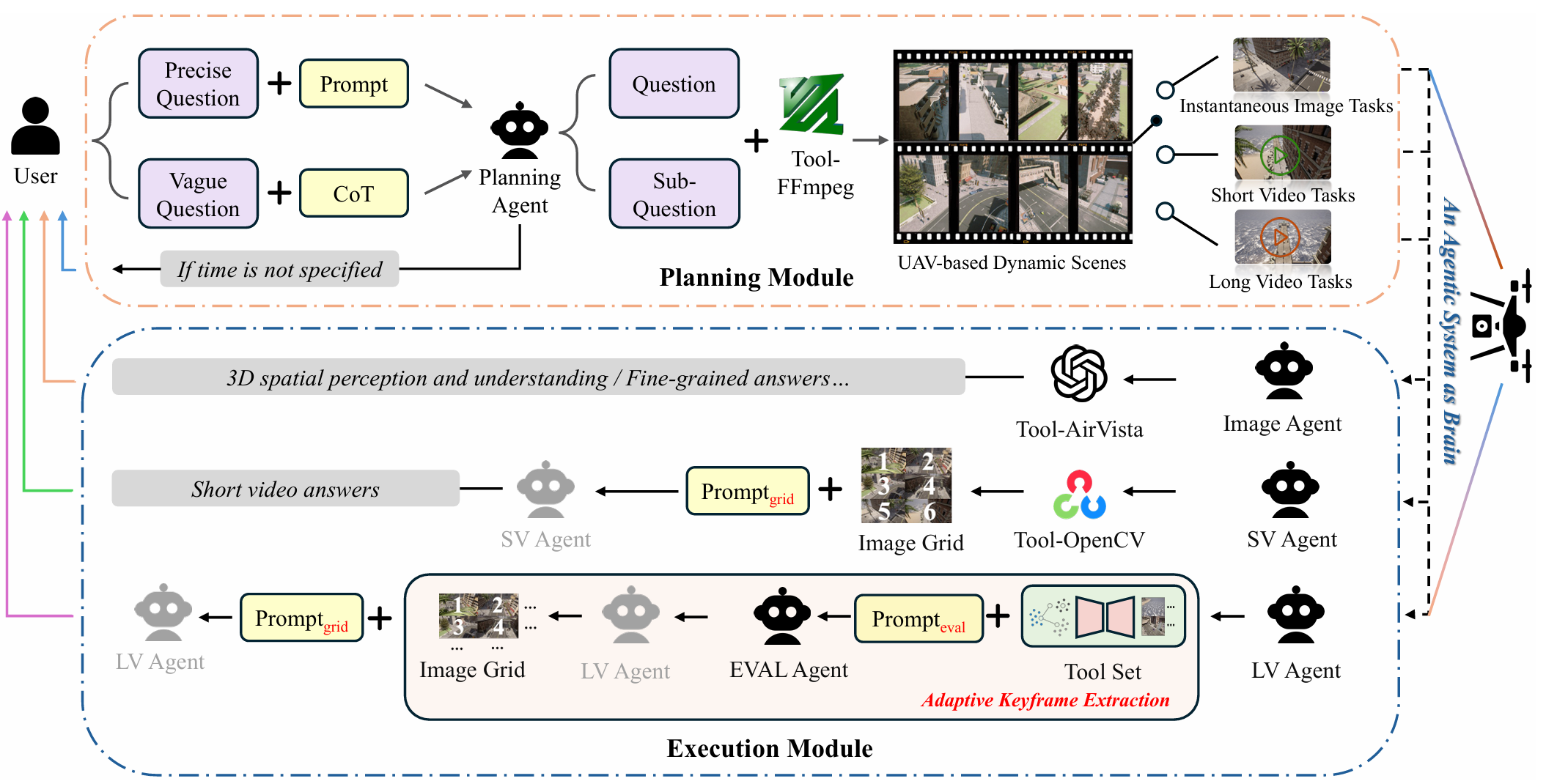
系统架构
AirVista-II系统由规划模块和执行模块组成。根据输入场景的时间长度,将动态场景分为三种类型:即时场景(单帧图像)、短视频(小于60秒)和长视频(大于等于60秒),分别对应不同的任务形式和执行策略。
规划模块
- 核心功能:基于LLaVA或GPT-4o的规划代理,将自然语言指令转化为结构化任务,并分派给下游执行代理。
- 处理流程:
- 如果查询缺乏明确的时间信息,则通过交互式细化模块更新查询。
- 对于语义模糊的查询,应用链式思考(CoT)模板将其分解为更具体的子问题。
- 根据提取的时间信息,使用FFmpeg工具从输入视频中检索图像帧或视频片段。
- 根据持续时间确定数据的模态标签(图像、短视频或长视频)。
执行模块
即时图像任务
- 处理方式:图像代理接收图像和用户查询,并调用AirVista工具生成答案。AirVista是一个专门针对无人机的多模态问答模型,能够进行细粒度的语义理解和3D空间推理。
短视频任务
- 关键帧提取:短视频代理首先使用OpenCV从短视频中提取6个均匀间隔的关键帧,形成一个3×2的时间网格图像。
- 推理过程:在网格提示的引导下,代理对网格和查询进行自我推理以产生答案。这种策略显著减少了计算开销,同时保留了时间上下文。
长视频任务
- 自适应关键帧提取策略:
- 运动感知采样:计算采样步长 s = ⌊ f ⋅ λ v ⌋ s = \left\lfloor \frac{f \cdot \lambda}{v} \right\rfloor s=⌊vf⋅λ⌋,其中 f f f 是帧率, v v v 是无人机的平均速度, λ \lambda λ 是期望的语义分辨率。这确保了无人机在采样帧之间至少移动 λ \lambda λ 米,平衡了覆盖范围和效率。
- 聚类分析:使用CLIP ViT-B/16提取高维语义嵌入,对不同数量的聚类进行评估,选择最优聚类数量。
- 模型引导选择:从每个聚类中选择最早时间戳的帧形成最终关键帧集,构建近方形网格图像。
- 推理过程:在网格提示的引导下,代理对网格和查询进行推理以生成答案。
实验
短视视频场景实验
CapERA-QA任务

- 任务描述:基于CapERA数据集构建内容总结问答任务,随机选择一个人类标注的字幕作为参考答案,并手动构建相应的问题。
- 评估方法:采用基于GPT的语义评估方法,结果显示准确率为75.6%,平均得分为3.703。这表明系统能够准确捕捉大多数航拍视频中的主要事件和动态语义。
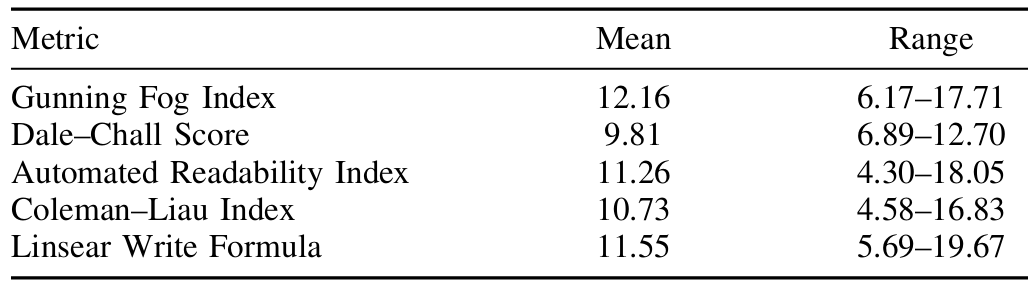
- 可读性评估:采用多种主流英语可读性指标(如Gunning Fog Index、Dale–Chall Readability Formula等),统计结果显示生成答案的可读性较好。

ERA-QA任务
- 任务描述:基于ERA数据集构建开放性问答任务,包含运动理解、空间关系、时间关系和自由形式问题四种类型。
- 评估方法:比较基于LLaVA-1.6-34B和GPT-4o的短视频代理的性能,结果显示LLaVA-1.6-34B的准确率为66.5%,平均得分为3.715;GPT-4o的准确率为53.0%,平均得分为3.140。
长视频场景实验
- 任务描述:基于SynDrone数据集构建长视频问答任务,手动设计开放性问题以评估系统在长时间、多事件动态场景中的综合问答能力。
- 聚类评估:通过视觉分析聚类评估结果,选择最优聚类数量。实验结果表明,自适应关键帧提取策略能够根据场景复杂性动态选择不同数量的关键帧。
- 性能对比:与固定帧采样策略(如均匀采样6帧)相比,自适应关键帧提取策略更有效地捕捉长视频的关键语义内容,使代理能够生成完整准确的响应。
结论与未来工作
- 结论:
- AirVista-II系统通过自适应关键帧提取方法,有效提高了无人机对复杂动态内容的感知和推理性能,增强了无人机在动态环境中的通用语义理解和推理能力。
- 该系统在多个公共航拍视频数据集上的实验结果表明,其在零样本设置下具有高准确性和描述质量,展示了良好的实际应用潜力。
- 未来工作:
- 优化流程:将专注于优化流程以减少计算开销,特别是在长视频处理中,进一步提高系统的实时性和效率。
- 增强鲁棒性:通过更多的实验和测试,增强整个系统在复杂环境下的鲁棒性,确保其在实际应用中的稳定性和可靠性。
