【day01】 Chroma 核心操作流程
目录
一、集合(Collection)增删改查操作
1.1 客户端类型简单对比
1.2 Chroma 本地客户端(local client)集合操作代码示例
二、Chroma Client-Server Mode
✅ 2.1、启动 Chroma Server 端
1. 安装(确保你安装了 chromadb 0.4+)
2. 运行 Server 服务端
✅ 2.2、客户端连接并使用
1. 连接服务端
2. 创建集合(和嵌入函数不能直接绑定)
3. 添加数据(你需要自己生成 embedding 向量)
4. 查询
总结区别:Client-Server 模式 vs 本地模式
✅ 推荐实践
三、Chroma Client-Server 模式使用 Demo流程
✅3.1 Server 端启动服务(只需要运行一次)
✅ 3.2 Client 端 Python 脚本
✅ 3.3 执行流程总结
✅ 可选:扩展用法
一、集合(Collection)增删改查操作
▲集合是 Chroma 中管理数据的基本单元,类似关系数据库的表;
▲client = chromadb.PersistentClient(path="D:/chroma_db_data") 这种方式属于 本地客户端(local client) 的使用方式。
1.1 客户端类型简单对比
| 客户端类型 | 是否本地 | 说明 |
|---|---|---|
chromadb.Client() | 否(默认使用内存) | 临时内存中的数据,不持久化,适合测试 |
chromadb.PersistentClient(path=...) | ✅ 本地持久化 | 本地存储数据,重启后数据依然保留 |
| 远程服务连接(如 HTTP API) | ❌ 远程服务 | 连接部署在服务器或云端的 Chroma 实例 |
1.2 Chroma 本地客户端(local client)集合操作代码示例
解释:
-
chromadb.PersistentClient是 Chroma 提供的一个持久化客户端类。 -
参数
path="D:/chroma_db_data"表示 Chroma 会将数据保存在本地的这个路径下。 -
所有的数据索引、向量存储、元数据等都会持久化在你指定的目录中,而不是运行在一个远程的服务或云端中。
import chromadb
from chromadb.utils import embedding_functions
import numpy as np# 创建客户端(本地持久化存储)
client = chromadb.PersistentClient(path="D:/chroma_db_data")# 嵌入函数
embedding_function = embedding_functions.DefaultEmbeddingFunction()# 创建集合,异常处理避免重复创建
try:collection = client.create_collection(name="my_collection",configuration={"embedding_function": embedding_function,"hnsw": {"space": "cosine","ef_search": 100,"ef_construction": 200,"max_neighbors": 16,"num_threads": 4}})
except Exception as e:print("集合已存在,获取已存在集合")collection = client.get_collection(name="my_collection")#------------------------------增加数据1----------------------------------
# 数据
texts = ["今天天气很好","明天可能下雨","股票行情波动较大"
]
ids = ["1", "2", "3"]# 生成向量,转成纯列表
vectors = [embedding_function(text)[0].tolist() for text in texts]# 添加数据
collection.add(documents=texts,ids=ids,embeddings=vectors
)#------------------------------增加数据2----------------------------------
# 方式1:自动生成向量(使用集合指定的嵌入模型)
collection.add(documents = ["RAG是一种检索增强生成技术", "向量数据库存储文档的嵌入表示", "在机器学习领域,智能体(Agent)通常指能够感知环境、做出决策并采取行动以实现特定目标的实体"],metadatas = [{"source": "RAG"}, {"source": "向量数据库"}, {"source": "Agent"}],ids = ["id1", "id2", "id3"]
)#------------------------------增加数据3----------------------------------
# 方式2:手动传入预计算向量
# collection.add(
# embeddings = [[0.1, 0.2, ...], [0.3, 0.4, ...]],
# documents = ["文本1", "文本2"],
# ids = ["id3", "id4"]
# )print("数据插入完成")#------------------------------查询数据1----------------------------------
# 查询示例
query_text = "天气预报"
query_vector = embedding_function(query_text)[0].tolist()results = collection.query(query_embeddings=[query_vector],n_results=3
)#------------------------------查询数据2----------------------------------
#文本查询(自动向量化):
results2 = collection.query(query_texts = ["RAG是什么?"],n_results = 3,# where = {"source": "RAG"}, # 按元数据过滤# where_document = {"$contains": "检索增强生成"} # 按文档内容过滤
)#------------------------------更新数据1----------------------------------
#更新集合中的数据:
collection.update(ids=["id1"], documents=["RAG是一种检索增强生成技术,在智能客服系统中大量使用"])results3 = collection.query(query_texts = ["RAG是什么?"],n_results = 3,
)#------------------------------删除数据----------------------------------
#删除集合中的数据:
collection.delete(ids=["id3"])
results4 = collection.query(query_texts = ["机器学习领域Agent能干嘛?"],n_results = 3,
)#------------------------------查询集合----------------------------------
collection = client.get_collection(name="my_collection")
print("✅查询集合:\n",collection,'\n')
print("✅查看前10条集合数据:\n",collection.peek(),'\n')#查看集合中的前几条数据(默认最多 10 条)。
print("✅查看所有集合数据:\n",collection.get(),'\n')#查看所有数据(超过 10 条)
#limit:最多返回多少条记录(上限);默认值是 10,最大值取决于系统资源
#offset:从第几条数据开始获取(偏移量);0 表示从头开始,10 表示跳过前 10 条
print("✅查看带分页控制集合数据:\n",collection.get(limit=11, offset=4),'\n')
print("✅集合中总共有多少条数据:\n",collection.count(),'\n')print("✅查询结果:\n", results,'\n')
print("✅查询结果2:\n",results2,'\n')
print("✅查询结果3:\n",results3,'\n')
print("✅查询结果4:\n",results4,'\n')二、Chroma Client-Server Mode
Chroma 有 Client-Server 模式(分布式/远程访问),分为 Server 端运行服务 和 Client 端连接服务 两部分。下面是完整的使用方法(✅适用于你本地启动服务并连接):
✅ 2.1、启动 Chroma Server 端
1. 安装(确保你安装了 chromadb 0.4+)
pip install chromadb
2. 运行 Server 服务端
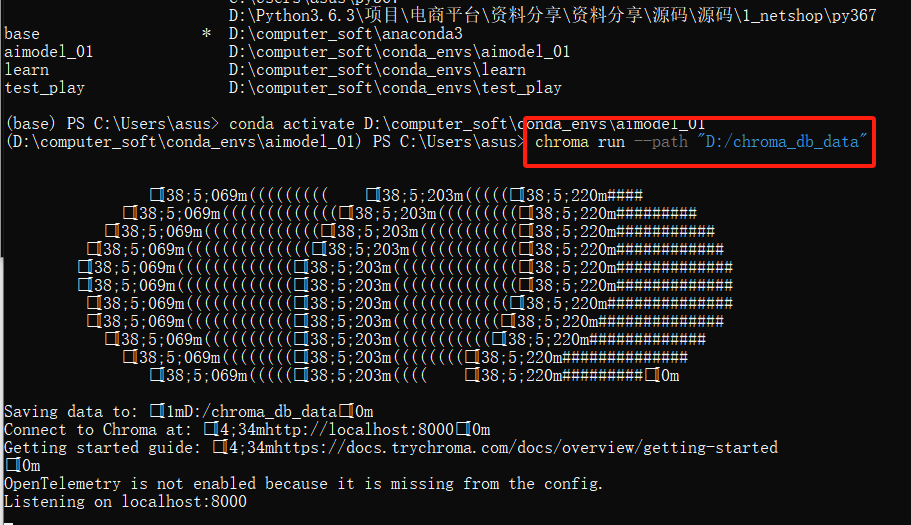
使用 CLI 启动服务端,并指定数据库存储路径:
chroma run --path "/your/path/to/chroma_data"
例如,上面代码存储位置是D:/chroma_db_data:
chroma run --path "D:/chroma_db_data"
默认会启动在 localhost:8000
成功启动后会显示日志:
[INFO] Starting Chroma server on http://localhost:8000
✅ 2.2、客户端连接并使用
你可以在另一个脚本或另一个终端里,作为“客户端”来访问这个 Server:
1. 连接服务端
import chromadb# 用 HttpClient 连接远程(或本地)服务端
client = chromadb.HttpClient(host='localhost', port=8000)
2. 创建集合(和嵌入函数不能直接绑定)
注意:在 Server 模式中,不能直接传嵌入函数!嵌入必须你自己提前生成好再传进去。
# 创建或获取集合
try:
collection = client.create_collection(name="my_collection")
except:
collection = client.get_collection(name="my_collection")
3. 添加数据(你需要自己生成 embedding 向量)
# 示例嵌入(假设你用 OpenAI 或 SentenceTransformer 生成)
import numpy as nptexts = ["今天天气很好", "明天可能下雨", "股票行情波动较大"]
ids = ["1", "2", "3"]# 假设你已经有嵌入函数了
from chromadb.utils import embedding_functions
embedding_func = embedding_functions.DefaultEmbeddingFunction()
embeddings = [embedding_func(text).tolist() for text in texts]# 添加数据
collection.add(documents=texts, ids=ids, embeddings=embeddings)
4. 查询
query_text = "天气预报"
query_embedding = embedding_func(query_text).tolist()results = collection.query(query_embeddings=[query_embedding], n_results=3)
print(results)
总结区别:Client-Server 模式 vs 本地模式
| 模式 | 特点 |
|---|---|
chromadb.PersistentClient(path=...) | 本地嵌入式数据库,运行在 Python 内部进程,单机使用 |
chromadb.HttpClient(host=..., port=...) | 客户端访问外部 Server,适合分布式、多用户环境 |
✅ 推荐实践
-
启动 Server(长期后台服务)
-
Client 脚本中只需连接,不要传嵌入函数
-
所有 embedding 向量由你自己负责生成并传入
三、Chroma Client-Server 模式使用 Demo流程
✅3.1 Server 端启动服务(只需要运行一次)
你可以在终端或命令行中运行以下命令:
chroma run --path "D:/chroma_db_data"
-
会启动在
http://localhost:8000 -
数据将保存在
D:/chroma_db_data中 -
不用写 Python 脚本,直接启动服务即可
✅ 3.2 Client 端 Python 脚本
这是你平时使用的代码逻辑:连接服务、生成向量、插入数据、查询。
import chromadb
from chromadb.utils import embedding_functions# 连接远程 Chroma Server
client = chromadb.HttpClient(host='localhost', port=8000)# 嵌入函数(在 Client 端自己生成向量)
embedding_func = embedding_functions.DefaultEmbeddingFunction()# 获取或创建集合(不能传 embedding_function)
try:collection = client.create_collection(name="my_collection")
except:collection = client.get_collection(name="my_collection")# 示例数据
texts = ["今天天气很好", "明天可能下雨", "股票行情波动较大"]
ids = ["1", "2", "3"]# 生成向量(注意 tolist())
embeddings = [embedding_func(text).tolist() for text in texts]# 插入数据
collection.add(documents=texts, ids=ids, embeddings=embeddings)print("✅ 插入完成")# 查询
query = "天气预报"
query_embedding = embedding_func(query).tolist()results = collection.query(query_embeddings=[query_embedding], n_results=3)print("🔍 查询结果:")
for doc, score in zip(results['documents'][0], results['distances'][0]):print(f"文档: {doc}, 相似度: {1 - score:.4f}")
✅ 3.3 执行流程总结
| 步骤 | 操作 |
|---|---|
| 1. 启动服务端 | chroma run --path "D:/chroma_db_data" |
| 2. 运行客户端脚本 | 用上面 Python 脚本连接 localhost:8000 插入和查询数据 |
✅ 可选:扩展用法
你还可以用:
-
OpenAI Embedding:替换
embedding_func,使用更强大的模型 -
多用户共享数据库:部署服务在云服务器或局域网
-
持久化嵌入搜索:本地文件夹中保存
.parquet等数据结构