机器学习 day03
文章目录
- 前言
- 一、特征降维
- 1.特征选择
- 2.主成分分析(PCA)
- 二、KNN算法
- 三、模型的保存与加载
前言
通过今天的学习,我掌握了机器学习中的特征降维的概念以及用法,KNN算法的基本原理及用法,模型的保存和加载
一、特征降维
对于未经处理的原始数据,其中往往包括大量的特征,会导致计算量很大,我们希望通过降维,舍弃掉一些特征,或者将几个特征转换为一个特征
特征降维的方式主要包括:
- 特征选择:舍弃掉一些特征,从原始特征集中挑选出最相关的特征
- 主成分分析(PCA):通过数学计算,将几个特征转换为一个特征,达到降维的目的
1.特征选择
(1)低方差过滤特征选择
原理:如果计算某一个特征的数据得到的方差很小,说明这个特征的数据总体变化不大,包含的信息较少,可以舍弃
API用法:sklearn.feature_selection.VarianceThreshold(threshold=2.0)
- threshold参数用于指定低方差阈值,小于该阈值的特征将被过滤
data = pd.DataFrame([[10,1],[11,3],[11,1],[11,5],[11,9],[11,3],[11,2],[11,6]])
# 实例化转换器对象
transfer = VarianceThreshold(threshold=0.1)
# 特征选择
data_new = transfer.fit_transfrom(data)
print(data_new)
(2)相关系数特征选择
原理:根据计算两个变量的皮尔逊相关系数度量二者的相关性,若相关系数很小,则说明两个量之间没什么关联,可以据此舍弃一些与目标不相关的特征
皮尔逊相关系数的取值范围为:[-1,1],越接近1代表正相关性越强,反之代表负相关性越强,而接近0代表相关性很弱
通过以下公式:
ρ = Cos ( x , y ) D x ⋅ D y = E [ ( x − E x ) ( y − E y ) ] D x ⋅ D y = ∑ i = 1 n ( x − x ~ ) ( y − y ˉ ) / ( n − 1 ) ∑ i = 1 n ( x − x ˉ ) 2 / ( n − 1 ) ⋅ ∑ i = 1 n ( y − y ˉ ) 2 / ( n − 1 ) \rho=\frac{\operatorname{Cos}(x, y)}{\sqrt{D x} \cdot \sqrt{D y}}=\frac{E[(x_-E x)(y-E y)]}{\sqrt{D x} \cdot \sqrt{D y}}=\frac{\sum_{i=1}^{n}(x-\tilde{x})(y-\bar{y}) /(n-1)}{\sqrt{\sum_{i=1}^{n}(x-\bar{x})^{2} /(n-1)} \cdot \sqrt{\sum_{i=1}^{n}(y-\bar{y})^{2} /(n-1)}} ρ=Dx⋅DyCos(x,y)=Dx⋅DyE[(x−Ex)(y−Ey)]=∑i=1n(x−xˉ)2/(n−1)⋅∑i=1n(y−yˉ)2/(n−1)∑i=1n(x−x~)(y−yˉ)/(n−1)
计算得到余弦相似度,|ρ|<0.4为低度相关; 0.4<=|ρ|<0.7为显著相关; 0.7<=|ρ|<1为高度相关
API用法:scipy.stats.personr(x,y)
- x,y为需要比较的两个向量
- 返回值包括:statistic皮尔逊相关系数以及pvalue零假设,该值越小说明两个量越相关
from scipy.stats import pearsonr
x = [1,2,3]
y = [10,20,30]
res = pearsonr(x,y)
print(res.statistic)
print(res.pvalue)
2.主成分分析(PCA)
主成分分析的核心是在保留数据方差的前提下将原始数据降维到新的坐标空间中以减少数据维度
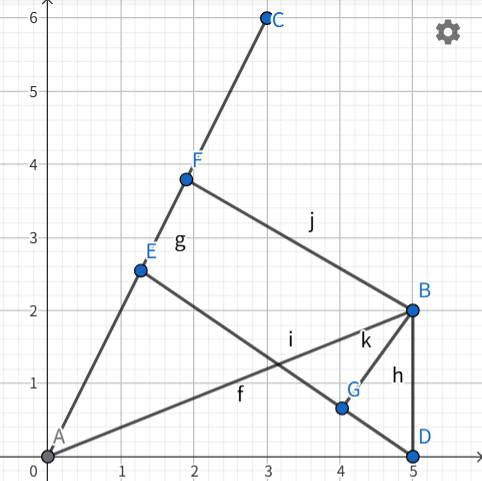
假设B点坐标为( x 0 x_0 x0, y 0 y_0 y0),根据上图的几何关系 x 0 x_0 x0投影到L的大小AE为 x 0 ∗ c o s α x_0*cos \alpha x0∗cosα,
y 0 y_0 y0投影到L的大小EF为 y 0 ∗ s i n α y_0*sin\alpha y0∗sinα
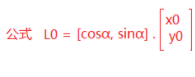
通过这个公式,我们可以将二维坐标点映射到一维的直线上(本质上是通过矩阵运算进行线性变换),达到降维的目的
这里投影到直线上的距离就是降维后保留的信息,而垂直于直线上的投影则是损失的信息,在进行PCA时,我们要使保留信息/原始信息=信息保留的比例较大
其次,我们根据主成分的方差等,确定最终保留的主成分个数, 方差大的要留下
API用法:sklearn.decomposition.PCA(n_components=None)
- n_components用于指定降维参数,如果是小数表示降维后的信息保留比,如果是整数表示降维至多少特征
from sklearn.decomposition import PCA
# 注意该列表中元素表示四维向量
data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]
# 实参为小数表示信息保留比,为整数时表示保留特征的个数
tool = PCA(n_components=2)
data = tool.fit_transform(data)
print(data)
tips:在机器学习库中,默认输入的数据中:行代表每一个数据样本,列代表数据样本的各个特征,降维指的是减少数据样本的特征数
二、KNN算法
K-近邻算法(K-Nearest Neighbors,简称KNN),根据K个邻居样本的类别来判断当前样本的类别;
该算法的核心是计算某个样本到相邻k个样本间的距离,再对得到的距离进行排序,最后得到样本的类别
KNN算法的原理简单易懂,但对于维度较高和数据链较大的样本效果不佳且效率低下
API用法:sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, algorithm=‘auto’)
- n_neighbors代表近邻的个数
- algorithm指找到近邻的方法,是数据结构中的算法,一般指定为“auto”
from sklearn.datasets import load_iris
from sklearn.model_selction import train_test_split
from sklearn.perprocessing import StandarScaler
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
# 加载数据
x,y = load_iris(return_X_y=True)
# 数据划分
x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.8,shuff=True,random_state=42)
# 特征工程
transfer = StandarScaler()
x_train = transfer.fit_transfrom(x_train)
x_test = transfer.transfrom(x_test)
# 创建模型
model = KNeughborsClassifier(n_neighbors=5)
# 训练模型
model.fit(x_train,t_train)
# 模型预测
y_pred = model.predict(x_test)
# 模型评估
score = np.sum(y_test==y_pred)/len(y_test)
print(score)
三、模型的保存与加载
在现实开发场景中,模型的训练和使用往往是分离的,因此我们希望训练完模型后可以保存到指定位置,再次使用时可以加载模型直接使用
API使用:
- 保存模型:joblib.dump(model, path)
- 加载模型:joblib.load(path)
if score > 0.9:joblib.dump(model,"./src/model/knn.pkl")joblib.dump(transfer,"./src/model/knn_transfer.pkl")print("保存成功!")
else:print("模型效果差,保存失败!")
THE END