Python----神经网络(《Searching for MobileNetV3》论文概括和MobileNetV3网络)
一、《Searching for MobileNetV3》

1.1、 基本信息
-
标题:Searching for MobileNetV3
-
作者:Andrew Howard、Mark Sandler等(Google AI 和 Google Brain 团队)
-
发表时间:2019年(arXiv版本1905.02244v3)
-
研究目标:设计适用于移动设备的高效神经网络模型,优化准确率与延迟的权衡,覆盖分类、检测、分割任务。
1.2、主要内容
核心方法:软硬结合的神经架构搜索
硬件感知的神经架构搜索(NAS): 你准确地指出了他们结合了平台感知的NAS和NetAdapt算法。这里的关键在于“硬件感知”。这意味着在搜索网络结构时,他们不仅考虑了模型的准确率,还将模型在目标硬件上的实际延迟纳入了优化目标。这与以往一些只关注理论计算量(如FLOPs)的NAS方法不同,更贴合实际应用需求。
NetAdapt算法的补充作用: NetAdapt算法在NAS找到的宏观结构基础上,对每一层的滤波器数量进行微调,以在保持性能的前提下进一步降低延迟。这体现了自动搜索和精细调整相结合的思路。
改进的构建模块:效率与性能的融合
逆残差结构与轻量级注意力模块(Squeeze-and-Excite): MobileNetV3继承了MobileNetV2的逆残差结构,这种结构通过扩展中间层的通道数,允许更丰富的特征表达,同时利用深度可分离卷积保持计算效率。而Squeeze-and-Excite (SE) 模块的引入,则为网络增加了通道注意力机制,能够动态地调整不同通道特征的重要性,从而提升模型性能。
新型激活函数 h-swish: 你提到了h-swish是基于分段线性近似的Sigmoid函数。这个设计的关键在于它在保持swish非线性激活优势(有助于提升模型准确率)的同时,避免了Sigmoid函数在移动设备上计算开销较大以及不易量化的缺点。分段线性函数在计算上更高效,并且更适合进行模型量化,这对于在资源受限的移动设备上部署至关重要。
网络结构改进:针对效率的精细设计
重新设计初始层和末尾层: 论文中提到对网络的初始几层和最后几层进行了特别的设计。通常,网络的初始层负责提取低级特征,如果使用过多的冗余滤波器,会增加不必要的计算。末尾层通常用于最终的分类或特征输出,其设计会直接影响模型的延迟和精度。MobileNetV3通过实验分析,对这些关键层进行了优化,以减少冗余计算并优化特征生成过程中的延迟。你提到的将最后的平均池化层调整到更高维度的特征空间,并在其后使用1x1卷积来减少计算量,就是一个很巧妙的例子。
轻量分割解码器 LR-ASPP: 对于语义分割任务,MobileNetV3提出了轻量级的LR-ASPP解码器。传统的ASPP模块为了捕获多尺度上下文信息,通常包含多个并行的空洞卷积分支,计算量较大。LR-ASPP通过简化结构,例如使用一个全局平均池化分支和一个1x1卷积分支,显著降低了计算成本,同时尽可能地保持了分割精度。
模型版本:适应不同资源场景
MobileNetV3-Large 和 MobileNetV3-Small: 这两个不同尺寸的模型旨在满足不同资源和性能要求的应用场景。Large版本拥有更多的参数和计算量,适用于对精度要求更高的任务;而Small版本则更加轻量化,适用于资源受限但仍需一定性能的场景。这种设计思路使得MobileNetV3具有更广泛的适用性。
实验验证:多任务的性能提升
分类(ImageNet): 在ImageNet这个经典的图像分类数据集上的显著性能提升和延迟降低,直接证明了MobileNetV3在效率和准确率上的进步。
检测(COCO)和分割(Cityscapes): 在目标检测和语义分割任务上的表现,进一步验证了MobileNetV3作为特征提取器和轻量级分割模型的有效性。它不仅提升了速度,还在一定程度上保持甚至提升了精度,这对于实时性要求高的视觉任务至关重要。
1.3、影响与作用
技术贡献:
首次系统化结合自动搜索(NAS)与手工设计,为高效模型开发提供新范式。
提出h-swish激活函数和LR-ASPP解码器,成为后续轻量模型设计的重要参考。
工业价值:
显著降低移动端AI应用的延迟与能耗,支持实时任务(如拍照增强、AR)。
推动隐私保护(本地计算)与用户体验(低延迟、长续航)的平衡。
1.4、优点
高效性:在ImageNet、COCO、Cityscapes任务中均实现SOTA的准确率-延迟平衡。通过h-swish和结构优化,减少计算量(如V3-Large MAdds降低至219M)。
技术创新:结合NAS与手工改进,兼顾自动化与领域知识。LR-ASPP解码器在分割任务中高效且有效。
实验全面性:覆盖分类、检测、分割任务,提供多分辨率与量化结果(如FP32/INT8性能对比)。
1.5、 缺点
计算成本:NAS过程依赖大量计算资源,可能限制小团队复现或改进。
硬件泛化性:实验主要基于Google Pixel设备,对其他移动平台(如iOS或边缘芯片)的兼容性未充分验证。
可扩展性:部分改进(如h-swish)可能难以直接迁移到非卷积架构(如Transformer)。
细节缺失:对量化部署中的实际工程挑战(如精度损失、硬件适配)讨论较少。
论文地址:
[1905.02244] Searching for MobileNetV3
二、MobileNetV3
2.1、网络的背景
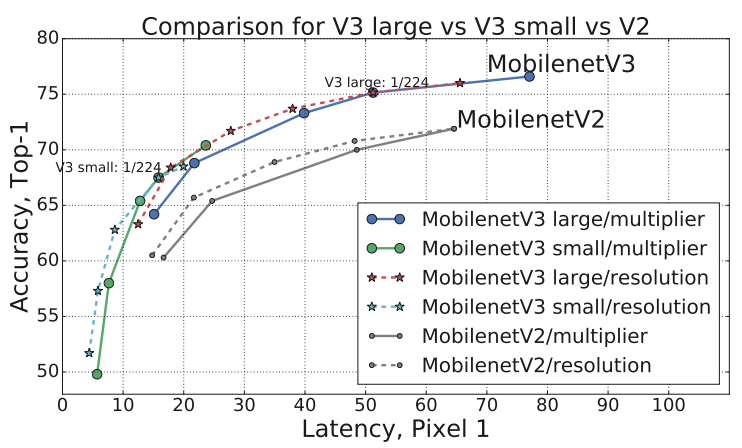
在相同延时下,MobileNetV3准确率更高。
MobileNetV3提出了large和small两个版本(区别在于网络结构不同),paper中讲 在MobileNetV3 Large在ImageNet分类任务上,较MobileNetV2,TOP1准确率提高 了大约3.2%,时间减少了20%。与具有同等延迟的MobileNetV2模型相比,Mobile NetV3 Small的准确率高6.6%。
2.2、更新Block
对Block的结构进行了更新,在其中加入了SE模块,即注意力机制,以及更新了激活 函数。
在MobileNetV2中,采用了倒残差结构,该结构如下图所示:
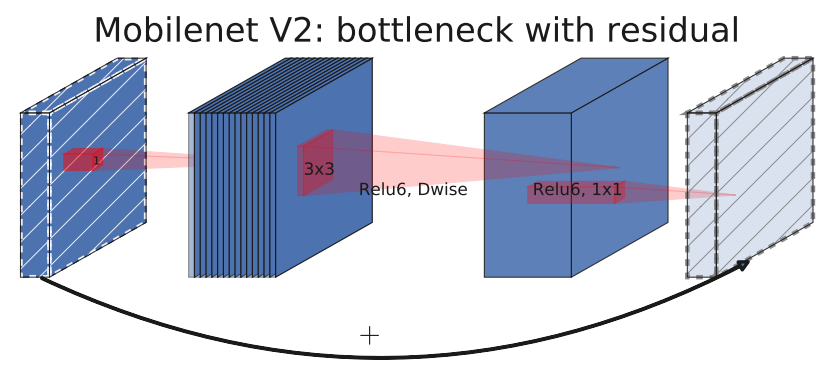
首先会通过一个1x1卷积层来进行升维处理,在卷积后会跟有BN和ReLU6激活函 数
紧接着是一个3x3大小DW卷积,卷积后面依旧会跟有BN和ReLU6激活函数
最后一个卷积层是1x1卷积,起到降维作用,注意卷积后只跟了BN结构,并没有 使用ReLU6激活函数。
当stride=1且输入特征矩阵=输入特征矩阵时,还有shortcut结构。
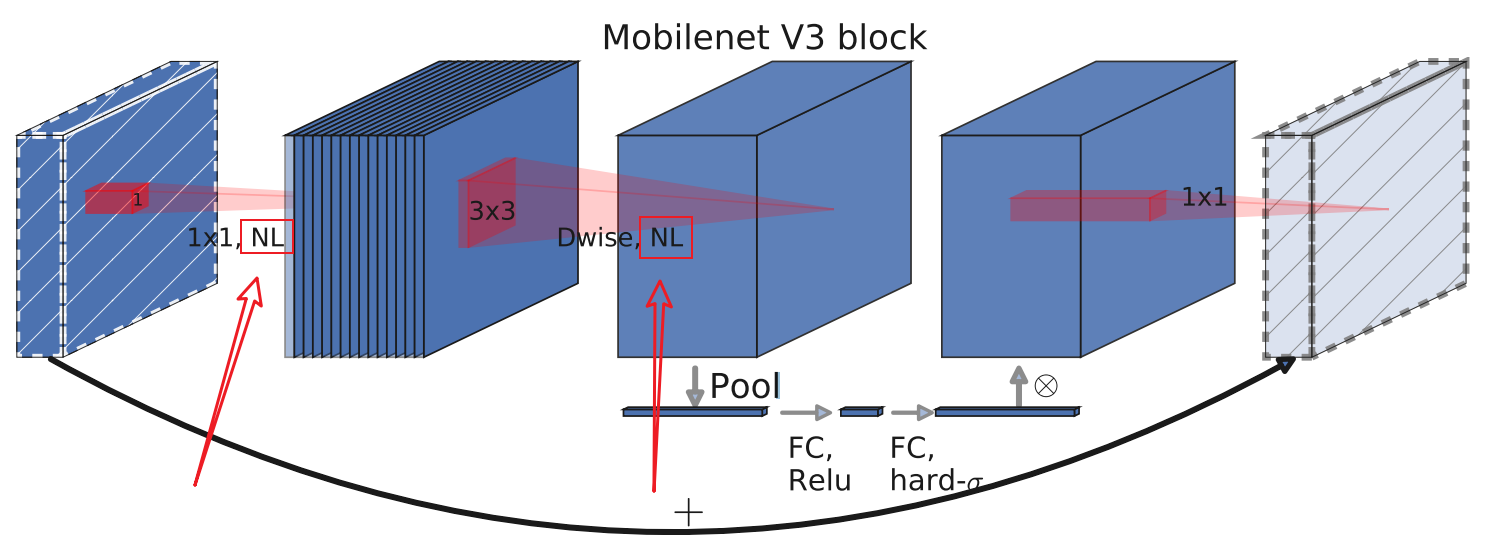
但是MobileNetV3中的某些层中(注意不是全部),在进行最后一个1x1卷积之前, 要进行一个SE模块注意力机制,MobileNetV3的倒残差如下图所示:
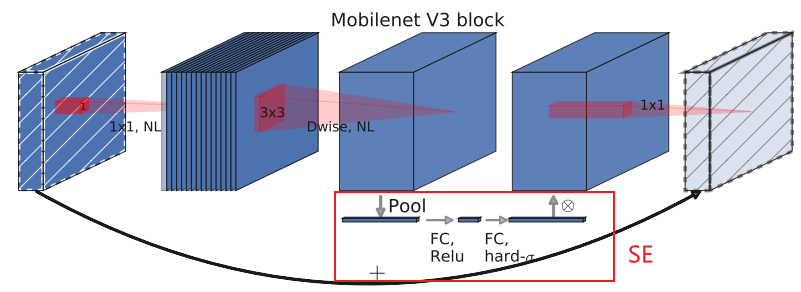
可以在上图中很明显的看到圈出的红框内容,这是一个SE模块,这里的SE模块是一 个通道注意力机制,即对通道进行特征注意。
它的作用是针对于得到的特征矩阵,对每一个channel进行池化处理,有多少 channel,得到的池化后的一维向量就有多少个元素,接下来通过第一个全连接层, 这个全连接层的节点个数=特征矩阵channel的1/4,接下来是第二个全连接层,它的 节点个数=特征矩阵channel。所以SE模块可以理解为:对特征矩阵的每个channel分 析出一个权重关系,它把比较重要的channel赋予更大的权重值,把不那么重要的 channel赋予比较小的权重值。该过程举例如下:
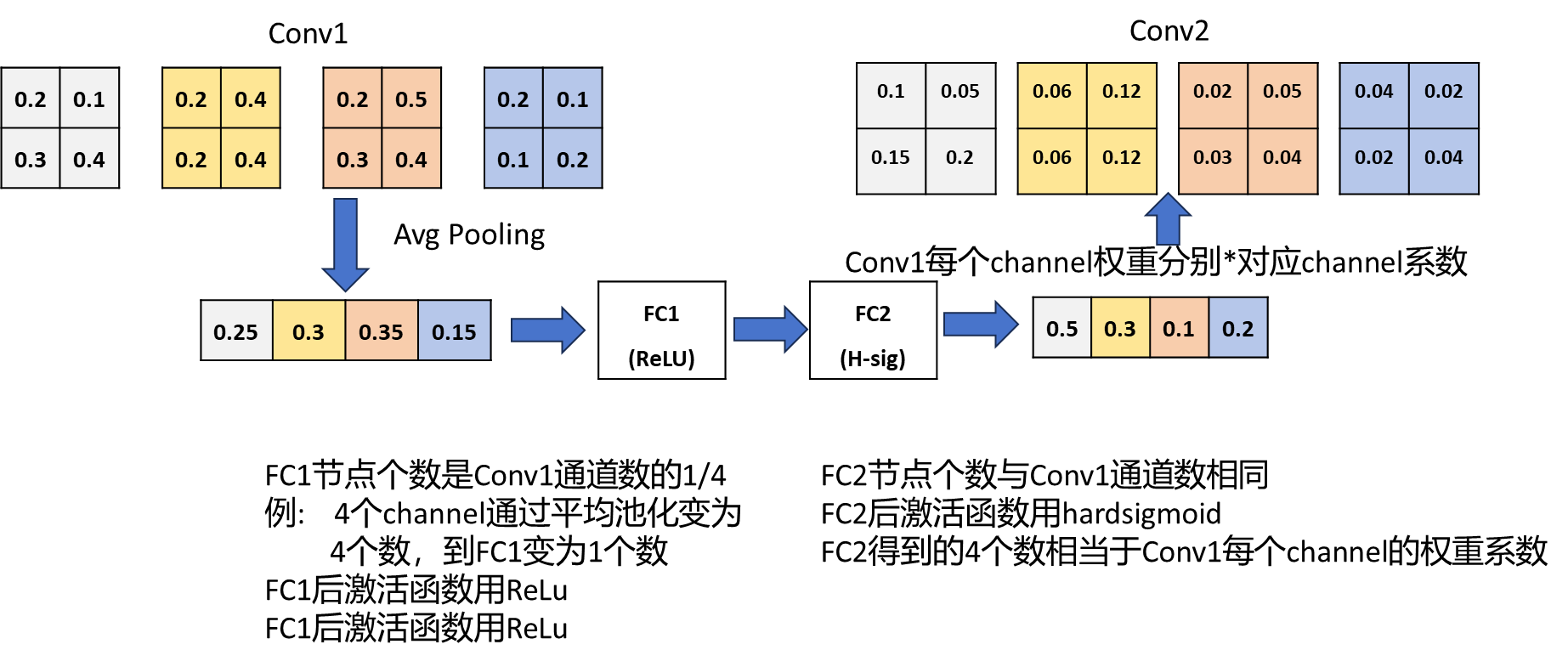
上图中,Conv1是DW卷积后得到的特征矩阵,该特征矩阵共4个channel,当然实际 上多得多,这里只是简单举例,对每个channel进行平均池化操作,得到一个向量, 接下来要经过第一次全连接层,全连接层的激活函数为Relu,节点个数=1,即4个 channel的1/4,接下来通过第二个全连接层和h-sigmoid激活函数,该激活函数在后 续会讲到,节点个数为4,最后得到的向量要与Conv1的每一个元素进行相乘,例如 Conv1左上角的0.2,与得到的第一个channel的系数0.5进行相乘,得到Conv2的左 上角的0.1,以此类推,就完成了SE模块的功能。
2.3、更新了激活函数
在新的Block结构中,更新了激活函数,在下图中的红框内可以看到,激活函数用了 NL进行表示,NL指的是非线性激活函数,在不同的层中,使用了不同的激活函数, 所以只是用了NL进行表示具体哪一层用了什么激活函数,会在网络的结构中指出。

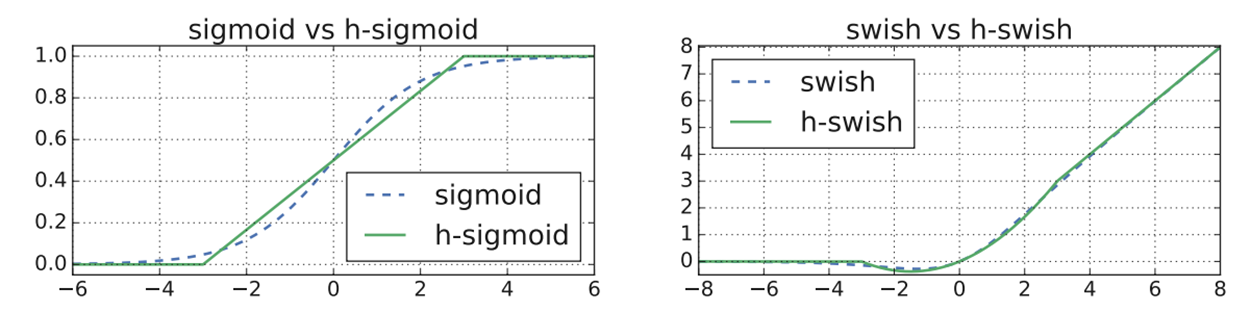 h-swish[x]激活函数其实是x乘以h-sigmoid激活函数,可以从图像中看出,hswish[x]激活函数与swish x激活函数非常相似,而且公式更为简单,没有幂运算, 计算速度更快,同时对量化过程更加友好。
h-swish[x]激活函数其实是x乘以h-sigmoid激活函数,可以从图像中看出,hswish[x]激活函数与swish x激活函数非常相似,而且公式更为简单,没有幂运算, 计算速度更快,同时对量化过程更加友好。
并非整个模型都使用了h-swish,模型的前一半层使用常规ReLU(第一个conv层之 后的除外)。 为什么要这样做呢?因为作者发现,h-swish[x]激活函数仅在更深层次 上有用。此外,考虑到特征图在较浅的层中往往更大,因此计算其激活成本更高,所 以作者选择在这些层上简单地使用ReLU(而非ReLU6),因为它比h-swish省时。
2.4、使用NAS搜索参数
NAS是Neural Architecture Search,实现网络结构搜索,由资源受限的 NAS 执行整 体模块结构搜索,该算法是在2018年 MnasNet 论文中提出的。过去神经网络搜索都 是针对一个卷积模块内部的结构进行搜索,然后网络各层重复利用这个模块,例如 MobileNetV2 的 Bottleneck Residual Block。这种方法潜在的问题是会失去模块与模块(层与层)之间的多样性,而层的多样性对于实现高精度和低延迟非常重要。
MobileNetV3将网络以倒残差模块为单位分解为独立的块,然后为每一个块在宏观上 搜索网络结构,这样将会允许不同的块使用不同的宏观结构。例如,在网络的早期阶 段(靠近输入的几层),通常会处理大量的数据,这些层关于延迟的影响要比远离输 入的层大得多,所以对比后面的层应该有不同的结构。
在执行 NAS 网络搜索时,MobileNet v3 采用的是强化学习求解多目标优化问题 (accuracy 和 latency)。 使用资源受限的 NAS 执行整体模块结构搜索后,MobileNet v3 继续使用 NetAdapt 算法对各层的结构进行精调。这个过程主要是在 NAS 搜索得到的网络基础上,对网 络的某一层生成一些新的待选结构,先测试新的结构是否能降低延迟,在此基础上对 能降低延迟的结构再测试其对应的模型准确率,最后选择的是最优的结构。总体来 说,NetAdapt 实现了两个结果:
1. 降低了倒残差模块 Expansion Layer 的大小;
2. 降低了倒残差模块 Projection Layer 的大小,让模型各层 Projection Layer 大小 相同,保证各层都使用残差连接。
2.5、重新设计耗时层
在paper中,提出了一些为了减少网络计算时耗时所涉及的内容。MobileNetV3将第一层卷积的卷积核个数由32个减少到16个,在paper中是这样介绍 的,当第一层的卷积由32减少到16之后,准确率是一样的,但是会节省2ms的时间。
在网络结构的最后一个部分,原本是NAS搜索出来的Original Last Stage,如下图上 面的图示流程,过程是:卷积->卷积->卷积->卷积->池化->卷积输出。但是在实际使 用过程中发现该结构是比较耗时的。于是对该结构进行了精简,提出了Efficient Last Stage,如下图下面的图示流程,精简之后,在进行第一个卷积之后,直接就进行了 池化,然后跟着两个卷积层进行输出,相对于原来的结构,节省了7ms的时间,占据 了整个推理过程的11%的时间。
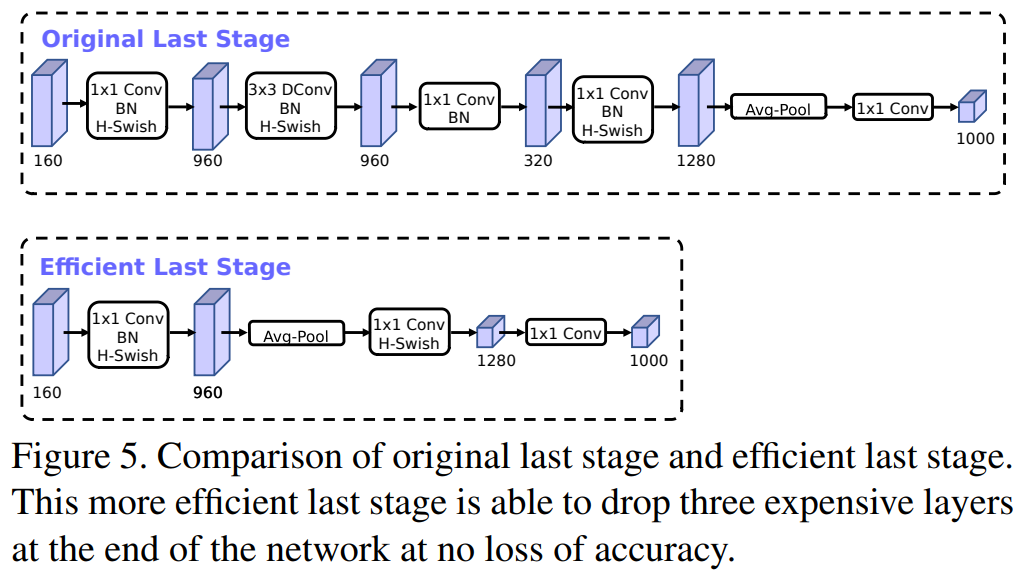
在使用过程中,可能会出现MobileNetV3准确率不如MobileNetV2的情况, MobileNetV3是来自于Google的,自然它更关注的是网络在Android设备上的表现, 事实也的确如此,作者主要针对Google Pixel硬件对网络做了参数优化。 当然这并不意味着MobileNet V3就是慢的了,只不过它无法在其他一些设备上达到 最佳效果。
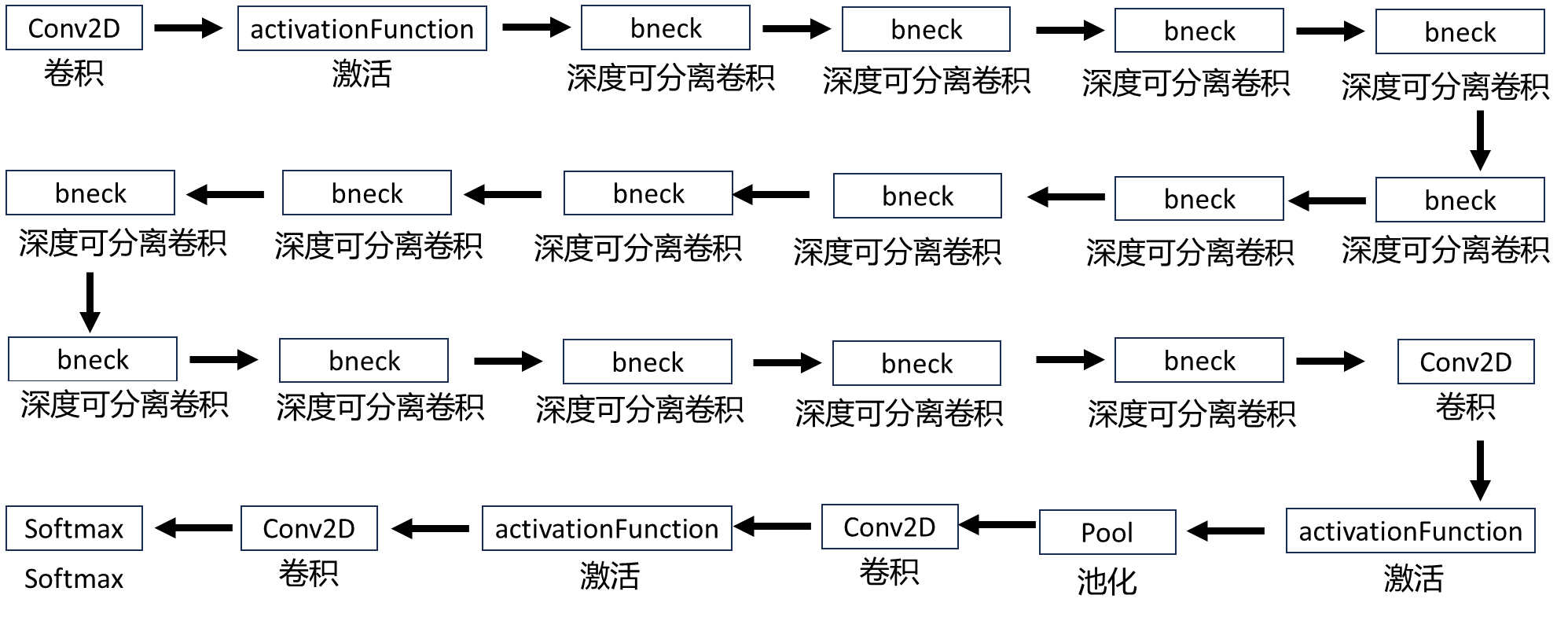
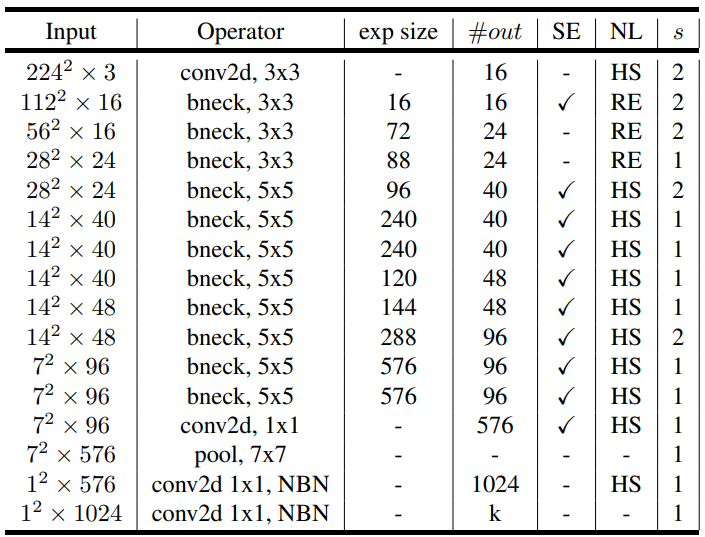
2.6、网络的结构
2.6.1、MobileNetV3-Large
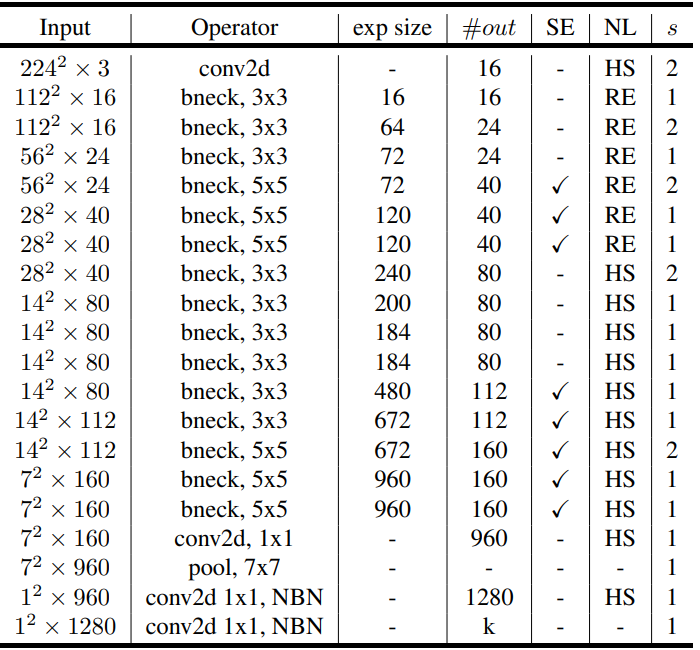
Input代表输入当前层的特征矩阵;
Operator代表操作(bneck就是倒残差结构,后面的3x3或者5x5就是DW卷积的 卷积核大小,在最后两层有个NBN参数,NBN代表这两层无batchNorm,意味 着其它层的Conv2D以及DWConv2D每一层之后都需要跟batchNorm);
exp size代表第一个升维的卷积所升到维度;
#out代表输出矩阵的channel;
SE代表这一层bneck是否使用注意力机制,对号代表使用;
NL代表激活函数的类别(HS是h-swish[x]激活函数,RE是Relu激活函数);
s代表步距,但是在bneck结构中指的是DW卷积的步距,其他层步距依然为1。
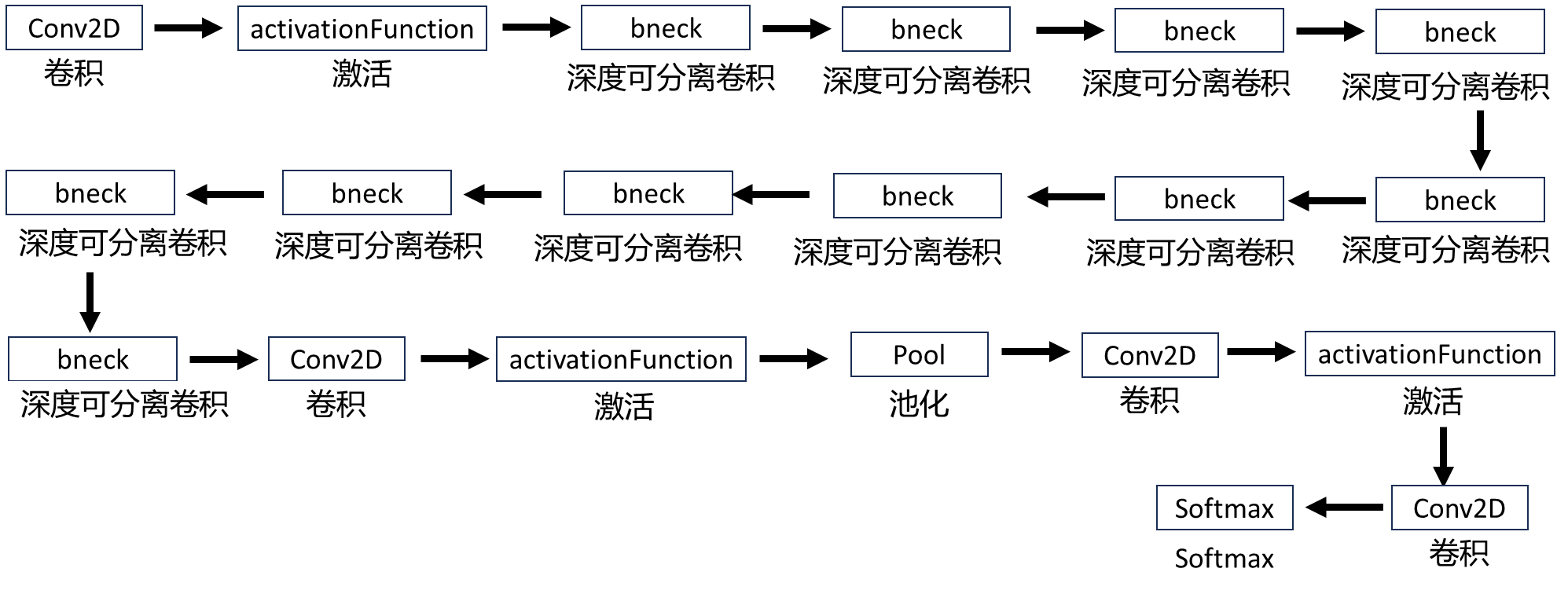
2.6.2、MobileNetV3-small
import torch.nn as nn
from torch.nn import functional as F
from torchsummary import summary# 定义 h-swish 激活函数
class HSigmoid(nn.Module):'''- HSigmoid 是一个 hard sigmoid 函数的实现,它是 sigmoid 函数的近似,计算更高效,更适合量化。'''def __init__(self, inplace=True):super().__init__()self.inplace = inplacedef forward(self, x):# 等价于 F.relu6(x + 3, inplace=True) / 6return (x + 3).clamp(0, 6) / 6class HSwish(nn.Module):'''h-swish 激活函数 (HSigmoid 和 HSwish 类):- HSwish 是将输入乘以 HSigmoid(输入) 得到的激活函数,在 MobileNetV3 中被广泛使用。'''def __init__(self, inplace=True):super().__init__()self.inplace = inplaceself.h_sigmoid = HSigmoid(inplace=True)def forward(self, x):return x * self.h_sigmoid(x)class SEModule(nn.Module):'''Squeeze-and-Excite (SE) 模块 (SEModule 类):- SE 模块用于增强网络对通道特征的敏感性。- 它首先对每个通道的特征图进行全局平均池化,得到每个通道的全局统计信息。- 然后,通过两个全连接层和一个 h-sigmoid 激活函数,学习到每个通道的权重 (excitation)。- 最后,将这些权重乘回原始的特征图,实现通道特征的重加权。'''def __init__(self, in_channels, reduction=4):super().__init__()# 计算中间通道数,用于 bottleneckself.se_channels = in_channels // reduction# 第一个全连接层,将输入通道数降维到 se_channelsself.fc1 = nn.Linear(in_channels, self.se_channels)# 第二个全连接层,将通道数恢复到原始的 in_channelsself.fc2 = nn.Linear(self.se_channels, in_channels)self.h_sigmoid = HSigmoid() # 使用 h-sigmoid 作为激活函数def forward(self, x):# 1. 全局平均池化,将每个通道的特征图压缩为一个标量# (B, C, H, W) -> (B, C, 1, 1)n, c, h, w = x.size()squeeze = x.mean(dim=(2, 3), keepdim=True) # (B, C, 1, 1)# 2. 通过两个全连接层和激活函数进行 excitationexcitation = self.h_sigmoid(self.fc2(F.relu(self.fc1(squeeze.view(n, c))))) # (B, C, 1, 1)# 3. 将 excitation 乘回原始的特征图,进行通道加权scale = excitation.view(n, c, 1, 1).expand_as(x)return x * scaleclass InvertedResidual(nn.Module):'''- 这是 MobileNetV3 的核心构建块。- 它首先使用一个 1x1 卷积层 (expand layer) 扩展输入通道数 (如果 expand_ratio > 1)。- 接着是一个深度可分离卷积 (depthwise convolution),用于在每个通道上独立地进行空间卷积,减少计算量。- 如果配置中指定使用 SE 模块 (use_se 为 True),则在此处插入 SE 模块。- 最后,使用一个 1x1 卷积层 (project layer) 将通道数减少到输出通道数。- 如果步长为 1 且输入输出通道数相同,则使用残差连接,将输入直接加到输出上。- 根据配置 (activation),使用 ReLU 或 h-swish 作为激活函数。'''def __init__(self, in_channels, out_channels, stride, expand_ratio, use_se, activation='RE'):super().__init__()self.stride = strideassert stride in [1, 2]self.use_res_connect = self.stride == 1 and in_channels == out_channelshidden_dim = int(round(in_channels * expand_ratio))self.expand = Noneif expand_ratio != 1:# 扩展层:1x1 卷积增加通道数self.expand = nn.Conv2d(in_channels, hidden_dim, kernel_size=1, bias=False)self.bn1 = nn.BatchNorm2d(hidden_dim)# 深度可分离卷积 (Depthwise Convolution)self.depthwise = nn.Conv2d(hidden_dim, hidden_dim, kernel_size=3, stride=stride, padding=1, groups=hidden_dim, bias=False)self.bn2 = nn.BatchNorm2d(hidden_dim)self.se = Noneif use_se:# Squeeze-and-Excite 模块self.se = SEModule(hidden_dim)# 投影层:1x1 卷积减少通道数到 out_channelsself.project = nn.Conv2d(hidden_dim, out_channels, kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(out_channels)# 选择激活函数if activation == 'RE':self.activation = nn.ReLU(inplace=True)elif activation == 'HS':self.activation = HSwish(inplace=True)else:raise ValueError("Unsupported activation type")def forward(self, x):identity = xif self.expand is not None:out = self.activation(self.bn1(self.expand(x)))else:out = xout = self.activation(self.bn2(self.depthwise(out)))if self.se is not None:out = self.se(out)out = self.bn3(self.project(out))if self.use_res_connect:return identity + outelse:return out# MobileNetV3 的主体结构定义
class MobileNetV3(nn.Module):'''MobileNetV3 主体结构 (MobileNetV3 类):- 网络的初始化部分定义了第一个卷积层和后续的倒置残差模块序列。- `cfgs` 参数是一个列表,包含了每个倒置残差模块的配置信息,包括:- t: 扩展率 (expand ratio)- c: 输出通道数 (out channels)- s: 步长 (stride)- SE: 是否使用 SE 模块 (True/False)- HS: 使用的激活函数 ('HS' 代表 h-swish, 'RE' 代表 ReLU)- `features` 是一个 Sequential 容器,包含了所有的卷积层和倒置残差模块。- 网络的最后部分包括一个 1x1 卷积层、BatchNorm、h-swish 激活函数、全局平均池化和分类器。- 分类器包含两个全连接层,中间使用 h-swish 激活和 Dropout 正则化。- `_make_divisible` 函数用于确保网络的通道数是 8 的倍数,这在一些硬件上可以提高计算效率。'''def __init__(self, cfgs, num_classes=1000, width_multiplier=1.0):super().__init__()# 设置宽度乘数,用于调整网络宽度self.width_multiplier = width_multiplier# 定义网络的第一个卷积层first_channel = self._make_divisible(16 * width_multiplier, 8)layers = [nn.Conv2d(3, first_channel, kernel_size=3, stride=2, padding=1, bias=False),nn.BatchNorm2d(first_channel),HSwish(inplace=True)]in_channels = first_channel# 构建中间的倒置残差模块for cfg in cfgs:out_channels = self._make_divisible(cfg[0] * width_multiplier, 8)expand_ratio = cfg[1]stride = cfg[2]use_se = cfg[3]activation = cfg[4]layers.append(InvertedResidual(in_channels, out_channels, stride, expand_ratio, use_se, activation))in_channels = out_channelsself.features = nn.Sequential(*layers)# 构建网络的最后部分last_channel = self._make_divisible(cfgs[-1][0] * width_multiplier * 6, 8)self.conv = nn.Conv2d(in_channels, last_channel, kernel_size=1, bias=False)self.bn = nn.BatchNorm2d(last_channel)self.hswish = HSwish(inplace=True)self.avgpool = nn.AdaptiveAvgPool2d(1)self.classifier = nn.Sequential(nn.Linear(last_channel, self._make_divisible(1280 * width_multiplier, 8)),HSwish(inplace=True),nn.Dropout(0.2), # 添加 dropout 正则化nn.Linear(self._make_divisible(1280 * width_multiplier, 8), num_classes),)def _make_divisible(self, v, divisor, min_value=None):# 确保通道数可以被 8 整除if min_value is None:min_value = divisornew_v = max(min_value, int(v + divisor / 2) // divisor * divisor)# 确保不要减少超过 10%if new_v < 0.9 * v:new_v += divisorreturn new_vdef forward(self, x):x = self.features(x)x = self.hswish(self.bn(self.conv(x)))x = self.avgpool(x)x = x.view(x.size(0), -1)x = self.classifier(x)return x# 创建 MobileNetV3-Large 模型实例
def mobilenetv3_large(num_classes=1000, width_multiplier=1.0):"""创建 MobileNetV3-Large 模型。Args:num_classes (int): 分类任务的类别数,默认为 1000 (ImageNet).width_multiplier (float): 网络宽度的乘数,用于调整模型大小,默认为 1.0.Returns:MobileNetV3: MobileNetV3-Large 模型实例."""cfgs_large = [# t, c, s, SE, HS# t: 扩展率 (expand ratio)# c: 输出通道数 (out channels)# s: 步长 (stride)# SE: 是否使用 SE 模块 (True/False)# HS: 使用的激活函数 ('HS' 代表 h-swish, 'RE' 代表 ReLU)[1, 16, 1, False, 'RE'],[4, 24, 2, False, 'RE'],[3, 24, 1, False, 'RE'],[3, 40, 2, True, 'RE'],[3, 40, 1, True, 'RE'],[3, 40, 1, True, 'RE'],[6, 80, 2, False, 'HS'],[2.5, 80, 1, False, 'HS'],[2.3, 80, 1, False, 'HS'],[2.3, 112, 1, True, 'HS'],[6, 112, 1, True, 'HS'],[6, 160, 2, True, 'HS'],[6, 160, 1, True, 'HS'],]return MobileNetV3(cfgs_large, num_classes, width_multiplier)# 创建 MobileNetV3-Small 模型实例
def mobilenetv3_small(num_classes=1000, width_multiplier=1.0):"""创建 MobileNetV3-Small 模型。Args:num_classes (int): 分类任务的类别数,默认为 1000 (ImageNet).width_multiplier (float): 网络宽度的乘数,用于调整模型大小,默认为 1.0.Returns:MobileNetV3: MobileNetV3-Small 模型实例."""cfgs_small = [# t, c, s, SE, HS# t: 扩展率 (expand ratio)# c: 输出通道数 (out channels)# s: 步长 (stride)# SE: 是否使用 SE 模块 (True/False)# HS: 使用的激活函数 ('HS' 代表 h-swish, 'RE' 代表 ReLU)[1, 16, 2, True, 'RE'],[4.5, 24, 2, False, 'RE'],[3.6, 24, 1, False, 'RE'],[4, 40, 2, True, 'RE'],[3, 48, 1, True, 'RE'],[3, 48, 1, True, 'RE'],[6, 96, 2, True, 'HS'],[6, 96, 1, True, 'HS'],]return MobileNetV3(cfgs_small, num_classes, width_multiplier)if __name__ == '__main__':# 实例化 Large 模型并打印结构概要model_large = mobilenetv3_large()print("MobileNetV3-Large Summary:")summary(model_large, (3, 224, 224))print("\n" + "="*40 + "\n")# 实例化 Small 模型并打印结构概要model_small = mobilenetv3_small()print("MobileNetV3-Small Summary:")summary(model_small, (3, 224, 224))MobileNetV3-Large Summary:
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 16, 112, 112] 432BatchNorm2d-2 [-1, 16, 112, 112] 32HSigmoid-3 [-1, 16, 112, 112] 0HSwish-4 [-1, 16, 112, 112] 0Conv2d-5 [-1, 256, 112, 112] 4,096BatchNorm2d-6 [-1, 256, 112, 112] 512ReLU-7 [-1, 256, 112, 112] 0Conv2d-8 [-1, 256, 112, 112] 2,304BatchNorm2d-9 [-1, 256, 112, 112] 512ReLU-10 [-1, 256, 112, 112] 0Conv2d-11 [-1, 8, 112, 112] 2,048BatchNorm2d-12 [-1, 8, 112, 112] 16InvertedResidual-13 [-1, 8, 112, 112] 0Conv2d-14 [-1, 192, 112, 112] 1,536BatchNorm2d-15 [-1, 192, 112, 112] 384ReLU-16 [-1, 192, 112, 112] 0Conv2d-17 [-1, 192, 56, 56] 1,728BatchNorm2d-18 [-1, 192, 56, 56] 384ReLU-19 [-1, 192, 56, 56] 0Conv2d-20 [-1, 8, 56, 56] 1,536BatchNorm2d-21 [-1, 8, 56, 56] 16InvertedResidual-22 [-1, 8, 56, 56] 0Conv2d-23 [-1, 192, 56, 56] 1,536BatchNorm2d-24 [-1, 192, 56, 56] 384ReLU-25 [-1, 192, 56, 56] 0Conv2d-26 [-1, 192, 56, 56] 1,728BatchNorm2d-27 [-1, 192, 56, 56] 384ReLU-28 [-1, 192, 56, 56] 0Conv2d-29 [-1, 8, 56, 56] 1,536BatchNorm2d-30 [-1, 8, 56, 56] 16InvertedResidual-31 [-1, 8, 56, 56] 0Conv2d-32 [-1, 320, 56, 56] 2,560BatchNorm2d-33 [-1, 320, 56, 56] 640ReLU-34 [-1, 320, 56, 56] 0Conv2d-35 [-1, 320, 28, 28] 2,880BatchNorm2d-36 [-1, 320, 28, 28] 640ReLU-37 [-1, 320, 28, 28] 0Linear-38 [-1, 80] 25,680Linear-39 [-1, 320] 25,920HSigmoid-40 [-1, 320] 0SEModule-41 [-1, 320, 28, 28] 0Conv2d-42 [-1, 8, 28, 28] 2,560BatchNorm2d-43 [-1, 8, 28, 28] 16InvertedResidual-44 [-1, 8, 28, 28] 0Conv2d-45 [-1, 320, 28, 28] 2,560BatchNorm2d-46 [-1, 320, 28, 28] 640ReLU-47 [-1, 320, 28, 28] 0Conv2d-48 [-1, 320, 28, 28] 2,880BatchNorm2d-49 [-1, 320, 28, 28] 640ReLU-50 [-1, 320, 28, 28] 0Linear-51 [-1, 80] 25,680Linear-52 [-1, 320] 25,920HSigmoid-53 [-1, 320] 0SEModule-54 [-1, 320, 28, 28] 0Conv2d-55 [-1, 8, 28, 28] 2,560BatchNorm2d-56 [-1, 8, 28, 28] 16InvertedResidual-57 [-1, 8, 28, 28] 0Conv2d-58 [-1, 320, 28, 28] 2,560BatchNorm2d-59 [-1, 320, 28, 28] 640ReLU-60 [-1, 320, 28, 28] 0Conv2d-61 [-1, 320, 28, 28] 2,880BatchNorm2d-62 [-1, 320, 28, 28] 640ReLU-63 [-1, 320, 28, 28] 0Linear-64 [-1, 80] 25,680Linear-65 [-1, 320] 25,920HSigmoid-66 [-1, 320] 0SEModule-67 [-1, 320, 28, 28] 0Conv2d-68 [-1, 8, 28, 28] 2,560BatchNorm2d-69 [-1, 8, 28, 28] 16InvertedResidual-70 [-1, 8, 28, 28] 0Conv2d-71 [-1, 640, 28, 28] 5,120BatchNorm2d-72 [-1, 640, 28, 28] 1,280HSigmoid-73 [-1, 640, 28, 28] 0HSwish-74 [-1, 640, 28, 28] 0Conv2d-75 [-1, 640, 14, 14] 5,760BatchNorm2d-76 [-1, 640, 14, 14] 1,280HSigmoid-77 [-1, 640, 14, 14] 0HSwish-78 [-1, 640, 14, 14] 0Conv2d-79 [-1, 8, 14, 14] 5,120BatchNorm2d-80 [-1, 8, 14, 14] 16InvertedResidual-81 [-1, 8, 14, 14] 0Conv2d-82 [-1, 640, 14, 14] 5,120BatchNorm2d-83 [-1, 640, 14, 14] 1,280HSigmoid-84 [-1, 640, 14, 14] 0HSwish-85 [-1, 640, 14, 14] 0Conv2d-86 [-1, 640, 14, 14] 5,760BatchNorm2d-87 [-1, 640, 14, 14] 1,280HSigmoid-88 [-1, 640, 14, 14] 0HSwish-89 [-1, 640, 14, 14] 0Conv2d-90 [-1, 8, 14, 14] 5,120BatchNorm2d-91 [-1, 8, 14, 14] 16InvertedResidual-92 [-1, 8, 14, 14] 0Conv2d-93 [-1, 640, 14, 14] 5,120BatchNorm2d-94 [-1, 640, 14, 14] 1,280HSigmoid-95 [-1, 640, 14, 14] 0HSwish-96 [-1, 640, 14, 14] 0Conv2d-97 [-1, 640, 14, 14] 5,760BatchNorm2d-98 [-1, 640, 14, 14] 1,280HSigmoid-99 [-1, 640, 14, 14] 0HSwish-100 [-1, 640, 14, 14] 0Conv2d-101 [-1, 8, 14, 14] 5,120BatchNorm2d-102 [-1, 8, 14, 14] 16
InvertedResidual-103 [-1, 8, 14, 14] 0Conv2d-104 [-1, 896, 14, 14] 7,168BatchNorm2d-105 [-1, 896, 14, 14] 1,792HSigmoid-106 [-1, 896, 14, 14] 0HSwish-107 [-1, 896, 14, 14] 0Conv2d-108 [-1, 896, 14, 14] 8,064BatchNorm2d-109 [-1, 896, 14, 14] 1,792HSigmoid-110 [-1, 896, 14, 14] 0HSwish-111 [-1, 896, 14, 14] 0Linear-112 [-1, 224] 200,928Linear-113 [-1, 896] 201,600HSigmoid-114 [-1, 896] 0SEModule-115 [-1, 896, 14, 14] 0Conv2d-116 [-1, 8, 14, 14] 7,168BatchNorm2d-117 [-1, 8, 14, 14] 16
InvertedResidual-118 [-1, 8, 14, 14] 0Conv2d-119 [-1, 896, 14, 14] 7,168BatchNorm2d-120 [-1, 896, 14, 14] 1,792HSigmoid-121 [-1, 896, 14, 14] 0HSwish-122 [-1, 896, 14, 14] 0Conv2d-123 [-1, 896, 14, 14] 8,064BatchNorm2d-124 [-1, 896, 14, 14] 1,792HSigmoid-125 [-1, 896, 14, 14] 0HSwish-126 [-1, 896, 14, 14] 0Linear-127 [-1, 224] 200,928Linear-128 [-1, 896] 201,600HSigmoid-129 [-1, 896] 0SEModule-130 [-1, 896, 14, 14] 0Conv2d-131 [-1, 8, 14, 14] 7,168BatchNorm2d-132 [-1, 8, 14, 14] 16
InvertedResidual-133 [-1, 8, 14, 14] 0Conv2d-134 [-1, 1280, 14, 14] 10,240BatchNorm2d-135 [-1, 1280, 14, 14] 2,560HSigmoid-136 [-1, 1280, 14, 14] 0HSwish-137 [-1, 1280, 14, 14] 0Conv2d-138 [-1, 1280, 7, 7] 11,520BatchNorm2d-139 [-1, 1280, 7, 7] 2,560HSigmoid-140 [-1, 1280, 7, 7] 0HSwish-141 [-1, 1280, 7, 7] 0Linear-142 [-1, 320] 409,920Linear-143 [-1, 1280] 410,880HSigmoid-144 [-1, 1280] 0SEModule-145 [-1, 1280, 7, 7] 0Conv2d-146 [-1, 8, 7, 7] 10,240BatchNorm2d-147 [-1, 8, 7, 7] 16
InvertedResidual-148 [-1, 8, 7, 7] 0Conv2d-149 [-1, 1280, 7, 7] 10,240BatchNorm2d-150 [-1, 1280, 7, 7] 2,560HSigmoid-151 [-1, 1280, 7, 7] 0HSwish-152 [-1, 1280, 7, 7] 0Conv2d-153 [-1, 1280, 7, 7] 11,520BatchNorm2d-154 [-1, 1280, 7, 7] 2,560HSigmoid-155 [-1, 1280, 7, 7] 0HSwish-156 [-1, 1280, 7, 7] 0Linear-157 [-1, 320] 409,920Linear-158 [-1, 1280] 410,880HSigmoid-159 [-1, 1280] 0SEModule-160 [-1, 1280, 7, 7] 0Conv2d-161 [-1, 8, 7, 7] 10,240BatchNorm2d-162 [-1, 8, 7, 7] 16
InvertedResidual-163 [-1, 8, 7, 7] 0Conv2d-164 [-1, 40, 7, 7] 320BatchNorm2d-165 [-1, 40, 7, 7] 80HSigmoid-166 [-1, 40, 7, 7] 0HSwish-167 [-1, 40, 7, 7] 0
AdaptiveAvgPool2d-168 [-1, 40, 1, 1] 0Linear-169 [-1, 1280] 52,480HSigmoid-170 [-1, 1280] 0HSwish-171 [-1, 1280] 0Dropout-172 [-1, 1280] 0Linear-173 [-1, 1000] 1,281,000
================================================================
Total params: 4,166,344
Trainable params: 4,166,344
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 384.21
Params size (MB): 15.89
Estimated Total Size (MB): 400.68
----------------------------------------------------------------========================================MobileNetV3-Small Summary:
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 16, 112, 112] 432BatchNorm2d-2 [-1, 16, 112, 112] 32HSigmoid-3 [-1, 16, 112, 112] 0HSwish-4 [-1, 16, 112, 112] 0Conv2d-5 [-1, 256, 112, 112] 4,096BatchNorm2d-6 [-1, 256, 112, 112] 512ReLU-7 [-1, 256, 112, 112] 0Conv2d-8 [-1, 256, 56, 56] 2,304BatchNorm2d-9 [-1, 256, 56, 56] 512ReLU-10 [-1, 256, 56, 56] 0Linear-11 [-1, 64] 16,448Linear-12 [-1, 256] 16,640HSigmoid-13 [-1, 256] 0SEModule-14 [-1, 256, 56, 56] 0Conv2d-15 [-1, 8, 56, 56] 2,048BatchNorm2d-16 [-1, 8, 56, 56] 16InvertedResidual-17 [-1, 8, 56, 56] 0Conv2d-18 [-1, 192, 56, 56] 1,536BatchNorm2d-19 [-1, 192, 56, 56] 384ReLU-20 [-1, 192, 56, 56] 0Conv2d-21 [-1, 192, 28, 28] 1,728BatchNorm2d-22 [-1, 192, 28, 28] 384ReLU-23 [-1, 192, 28, 28] 0Conv2d-24 [-1, 8, 28, 28] 1,536BatchNorm2d-25 [-1, 8, 28, 28] 16InvertedResidual-26 [-1, 8, 28, 28] 0Conv2d-27 [-1, 192, 28, 28] 1,536BatchNorm2d-28 [-1, 192, 28, 28] 384ReLU-29 [-1, 192, 28, 28] 0Conv2d-30 [-1, 192, 28, 28] 1,728BatchNorm2d-31 [-1, 192, 28, 28] 384ReLU-32 [-1, 192, 28, 28] 0Conv2d-33 [-1, 8, 28, 28] 1,536BatchNorm2d-34 [-1, 8, 28, 28] 16InvertedResidual-35 [-1, 8, 28, 28] 0Conv2d-36 [-1, 320, 28, 28] 2,560BatchNorm2d-37 [-1, 320, 28, 28] 640ReLU-38 [-1, 320, 28, 28] 0Conv2d-39 [-1, 320, 14, 14] 2,880BatchNorm2d-40 [-1, 320, 14, 14] 640ReLU-41 [-1, 320, 14, 14] 0Linear-42 [-1, 80] 25,680Linear-43 [-1, 320] 25,920HSigmoid-44 [-1, 320] 0SEModule-45 [-1, 320, 14, 14] 0Conv2d-46 [-1, 8, 14, 14] 2,560BatchNorm2d-47 [-1, 8, 14, 14] 16InvertedResidual-48 [-1, 8, 14, 14] 0Conv2d-49 [-1, 384, 14, 14] 3,072BatchNorm2d-50 [-1, 384, 14, 14] 768ReLU-51 [-1, 384, 14, 14] 0Conv2d-52 [-1, 384, 14, 14] 3,456BatchNorm2d-53 [-1, 384, 14, 14] 768ReLU-54 [-1, 384, 14, 14] 0Linear-55 [-1, 96] 36,960Linear-56 [-1, 384] 37,248HSigmoid-57 [-1, 384] 0SEModule-58 [-1, 384, 14, 14] 0Conv2d-59 [-1, 8, 14, 14] 3,072BatchNorm2d-60 [-1, 8, 14, 14] 16InvertedResidual-61 [-1, 8, 14, 14] 0Conv2d-62 [-1, 384, 14, 14] 3,072BatchNorm2d-63 [-1, 384, 14, 14] 768ReLU-64 [-1, 384, 14, 14] 0Conv2d-65 [-1, 384, 14, 14] 3,456BatchNorm2d-66 [-1, 384, 14, 14] 768ReLU-67 [-1, 384, 14, 14] 0Linear-68 [-1, 96] 36,960Linear-69 [-1, 384] 37,248HSigmoid-70 [-1, 384] 0SEModule-71 [-1, 384, 14, 14] 0Conv2d-72 [-1, 8, 14, 14] 3,072BatchNorm2d-73 [-1, 8, 14, 14] 16InvertedResidual-74 [-1, 8, 14, 14] 0Conv2d-75 [-1, 768, 14, 14] 6,144BatchNorm2d-76 [-1, 768, 14, 14] 1,536HSigmoid-77 [-1, 768, 14, 14] 0HSwish-78 [-1, 768, 14, 14] 0Conv2d-79 [-1, 768, 7, 7] 6,912BatchNorm2d-80 [-1, 768, 7, 7] 1,536HSigmoid-81 [-1, 768, 7, 7] 0HSwish-82 [-1, 768, 7, 7] 0Linear-83 [-1, 192] 147,648Linear-84 [-1, 768] 148,224HSigmoid-85 [-1, 768] 0SEModule-86 [-1, 768, 7, 7] 0Conv2d-87 [-1, 8, 7, 7] 6,144BatchNorm2d-88 [-1, 8, 7, 7] 16InvertedResidual-89 [-1, 8, 7, 7] 0Conv2d-90 [-1, 768, 7, 7] 6,144BatchNorm2d-91 [-1, 768, 7, 7] 1,536HSigmoid-92 [-1, 768, 7, 7] 0HSwish-93 [-1, 768, 7, 7] 0Conv2d-94 [-1, 768, 7, 7] 6,912BatchNorm2d-95 [-1, 768, 7, 7] 1,536HSigmoid-96 [-1, 768, 7, 7] 0HSwish-97 [-1, 768, 7, 7] 0Linear-98 [-1, 192] 147,648Linear-99 [-1, 768] 148,224HSigmoid-100 [-1, 768] 0SEModule-101 [-1, 768, 7, 7] 0Conv2d-102 [-1, 8, 7, 7] 6,144BatchNorm2d-103 [-1, 8, 7, 7] 16
InvertedResidual-104 [-1, 8, 7, 7] 0Conv2d-105 [-1, 40, 7, 7] 320BatchNorm2d-106 [-1, 40, 7, 7] 80HSigmoid-107 [-1, 40, 7, 7] 0HSwish-108 [-1, 40, 7, 7] 0
AdaptiveAvgPool2d-109 [-1, 40, 1, 1] 0Linear-110 [-1, 1280] 52,480HSigmoid-111 [-1, 1280] 0HSwish-112 [-1, 1280] 0Dropout-113 [-1, 1280] 0Linear-114 [-1, 1000] 1,281,000
================================================================
Total params: 2,256,024
Trainable params: 2,256,024
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 153.69
Params size (MB): 8.61
Estimated Total Size (MB): 162.87
----------------------------------------------------------------