【AAAI 2025】 Local Conditional Controlling for Text-to-Image Diffusion Models
Local Conditional Controlling for Text-to-Image Diffusion Models(文本到图像扩散模型的局部条件控制)
文章目录
- 内容摘要
- 关键词
- 作者及研究团队
- 项目主页
- 01 研究领域待解决问题
- 02 论文解决的核心问题
- 03 关键解决方案
- 04 主要贡献
- 05 相关研究工作
- 06 解决方案实现细节
- 07 实验设计
- 08 实验结果与对比
- 09 消融研究发现
- 10 后续优化方向
内容摘要
本文针对文本到图像扩散模型的局部控制问题,提出一种无需训练的推理阶段优化方法。现有全局控制(如ControlNet)无法灵活约束特定区域,直接添加局部条件会导致“局部控制主导”(图2),忽视非控制区域的文本对齐。作者设计了区域判别损失(RDLoss)(公式5)、聚焦令牌响应(FTR)(公式8)和特征掩码约束(FMC)(公式9)三大模块:RDLoss通过最大化局部/非局部注意力差异更新隐变量,FTR抑制弱响应令牌减少重复,FMC通过掩码控制ControlNet特征泄漏。实验表明,该方法在COCO和Attend-Condition数据集上实现了局部条件与文本提示的高精度对齐(FID 21.86±0.48,CLIP T2T 0.801±0.006),解决了局部控制中结构失真和概念缺失的核心挑战(图1、5)。
关键词
Text-to-Image Diffusion, Local Control, Attention Modulation, Diffusion Model, Controllable Generation
作者及研究团队
本文由浙江大学CAD&CG国家重点实验室、Fabu Inc.、腾讯等机构合作完成。
项目主页
论文未公开代码,但提及基于Stable Diffusion和ControlNet框架,实验细节见附录(Section 4.1-4.3)。
01 研究领域待解决问题
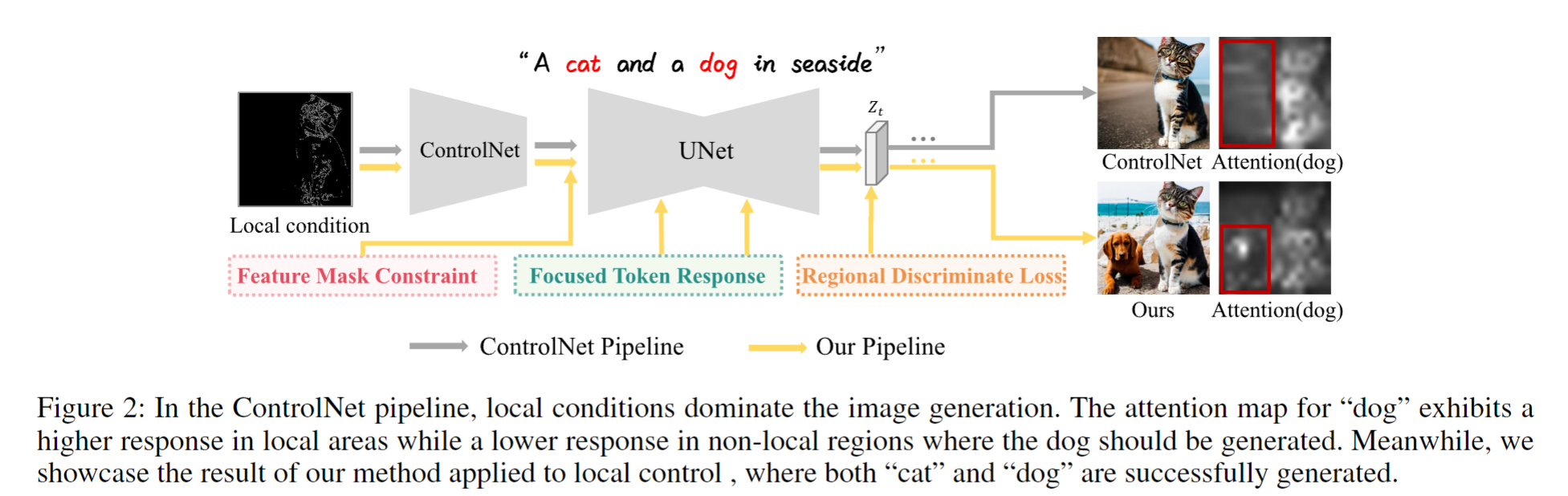
Existing text-to-image diffusion models with global controls (e.g., ControlNet) lack fine-grained localization capability. Directly applying local conditions causes “local control dominance” (Fig. 2), where the model over-focuses on controlled regions and neglects object generation in non-control areas aligned with text prompts. Additionally, global control methods (Section 2) fail to balance structural fidelity and text consistency in localized regions, leading to concept omission or duplication (Table 1, Fig. 5).
当前文本到图像扩散模型的全局控制(如ControlNet)缺乏局部精细化能力。直接引入局部条件会触发“局部控制主导”(图2),模型过度关注控制区域,忽视非控制区域与文本提示的对齐。此外,全局控制方法(第2节)无法平衡局部结构保真度与文本一致性,导致概念缺失或重复(表1,图5)。例如,在“猫和狗在海边”的提示中,ControlNet仅生成局部狗的结构,完全忽略猫的存在(图2左)。
02 论文解决的核心问题
The paper addresses local control dominance in text-to-image generation: how to enforce user-defined local conditions (e.g., cat canny) while preserving text-aligned object generation in non-control regions (e.g., dog, seaside). Existing methods either ignore non-control concepts (Fig. 2) or introduce artifacts due to feature inconsistency (Section 3.5).
论文解决文本到图像生成中的局部控制主导问题:在施加用户定义的局部条件(如猫的边缘图)时,如何保留非控制区域(如狗、海边)与文本提示的对齐。现有方法要么忽略非控制概念(图2),要么因特征不一致引入伪影(第3.5节)。例如,图1中全局控制(带掩码)仍无法生成符合“玩具车”提示的非控制区域,而本文方法同时满足局部结构与全局文本。

03 关键解决方案
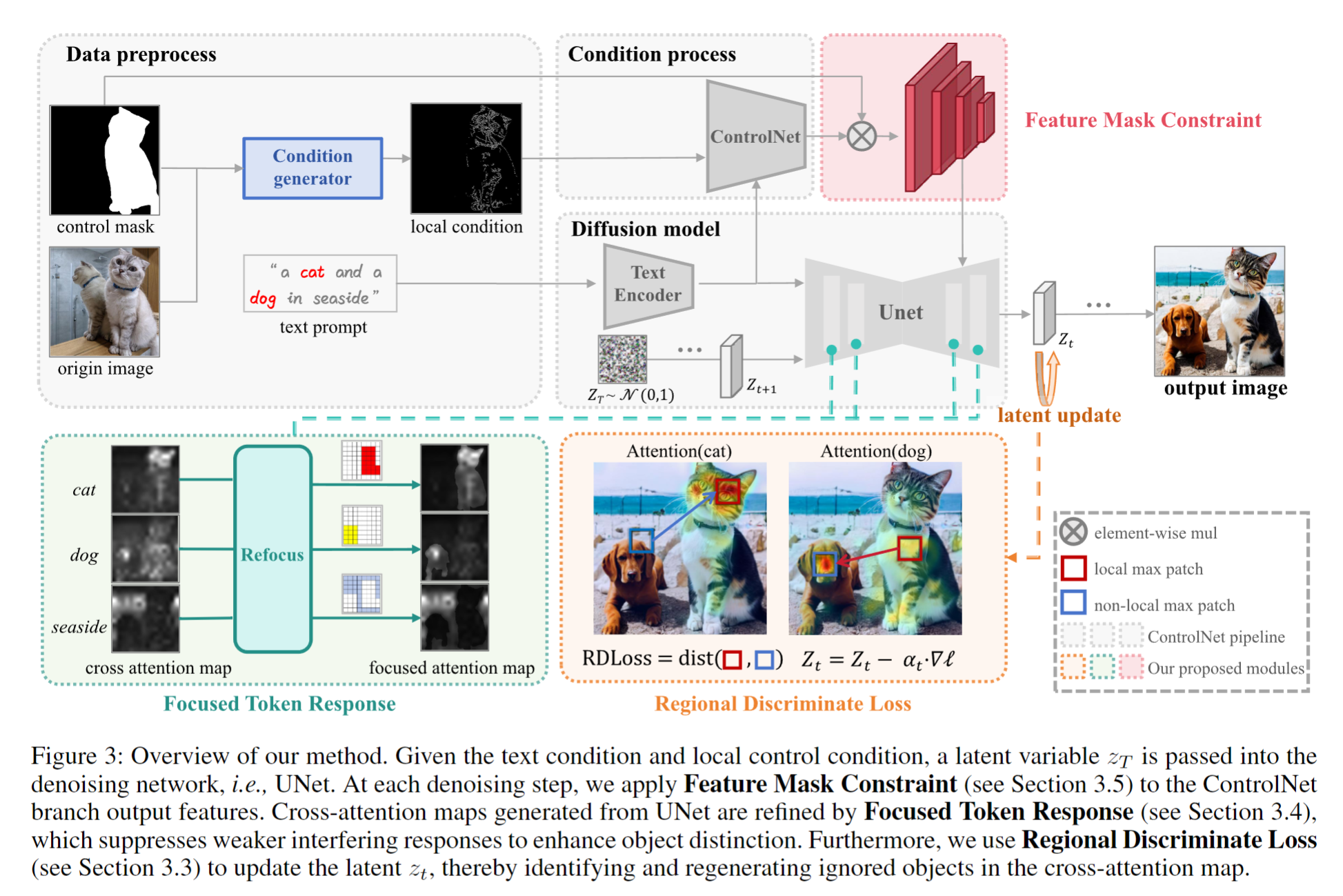
Three inference-stage techniques (Fig. 3):
- Regional Discriminate Loss (RDLoss) (Eq. 5): Maximizes attention discrepancy between local/non-local regions for C control t C_{\text{control}}^t Ccontrolt (Eq. 4), guiding latent updates to regenerate ignored objects.
- Focused Token Response (FTR) (Eq. 8): Suppresses weak attention scores via token-wise max suppression, reducing object duplication.
- Feature Mask Constraint (FMC) (Eq. 9): Applies control mask to ControlNet features, mitigating quality degradation from blank non-control regions.
推理阶段三大技术(图3):
- 区域判别损失(RDLoss)(公式5):通过最大化局部/非局部注意力差异(针对控制概念 C control t C_{\text{control}}^t Ccontrolt,公式4),引导隐变量更新以再生被忽略的对象。例如,对“狗”令牌,强制非控制区域的注意力最大值高于局部(图2右)。
- 聚焦令牌响应(FTR)(公式8):通过令牌维度的最大抑制,削弱弱响应补丁的注意力,减少对象重复。如在“咖啡杯+泰迪熊”场景中,抑制非最大响应的背景令牌(图4)。
- 特征掩码约束(FMC)(公式9):对ControlNet输出施加掩码,避免非控制区域的空白特征干扰。实验显示,FMC使LPIPS降低12.67±1.03(表1)。



04 主要贡献
-
New Task: Defines “local control” as region-specific structural guidance with text prompts (Fig. 1).
-
Training-free Solution: Three modules addressing dominance, duplication, and feature inconsistency without retraining.
-
Empirical Validation: State-of-the-art results on COCO (FID 21.86) and Attend-Condition (CLIP T2T 0.804) datasets, outperforming baselines (Table 1, Fig. 5).
-
新任务定义:提出“局部控制”范式,允许用户指定区域的结构引导(图1),填补了全局控制与局部编辑的空白。
-
零训练方案:三大模块在推理阶段解决主导、重复和特征不一致问题,无需额外训练或数据(第3节)。
-
实证突破:在COCO(FID 21.86)和Attend-Condition(CLIP T2T 0.804)数据集上超越所有基线(表1,图5),例如Inpainting基线的IOU仅0.51,而本文达0.57(表2)。

05 相关研究工作
-
Global Control: ControlNet (Zhang et al. 2023) and T2I-Adapter (Mou et al. 2023) enable global structural guidance but fail in localization (Fig. 5).
-
Compositional Generation: Attend-and-Excite (Chefer et al. 2023) refines attention for multi-concepts, but lacks spatial constraints.
-
Local Editing: Inpainting methods (Lugmayr et al. 2022) post-process global results, leading to inconsistency (Section 4.2).
-
全局控制:ControlNet和T2I-Adapter实现全局结构引导,但无法局部约束(图5中ControlNet生成的“飞机”偏离指定区域)。
-
组合生成:Attend-and-Excite优化多概念注意力,但缺乏空间约束,导致对象重叠(第2节)。
-
局部编辑:修复方法(如Inpainting)后处理全局结果,导致控制区与非控制区不一致(图5右,Inpainting的“桌子”结构模糊)。
06 解决方案实现细节
-
Control Concept Matching (Eq. 4): Select C control t C_{\text{control}}^t Ccontrolt via attention sum in local regions, stabilized by C o u n t max Count_{\text{max}} Countmax for early timesteps ( β = 0.8 \beta=0.8 β=0.8,图8b).

-
RDLoss Update (Eq. 7): Gradient-based latent adjustment using attention max-distance, with α t \alpha_t αt scaling (Section 3.3).

-
FTR Suppression (Eq. 8): Apply γ = 0.1 \gamma=0.1 γ=0.1 to non-max tokens in cross-attention (Fig. 3), reducing patch overlap.
-
FMC Integration (Eq. 9): Mask ControlNet features at UNet blocks, avoiding blank region interference.
-
控制概念匹配(公式4):通过局部区域注意力和选择 C control t C_{\text{control}}^t Ccontrolt,早期步数用 C o u n t max Count_{\text{max}} Countmax稳定(β=0.8最优,图8b)。例如,“猫+狗”场景中,动态选择局部区域主导的概念。
-
RDLoss更新(公式7):基于注意力最大距离的梯度调整隐变量,α_t控制步长(第3.3节)。对非控制令牌(如“海边”),强制非局部注意力最大值高于局部。
-
FTR抑制(公式8):对交叉注意力中非最大令牌施加γ=0.1缩放(图3),减少“咖啡杯”与“泰迪熊”的特征重叠(图4)。
-
FMC集成(公式9):在UNet模块对ControlNet特征加掩码,避免非控制区空白特征导致的伪影(图7c vs f)。
07 实验设计
-
Datasets: COCO-5k (validation) and Attend-Condition (11 object+animal pairs, Section 4.1).
-
Baselines: ControlNet, T2I-Adapter, Noise-Mask (Eq. 10), Feature-Mask, Inpainting.
-
Metrics: FID, CLIP Score (text-image), CLIP T2T (caption-text), IOU (segmentation), LPIPS (local fidelity).
-
Ablation: RDLoss, FTR, FMC on COCO-canny (Table 2).
-
数据集:COCO-5k(验证集)和Attend-Condition(11对物体+动物,第4.1节),如图4的“蛋糕+泰迪熊”场景。
-
基线:ControlNet(全局控制)、T2I-Adapter(轻量控制)、Noise-Mask(掩码噪声混合,公式10)、Feature-Mask(仅FMC)、Inpainting(修复后处理)。
-
指标:FID(图像质量)、CLIP分数(文本-图像对齐)、CLIP T2T(生成描述-原提示对齐)、IOU(分割定位)、LPIPS(局部保真度)。
-
消融:在COCO-canny数据集测试三大模块(表2),验证RDLoss(+0.018 CLIP分数)和FMC(-1.82 FID)的关键作用。
08 实验结果与对比
英文:
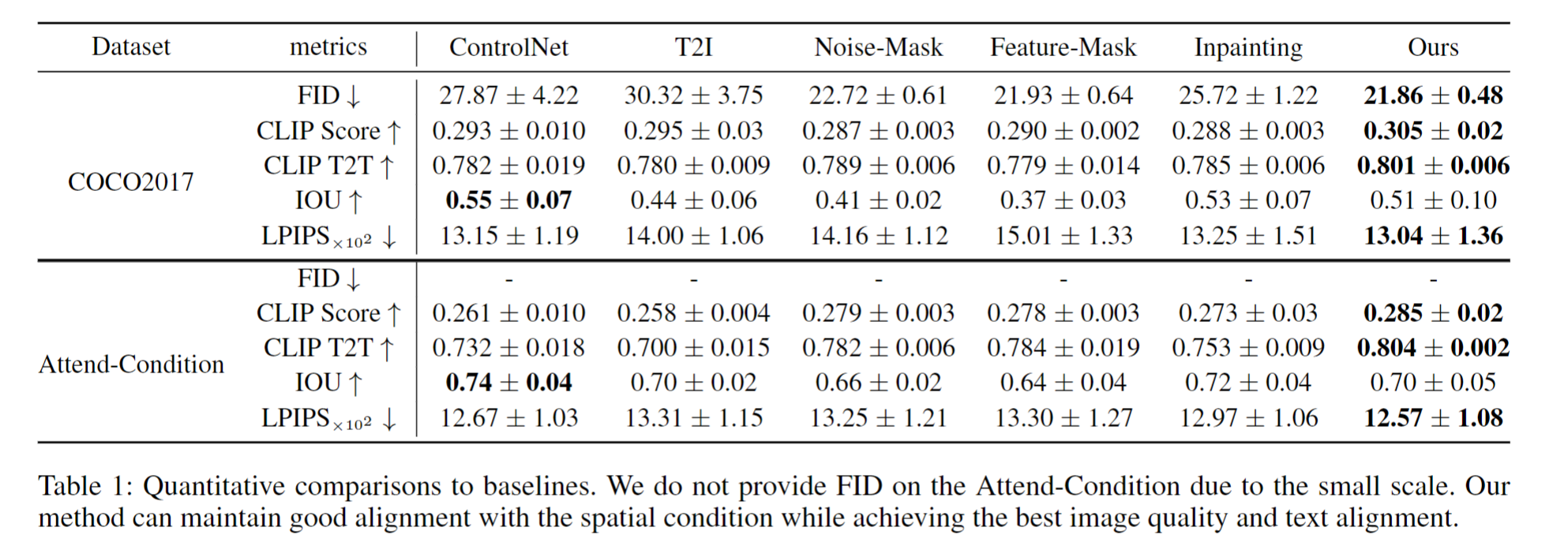
- Quantitative (Table 1): Ours achieves lowest FID (21.86) and highest CLIP T2T (0.801) on COCO, outperforming Inpainting (FID 25.72) and ControlNet (CLIP T2T 0.782).
- Qualitative (Fig. 5-6): Baselines fail in multi-object scenarios (e.g., ControlNet generates only “plane” in “building+plane”), while ours preserves both concepts with structural fidelity.
- Localization (IOU 0.57): Accurate alignment of local conditions (e.g., cat canny in Fig. 1) without leaking to non-control regions.
中文:
- 量化结果(表1):在COCO上,本文FID最低(21.86),CLIP T2T最高(0.801),优于Inpainting(FID 25.72)和ControlNet(CLIP T2T 0.782)。Attend-Condition数据集的CLIP T2T达0.804,远超T2I-Adapter的0.700。
- 定性结果(图5-6):基线在多物体场景失效(如ControlNet仅生成“飞机”忽略“建筑”),本文保留所有概念并保持结构保真。图6中,基线的“青蛙”控制区出现伪影,而本文的“狮子”局部边缘清晰对齐。
- 定位精度(IOU 0.57):局部条件(如图1的猫边缘)准确定位,无泄漏到非控制区。对比Noise-Mask的IOU仅0.37,本文通过FMC显著提升空间一致性。

09 消融研究发现
英文:
- RDLoss (Table 2): Improves CLIP T2T by +0.036 (baseline vs RDLoss+FMC), proving its role in regenerating ignored objects.
- FMC (Fig. 7c vs f): Reduces FID by 1.82 (23.65→21.83) by mitigating feature inconsistency, but slightly lowers IOU (-0.22) due to mask constraint.
- FTR (Table 2): Enhances object distinction, reducing duplication in “train+dog” scenes (Fig. 7d vs f).
中文:
- RDLoss(表2):CLIP T2T提升0.036(基线0.750→RDLoss+FMC 0.802),证明其再生被忽略对象的作用。如图7b(仅RDLoss)的“狗”在非控制区正确生成。
- FMC(图7c vs f):通过减少特征不一致使FID降低1.82(23.65→21.83),但因掩码约束导致IOU轻微下降(-0.22),验证特征约束的必要性。
- FTR(表2):增强对象区分,减少“火车+狗”场景的重复(图7d vs f)。移除FTR后,“海边”的沙滩纹理出现重复斑块。


10 后续优化方向
英文:
- Multi-condition Support: Extend to multi-modal local controls (e.g., depth + edge).
- Real-time Inference: Optimize gradient-based updates (Eq. 7) for faster generation.
- Dynamic Masking: Adaptive mask refinement during denoising, improving boundary fidelity (Fig. 1 control region edges).
- Cross-dataset Generalization: Validate on complex scenes (e.g., cityscapes) beyond COCO.
中文:
- 多条件支持:扩展至多模态局部控制(如深度图+边缘图),解决图4中“蝴蝶”的姿态控制问题。
- 实时推理:优化梯度更新(公式7),当前50步推理需20秒,可探索步长α_t的动态调整。
- 动态掩码:在去噪过程中自适应优化掩码,改善控制区边界保真度(如图1猫的边缘锯齿问题)。
- 跨数据集泛化:在COCO以外的复杂场景(如Cityscapes)验证,解决“建筑+飞机”的尺度一致性(图5)。