大模型交叉研讨课笔记-Transformer架构
概述
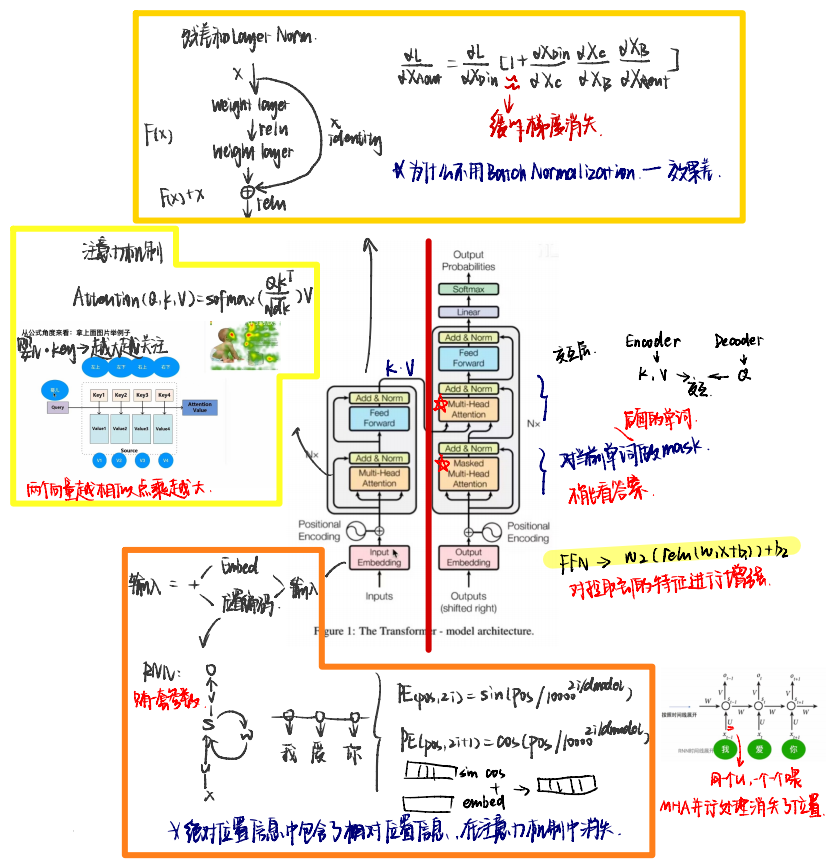
Transformer整体的结构非常清晰,就是把输入通过一堆 Encoder 和 Decoder 层“加工”一下,最后得到输出。具体来说:
-
Encoder: 负责“理解”输入。
它接收原始输入(比如一句中文),通过多层的注意力机制和前馈网络,逐层提取出更深层次的语义信息。 -
Decoder: 负责“生成”输出。
它一边看 Encoder 提取的信息,一边根据当前已生成的内容,逐步生成最终输出(比如一句英文)。
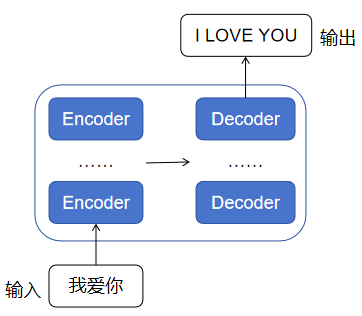
详细来说就是下面的架构图,红色框是Encoder的架构,蓝色框是Decoder的架构:
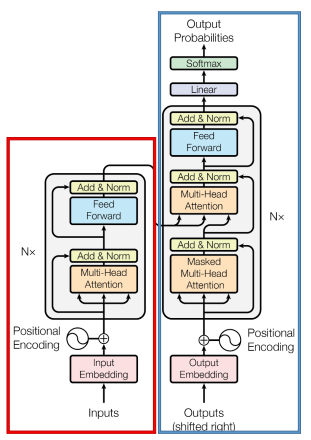
Encoder
Encoder主要包含三个方面:Input、Multi-Head Attention、Feed Forward(FFN)。不过大多数时候FFN就是两个两个线性层中间加上激活函数:FFN(x) = Linear(ReLU(Linear(x))),就不多说了。
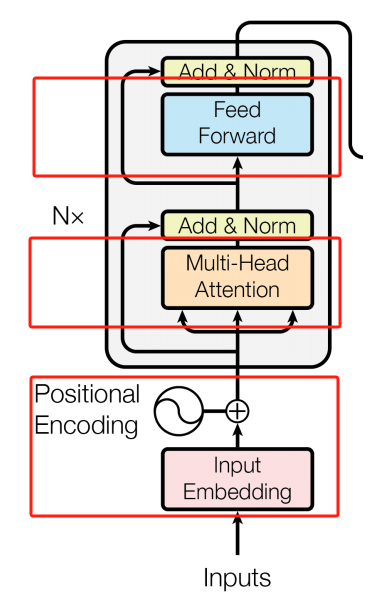
Input Processing
这一部分解决的问题是怎么把输入喂给Transformer——BPE+Positional Encoding,也就是两步走:① 把文字变成“词向量”(BPE);② 告诉模型每个词在句子中的“位置”(PE),最后输入阶段得到的喂给模型的表示为:BPE+PE
BPE:解决“词太多”和“没见过”的问题
自然语言中存在两大难题:
-
太多词:词表太大,难以训练;
-
生僻词:没见过的词,模型处理不了。
为了解决这个问题,Transformer 使用了一种叫 Byte Pair Encoding(BPE) 的技术。本质是:
将词拆成更小的“子词”单位,然后学习最常见的组合。
比如:
-
把
lower,lowest拆成:low+er,low+est -
即使遇到从没见过的词
lowers,也能拆成low+ers,照样处理!
可以把它理解成一种频繁项合并算法,越常出现的组合,越容易被合成一个整体。
Positional Encoding:告诉模型“词在第几位”
Transformer 是并行的,没有像 RNN 那样天然知道“顺序”,所以我们得手动告诉它每个词的位置。这就是 位置编码(Positional Encoding) 的作用,核心思想:
给每个词的向量加上一段“位置向量”,让模型知道它在句子中的位置。
这个位置向量是通过一套公式计算出来的:
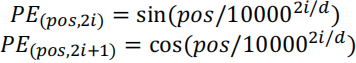
假设我们设定:
-
embedding 维度
d = 4 -
我们看两个位置:
pos = 0(第一个词)和pos = 1(第二个词)
对应的PE公式为:
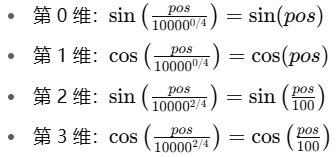
所以不同的位置 pos得到的向量值是完全不同的;而不同维度 i 的值是由不同频率的 sin/cos 控制的。
| POS | PE(POS) |
| 0 | [sin(0), cos(0), sin(0/100), cos(0/100)] = [0, 1, 0, 1] |
| 1 | [sin(1), cos(1), sin(0.01), cos(0.01)] ≈ [0.841, 0.540, 0.01, 0.9999] |
这样做的好处:
- 每个位置都有一个唯一的编码向量;
- 如果你算 PE(1) - PE(0),这个差值向量是有规律的,模型可以利用这种规律去理解词之间的相对距离
Multi-Head Self Attention
输入嵌入处理好之后,Transformer 的核心模块就要开始工作了,要理解“Multi-Head Self Attention”首先从Self Attention开始。
Self-Attention:自己关注自己,理解上下文
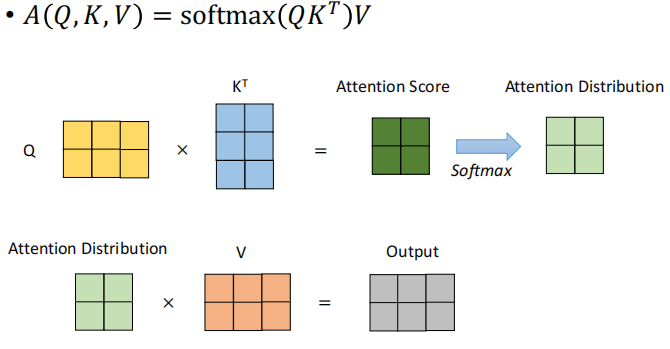
Self-Attention 的本质是:
让一个词,去关注同一句子中其他所有词,计算它们对自己的“重要性”。
我们从输入向量(比如每个词的 embedding)中,经过三个线性变换(也就是通过三个线性层),得到:
-
Q(Query):我要去关注别人
-
K(Key):我是被关注的
-
V(Value):我携带的信息内容
然后计算 Q 和 K 的相似度,得到每个词对其它词的注意力权重(用 Softmax 归一化),最后用这个权重去加权 V,也就是“从别人那学点有用的东西回来”:
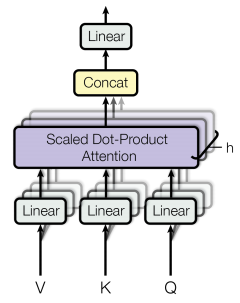
Multi-Head Attention:从多个角度“看世界”
为什么需要多头?
因为一句话中,不同词之间可能存在多种关系,一个注意力头可能只关注其中一个角度。
比如,“The animal didn’t cross the street because it was too tired.”,模型要判断 "it" 指的是 "animal" 还是 "street",这就需要捕捉不同词之间的语义联系。实现多头也很简单,使用不同的线形层生成多组QKV就好了,每组QKV独立做Self-Attention,最后把所有头的输出concat起来,再过一个线形层整合信息。
Decoder
Decoder 的任务是根据 Encoder 编码过的信息,一步步“翻译”出目标序列(比如生成一句英文句子)。每个 Decoder Layer 主要由两个注意力模块:
-
Masked Multi-Head Self-Attention(掩码自注意力)
-
Multi-Head Attention(对 Encoder 输出的注意力)
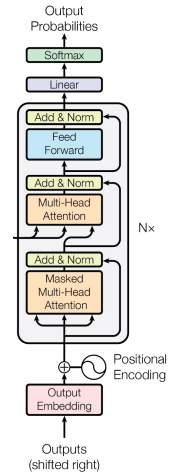
Masked Multi-Head Self-Attention:防止“偷看未来”
在生成句子的过程中,比如我们要生成一句话“I am happy today”,当 Decoder 已经输出了 “I” 和 “am”,此时模型去预测下一个词("happy")时,不应该看到后面还没生成的词(比如 “today”)。所以这一块的重点是:
要保证模型只能基于“已经生成的词”做预测,不能“未卜先知”。
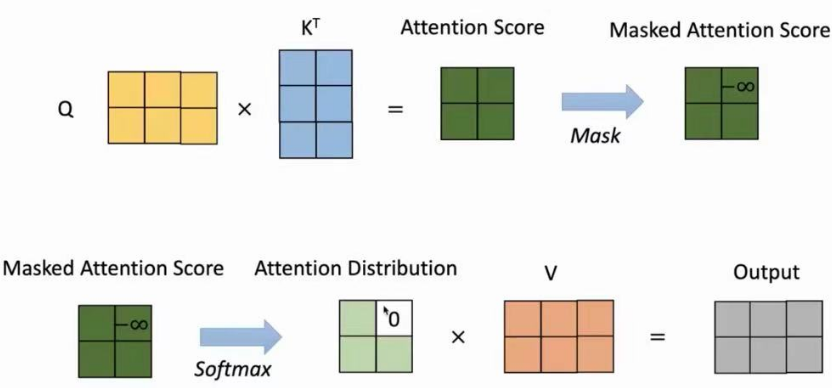
要实现“防偷看”就用到了课程里面提到的“下三角的掩码矩阵”,举个例子:
位置: 0 1 2 3
Mask矩阵:[[1, 0, 0, 0],[1, 1, 0, 0],[1, 1, 1, 0],[1, 1, 1, 1]]
每一行表示第几个词,这个mask矩阵就表示第 t 个位置的词,只能看到 0~t 的内容,不能看未来的位置。
技术上是:对 QK 相乘后的矩阵,给“未来位置”加一个很大的负数(比如 -1e9),经过 softmax 后这些位置权重就接近于 0 了。
Multi-Head Attention:从 Encoder 获取输入信息
其实到这里就已经能实现生成文字了,为什么还需要一个注意力模块呢?因为Masked Self-Attention 只处理“自己已经生成的部分”,但生成新词还需要结合源句子的意思(Encoder 输出)。比如:输入是中文“我很高兴”,Decoder 已经生成了“I am”,那要生成 “happy” 时,必须参考“高兴”这个词对应的 Encoder 信息。
-
Decoder 的当前输出作为 Query (Q);
-
Encoder 的输出作为 Key (K) 和 Value (V);
-
做一次标准的 Attention,计算 Decoder 生成词与 Encoder 中所有位置的相关性,然后加权获得信息。
拓展:Vision Transformer
视觉领域的Transformer框架和大语言模型基本相同,变化最大的地方就是Input Processing部分,是由计算机视觉领域针对图片的两个操作:Patch embed 和 Positional Encoding(不变),也就一个是将文本转化成embedding,一个是将图片转化为embedding。