Windows部署LatentSync唇形同步(字节跳动北京交通大学联合开源)
#工作记录
一、前言
LatentSync:基于音频驱动的端到端唇形同步框架
LatentSync是由ByteDance开源的一个先进唇形同步框架,旨在通过音频条件驱动的潜在扩散模型实现高精度的唇形同步。与传统基于像素空间扩散或两阶段生成的方法不同,LatentSync采用端到端架构,直接利用Stable Diffusion的强大生成能力建模复杂的音频-视觉关联,避免了中间运动表征的冗余计算。
针对扩散模型在时间一致性上的不足,项目创新性地提出了时间表示对齐(TREPA)机制。该机制通过大规模自监督视频模型提取的时间特征,将生成帧与真实帧在时间维度上对齐,有效解决了传统方法因扩散过程不一致导致的时序抖动问题,同时保持唇形同步的高准确性。
在技术实现上,LatentSync利用Whisper提取音频梅尔频谱并转换为嵌入向量,通过交叉注意力机制融入U-Net网络。训练阶段采用一步法从预测噪声中恢复清晰潜在表示,并结合TREPA、LPIPS和SyncNet损失进行多目标优化。项目还提供了一套完整的数据处理流程,包括视频分帧、人脸对齐、质量控制等步骤,确保训练数据的可靠性。
此外,LatentSync开源了预训练模型(如SyncNet、U-Net)及推理脚本,支持通过Gradio界面或命令行快速部署。用户可灵活调整参数(如推理步数、引导系数)以平衡生成速度与质量。项目在真实感视频和动漫角色上均展示了出色的同步效果,为虚拟人、动画制作等领域提供了高效解决方案。
关键词:唇形同步、扩散模型、时间一致性、Stable Diffusion、音频驱动
GitHub项目开源地址:
bytedance/LatentSync: Taming Stable Diffusion for Lip Sync!
二、部署流程
(一)克隆项目
推荐用GitHub Desktop进行稳定克隆:
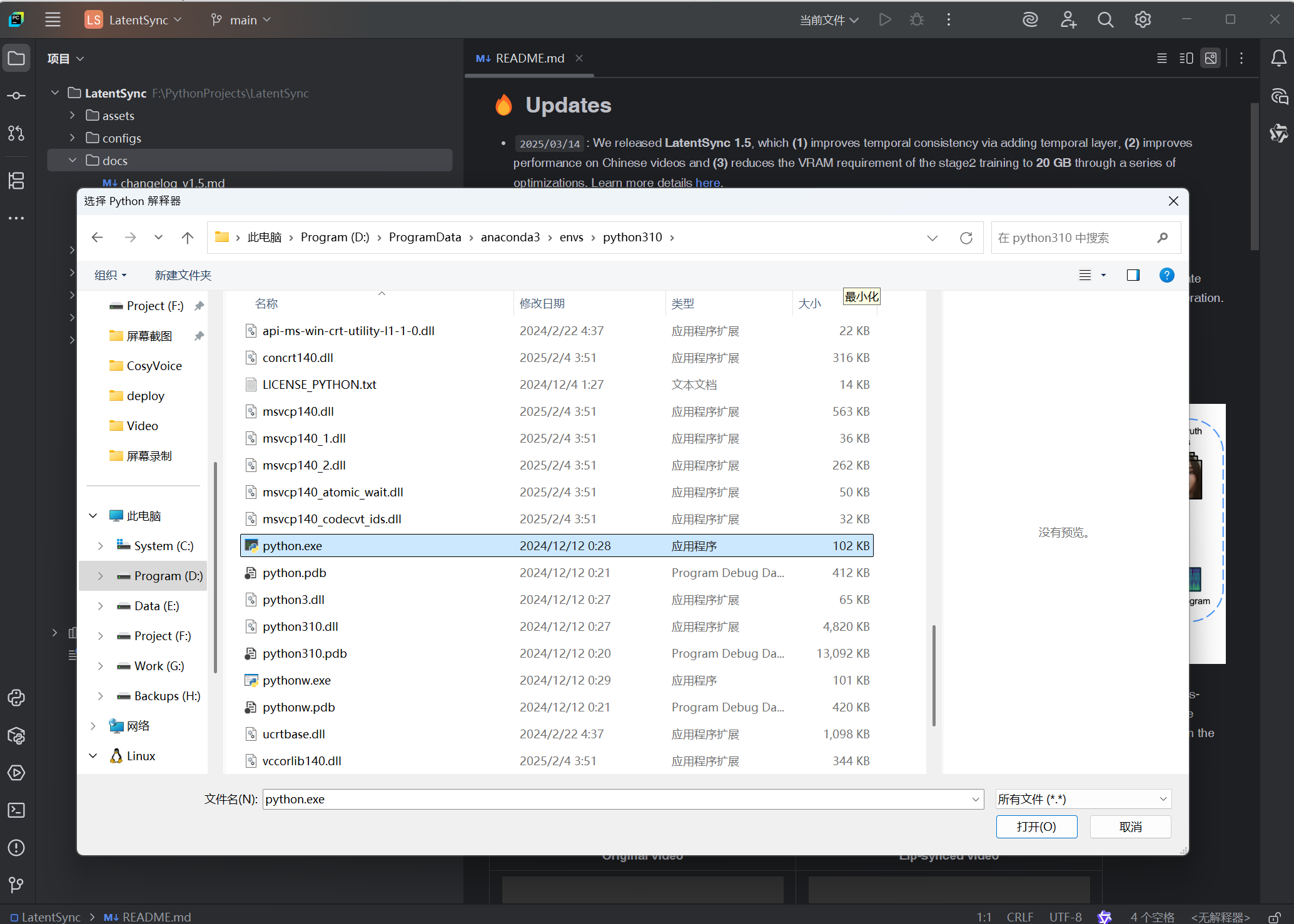
(二)创建虚拟环境
克隆后进入项目文件夹,用PyCharm打开进入环境创建流程
python=3.10
(三)升级pip等构建工具
配置并进入虚拟环境,运行:
python -m pip install --upgrade pip setuptools wheel
(四)修改requirements.txt
打开requirements.txt文件,在第2行后增加一行,加入:
torchaudio==2.5.1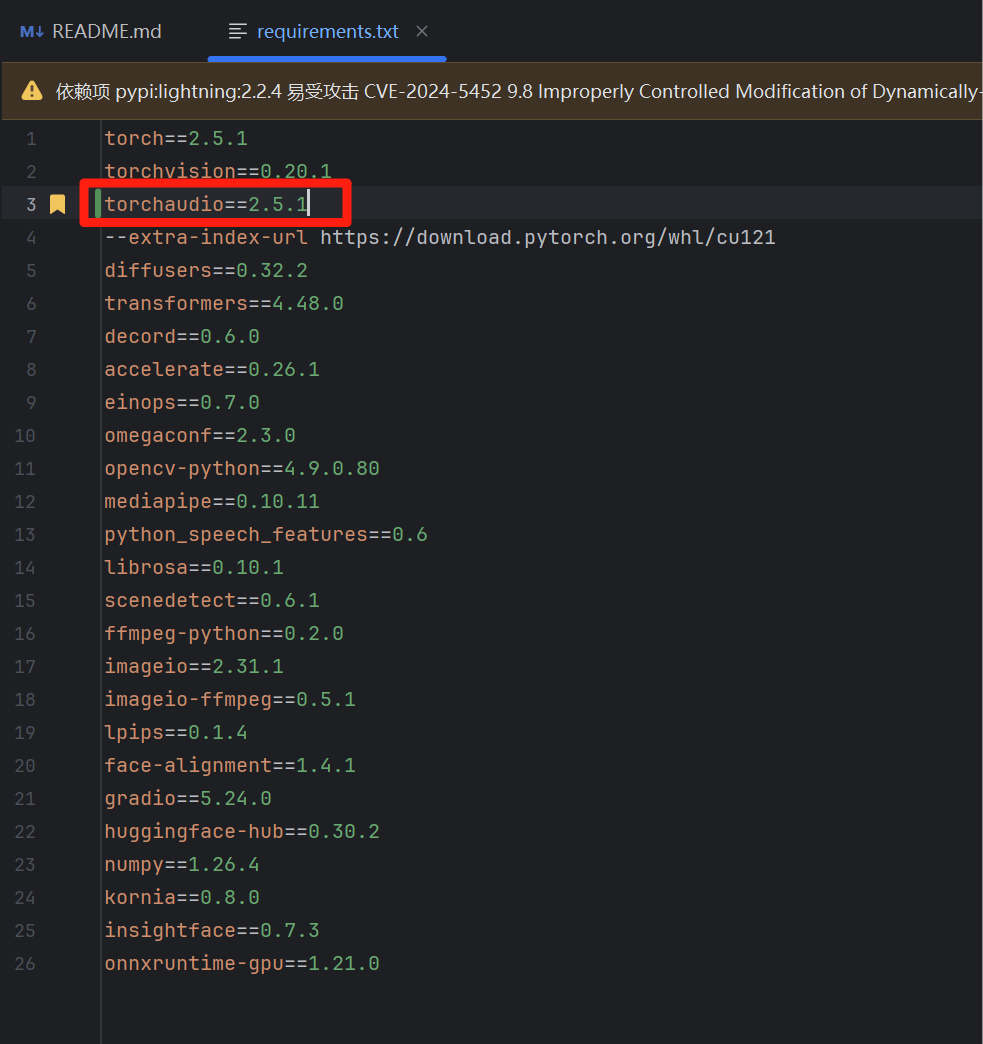
“100% 成功的 PyTorch CUDA GPU 支持” 安装攻略_安装pytorch支持cuda-CSDN博客
(五)安装依赖
pip install -r requirements.txt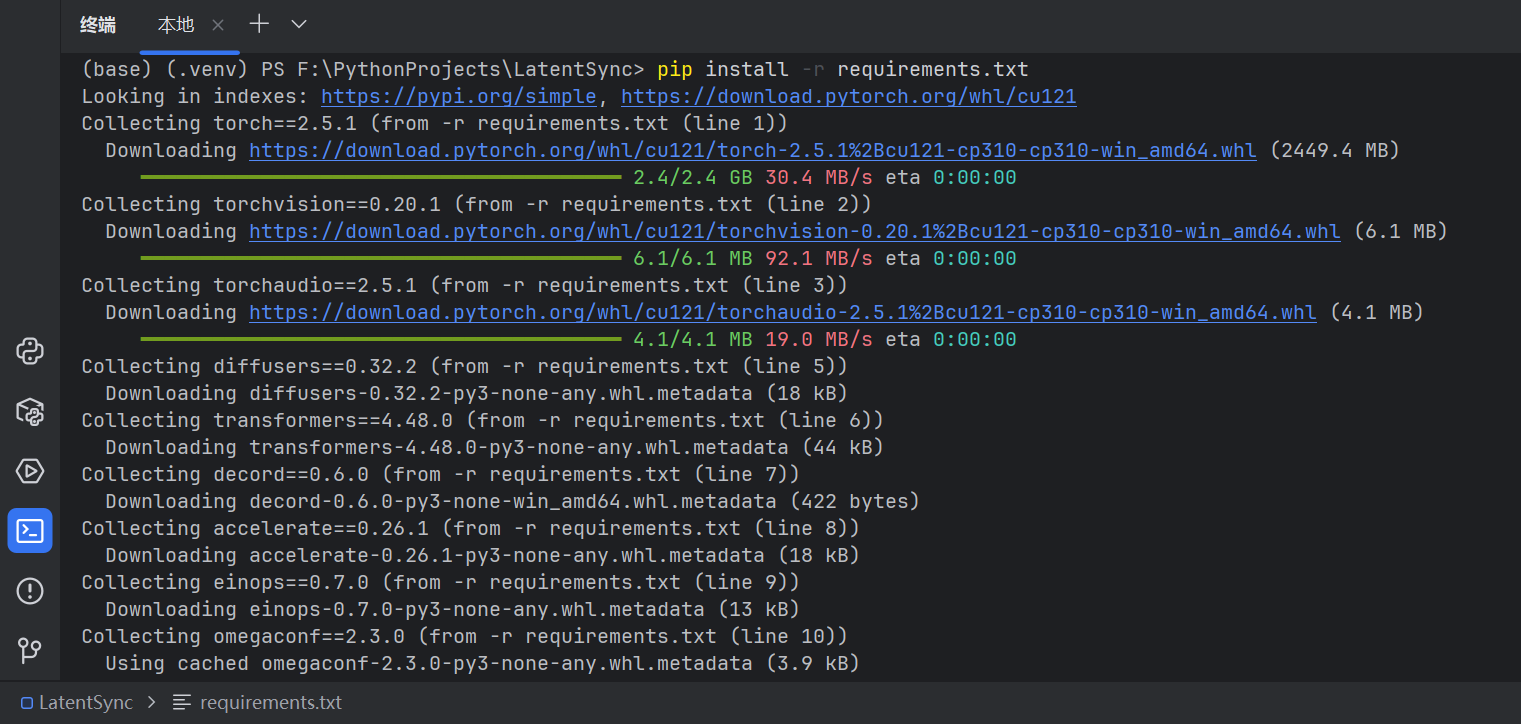

安装后需要验证PyTorch的 CUDA GPU支持 :
import torch # 导入 PyTorch 库print("PyTorch 版本:", torch.__version__) # 打印 PyTorch 的版本号# 检查 CUDA 是否可用,并设置设备("cuda:0" 或 "cpu")
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("设备:", device) # 打印当前使用的设备
print("CUDA 可用:", torch.cuda.is_available()) # 打印 CUDA 是否可用
print("cuDNN 已启用:", torch.backends.cudnn.enabled) # 打印 cuDNN 是否已启用# 打印 PyTorch 支持的 CUDA 和 cuDNN 版本
print("支持的 CUDA 版本:", torch.version.cuda)
print("cuDNN 版本:", torch.backends.cudnn.version())# 创建两个随机张量(默认在 CPU 上)
x = torch.rand(5, 3)
y = torch.rand(5, 3)# 将张量移动到指定设备(CPU 或 GPU)
x = x.to(device)
y = y.to(device)# 对张量进行逐元素相加
z = x + y# 打印结果
print("张量 z 的值:")
print(z) # 输出张量 z 的内容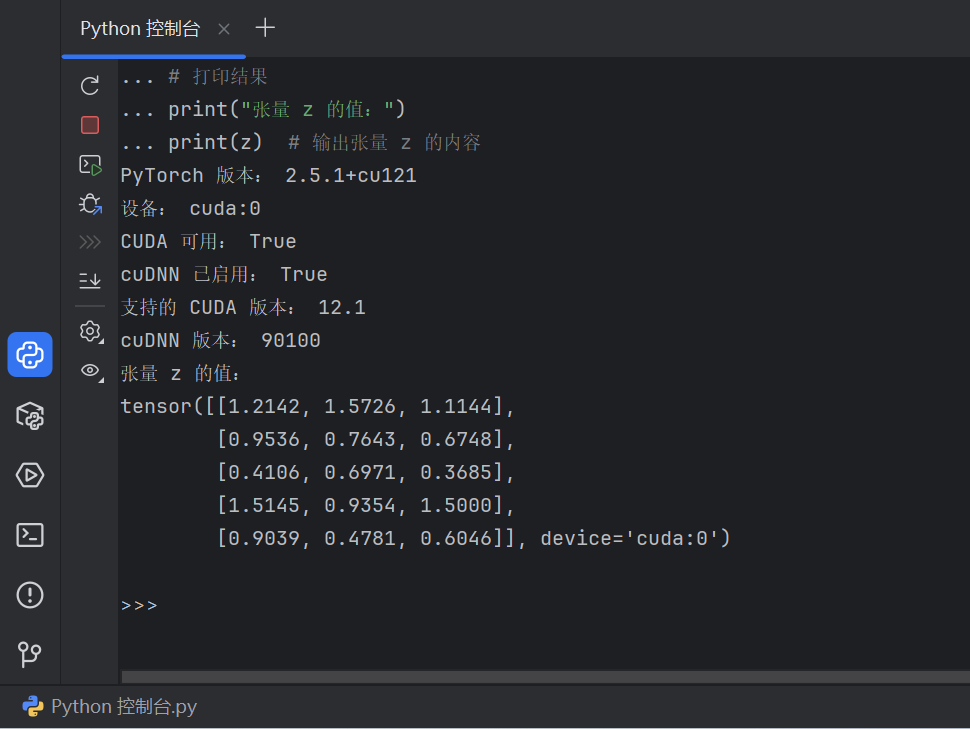
(六)下载模型
1、创建模型文件夹
checkpoints2、下载模型
huggingface-cli download ByteDance/LatentSync-1.5 whisper/tiny.pt --local-dir ./checkpoints
huggingface-cli download ByteDance/LatentSync-1.5 latentsync_unet.pt --local-dir ./checkpoints
(七)运行测试
python gradio_app.py
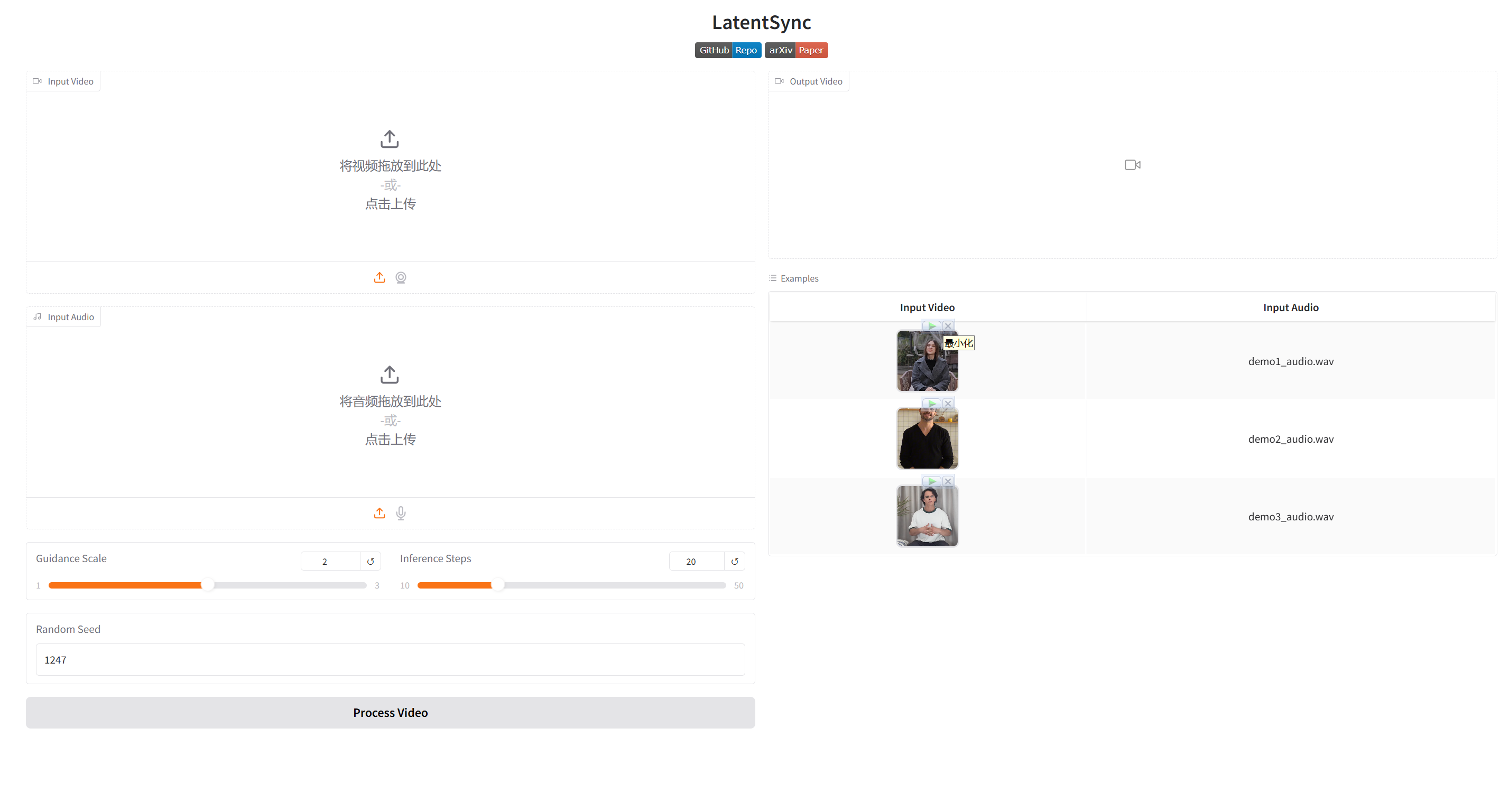
选中一个示例(视频+音频)进行测试:
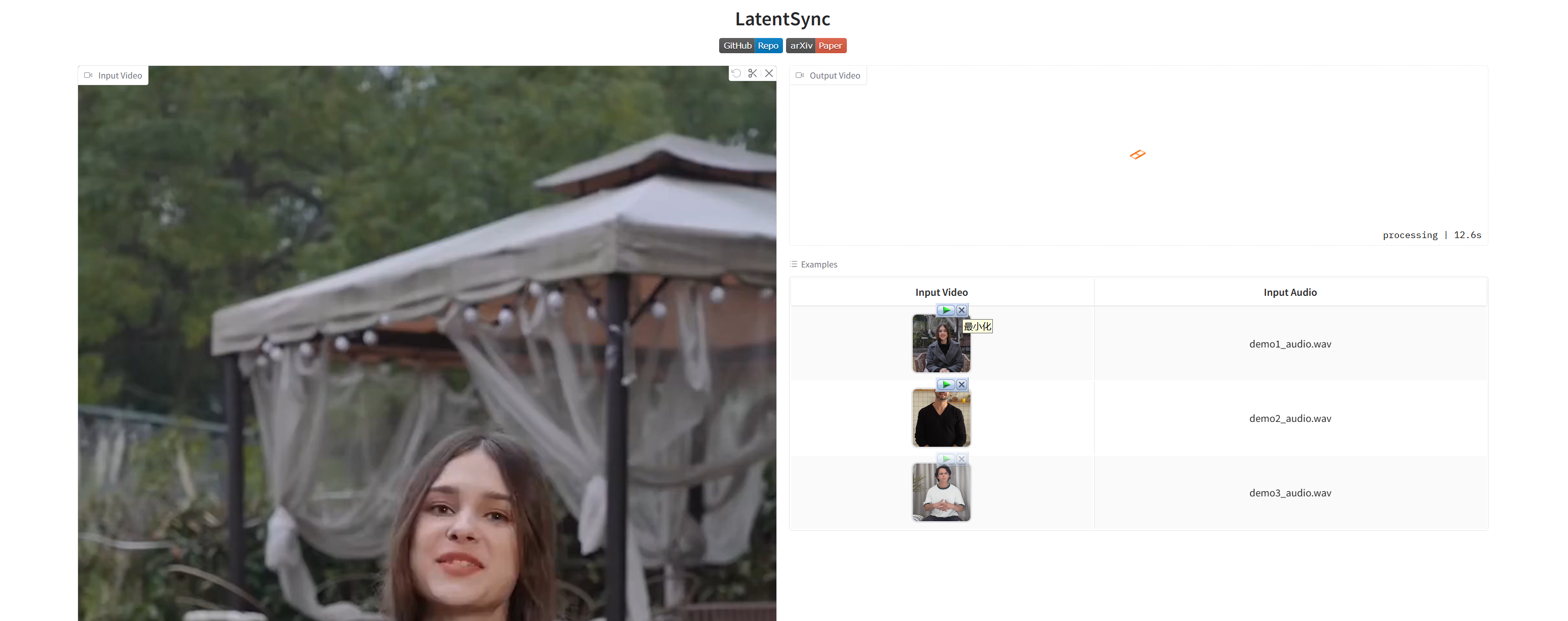




三、总结与展望
LatentSync 本地部署总结与展望
一、本地部署总结
-
环境配置
- Linux系统可以通过
setup_env.sh脚本可一键安装依赖项并下载预训练模型(如latentsync_unet.pt和whisper/tiny.pt),降低了部署门槛。 - 项目依赖 PyTorch 和相关深度学习库,建议配置 6.5GB 显存 GPU 以流畅运行推理任务。
- Linux系统可以通过
-
推理方式
- 提供 Gradio 可视化界面(
gradio_app.py)和 命令行脚本(inference.sh)两种推理方式,满足不同用户需求。 - 支持调整关键参数(如
inference_steps和guidance_scale),便于优化生成效果。
- 提供 Gradio 可视化界面(
-
数据处理
- 数据处理管道(
data_processing_pipeline.sh)涵盖视频分帧、人脸对齐、质量过滤等步骤,确保输入数据符合模型要求。 - 预处理后的数据存储在
high_visual_quality目录,便于后续训练和推理。
- 数据处理管道(
-
模型训练
- 支持 U-Net 和 SyncNet 的独立训练,提供预训练 SyncNet(VoxCeleb2 上 94% 准确率)以加速 U-Net 训练。
- 训练脚本(
train_unet.sh/train_syncnet.sh)允许自定义数据路径和超参数,灵活性较高。
-
评估与优化
- 提供 SyncNet 同步置信度评估脚本(
eval_sync_conf.sh),量化模型性能。 - 支持 LPIPS 和 SyncNet 损失优化,提升唇形同步精度和时序一致性。
- 提供 SyncNet 同步置信度评估脚本(
总结:LatentSync 的本地部署流程清晰,文档完善,适合研究者和开发者快速上手。其端到端架构和 TREPA 机制在唇形同步任务上表现出色,但仍存在一定的硬件门槛(需 GPU 支持)。
二、未来展望
-
轻量化优化
- 探索模型量化(如 INT8/FP16)或蒸馏技术,降低显存占用,适配消费级 GPU 或 CPU 推理。
- 研究更高效的扩散过程优化(如 DDIM 加速采样),减少推理时间。
-
多模态扩展
- 支持更多音频输入格式(如实时麦克风输入),增强交互性。
- 探索跨语言唇形同步能力,提升国际化应用潜力。
-
数据增强与鲁棒性提升
- 引入更多样化的训练数据(如不同口型、语速、情感表达),增强模型泛化能力。
- 优化人脸检测和对齐模块,提升遮挡、侧脸等复杂场景的鲁棒性。
-
开源社区协作
- 提供更详细的训练日志和可视化工具(如 TensorBoard 集成),方便用户调试。
- 鼓励社区贡献新功能(如动漫风格适配、语音驱动全身动画),拓展应用场景。
-
商业化应用探索
- 结合虚拟主播、智能客服等场景,推动唇形同步技术的落地应用。
- 探索与 AR/VR 技术结合,提升虚拟人交互体验。
展望:LatentSync 在唇形同步领域已取得显著成果,未来通过轻量化、多模态扩展和社区协作,有望成为虚拟人、动画制作等领域的标准工具,进一步推动 AI 生成内容(AIGC)的发展。