MCP-RAG 服务器:完整设置和使用指南
在快速发展的人工智能应用时代,结合静态领域知识和实时网络信息的系统需求比以往任何时候都更加迫切。传统的检索增强生成(RAG)模型通常依赖于预先索引的数据,这限制了它们对新发展的反应能力。MCP-RAG Server通过将基于语义的向量搜索(通过Qdrant)与实时网页搜索能力(通过Scrapeless)集成,弥补了这一差距,为智能问答系统提供了一个生产就绪的基础。无论您是构建内部知识代理的企业,还是正在实验LLM集成的开发人员,本指南将带您完成MCP-RAG的完整设置和使用——确保您能够部署一个现代化、响应灵敏的人工智能知识系统。
什么是MCP-RAG Server?
MCP-RAG Server是一个基于TypeScript的系统,结合了向量搜索能力和实时网络搜索,以创建增强的人工智能知识系统。它提供三个主要工具:
- 机器学习常见问题检索 - 通过您的向量数据库进行语义搜索
- 文档添加 - 使用新信息扩展知识库
- 网络搜索 - 从互联网上获取当前信息
该系统解决了关键的AI局限性:过时的知识、缺乏领域专长和低效的信息检索。
Scrapeless介绍:RAG的网页智能增强引擎
Scrapeless Google搜索抓取API是一个强大的网页抓取API,提供稳定的搜索引擎结果访问,而无需担心被传统爬虫阻塞。
为什么Scrapeless对RAG系统至关重要
传统的RAG系统受限于它们的静态知识库。Scrapeless通过以下方式转变了MCP-RAG Server:
- 实时信息检索:访问最新的网页信息
- 知识库增强:持续用当前数据更新您的向量数据库
- 补充搜索:在内部知识不足时填补空白
- 多元视角:从不同地理区域和语言中搜索
Scrapeless在MCP-RAG中的工作原理是什么?
Scrapeless通过TypeScript封装类ScrapelessClient与MCP-RAG Server集成,以实现以下功能:
Copy
export class ScrapelessClient {private api: AxiosInstance;constructor(config: ScrapelessConfig) {this.api = axios.create({baseURL: config.baseURL,headers: {"Content-Type": "application/json","x-api-token": config.token,},});}async searchWeb(params: WebSearchParams) {try {const response = await this.api.post("/api/v1/scraper/request", {actor: "scraper.google.search",input: {q: params.query,gl: params.country || "us",hl: params.language || "en",google_domain: params.domain || "google.com"}});return {query: params.query,results: response.data};} catch (error) {// 错误处理...}}
}支持的高级功能
| 功能 | 描述 |
|---|---|
| Google搜索集成 | 使用scraper.google.search角色获取搜索结果 |
| 地理目标定位 | 使用gl参数控制国家/地区 |
| 多语言支持 | 使用hl参数以不同语言返回结果 |
| 搜索引擎域名切换 | 支持多个域名,如google.de、google.fr等 |
| 代理自动管理 | 默认启用代理轮换以避免IP阻塞 |
智能问答系统部署指南(基于向量搜索 + 实时网页搜索)
第1步:初始化项目结构并安装依赖
克隆并设置项目:
Copy
git clone git@github.com:scrapeless-ai/mcp-rag-server.git
cd mcp-rag-server分析项目结构:
Copy
mcp-rag-server/
├── src/
│ ├── config.ts
│ ├── index.ts
│ ├── server.ts
│ ├── qdrant-client.ts
│ └── scrapeless-client.ts
├── package.json
├── tsconfig.json
└── .env安装依赖:
Copy
npm install💡解决的问题:
确保TypeScript项目环境已准备就绪,必要的依赖(如@modelcontextprotocol/sdk、axios、zod等)已集成,并且开发所需的类型定义也已自动配置。
第2步:环境配置
创建.env文件:
Copy
QDRANT_URL=http://localhost:6333
QDRANT_API_KEY=
QDRANT_COLLECTION=ml_faq_collection
SCRAPELESS_KEY=你的_scrapeless_api_key
SCRAPELESS_BASE_URL=https://api.scrapeless.com 理解配置(来自 config.ts):
Copy
const QDRANT_URL = process.env.QDRANT_URL?.trim() || "http://localhost:6333";
const QDRANT_API_KEY = process.env.QDRANT_API_KEY?.trim() || "";
const QDRANT_COLLECTION = process.env.QDRANT_COLLECTION?.trim() || "ml_faq_collection";
const SCRAPELESS_KEY = process.env.SCRAPELESS_KEY?.trim();
const SCRAPELESS_BASE_URL = process.env.SCRAPELESS_BASE_URL?.trim() || "https://api.scrapeless.com";💡问题解决:
提供外部依赖项的正确连接参数(Qdrant 向量数据库和 Scrapeless 实时搜索)。配置代码中内置了默认值和 trim() 处理以防止变量格式错误。如果缺少 Scrapeless 密钥,将发出警告。
第 3 步:设置 Qdrant 向量数据库
使用 Docker 启动 Qdrant:
Copy
# 拉取 Qdrant 镜像
docker pull qdrant/qdrant # 运行具有数据持久性的 Qdrant 容器
docker run -d \ --name qdrant-server \ -p 6333:6333 \ -p 6334:6334 \ -v $(pwd)/qdrant_storage:/qdrant/storage \ qdrant/qdrant 创建 FAQ 向量集合:
Copy
curl -X PUT 'http://localhost:6333/collections/ml_faq_collection' \ -H 'Content-Type: application/json' \ --data-raw '{ "vectors": { "size": 1536, "distance": "Cosine" } }' 💡问题解决:
配置语义向量检索存储,使用 1536 维和余弦相似度,并与嵌入生成器输出和 QdrantClient 调用兼容。
第 4 步:集成 Scrapeless 实时网页搜索
获取 Scrapeless API 密钥:
- 访问 Scrapeless 并创建一个帐户
- 从仪表板中检索您的 API 令牌
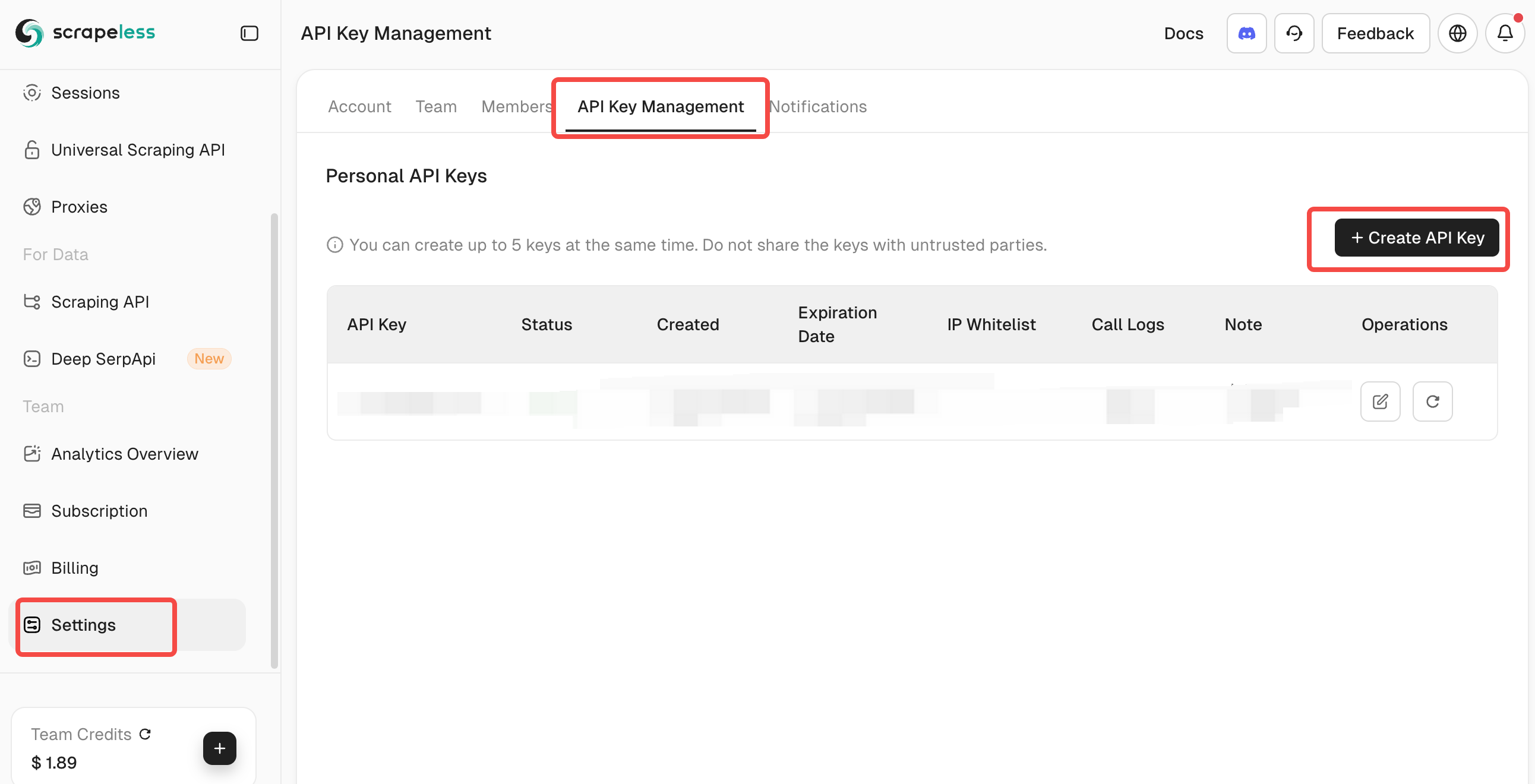
- 将其添加到 .env 文件下的 SCRAPELESS_KEY
测试 Scrapeless 连接:
Copy
# 测试 API 连接(可选)
curl -X POST 'https://api.scrapeless.com/api/v1/scraper/request' \ -H 'Content-Type: application/json' \ -H 'x-api-token: YOUR_API_KEY' \ -d '{"actor": "scraper.google.search", "input": {"q": "test query"}}' 问题解决:此步骤确保 Scrapeless API 正确配置。系统包括验证以检查 API 密钥是否已设置,防止在网页搜索期间出现运行时错误。
第 5 步:构建 TypeScript 项目
将 TypeScript 编译为 JavaScript:
Copy
npm run build 构建期间发生的事情(来自 package.json):
languageCopy
{ "scripts": { "build": "tsc && chmod 755 build/index.js", "start": "node build/index.js" }
} 验证构建输出:
languageCopy
ls build/
# 应显示:index.js, server.js, config.js, qdrant-client.js, scrapeless-client.js 问题解决:
此步骤将 TypeScript 编译为 JavaScript,并确保主入口点可执行。构建过程输出与 Node.js 兼容的 ES 模块(如 package.json 中所指定的 "type": "module")。
第 6 步:启动 MCP 服务器
languageCopy
运行服务器:
npm start 启动期间发生的事情(来自 index.ts):
Copy
async function main() { try { console.log("启动 MCP Agentic RAG 服务器..."); const transport = new StdioServerTransport(); await server.connect(transport); console.log("MCP 服务器正在端口 8080 上运行"); } catch (error) { console.error("main() 中的致命错误:", error); process.exit(1); }
} 问题解决:
此步骤启动 MCP 服务器,使用 STDIO 传输进行通信。服务器以适当的错误处理和日志记录进行初始化。
通过遵循上述六个步骤,您将构建一个具有以下功能的 AI 驱动问答系统:
- 语义问答能力(由 Qdrant 向量数据库提供支持)
- 实时网页增强(通过 Scrapeless API 集成)
- LLM 准备就绪的基础设施(基于 MCP 协议标准)
这为企业或开发人员快速部署生产就绪的 RAG(检索增强生成)系统打下了坚实的基础。
核心组件的详细说明
QdrantClient:向量处理引擎
QdrantClient 提供嵌入生成和向量数据库交互功能。示例使用一种简单的确定性嵌入方法进行演示:
Copy
private generateEmbedding(text: string): number[] { const seed = [...text].reduce((sum, char) => sum + char.charCodeAt(0), 0) % 10000; const vector: number[] = []; let value = seed; for (let i = 0; i < 1536; i++) { value = (value * 48271) % 2147483647; vector.push((value / 2147483647) * 2 - 1); } return vector;
} 主要特点:
- 简单的确定性嵌入生成
- 添加文档的 Upsert 操作
- 具有可配置评分阈值的语义搜索
- 合适的错误处理和后备响应
ScrapelessClient:网络搜索引擎接口
ScrapelessClient 访问 Scrapeless API 以实现网络搜索,并支持高级搜索参数:
Copy
async searchWeb(params: WebSearchParams) {try {if (!this.api.defaults.headers.common["x-api-token"]) {throw new Error("Scrapeless API 密钥未设置");}const response = await this.api.post("/api/v1/scraper/request", {actor: "scraper.google.search",input: {q: params.query,gl: params.country || "us",hl: params.language || "en",google_domain: params.domain || "google.com"}});return {query: params.query,results: response.data};} catch (error) {// 错误处理...}
}主要特点:
- 通过 Scrapeless 集成谷歌搜索
- 可配置的国家、语言和域名
- 全面的错误处理
- API 密钥验证
MCP 服务器工具
server.ts 文件定义了三个主要工具:
- machine-learning-faq-retrieval:
- 在向量数据库中搜索 ML 概念
- 使用语义相似度匹配
- 返回带有分数的格式化结果
- add-document-to-faq:
- 向知识库添加新文档
- 支持元数据(类别、来源、标签)
- 适当的错误处理,提供详细响应
- scrapeless-web-search:
- 通过 Scrapeless API 执行网络搜索
- 可配置的搜索参数
- 实时信息检索
使用指南:使用 Scrapeless 系统
基本用法示例
搜索知识库:
使用 machine-learning-faq-retrieval 查找关于神经网络的信息添加新信息:
使用 add-document-to-faq 添加以下内容:
文本:“随机森林是集成学习方法…”
类别:“集成方法”
标签:[“随机森林”,“集成学习”]通过 Scrapeless 搜索网络:
使用 scrapeless-web-search 查找 AI 的最新进展高级 Scrapeless 用法:
使用 scrapeless-web-search,参数如下:
查询:“最新的 PyTorch 特性”
国家:“uk”
语言:“en”
域名:“google.co.uk”与 Scrapeless 集成的高级工作流程
知识库增强:
1. 使用 scrapeless-web-search 查找“最新的变压器模型2024”
2. 使用 add-document-to-faq 添加相关发现
3. 使用 machine-learning-faq-retrieval 验证信息是否可搜索信息验证:
1. 使用 machine-learning-faq-retrieval 检查现有知识
2. 使用 scrapeless-web-search 查找当前信息
3. 对比并相应更新知识库多语言知识构建:
1. 使用 scrapeless-web-search 的 country="de" 和 language="de" 查找德国的 AI 研究
2. 使用 add-document-to-faq 添加翻译摘要
3. 构建多语言知识库与 Claude Desktop 集成
该项目包括 Claude Desktop 集成的示例配置:
{"mcpServers": {"MCP-RAG-app": {"command": "node","args": ["your-path/to/build/index.js"],"host": "127.0.0.1","port": 8080,"timeout": 30000,"env": {"QDRANT_URL": "http://localhost:6333","QDRANT_API_KEY": "","QDRANT_COLLECTION": "ml_faq_collection","SCRAPELESS_KEY": "SCRAPELESS_KEY"}}}
}常见问题及解决方案
- 构建错误:
- 确保 Node.js 版本 >= 18
- 检查 TypeScript 编译:npx tsc --noEmit
- 运行时错误:
- 验证 Qdrant 是否正在运行:curl http://localhost:6333/health
- 检查环境变量是否正确设置
- 确保 Scrapeless API 密钥有效
- Scrapeless 特定问题:
- 验证 API 密钥是否在环境中正确设置
- 检查 Scrapeless 控制面板中的 API 配额和限制
- 确保正确配置 API 端点
- 连接问题:
- 验证端口是否可用(Qdrant 的端口为 6333)
- 检查防火墙设置
- 确保 Docker 容器正在运行
组合系统的好处
Scrapeless 与 Qdrant 的集成创建了一个强大的混合系统:
- 静态 + 动态知识:将您的策划知识库与实时网络数据相结合
- 智能搜索:对内部数据使用语义搜索,对网络内容使用关键字搜索
- 持续增强:自动更新您的知识库,提供新信息
- 全球视角:获取来自不同地区和语言的信息
- 可靠性:Scrapeless 确保稳定的网络访问而无阻塞问题
结论
MCP-RAG 服务器与 Scrapeless 实现了一个高度可扩展、实时更新的智能问答系统。其核心价值包括:
- 语义理解:通过向量相似度理解上下文
- 实时信息访问:访问 Scrapeless 获取最新 web 内容
- 标准协议集成:使用 MCP 协议,轻松连接到 Claude 等平台
- 灵活配置:可定制的知识库集合和搜索工具
- 面向未来的智能平台:支持动态知识增强、多语言支持和网络智能爬取。
Scrapeless的加入使系统不再仅仅是一个静态的知识库,而是一个具有全球视野和持续学习能力的AI知识引擎。