进阶关卡 - 第4关 - InternVL 多模态模型部署微调实践
一 【环境配置】
1.1 开发机配置
镜像:Cuda12.2-conda
资源配置:50% A100 * 1
1.2 训练环境配置
1. 新建虚拟环境,输入:
conda create --name InternVL-xtuner python=3.10 -y
conda activate InternVL-xtuner
2. 安装与deepspeed集成的xtuner和相关包,输入:
pip install xtuner==0.1.23 timm==1.0.9
pip install 'xtuner[deepspeed]'
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
pip install transformers==4.39.0 tokenizers==0.15.2 peft==0.13.2 datasets==3.1.0 accelerate==1.2.0 huggingface-hub==0.26.5
1.3 推理环境配置
配置推理环境,输入:
conda create -n InternVL-lmdeploy python=3.10 -y
conda activate InternVL-lmdeploy
pip install lmdeploy==0.6.1 gradio==4.44.1 timm==1.0.9
二 【LMDeploy部署InternVL】
2.1 lmdeploy推理核心代码及基本用法了解
#我们主要通过pipeline.chat 接口来构造多轮对话管线,核心代码如下:
【
## 1.导入相关依赖包
from lmdeploy import pipeline, TurbomindEngineConfig, GenerationConfig
from lmdeploy.vl import load_image
## 2.使用你的模型初始化推理管线
model_path = "your_model_path"
pipe = pipeline(model_path,
backend_config=TurbomindEngineConfig(session_len=8192))
## 3.读取图片(此处使用PIL读取也行)
image = load_image('your_image_path')
## 4.配置推理参数
gen_config = GenerationConfig(top_p=0.8, temperature=0.8)
## 5.利用 pipeline.chat 接口 进行对话,需传入生成参数
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
## 6.之后的对话轮次需要传入之前的session,以告知模型历史上下文
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
】
2.2 LMDeploy部署InternVL应用并体验
1. 拉取InternVL2 github仓库资料,输入:
cd /root/
git clone https://github.com/Control-derek/InternVL2-Tutorial.git
cd /root/InternVL2-Tutorial
2. (如用默认,可忽略) 修改/root/InternVL2-Tutorial/demo.py文件中的InternVL2-2B模型路径
demo.py文件中,MODEL_PATH填写的是InternVL2-2B模型的路径,如果使用的是InternStudio的开发机自带模型则无需修改,否则改为模型路径。
3. 运行InternVL应用,输入:
cd /root/InternVL2-Tutorial
conda activate InternVL-lmdeploy
python demo.py
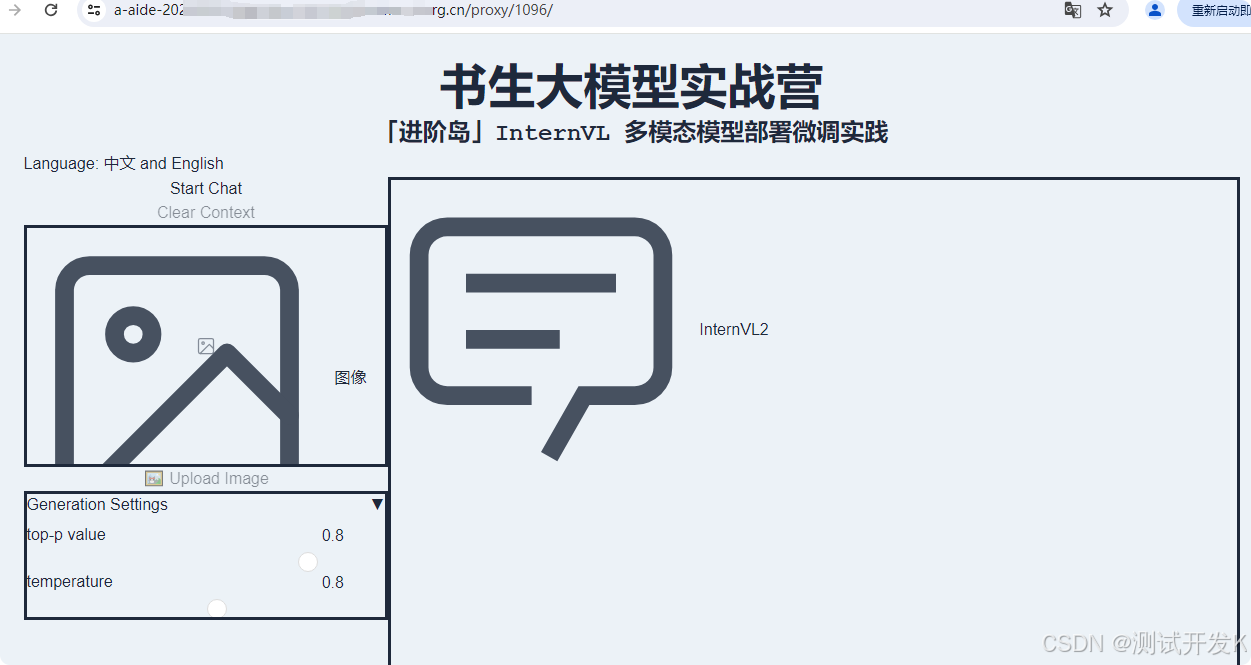
4. 体验web版InternVL。在本地机powershell做端口映射后,浏览器访问http://127.0.0.1:1096/
端口映射命令:
ssh -CNg -L 1096:127.0.0.1:1096 root@ssh.intern-ai.org.cn -p <远程开发机ssh端口>
# 1096端口可以在demo.py找到,或者后台服务日志中显示
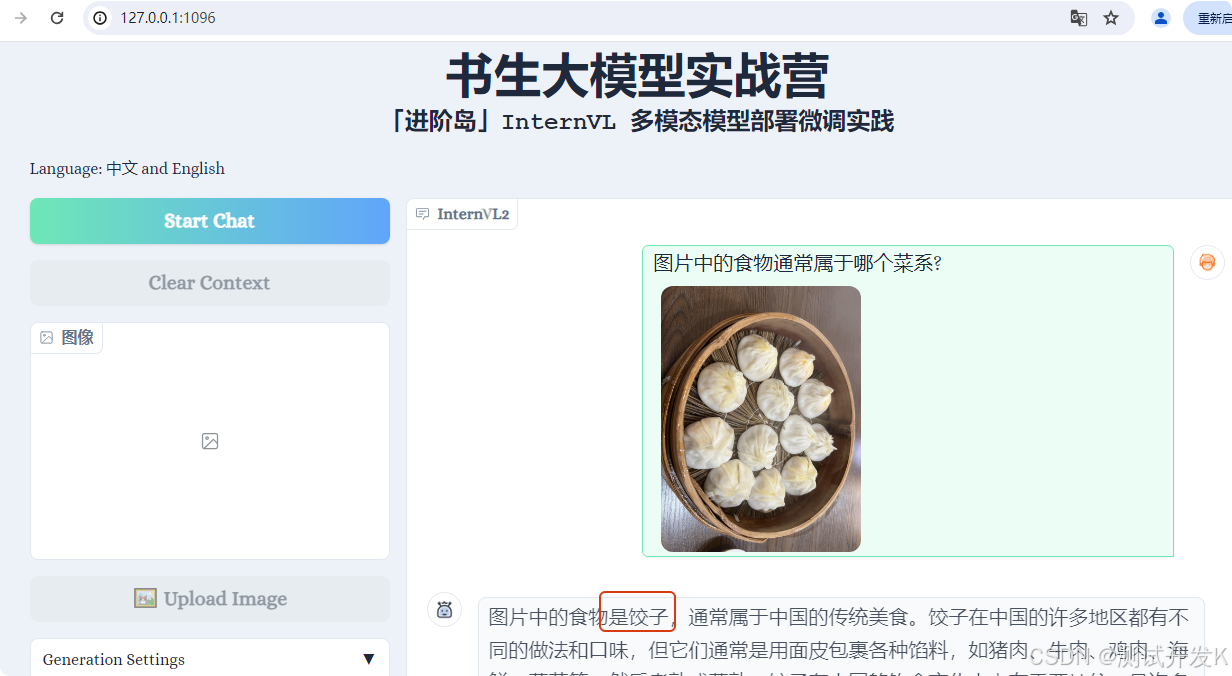
在本地浏览器尝试使用它的图像识别功能,例如识别食物
# 注意如果在开发机上访问该应用,会无法使用,所以需要在本地机做端口映射后访问
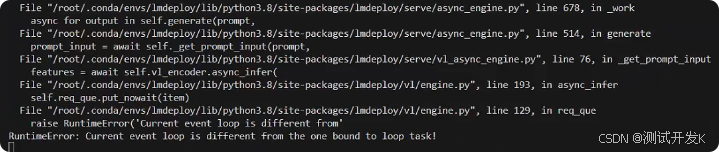
5. (如没报错,可忽略) 输入多张图,或者开多轮对话时可能出现的bug
解决方法:
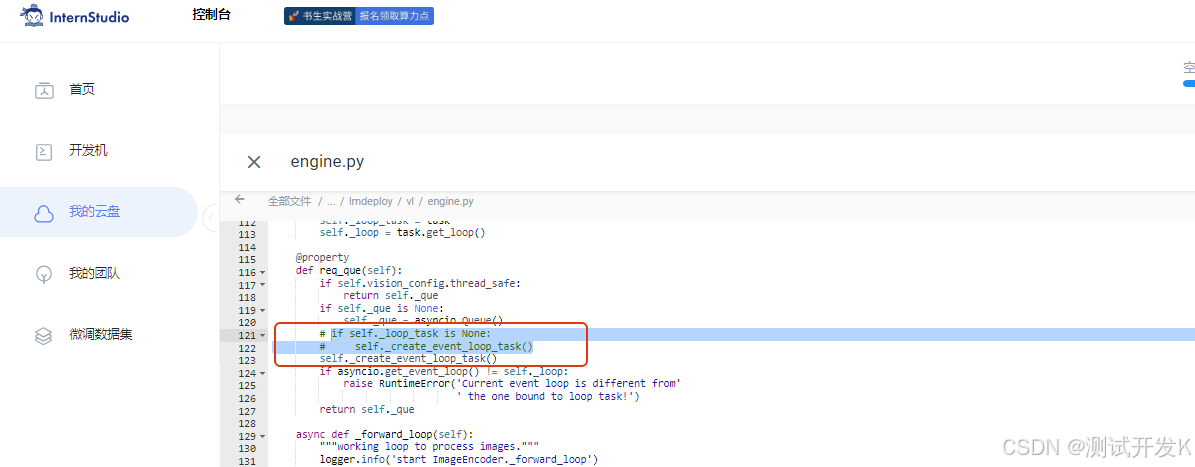
修改/root/.conda/envs/InternVL-lmdeploy/lib/python3.10/site-packages/lmdeploy/vl/engine.py文件,把下面两行源代码注释后用新代码替代(可参考https://github.com/InternLM/lmdeploy/issues/2101):
#if self._loop_task is None:
# self._create_event_loop_task()
self._create_event_loop_task()
三 【用XTuner微调多模态模型InternVL】
3.1 准备基本配置文件
1. 进入InternStudio开发机自带的xtuner目录,并激活训练环境,输入:
cd /root/xtuner #如果没有/root/xtuner,参考下一步
conda activate InternVL-xtuner # 或者是你自命名的训练环境
2. (如有/root/xtuner,可忽略) 如果没有/root/xtuner,就从GitHub上克隆一个,输入:
cd /root
git clone https://github.com/InternLM/xtuner.git
cd /root/xtuner
conda activate InternVL-xtuner
3. 把InternVL原始的微调配置文件复制一份到/root/xtuner/xtuner/configs/internvl/v2目录下,复制命令如下:
cp /root/InternVL2-Tutorial/xtuner_config/internvl_v2_internlm2_2b_lora_finetune_food.py /root/xtuner/xtuner/configs/internvl/v2/internvl_v2_internlm2_2b_lora_finetune_food.py
4. (可忽略) 配置文件参数解读
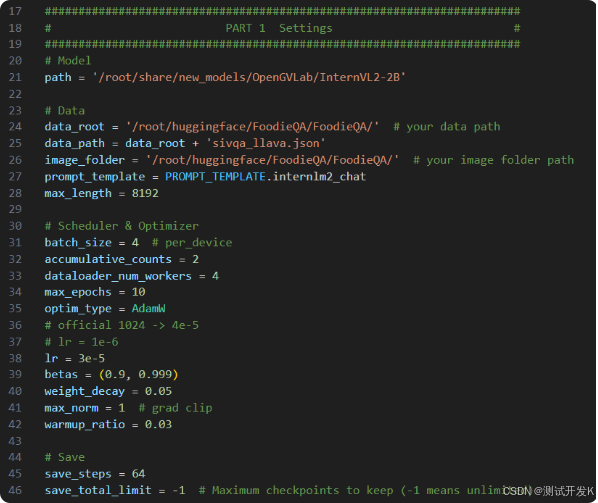
在第一部分的设置中,有如下参数:
path: 需要微调的模型路径,在InternStudio环境下,无需修改。
data_root: 数据集所在路径。
data_path: 训练数据文件路径。
image_folder: 训练图像根路径。
prompt_temple: 配置模型训练时使用的聊天模板、系统提示等。使用与模型对应的即可,此处无需修改。
max_length: 训练数据每一条最大token数。
batch_size: 训练批次大小,可以根据显存大小调整。
accumulative_counts: 梯度累积的步数,用于模拟较大的batch_size,在显存有限的情况下,提高训练稳定性。
dataloader_num_workers: 指定数据集加载时子进程的个数。
max_epochs:训练轮次。
optim_type:优化器类型。
lr: 学习率
betas: Adam优化器的beta1, beta2
weight_decay: 权重衰减,防止训练过拟合用
max_norm: 梯度裁剪时的梯度最大值
warmup_ratio: 预热比例,前多少的数据训练时,学习率将会逐步增加。
save_steps: 多少步存一次checkpoint
save_total_limit: 最多保存几个checkpoint,设为-1即无限制
在第二部分的设置中,LoRA有如下参数:
r: 低秩矩阵的秩,决定了低秩矩阵的维度。
lora_alpha 缩放因子,用于调整低秩矩阵的权重。
lora_dropout dropout 概率,以防止过拟合
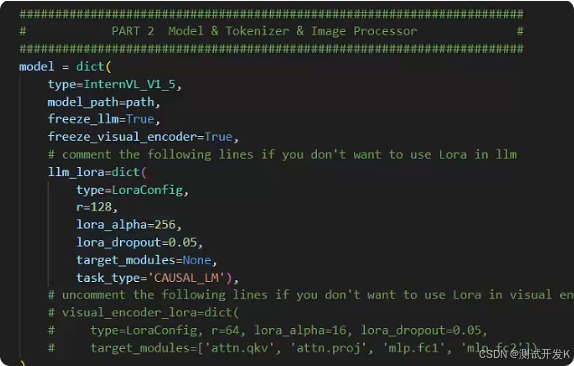
如果想断点重训,可以在最下面传入参数:
把load_from传入你想要载入的checkpoint,并设置resume=True即可断点重续。
3.2 数据集下载
# 这里以食物识别为例,采用FoodieQA数据集。可用internstudio开发机上自带的数据集,也可以从huggingface下载到本地再上传开发机,然后对数据集格式进行处理
1. (可忽略) FoodieQA 是一个专门为研究中国各地美食文化而设计的数据集。它包含了大量关于食物的图片和问题,帮助多模态大模型更好地理解不同地区的饮食习惯和文化特色。这个数据集的推出,让我们能够更深入地探索和理解食物背后的文化意义。
2. 如果使用开发机/root/share/目录下已处理好的数据集,可直接跳到 "3.3 检查配置文件的数据集路径"
数据集存放在 /root/share/datasets/FoodieQA 目录下
3. 如果通过huggingface下载,下载地址https://huggingface.co/datasets/lyan62/FoodieQA
# 首先,通过huggingface-cli登录,输入:
conda activate InternVL-xtuner
huggingface-cli login #期间需要输入hf登录需要的token
# 然后,使用命令下载数据集(如果麻烦也可以通过页面下载,然后上传到开发机指定目录),输入:
huggingface-cli download --repo-type dataset --resume-download lyan62/FoodieQA --local-dir /root/huggingface/FoodieQA --local-dir-use-symlinks False
# 最后,运行 process_food.py 处理下载的数据集(由于原始数据集格式不符合微调需要格式,需要处理方可使用)。输入:
conda activate InternVL-xtuner
cd /root/InternVL2-Tutorial/
python process_food.py
# 运行process_food.py前确认下数据集路径是否正确
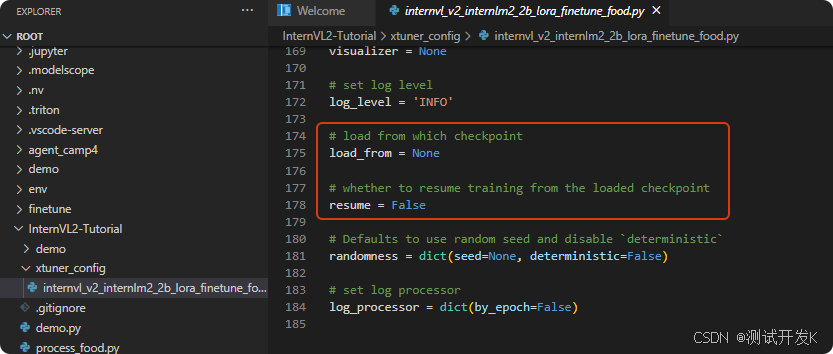
3.3 检查配置文件的数据集路径
打开配置文件/root/xtuner/xtuner/configs/internvl/v2/internvl_v2_internlm2_2b_lora_finetune_food.py,检查数据集的路径 data_root 是否正确
3.4 开始微调
运行命令,开始微调,输入:
conda activate InternVL-xtuner
cd /root/xtuner
xtuner train /root/xtuner/xtuner/configs/internvl/v2/internvl_v2_internlm2_2b_lora_finetune_food.py --deepspeed deepspeed_zero2
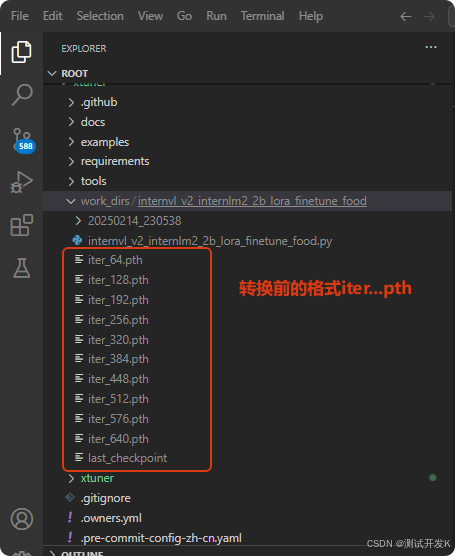
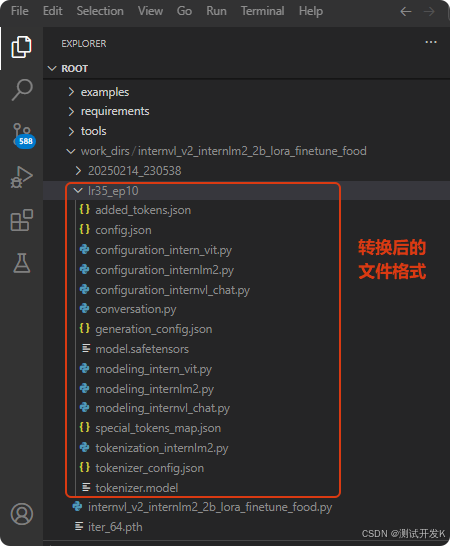
3.5 微调后,转换模型文件格式
微调后,把模型checkpoint的格式 (生成很多个iter_xxx.pth的文件,取其中一个一般取编号数最大那个,例如该例iter_640.pth) 转化为便于测试的格式(py,json,safetensors),输入:
conda activate InternVL-xtuner
cd /root/xtuner
python xtuner/configs/internvl/v1_5/convert_to_official.py xtuner/configs/internvl/v2/internvl_v2_internlm2_2b_lora_finetune_food.py ./work_dirs/internvl_v2_internlm2_2b_lora_finetune_food/iter_640.pth ./work_dirs/internvl_v2_internlm2_2b_lora_finetune_food/lr35_ep10/
#命令中最后那个路径是微调后的最终模型的存放位置,即.../lr35_ep10/
四 【验证微调后的多模态模型效果】
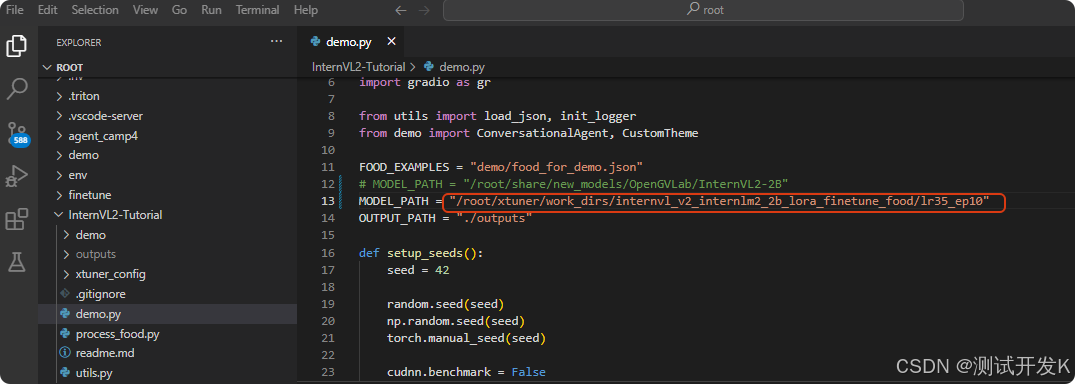
1. 修改/root/InternVL2-Tutorial/demo.py文件中MODEL_PATH
把原来的MODEL_PATH替换成微调后的模型存放目录,即/root/xtuner/work_dirs/internvl_v2_internlm2_2b_lora_finetune_food/lr35_ep10
2. 启动微调后的多模态应用服务
cd /root/InternVL2-Tutorial
conda activate InternVL-lmdeploy
python demo.py
ssh -CNg -L 1096:127.0.0.1:1096 root@ssh.intern-ai.org.cn -p <远程开发机ssh端口> #本地机做端口映射,然后浏览器访问应用
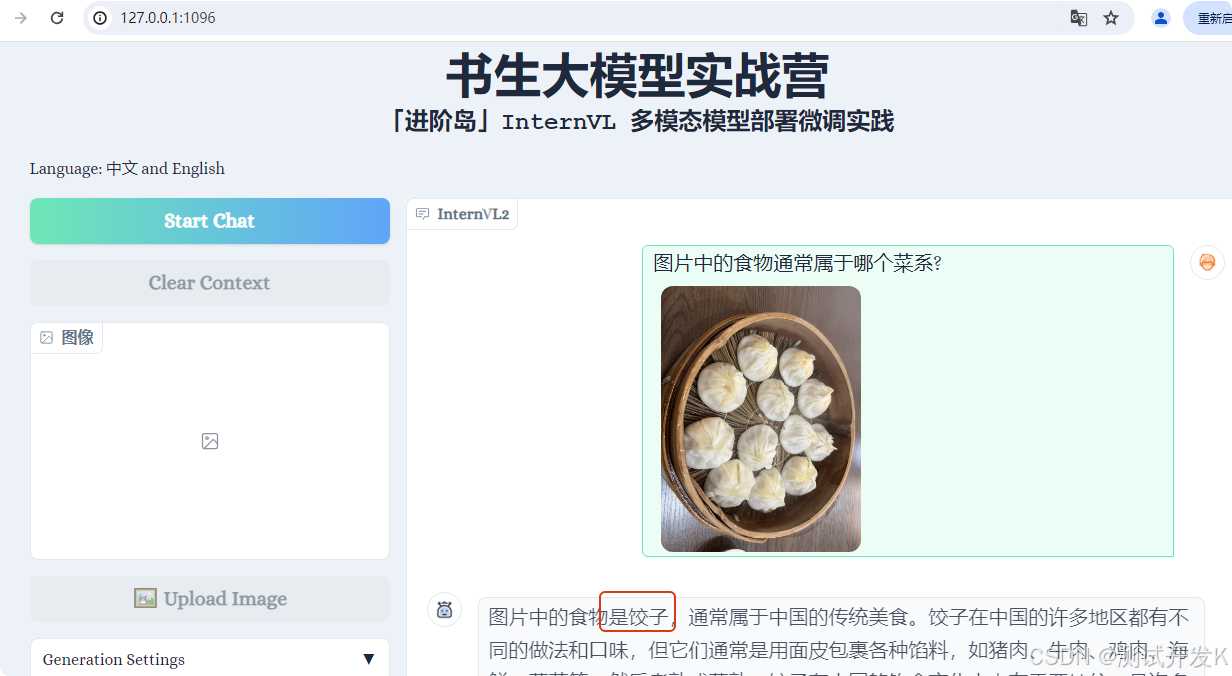
微调前的效果
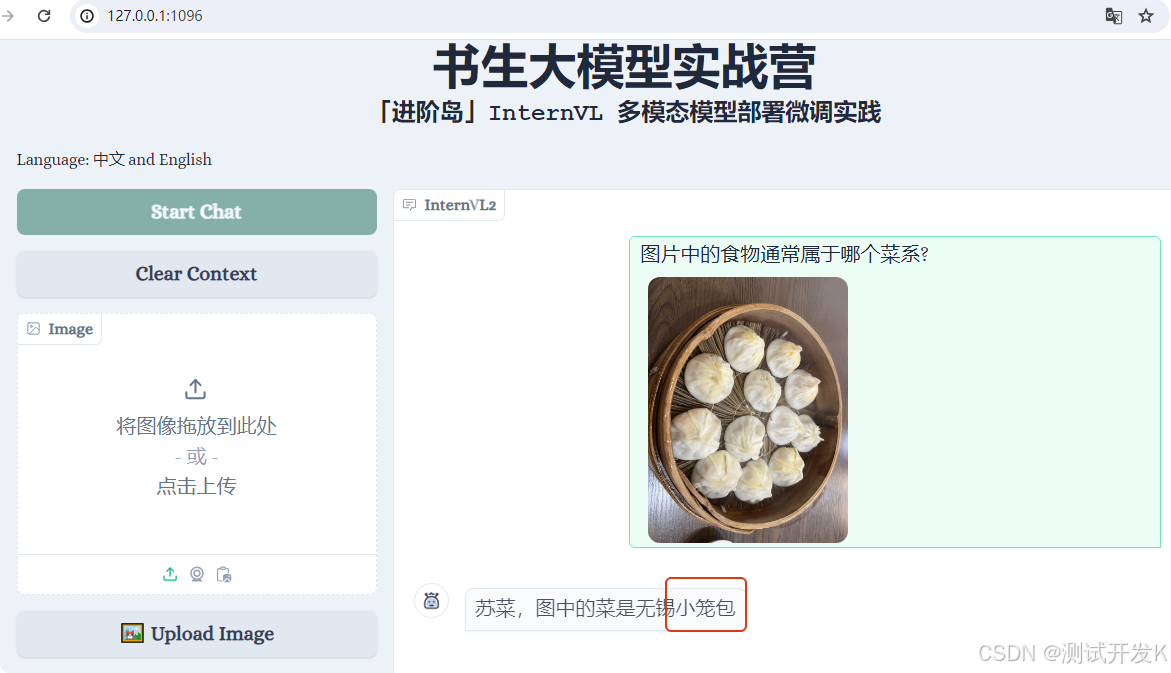
微调后的效果
3. 把微调后的模型上传到HuggingFace
# 文件太大需要用lfs上传,参考之前文章
书生大模型 基础关卡 --- 第5关:XTuner 微调个人小助手认知-CSDN博客
五 【多模态大模型简介】
5.1 什么是多模态大语言模型
多模态大语言模型(Multimodal Large Language Model, MLLM)是指能够处理和融合多种不同类型数据(如文本、图像、音频、视频等)的大型人工智能模型。这些模型通常基于深度学习技术,能够理解和生成多种模态的数据,从而在各种复杂的应用场景中表现出强大的能力。
多模态大模型研究的一个关键点是不同模态特征空间的对齐。常见的多模态融合模式有 Q-former 和 MLP两种,下面我们将介绍这两种设计模式及其工作原理。
5.2 Q-former
BLIP-2 提出了 Q-former,是多模态大模型领域最早最有影响力的工作之一。类似之前经典的多模态模型的双塔设计结构,Q-former 架构中两个塔之间通过self attention来进行参数的共享,起到一定的模态融合的作用。Feed Forward 层(FFN),不共享参数,类似于MOE中的那个专家模块,处理模态的差异化信息。
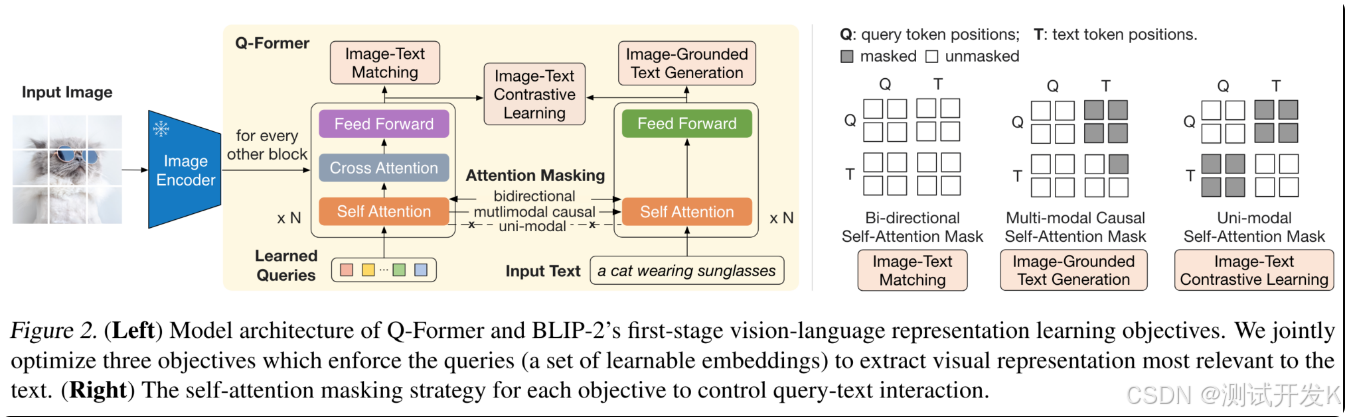
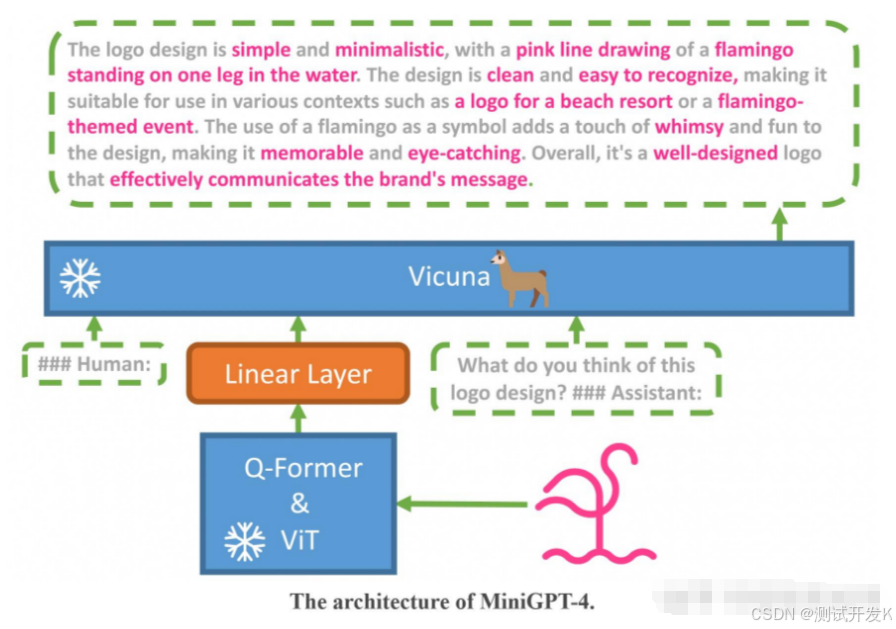
Q former学习三个loss。第一个是图文匹配loss,第二个是基于图像的文本生成loss以及图文的对比学习loss。通过这三个图文任务来优化这个多模态模型的对齐效果。
去年爆火的MiniGPT4 便采用 Q-former 进行多模态对齐
5.3 MLP
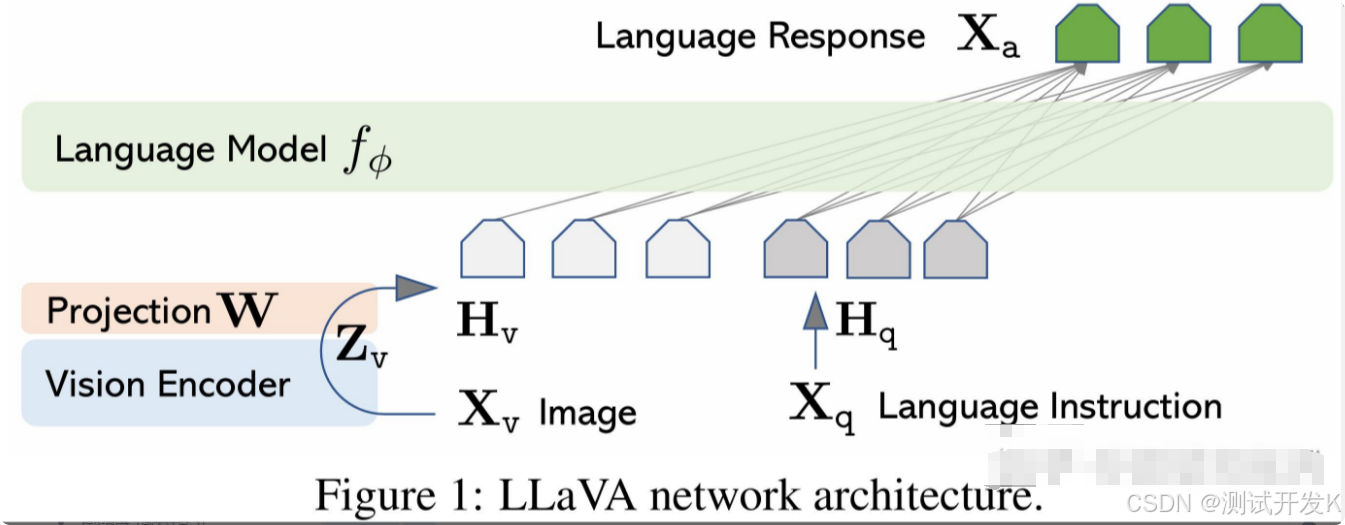
1. LLaVA
LLaVA 的想法比 Q-Former 简单很多,就是把 CLIP 的 Vision Encoder 用一个线性层(或者 MLP)变换后对齐到文本表示中,对齐的时候甚至只学线性层,但是效果却很好。
LLaVA 的设计非常简单,仅仅使用简单的线性层将图像特征投影到文本空间。参数少。
2. LLaVA-NeXT
LLaVA-NeXT 在 LLaVA1.5 的基础上,将图片分块后分别编码,这样可以支持更高分辨率。同时将整体图像 resize 到规定尺寸编码,保留全局信息。
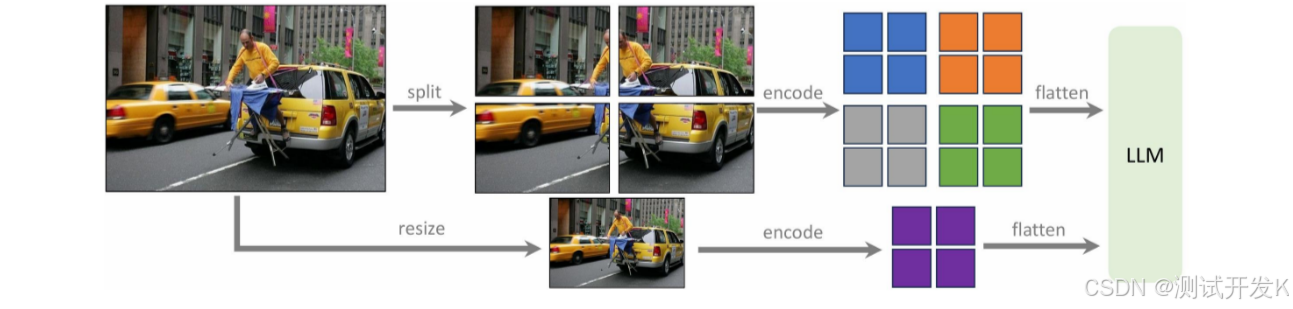
3. 为什么用 Q-Former 的变少了
① 收敛速度慢:Q-Former 的参数量较大(例如 BLIP-2 中的 100M 参数),导致其在训练过程中收敛速度较慢。相比之下,MLP 作为 connector 的模型(如 LLaVA-1.5)在相同设置下能够更快地收敛,并且取得更好的性能。
② 性能收益不明显:在数据量和计算资源充足的情况下,Q-Former 并没有展现出明显的性能提升。即使通过增加数据量和计算资源,Q-Former 的性能提升也并不显著,无法超越简单的 MLP 方案。
4. 为什么大家都用 LLaVA
①更强的 baselinesetting:LLaVA-1.5 通过改进训练数据,在较少的数据量和计算资源下取得了优异的性能,成为了一个强有力的 baseline。相比之下,BLIP2 的后续工作 lnstructBLIP 在模型结构上的改进并未带来显著的性能提升,且无法推广至多轮对话。
②模型结构的简洁性:LLaVA 系列采用了最简洁的模型结构,而后续从模型结构上进行改进的工作并未取得明显的效果。这表明,在当前的技术和数据条件下,简洁的模型结构可能更为有效。
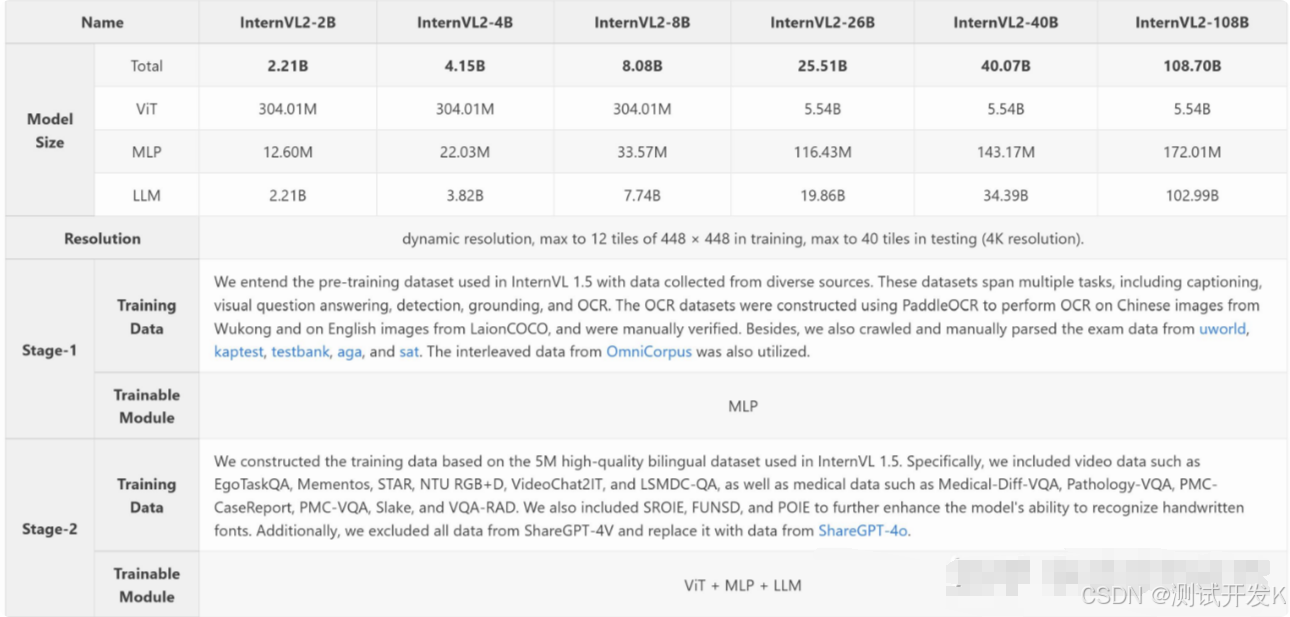
六 【InternVL2 简介】
InternVL2 是一款由上海人工智能实验室 OpenGVLab 发布的多模态大模型,其设计模式和模型架构以及训练流程都体现了多模态融合和深度学习的先进理念。
6.1 设计模式
InternVL2 采取了LLaVA 式架构设计 (ViT-MLP-LLM):
InternLM2-20B
InternViT-6B
MLP
6.2 模型架构
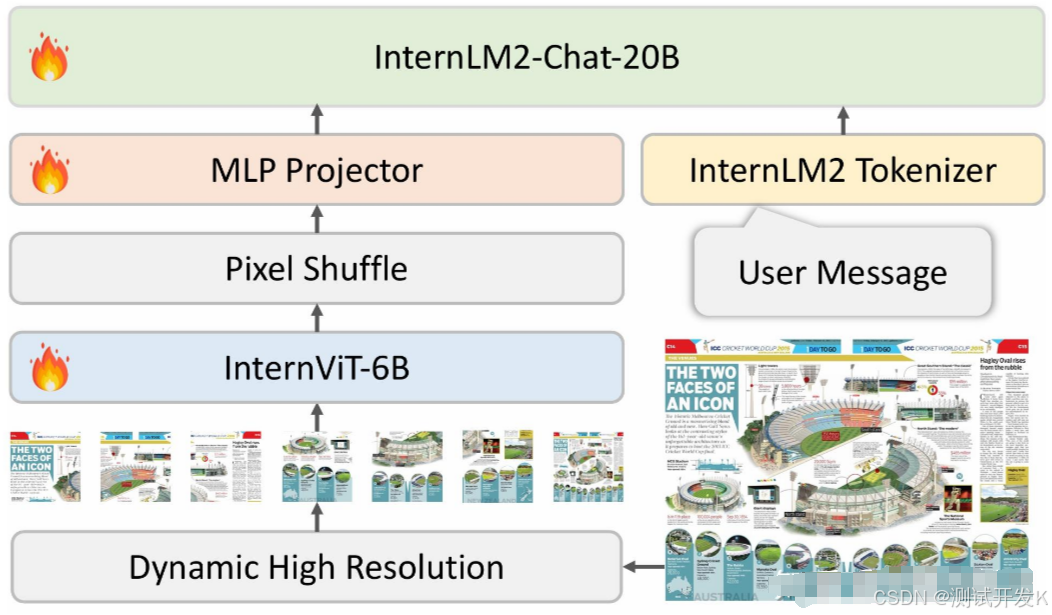
1. Dynamic High Resolution
InternVL 独特的预处理模块:动态高分辨率,是为了让 ViT 模型能够尽可能获取到更细节的图像信息,提高视觉特征的表达能力。
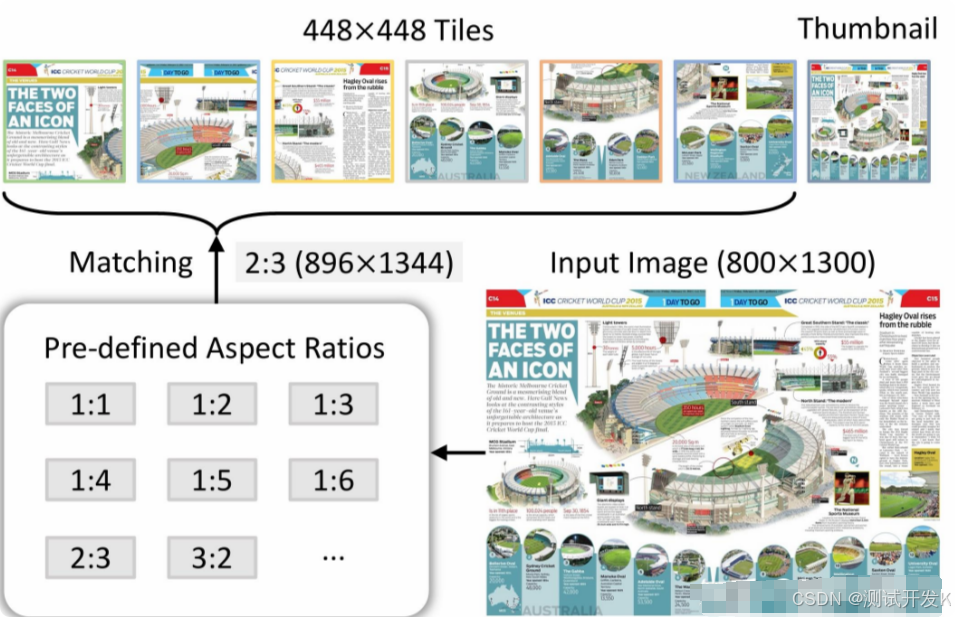
Pre-defined Aspect Ratios: 考虑到计算资源,设置最多 12 个 tile,就有 35 种长宽比的排列组合 (m*n, m, n≤12; 12+6+4+3+2+2+6)。
Match and split: 选择最接近的长宽比,resize 过去,切片成 448448 的 tiles。
Thumbnail: 某些任务需要全局信息,为了更好的感知全局信息,把原图 resize 到 448448,一块喂给 LLM。
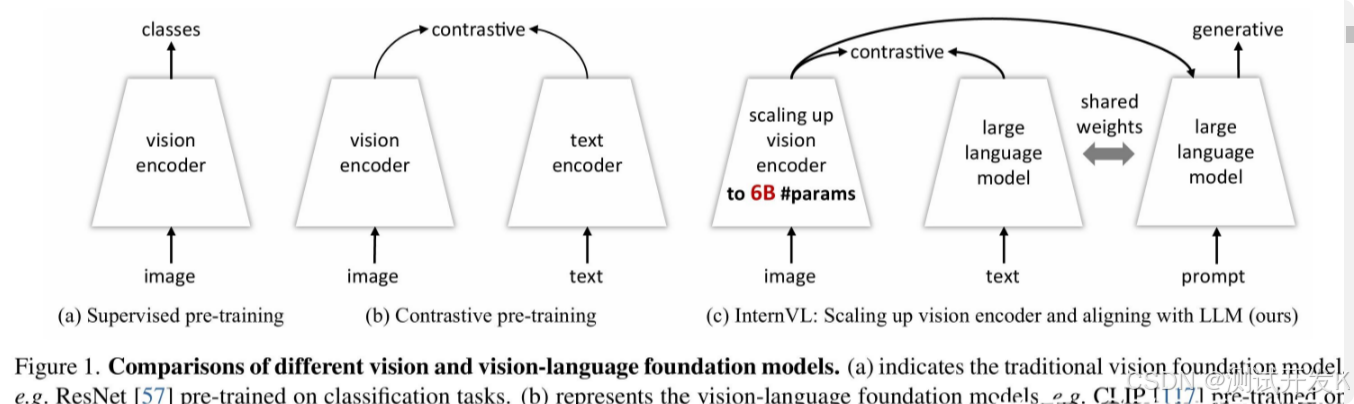
2. InternViT
下图为 InternVL 的训练流程。与传统的监督学习或CLIP的对比学习方法不同,InternVL 做了两方面的改进。一是 InternVL 增大了视觉编码器的参数量;二是,虽然InternVL也使用了类似CLIP的对比学习方法,但其训练方式有所不同:在CLIP中,对比学习训练完成后,通常将视觉编码器用于多模态大模型,而文本编码器则被丢弃;而在InternVL的训练过程中,视觉编码器与大语言模型(LLM)直接对齐,LLM替代了传统的文本编码器的位置。在后续的生成任务中,InternVL可以直接使用经过对齐的LLM。由于LLM在预训练阶段就已实现了自然对齐,因此后续的对齐适配效果会更好。
InternViT-6B-448px-V1.2 (InternVL 中的对 ViT 模块的修改):
在实验中发现,倒数第四层特征最有用,砍掉后三层,共 45 层
分辨率从 224 扩展到 448
与 LLM 联合训练时,在 captioning 和 OCR 数据集上训练
获取高分辨率和 OCR 能力
InternViT-6B-448px-V1.5 (InternVL2 对 InternViT 模块做了如下升级):
动态分辨率(类似 LLaVA-NeXT),最多 12 个 tile
更高质量的数据
3. Pixel Shuffle
Pixel Shuffle 在超分任务中是一个常见的操作,PyTorch 中有官方实现,即 nn.PixelShuffle (upscale_factor) 该类的作用就是将一个 tensor 中的元素值进行重排列,假设 tensor 维度为
, PixelShuffle 操作不仅可以改变 tensor 的通道数,也会改变特征图的大小。
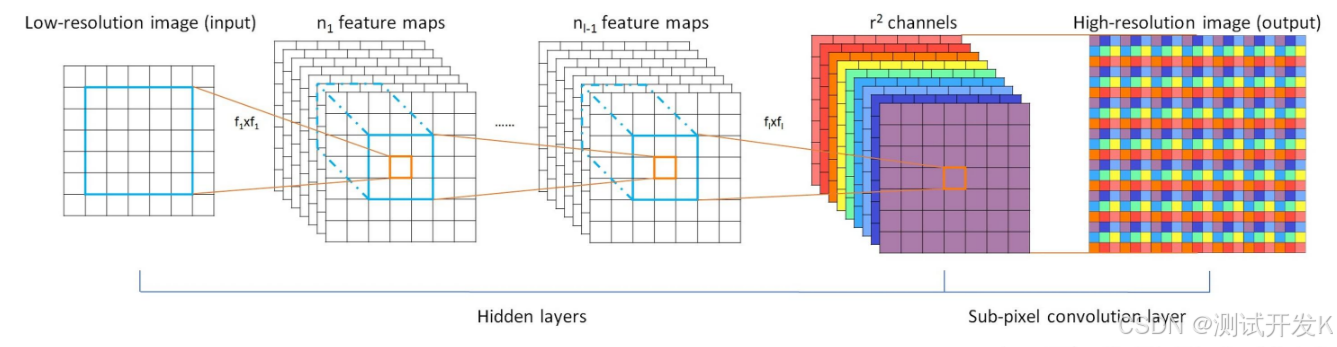
Why: 对于 448×448 像素的图像,若 patch 大小设置为 14×14,则会得到 32×32=1024 个 patch,相当于视觉模型需要处理 1024 个 token。这种设置会导致信息冗余,消耗大量计算资源,不利于处理较长的多模态上下文。
What: Pixel shuffle 技术源自超分辨率领域,它通过将不同通道的特征重新排列组合到一个通道上,实现特征图的上采样。具体来说,它将形状为 (N,C x r²,H,W) 的特征图转换为 (N,C,H x r,W x r) ,其中 r 是上采样因子。
How: 在此案例中,将采样因子 r 设为 0.5,可以将原本尺寸为 4096 x 0.5 x 0.5 (即 32×32)的图像特征转换为 4096 x 32 x 0.5 x 32 x 0.5 ,实现下采样至 256 个 token。
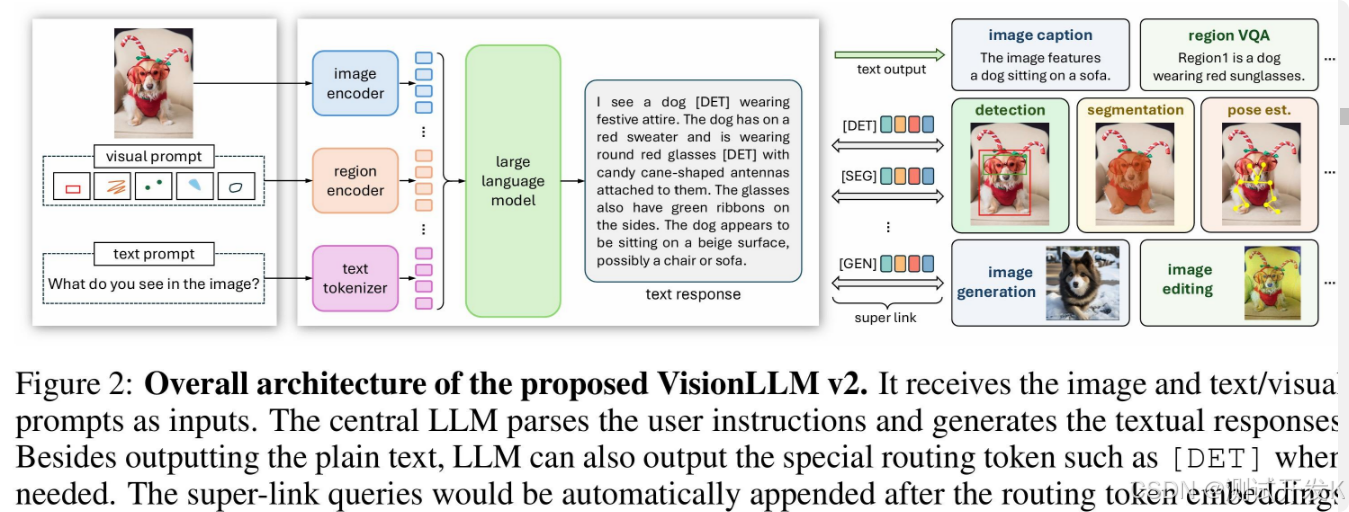
4. Multitask output
-- 利用 VisionLLMv2 的技术,初始化了一些任务特化 embedding(图像生成、分割、检测),添加了一些任务路由 token
-- 训练下游任务特化 embedding,生成路由 token 时,把任务 embedding 拼在路由 embedding 后面,送给 LLM 拿到 hidden_state
-- 把 hidden_state 送给路由到的解码器中,生成图像/bounding box/masks
6.3 训练流程
第一阶段:训练 MLP,用高质量预训练数据(各种视觉任务) 第二阶段:ViT+MLP+LLM 联合训练,用高质量视觉-文本指令任务