python3:文件与异常
本来这篇教程是打算在base python数据类型之后出的,但是计划赶不上变化,反正最后都要融会贯通,今日有时间、今天遇到了类似的问题,就今天做这一模块的整理,顺序不是重点。
参考我的上一篇博客:https://blog.csdn.net/weixin_62528784/article/details/144705158
本篇博客的核心在于File对象以及相应的open方法,OS对象以及相应的方法
参考:https://www.runoob.com/python/python-files-io.html

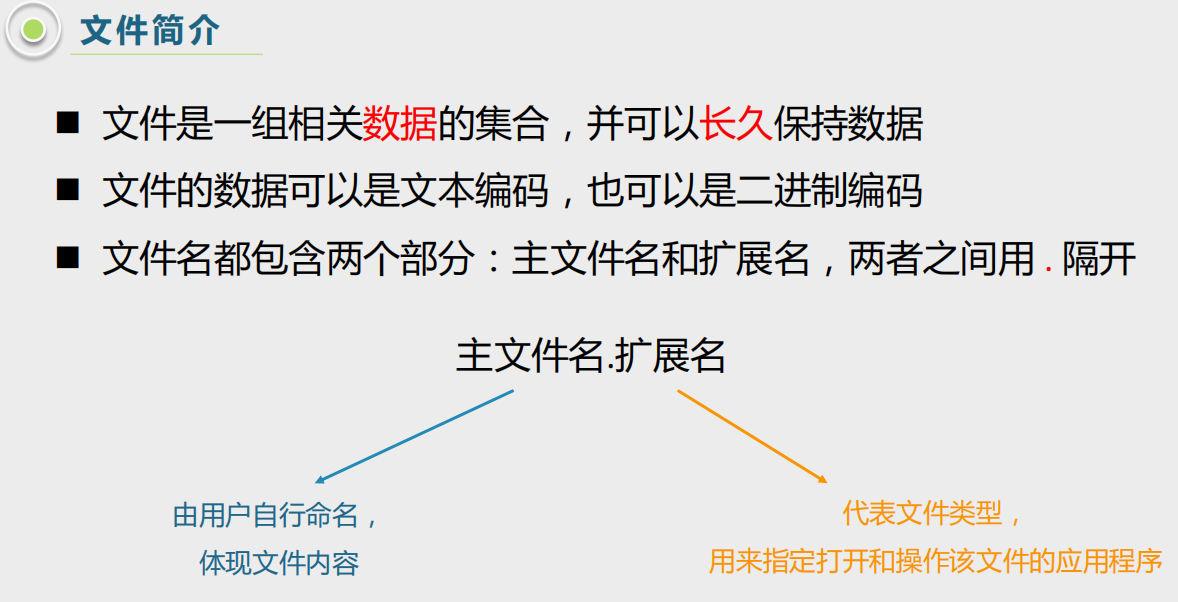
一,文件及文件基本操作
文件本质上也是数据,数据的集合,文件操作和我们处理一些基本的python中数据类型本质上也没什么区别,
处理原子类型的数据,和处理集合类型的数据
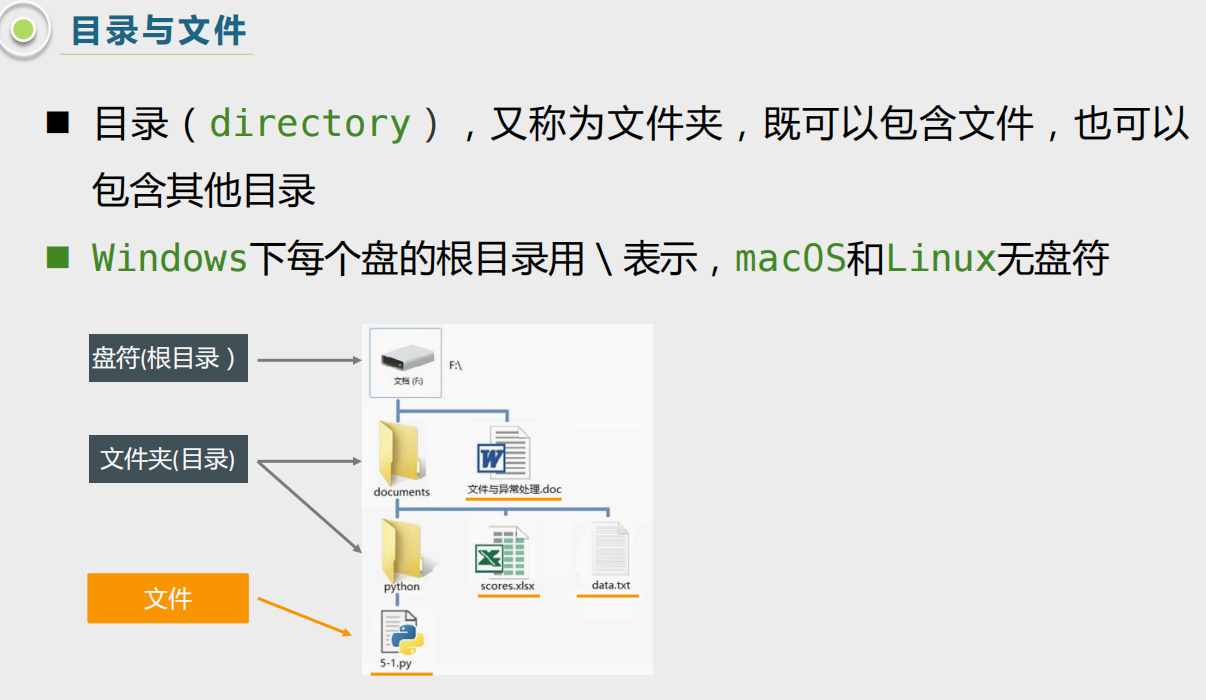
目录与文件,以linux的系统文件组织为主,这一块可以再重温一下:
1,谈到文件夹和文件,少不了的就是绝对路径以及相对路径了,
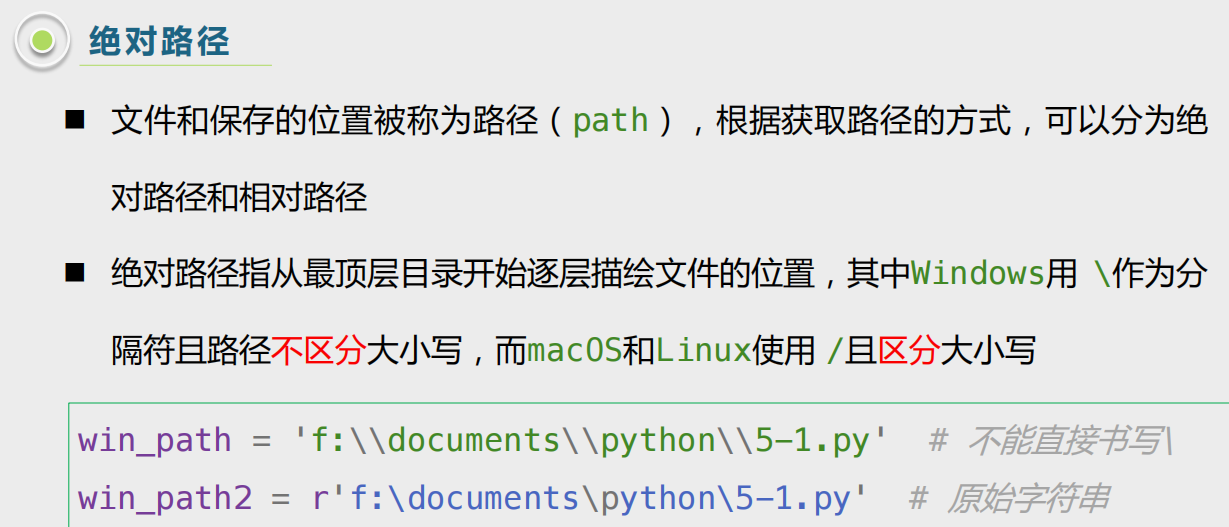

# 绝对路径
# 1,win系统中:
win_path="C:\\Users\\Administrator\\Desktop\\generate.pl"# 2,linux系统中(主):
linux_path="/data1/project/generate.pl"
很简单,linux系统中pwd之类怎么写的文件路径,文件操作的时候只需要在外面再加上“”即可;
windows系统中同理,因为windows系统中路径的话,其实我们潜移默化已经习惯了盘符层层递进的写法,而且我们更早习惯了转义字符的概念,所以我们同样写路径+外面套双引号(注意路径中的盘符,以及转义符号即可,与linux习惯的反过来双层斜杠,我想用R读写文件习惯了的人,这一点基础应该很快就能够融汇贯通)。
2,另外需要提一下在python中对文件系统的一些常见的操作,在os模块下
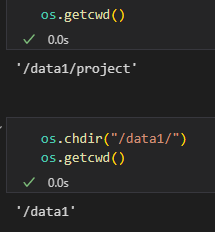
(1)获取当前工作目录
import os# 获取当前工作目录
current_dir = os.getcwd()
print(f"当前工作目录: {current_dir}")
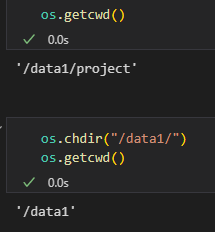
(2)修改当前工作目录
# 修改当前工作目录
os.chdir('/path/to/new/directory')
print(f"修改后的工作目录: {os.getcwd()}")
(3)创建目录
# 创建单级目录
os.mkdir('new_folder')# 创建多级目录
os.makedirs('parent_folder/child_folder')
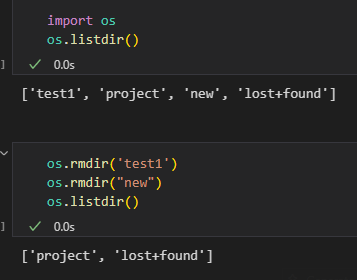
(4)删除目录
# 删除单级目录(目录必须为空)
os.rmdir('new_folder')# 删除多级目录
os.removedirs('parent_folder/child_folder')
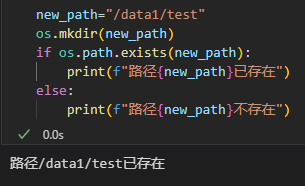
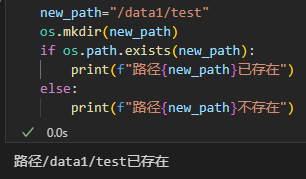
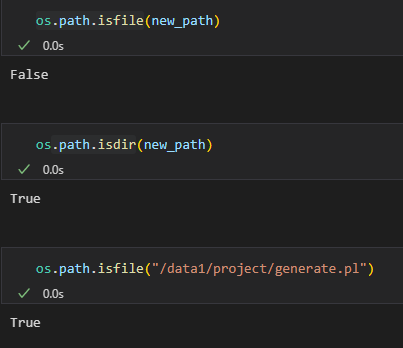
(5)检查路径是否存在
# 检查路径是否存在
path = '/path/to/check'
if os.path.exists(path):print(f"路径存在: {path}")
else:print(f"路径不存在: {path}")
(6)判断路径类型
path = '/path/to/check'# 判断是否为文件
if os.path.isfile(path):print(f"{path} 是一个文件")# 判断是否为目录
if os.path.isdir(path):print(f"{path} 是一个目录")
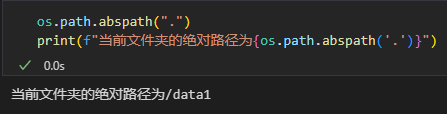
(7)获取文件或目录的绝对路径
# 获取绝对路径
absolute_path = os.path.abspath('relative_path')
print(f"绝对路径: {absolute_path}")
(8)分割路径:
path = '/path/to/file.txt'# 分割路径和文件名
dir_name, file_name = os.path.split(path)
print(f"目录: {dir_name}, 文件名: {file_name}")# 分割文件名和扩展名
file_base, file_ext = os.path.splitext(file_name)
print(f"文件名: {file_base}, 扩展名: {file_ext}")
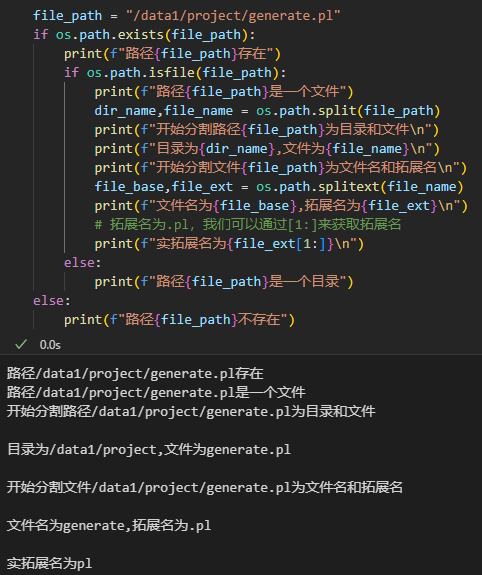
我实际应用的1个例子:
file_path = "/data1/project/generate.pl"
if os.path.exists(file_path):print(f"路径{file_path}存在")if os.path.isfile(file_path):print(f"路径{file_path}是一个文件")dir_name,file_name = os.path.split(file_path)print(f"开始分割路径{file_path}为目录和文件\n")print(f"目录为{dir_name},文件为{file_name}\n")print(f"开始分割文件{file_path}为文件名和拓展名\n")file_base,file_ext = os.path.splitext(file_name)print(f"文件名为{file_base},拓展名为{file_ext}\n")# 拓展名为.pl,我们可以通过[1:]来获取拓展名print(f"实拓展名为{file_ext[1:]}\n")else:print(f"路径{file_path}是一个目录")
else:print(f"路径{file_path}不存在")
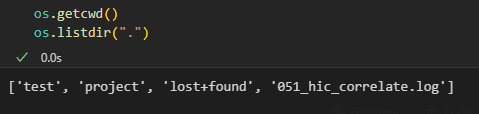
(9)列出目录内容
# 列出当前目录下的所有文件和子目录
contents = os.listdir('.')
print(f"目录内容: {contents}")
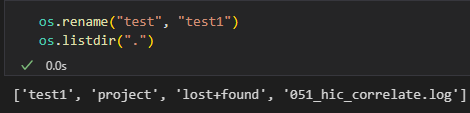
(10)重命名文件或目录
# 重命名文件或目录
os.rename('old_name', 'new_name')
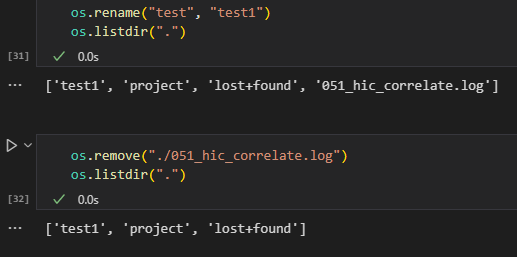
(11)删除文件
# 删除文件
os.remove('file_to_delete.txt')
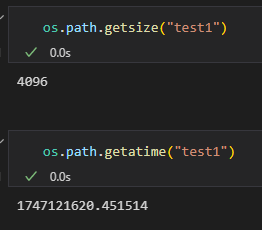
(12)获取文件或目录的属性
path = '/path/to/file_or_directory'# 获取文件大小(字节)
size = os.path.getsize(path)
print(f"文件大小: {size} 字节")# 获取最后修改时间
mod_time = os.path.getmtime(path)
print(f"最后修改时间: {mod_time}")
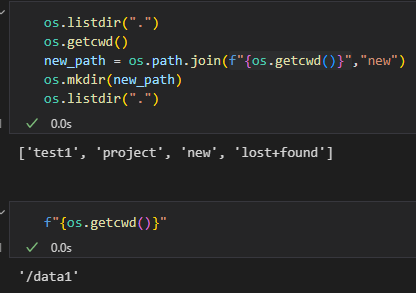
(13)拼接路径
# 拼接路径
new_path = os.path.join('/path/to', 'subdir', 'file.txt')
print(f"拼接后的路径: {new_path}")# 可以使用f"{os.getcwd()}"拼接当前工作路径
(14)获取环境变量
# 获取环境变量
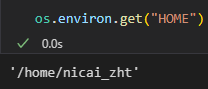
home_dir = os.environ.get('HOME')
print(f"HOME 环境变量: {home_dir}")
可以尝试获取各种已经安装软件的环境变量,这一块操作比较私密,仅提供代码,不提供示例图。
获取所有环境变量:
import os# 获取所有环境变量
env_vars = os.environ# 打印所有环境变量
for key, value in env_vars.items():print(f"{key}: {value}")
获取特定软件的环境变量:
如果你知道某个软件的环境变量前缀(例如 JAVA_HOME、PYTHONPATH 等),可以通过过滤来获取:
# 获取与特定软件相关的环境变量(例如包含 "JAVA" 的变量)
for key, value in os.environ.items():if "JAVA" in key:print(f"{key}: {value}")
使用 os.environ.get 获取单个环境变量:
如果你知道具体的环境变量名称,可以直接获取:
# 获取特定环境变量
java_home = os.environ.get('JAVA_HOME')
print(f"JAVA_HOME: {java_home}")
将环境变量导出到当前会话:
如果需要在当前会话中设置新的环境变量,可以使用 os.environ:
# 设置新的环境变量
os.environ['MY_VAR'] = 'my_value'# 验证是否设置成功
print(os.environ.get('MY_VAR')) # 输出: my_value
使用 subprocess 查看环境变量:
如果需要从子进程中获取环境变量,可以使用 subprocess 模块:
import subprocess# 使用 `env` 命令列出所有环境变量(Linux/Mac)
result = subprocess.run(['env'], capture_output=True, text=True)
print(result.stdout)# 在 Windows 上可以使用 `set` 命令
# result = subprocess.run(['set'], capture_output=True, text=True)
# print(result.stdout)
保存环境变量到文件:
如果需要将所有环境变量保存到文件中,可以这样操作:
with open('env_vars.txt', 'w') as f:for key, value in os.environ.items():f.write(f"{key}: {value}\n")
(15)执行系统命令
# 执行系统命令
os.system('ls -l') # 在 Linux/Mac 上列出文件
os.system('dir') # 在 Windows 上列出文件
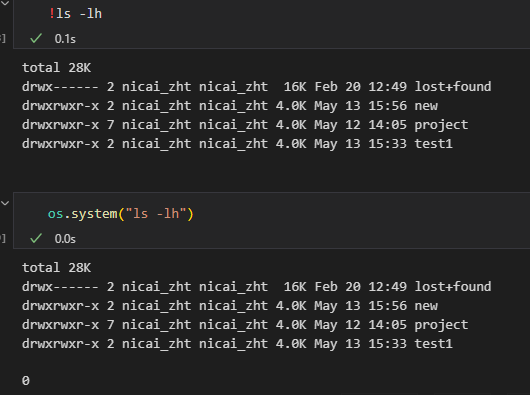
用magic或者是os模块
3,文件操作

其中最常用的模式字符串:主要是r以及w
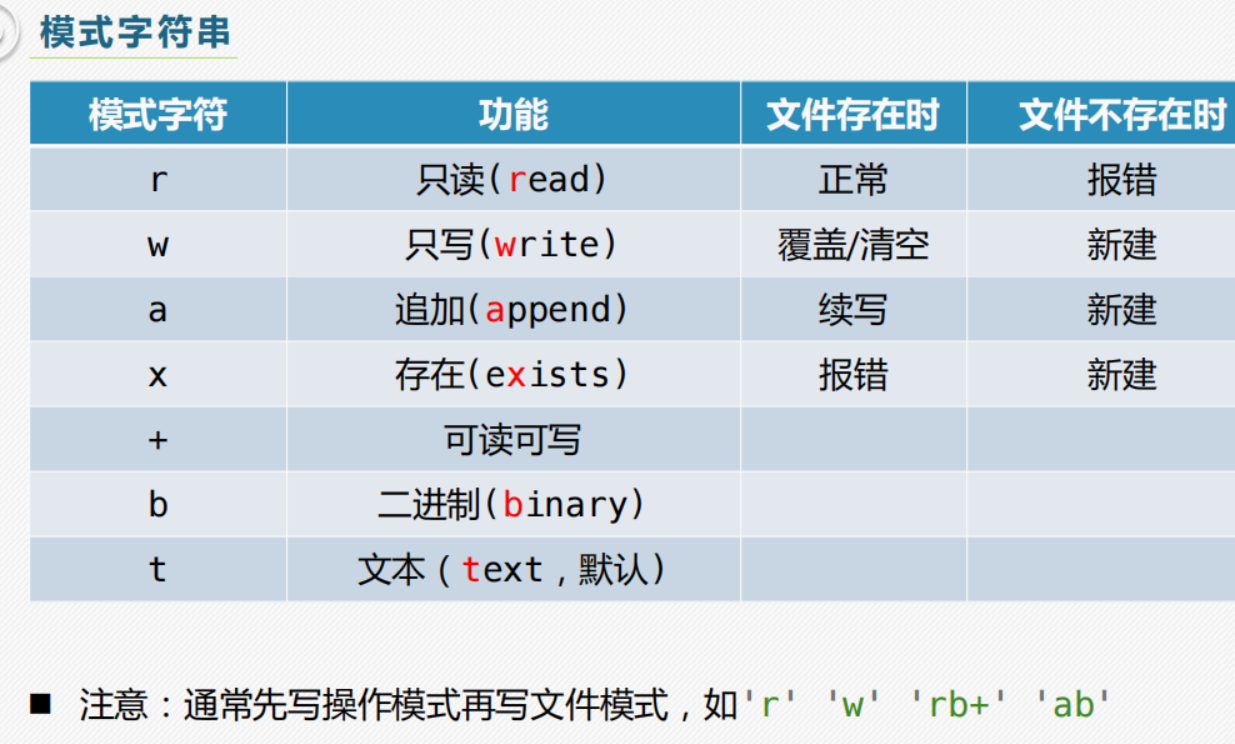
参考:https://www.runoob.com/python/python-files-io.html
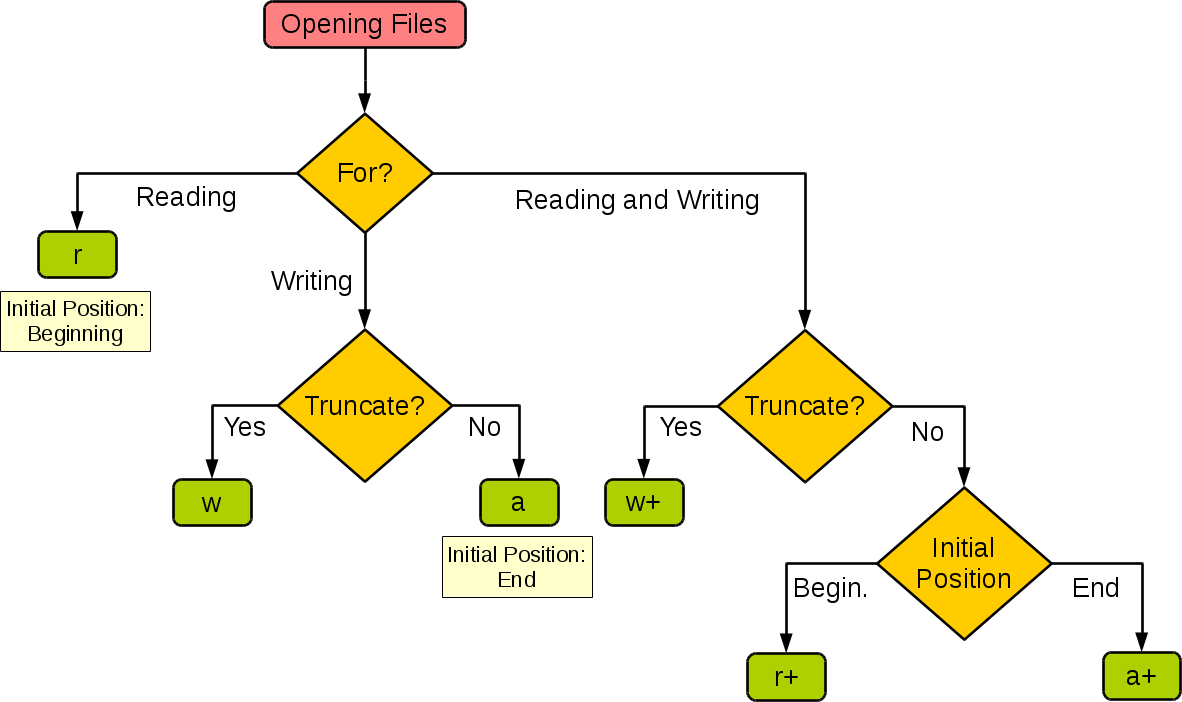
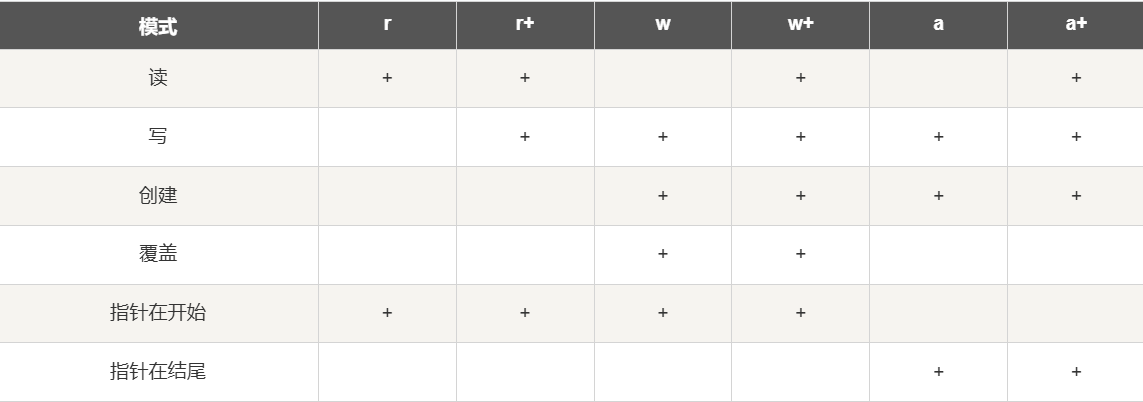
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
(1)写文件:

注意,只有close才能将文件内容写入,并呈现出来。
总之,open和close对应,只有在open后没有close前,才能正常写入文件;只有close之后,才能正常呈现正常写入的文件内容。
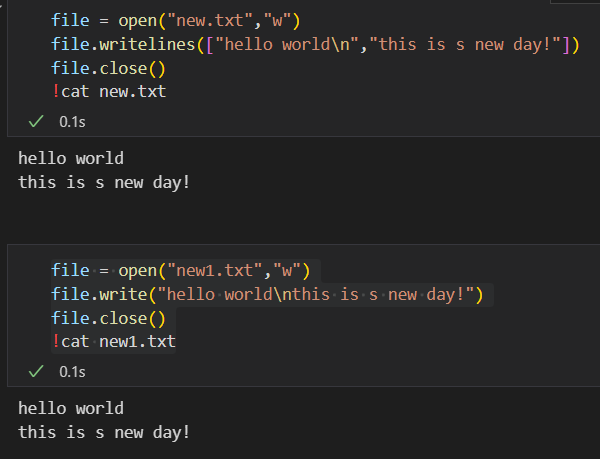
重点就是比较其中的write以及writelines:
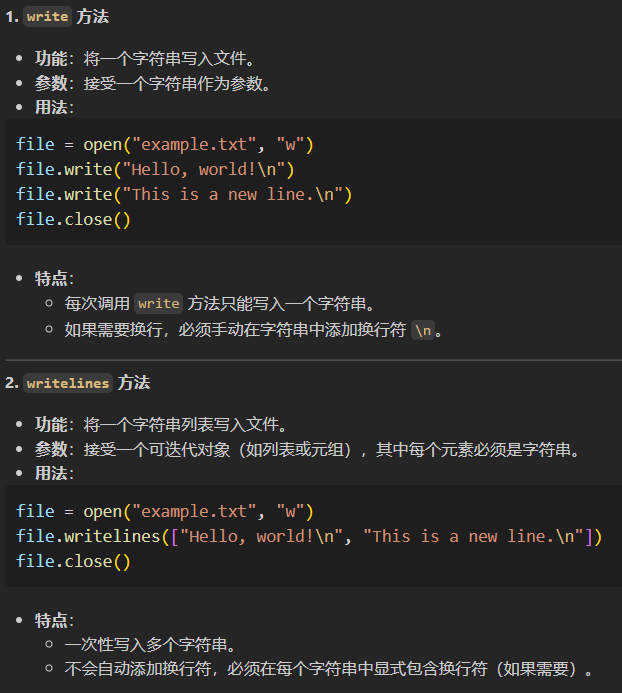
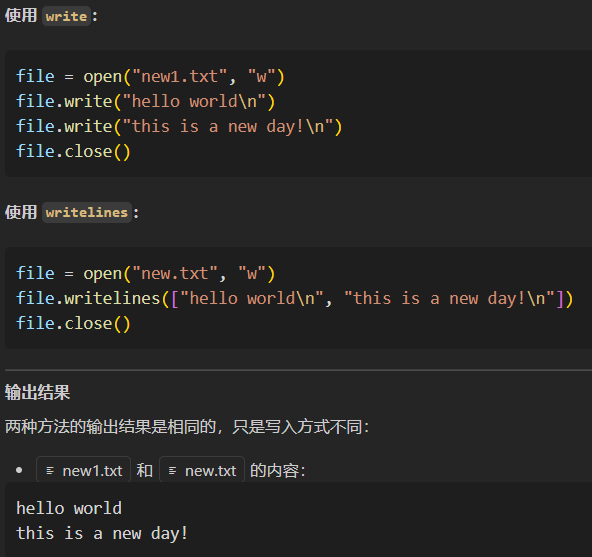
主要区别
| 特性 | **write** | **writelines** |
|---|---|---|
| 输入类型 | 单个字符串 | 字符串的可迭代对象(如列表、元组) |
| 写入方式 | 一次写入一个字符串 | 一次写入多个字符串 |
| 换行处理 | 需要手动添加换行符 | 需要手动在每个字符串中添加换行符 |
write顾名思义只能接受单个对象,writelines可以接受多个对象(字符串的可迭代对象)。
来个简单的例子:

上面的逻辑就是先写入字符内容,写完之后再判断字数有没有达到10个,10个一行,如果达到了就换行;
当然,我们也可以直接先判断是否达到10个一行的条件,如果达到了就输出字符以及换行符,否则正常打印:
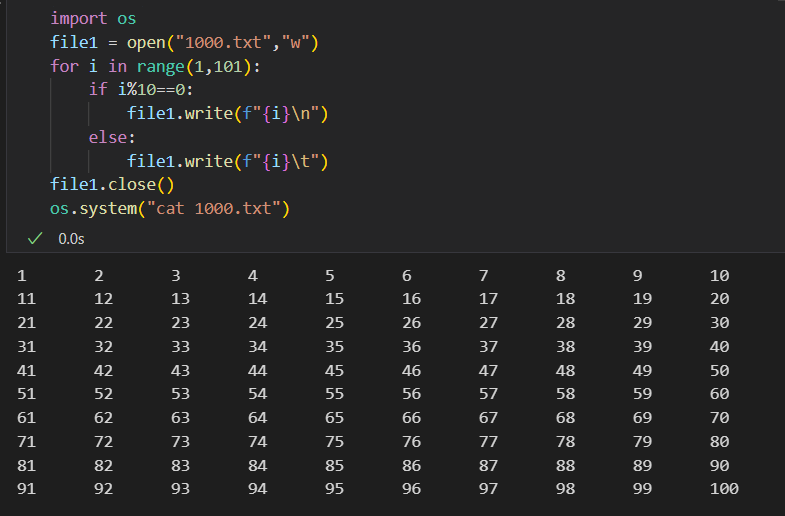
import os
file1 = open("1000.txt","w")
for i in range(1,101):if i%10==0:file1.write(f"{i}\n")else:file1.write(f"{i}\t")
file1.close()
os.system("cat 1000.txt")
(2)读文件:

注意,要正常读取的话,还是要考虑close,或者文件对象的重新读取:
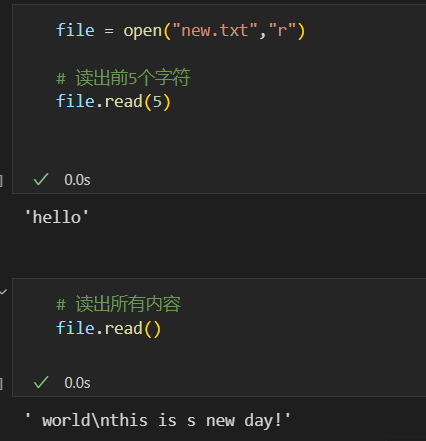
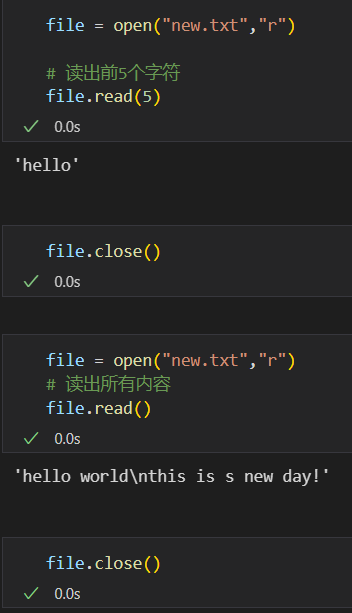
比如说对于文件对象file,我读取了前5个字符,如果没有close的话,我再接着读取出所有的内容,相当于是对剩下的file迭代内容进行读取。
在 Python 中,文件对象的 read() 方法是基于文件指针(file pointer)工作的。文件指针会随着每次读取操作而移动,因此第二次调用 read() 时,只能读取从上次读取结束位置到文件末尾的内容,而不是从文件开头重新读取。
文件指针的工作原理:
文件指针初始位置:当文件被打开时,文件指针默认位于文件的开头。
read(n) 的行为:
read(n) 会从当前文件指针的位置读取 n 个字符,并将文件指针移动到读取结束的位置。
read() 的行为:
如果不指定参数,read() 会从当前文件指针的位置读取到文件末尾。

一般麻烦的话,就直接多次打开文件对象进行读取:
总得来说:
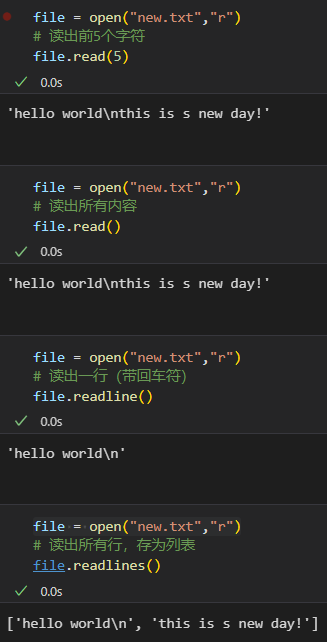
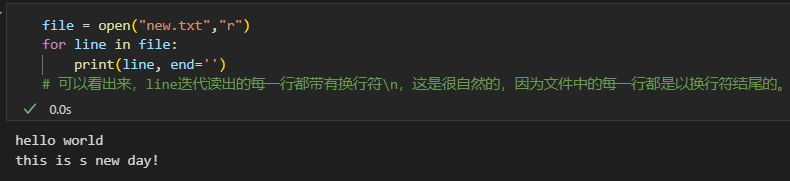
或者将可迭代在读的过程中迭代,或者将读完的内容进行迭代
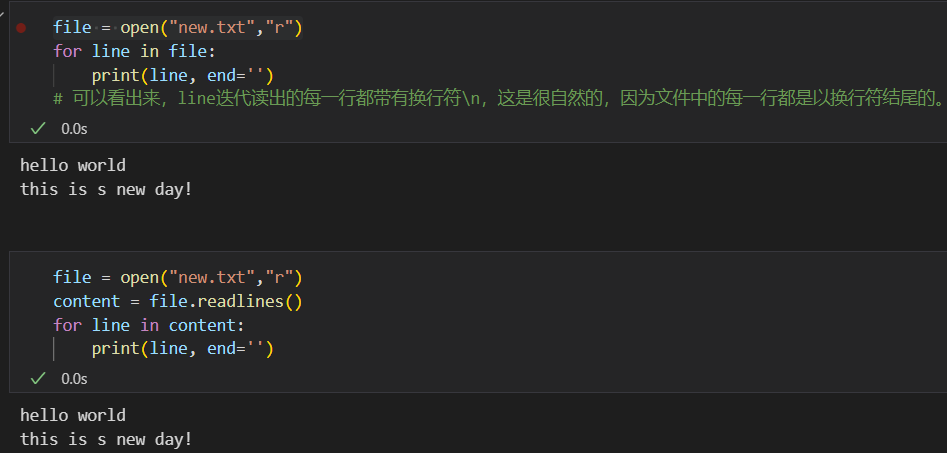
总之,文件IO操作基本操作如下:
# 写操作
# 最好就是使用writelines写入多个可迭代字符串对象
file = open("path_to_file_to_write","w")
file.writelines(["str1","str2","strn"]) # 所有的字符串内容# 读操作
# 最好是for循环读取,对每一个line对象分别操作
file = open("path_to_file_to_read","r")
for line in file:print(line,end="")# 或者是用readlines读出来,再
file_content = file.readlines()
# 因为file_content也是一个可迭代对象,可以对对其进行操作参考:https://liaoxuefeng.com/books/python/io/file/index.html
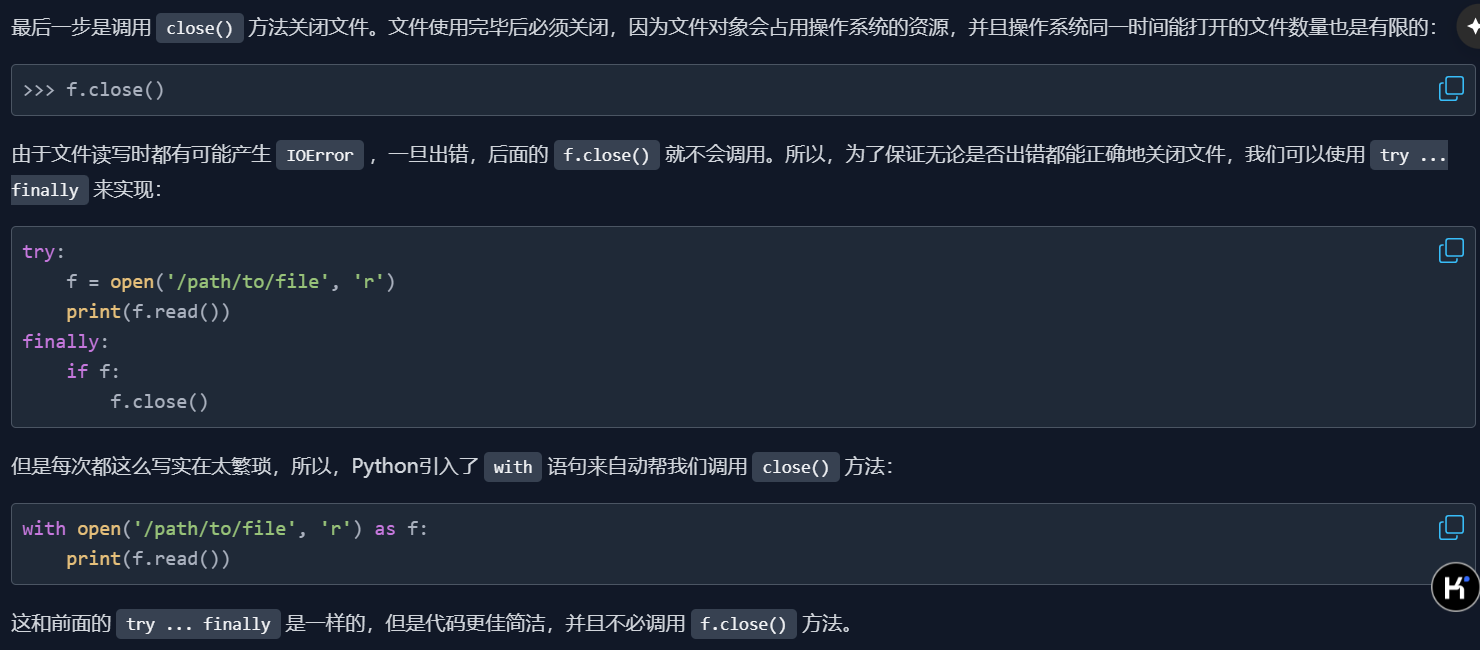

with语句能够自动帮我们调用close方法,所以为了养成良好的习惯,我们都使用with:
其实都是赋值的逻辑,原本的赋值逻辑"="变成了现在的“with as”语句形式
file=open() ————> with open() as file
# 写操作
# 最好就是使用writelines写入多个可迭代字符串对象
with open("path_to_file_to_write","w") as file:file.writelines(["str1","str2","strn"]) # 所有的字符串内容# 读操作
# 最好是for循环读取,对每一个line对象分别操作
with open("path_to_file_to_read","r") as file:for line in file:print(line,end="")# 或者是用readlines读出来,再file_content = file.readlines()
# 因为file_content也是一个可迭代对象,可以对对其进行操作
二,csv文件处理
此处以csv文件代称任何简单字符分割的文件,比如说常见的csv、tsv(bed、txt、excel格式等本质都是前面)。

主要是base python中常用的就是csv模块,所以我们用csv文件操作指代任何更一般的分割符操作:

(1)csv写文件:

首先待写入的文件得有,得有一个待写入文件对象;
然后对于这个对象,我们要使用csv模块进行操作,将基本操作中的待写入文件对象转化为csv模块中的writer对象。
总之,因为我们要使用csv模块,所以我们得将基本文件对象转换为csv中的writer对象,或者是下面的read对象;
然后再使用writer对象的函数,比如说writerow,或者是下面reader对象的函数。
再然后和基本文件读写操作一样关上。
(打开文件,转化对象,开始写或者读,再关上——》打转写关)
# csv文件写操作
# 打转写关import csv
file = open("test.csv","w") #打
csv_writer = csv.writer(file) #转
csv_writer.writerows([["姓名","年龄","性别"],["小明",18,"男"],["小红",19,"女"]]) #写
# 注意写入的是1个可迭代对象,所以可以是1个列表,而每一个被迭代的元素是csv中的一行,所以也可以是一个列表
file.close() #关
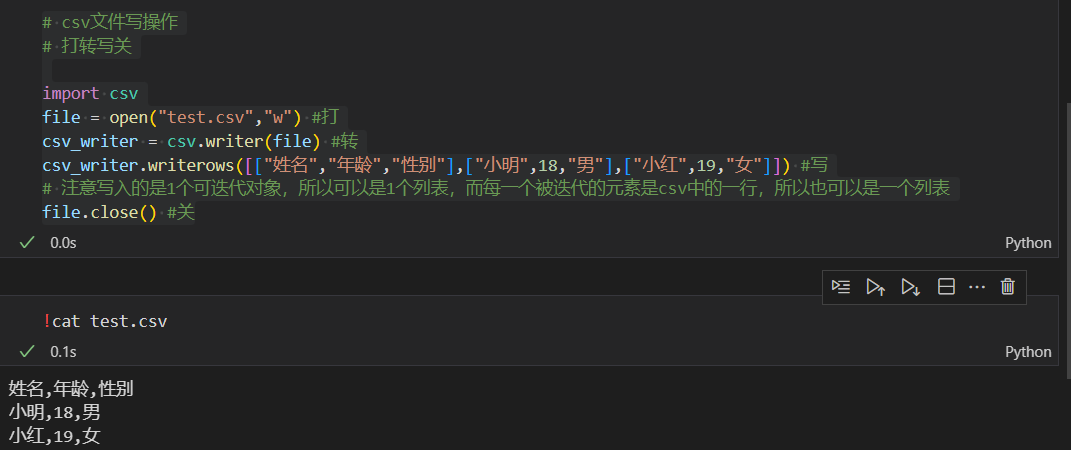
同样的,我们写单个字符用writerow,如果是写入一个可迭代对象就writerows
(2)csv读文件

然后注意对于reader对象,实际上是没有read、readline、readlines等函数方法的,
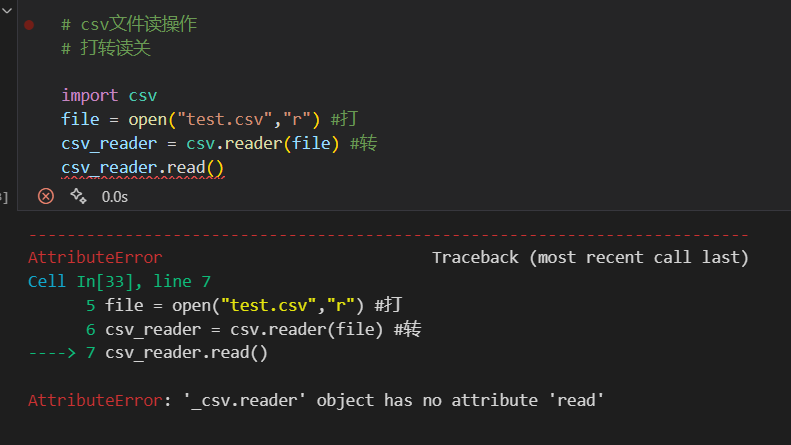
所以实际上还是得使用for循环,取出每一个可迭代对象,
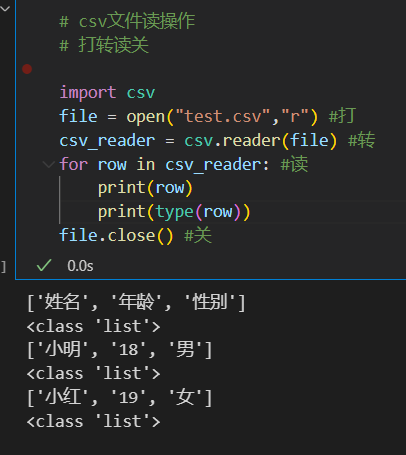
可以看出来读出来的每一个对象都是列表list
# 基本逻辑都是:
# 1,打开文件,如果是读csv文件,就open+r;如果是写csv文件,就open+w,按照前面文件基本读写模式
# 2,对打开的文件可操作对象进行转换(这样才方便使用对应csv对象中的实现方法)
# 3,writer写对象就用写方法,reader读对象就用读方法
# 4,读写完毕之后对于最初打开的文件可操作对象要关闭# 写:打转写关
import csv
file = open("path_to_csv_to_write.csv","w") #打
csv_writer = csv.writer(file) #转
csv_writer.writerows([1个可迭代对象]) #写
file.close() #关# 读:打转读关
import csv
file = open("path_to_csv_to_read.csv","r") #打
csv_reader = csv.reader(file) #转
for row in csv_reader:print(row) # 循环写,对csv中的每一行内容进行操作等
file.close() #关
同样的,养成with as的良好习惯,避免close操作的遗漏。
# 基本逻辑都是:
# 1,with操作打开文件,如果是读csv文件,就open+r;如果是写csv文件,就open+w,按照前面文件基本读写模式
# 2,对打开的文件可操作对象进行转换(这样才方便使用对应csv对象中的实现方法)
# 3,writer写对象就用写方法,reader读对象就用读方法
# 4,读写完毕之后对于最初打开的文件可操作对象要关闭# 写:with打转写
import csv
with open("path_to_csv_to_write.csv","w") as file: #with打csv_writer = csv.writer(file) #转csv_writer.writerows([1个可迭代对象]) #写# 读:with打转读
import csv
with open("path_to_csv_to_read.csv","r") as file: #with打csv_reader = csv.reader(file) #转for row in csv_reader:print(row) # 循环写,对csv中的每一行内容进行操作等
我们来总结一下上面的内容:
**在Python中,文件读写是通过open()函数打开的文件对象完成的。使用with语句操作文件IO是个好习惯。
**文件基本操作是:with打写、with打读;
涉及csv模块的:with打转写、with打转读
如果是读的话建议是for循环读。
另外注意一下encoding参数,即读写的文件编码格式即可,
参考:https://docs.python.org/3/library/codecs.html

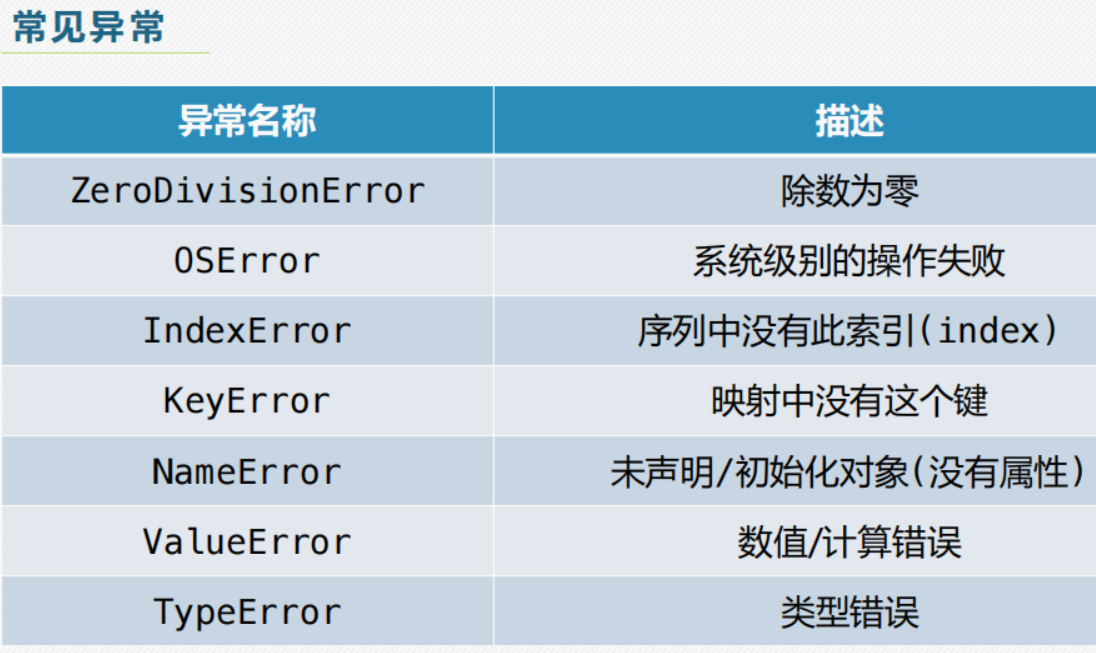
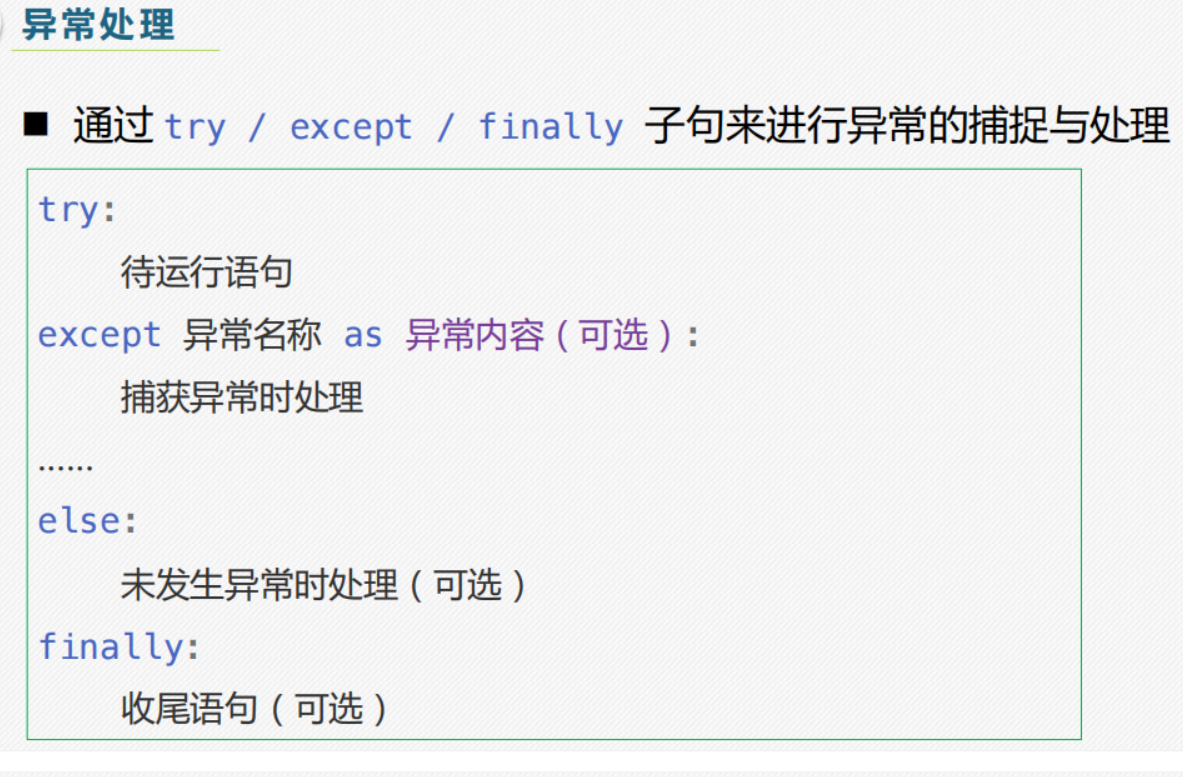
二,异常和异常处理:

要熟悉debug中各种常见的报错error:



这一部分主要是积累debug经验,以及自己严谨规范写代码中的操作。