Datawhale Ollama教程笔记2
本期学习易错点:
改文件后缀
改了models的存储地址后,把下载和新建的文件存储在什么地方
注册hugging face,找到token.
课程思路整理:
这是一个关于 Ollama 的教程,Ollama 看起来是一个用于运行和管理语言模型的工具。这部分内容的核心主题是“自定义导入模型”,也就是怎么把不同的模型格式(比如 GGUF、PyTorch、Safetensors)导入到 Ollama 里面。
第一部分是从 GGUF 文件导入模型。GGUF 这个词看起来是文件格式的名字,得记住它是干什么用的——是为了方便共享和导入模型。这样看来,第一步的重点就是下载一个 GGUF 文件,然后用 Ollama 的工具把它导入。可是为什么是从 GGUF 文件开始呢?是因为这个格式可能是 Ollama 最直接支持的方式,所以作为一个示例,一开始就讲这个会比较容易理解。
然后,下载 GGUF 文件之后,接下来是创建 Modelfile。Modelfile 是什么呢?是用来告诉 Ollama 怎么处理这个模型文件的。相当于一份“说明书”,说明这个模型文件是从哪里来的,接下来要用什么格式来处理。所以,Modelfile 的作用就是连接 GGUF 文件和 Ollama 的工具,让它们能协同工作。
再往后是用 ollama create 命令创建模型。这个命令的作用应该是把 GGUF 文件和 Modelfile 整合成一个可以在 Ollama 里使用的模型。这一步是把前面的准备工作落实到具体的操作上,让模型变成可以直接运行的状态
。
最后一步是运行模型,用 ollama run 命令。就是让模型开始工作,用户可以跟它对话或者让它生成文本。
第二部分,从 PyTorch 或 Safetensors 导入模型。这里好像稍微复杂一点,因为 PyTorch 和 Safetensors 是另一种文件格式,不直接被 Ollama 支持。原文里提到 Safetensors 是一种用于存储模型权重的文件格式,那这部分的重点应该是“如何把这种格式的模型转换成 Ollama 能用的东西”。
但是这里的内容好像有点模糊……文档里提到“目前这部分功能还有待社区成员开发”,说明这可能是个不太成熟的流程。觉得用户可能会不小心掉进这个坑里,因为有些人可能会觉得 PyTorch 和 Safetensors 格式的模型应该可以直接用,但其实可能需要额外的处理步骤。所以这里的关键是提醒用户,这种格式的模型可能需要用其他工具先转换成 GGUF,或者依赖 Ollama 的某些还没完全稳定的功能。
第三部分是从模型直接导入,涉及从 HuggingFace 下载模型、用 llama.cpp 转换和量化模型,然后再导入到 Ollama。这一部分看起来最长,应该也最复杂。首先是从 HuggingFace 下载模型,这一步没什么问题,就是普通的下载操作。然后是用 llama.cpp 把模型转换成 GGUF 格式。这里的逻辑是:HuggingFace 上的模型是各种格式的,而 Ollama 主要支持 GGUF,所以需要一个工具(llama.cpp)来完成格式转换。这个过程挺重要的,因为它是把通用的模型转换成 Ollama 可以用的格式的关键步骤。
接下来是模型量化。量化听起来像是减少模型大小、节省资源的操作。原文里提到量化可以“减少模型文件的大小和计算成本”,这让我想到,如果用户想把模型运行在资源有限的设备上(比如普通笔记本电脑),量化可能会是个必要的步骤。所以,用户如果觉得自己电脑的性能不够,就可以考虑进行量化。
最后一部分是自定义 Prompt。可以通过修改 Prompt 来让模型生成更符合自己需求的文本。比如,文件里举了个例子,把模型的输出从正常的回答变成了“马里奥风格”的回答。这种个性化配置挺有吸引力的,尤其是想让模型更有趣或者更符合某种特定风格。
总结:
“导入模型就像安装一个程序”,“Modelfile 就是程序的说明书”,“运行模型就像启动程序”。
目录
课程思路整理:
一、从 GGUF 导入
二、从 Pytorch 或 Safetensors 导入
三、由模型直接导入
3.1 从 HuggingFace 下载 Model
3.2 使用 llama.cpp 进行转换
3.3 使用llama.cpp进行模型量化
3.4 运行并上传模型
四、自定义 Prompt
参考链接
学习手册:https://datawhalechina.github.io/handy-ollama/#/
第 3 章 自定义导入模型![]() https://datawhalechina.github.io/handy-ollama/#/C3/1.%20%E8%87%AA%E5%AE%9A%E4%B9%89%E5%AF%BC%E5%85%A5%E6%A8%A1%E5%9E%8B
https://datawhalechina.github.io/handy-ollama/#/C3/1.%20%E8%87%AA%E5%AE%9A%E4%B9%89%E5%AF%BC%E5%85%A5%E6%A8%A1%E5%9E%8B
本节学习如何使用 Modelfile 来自定义导入模型,主要分为以下几个部分:
- 从 GGUF 导入
- 从 Pytorch 或 Safetensors 导入
- 由模型直接导入
- 自定义 Prompt
一、从 GGUF 导入
GGUF (GPT-Generated Unified Format) 是一种文件格式,用于保存经过微调的语言模型。这种格式旨在帮助用户方便地在不同的平台和环境之间共享和导入模型。它支持多种量化格式,可以有效减少模型文件的大小。
它的前身是 GGML(GPT-Generated Model Language),是专门为了机器学习而设计的 Tensor 库,目的是为了有一个单文件的格式,并且易在不同架构的 CPU 以及 GPU 上可以推理,但后续由于开发遇到了灵活性不足、相容性及难以维护的问题。
Ollama 支持从 GGUF 文件导入模型,通过以下步骤来实现:
- 下载
.gguf文件
下载链接:https://huggingface.co/RichardErkhov/Qwen_-_Qwen2-0.5B-gguf/resolve/main/Qwen2-0.5B.Q3_K_M.gguf?download=true
为了演示的方便,我们选用了 Qwen2-0.5B 模型。下载后复制到第一作业的models文件夹下面,例如:D:\AI\Ollama\models
2.在同一个目录下,例如:D:\AI\Ollama\models,新建创建 Modelfile 文件
FROM ./Qwen2-0.5B.Q3_K_M.gguf
这里一定记得改后缀,去掉.txt后缀。
不会改后缀看这里:

在文件夹位置:查看-详细信息-文件扩展名 这里打勾。
3. 在 Ollama 中创建模型
终端也改到在同一个目录下,例如:D:\AI\Ollama\models,运行下面:
ollama run mymodel
结果如下:

二、从 Pytorch 或 Safetensors 导入
Safetensors 是一种用于存储深度学习模型权重的文件格式,它旨在解决安全性、效率和易用性方面的问题。目前这部分功能还有待社区成员开发,目前文档资源有限。
如果正在导入的模型是以下架构之一,则可以通过 Modelfile 直接导入 Ollama。当然,你也可以将 safetensors 文件转换为 gguf 文件,再进行处理,转换过程可以参考第三部分。
有关 safetensors 以及 GGUF 更详细的信息可以参考这个链接进行学习 https://www.linkedin.com/pulse/llama-3-safetensors-vs-gguf-talles-carvalho-jjcqf
- LlamaForCausalLM
- MistralForCausalLM
- GemmaForCausalLM
由于这部分内容社区还在不断优化中,因此,这里提供的示例代码和流程仅供参考,并不保证能成功运行。详情请参考官方文档。
- 下载 llama-3 模型,在终端输入:
!pip install huggingface_hub然后显示如下:
 2. 去hugging face注册。头像--Access Tokens--Create new token--Read
2. 去hugging face注册。头像--Access Tokens--Create new token--Read




下载模型:
# 下载模型
from huggingface_hub import snapshot_download
model_id = "unsloth/llama-3-8b-bnb-4bit"
snapshot_download(
repo_id=model_id,
local_dir="llama-3-8b-bnb-4bit",
local_dir_use_symlinks=False,
revision="main",
# 怎么获取<YOUR_ACCESS_TOKEN>,请参照部分3
use_auth_token="<YOUR_ACCESS_TOKEN>")
根目录下创建 Modelfile 文件,内容如下:
FROM ./llama-3-8b-bnb-4bit在 Ollama 中创建模型
ollama create mymodel2 -f Modelfile
运行模型
ollama run mymodel2
那个,一开始觉得这里挺迷惑的,目的是装Qwen2-0.5B,它怎么去装 llama-3 模型了?
三、由模型直接导入
正常来说,我们在 HuggingFace 接触到的模型文件非常之多,庆幸的是,hf 提供了非常便捷的 API 来下载和处理这些模型,像上面那样直接下载受限于网络环境,速度非常慢,这一小段我们来使用脚本以及 hf 来完成。
llama.cpp 是 GGUF 的开源项目,提供 CLI 和 Server 功能。
对于不能通过 Ollama 直接转换的架构,我们可以使用 llama.cpp 进行量化,并将其转换为 GGUF 格式,再按照第一种方式进行导入。 我们整个转换的过程分为以下几步:
- 从 huggingface 上下载 model;
- 使用 llama.cpp 来进行转化;
- 使用 llama.cpp 来进行模型量化;
- 运行并上传模型。
3.1 从 HuggingFace 下载 Model
最直觉的下载方式是通过git clone或者链接来下载,但是因为llm每部分都按GB计算,避免出现 OOM Error(Out of memory),我们可以使用 Python 写一个简单的 download.py。
首先应该去hf拿到用户个人的 ACCESS_TOKEN,打开 huggingface 个人设置页面。
!pip install huggingface_hub
from huggingface_hub import snapshot_download
model_id = "Qwen/Qwen1.5-0.5B" # hugginFace's model name
snapshot_download(
repo_id=model_id,
local_dir="Qwen-0.5b",
local_dir_use_symlinks=False,
revision="main",
use_auth_token="<YOUR_ACCESS_TOKEN>")
3.2 使用 llama.cpp 进行转换
llama.cpp 是 GGML 主要作者基于最早的 llama 的 c/c++ 版本开发的,目的就是希望用 CPU 来推理各种 LLM,在社群的不断努力下现在已经支持大多数主流模型,甚至包括多模态模型。
首先我们克隆 llama.cpp 库到本地,与下载的模型放在同一目录下:
git clone https://github.com/ggerganov/llama.cpp.git
由于使用 llama.cpp 转换模型的流程基于 python 开发,需要安装相关的库,推荐使用 conda 或 venv 新建一个环境。
cd llama.cpp
pip install -r requirements.txt
python convert_hf_to_gguf.py -h
如果显示以下内容,说明转换程序已经准备好了。
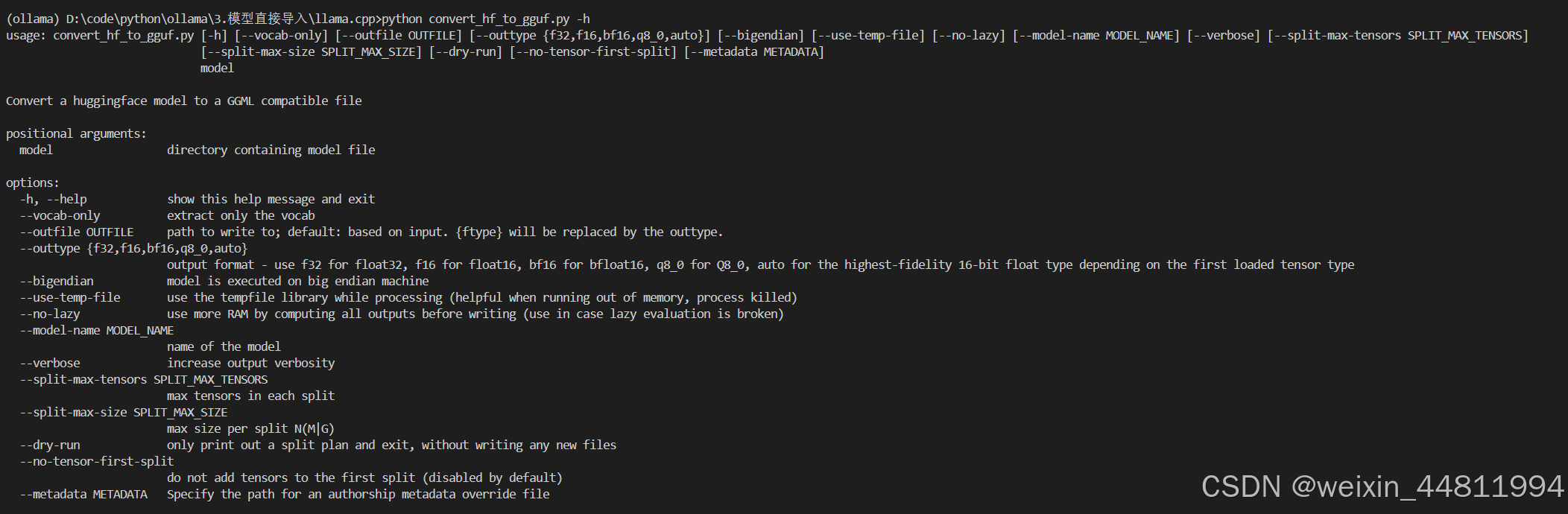
接下来,我们把刚刚从 HuggingFace 下载的模型转换为 GGUF 格式,具体使用以下脚本
python convert_hf_to_gguf.py ../Qwen-0.5b --outfile Qwen_instruct_0.5b.gguf --outtype f16
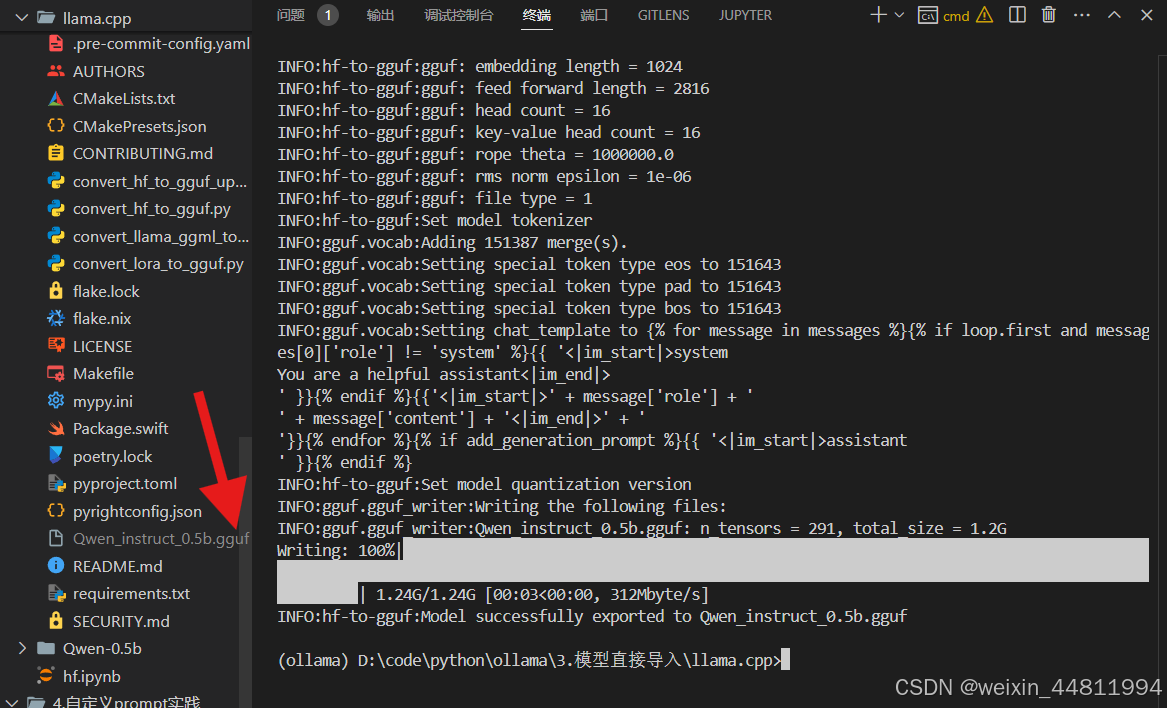
可以看到 llama.cpp 目录下多了一个 Qwen_instruct_0.5b.gguf 文件,这个过程只需要几秒钟。
为了节省推理时的开销,我们将模型量化,接下来我们开始量化实操。
3.3 使用llama.cpp进行模型量化
模型量化是一种技术,将高精度的浮点数模型转换为低精度模型,模型量化的主要目的是减少模型的大小和计算成本,尽可能保持模型的准确性,其目标是使模型能够在资源有限的设备上运行,例如CPU或者移动设备。
同样的,我们先创建 Modelfile 文件,再使 用 ollama create 命令来从 gguf 文件中创建我们的模型,不过与第一步稍有不同的是,我们添加了量化逻辑,只需要在执行 ollama create 是添加一个参数即可。
首先把上一步拿到的 Qwen_instruct_0.5b.gguf 移动至第三部分的根目录下,再创建 Modelfile 文件编写以下内容.
FROM ./Qwen_instruct_0.5b.gguf
终端运行创建和量化脚本。
# 第三部分根目录下
ollama create -q Q4_K_M mymodel3 -f ./Modelfile
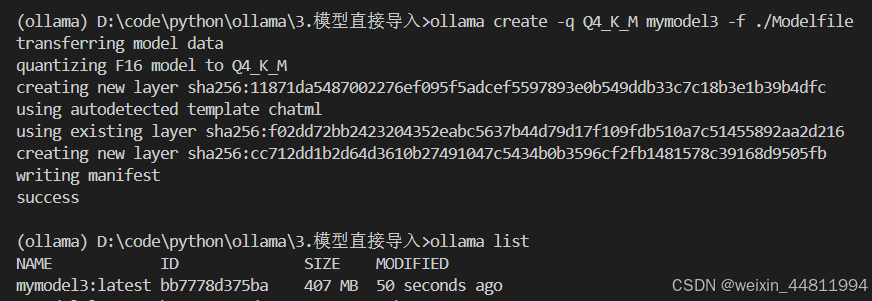 到此,我们的模型就量化并创建完成了,接下来我们就可以运行模型了。
到此,我们的模型就量化并创建完成了,接下来我们就可以运行模型了。
3.4 运行并上传模型
使用 gguf 运行模型的步骤详见第一部分,这里不再赘述。
果本地保存的模型文件太占用空间,可以上传 gguf 模型到 huggingface 的自己的 repo 中,同步骤一的思想,我们可以写一个 upload 的逻辑。
Tip
如果想完成上传,你的 HF_ACCESS_TOKEN 权限必须要为 write,并且要修改你的 model_id,your_hf_name 指的是你 huggingface 账号名称。
from huggingface_hub import HfApi
import os
api = HfApi()
HF_ACCESS_TOKEN = "<YOUR_HF_WRITE_ACCESS_TOKEN>"
#TODO 这里需要设置你的model_id
#例如 model_id = "little1d/QWEN-0.5b"
model_id = "your_hf_name/QWEN-0.5b"
api.create_repo(
model_id,
exist_ok=True,
repo_type="model", # 上傳格式為模型
use_auth_token=HF_ACCESS_TOKEN,
)
# upload the model to the hub
# upload model name includes the Bailong-instruct-7B in same folder
for file in os.listdir():
if file.endswith(".gguf"):
model_name = file.lower()
api.upload_file(
repo_id=model_id,
path_in_repo=model_name,
path_or_fileobj=f"{os.getcwd()}/{file}",
repo_type="model", # 上傳格式為模型
use_auth_token=HF_ACCESS_TOKE)
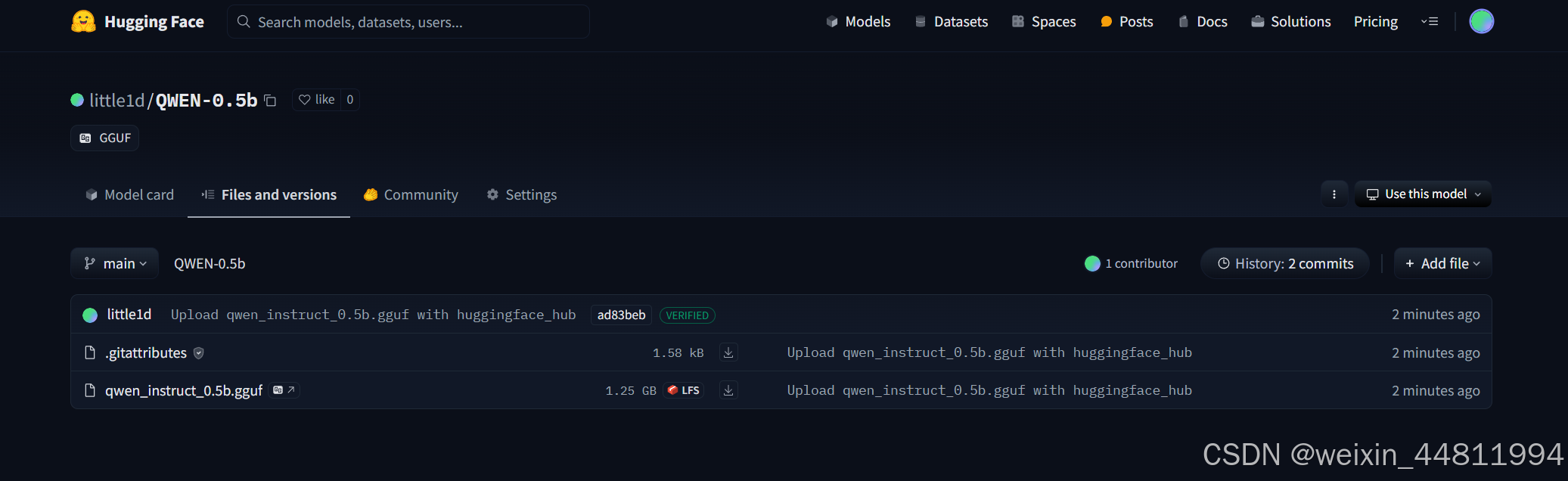
上传完成后就可以在自己的 hf 仓库中看到啦!
四、自定义 Prompt
Ollama 支持自定 义Prompt,可以让模型生成更符合用户需求的文本。
自定义 Prompt 的步骤如下:
- 根目录下创建一个 Modelfile 文件
FROM llama3.1
# sets the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 1
# sets the context window size to 4096, this controls how many tokens the LLM can use as context to generate the next token
PARAMETER num_ctx 4096
# sets a custom system message to specify the behavior of the chat assistant
SYSTEM You are Mario from super mario bros, acting as an assistant.
2.创建模型
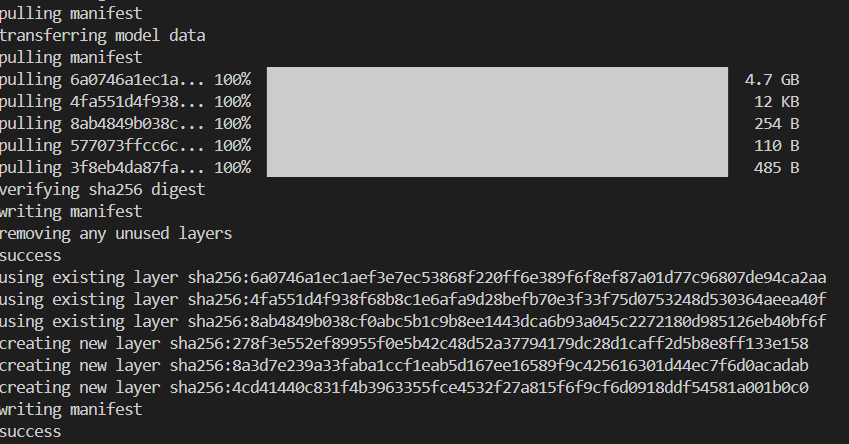
ollama create mymodel -f ./Modelfile
创建模型的时间可能稍微会久一点,和 pull 一个模型的时间差不多,请耐心等待。
再次运行 ollama list 查看已有的模型,可以看到 mymodel 已经正确创建了。

- 运行模型
ollama run mymodel

可以看到,我们的小羊驼 🦙 已经变成了 Mario!自定义 Prompt 成功!😘😘
参考链接
- https://www.linkedin.com/pulse/llama-3-safetensors-vs-gguf-talles-carvalho-jjcqf
- Ollama on Windows:本地运行大语言模型的利器 - 系统极客
- OpenAI compatibility · Ollama Blog
上一章节